はじめに
前回の記事
OpenMPとMicrosoft PPLとParallel STLを比較してみる(その1)
にてMicrosoft PPLがSequentialよりも遅かったので、パフォーマンスを改善してベンチマークを行いました。ベンチマークにはgoogle benchmarkを使用しました。
コードはshohirose/openmp-examples/benchmarkにあげてあります。
コード解説
前回の記事のコードをベンチマークしやすいようにリファクタリングしたものを使っています。
# include <benchmark/benchmark.h>
# include "function.hpp"
using namespace shirose;
std::vector<Point>& getPoints() {
static std::vector<Point> points = generatePoints(10'000'000);
return points;
}
template <typename Counter>
void BM_PiCalculation(benchmark::State& state) {
const auto& points = getPoints();
for (auto _ : state) {
const auto numPoints = state.range(0);
const auto pi = calcPi(points.data(), numPoints, Counter{});
benchmark::DoNotOptimize(pi);
}
}
BENCHMARK_TEMPLATE(BM_PiCalculation, SequentialSTLCounter)
->RangeMultiplier(4)
->Range(1 << 10, 1 << 22);
BENCHMARK_TEMPLATE(BM_PiCalculation, OpenMPCounter)
->RangeMultiplier(4)
->Range(1 << 10, 1 << 22);
BENCHMARK_TEMPLATE(BM_PiCalculation, MicrosoftPPLCounter)
->RangeMultiplier(4)
->Range(1 << 10, 1 << 22);
BENCHMARK_TEMPLATE(BM_PiCalculation, ChunkedMicrosoftPPLCounter)
->RangeMultiplier(4)
->Range(1 << 10, 1 << 22);
BENCHMARK_TEMPLATE(BM_PiCalculation, ParallelSTLCounter)
->RangeMultiplier(4)
->Range(1 << 10, 1 << 22);
BENCHMARK_TEMPLATE(BM_PiCalculation, ParallelOrVectorizedSTLCounter)
->RangeMultiplier(4)
->Range(1 << 10, 1 << 22);
BENCHMARK_MAIN();
ParallelSTLCounterはstd::execution::parを使い、ParallelOrVectorizedSTLCounterはstd::execution::par_unseqを使っています。ChunkedMicrosoftPPLCounterは自分で範囲を分割してconcurrency::parallel_for内でforループを回しています。
各クラスの詳細はファイルを直接みてもらうものとして、google benchmarkに係る部分について解説します。
まず点をランダムに生成するgeneratePointsは重い処理なので、ベンチマーク開始のときにgetPoints関数内で十分な数を一度だけ生成してしまいます。各ベンチマークではその点列を使って円周率を計算しています。ベンチマーク関数内に初期化処理を記載するとベンチマークを実行するたびに初期化処理が行われ、ベンチマーク全体が非常に遅くなるため、それを避けるためにベンチマーク外で初期化を行っています。
結果
データサイズとCPU時間
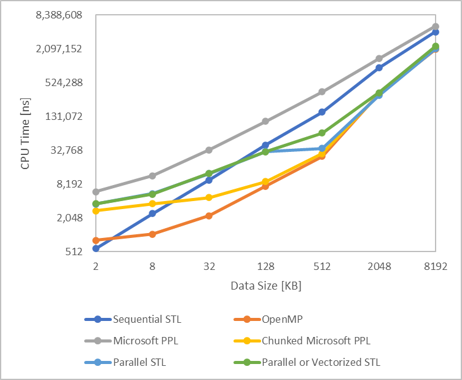
Core i7 9700K(8コア)を使っているので、コア当たりのデータサイズに対してCPU時間をプロットしました(Sequentialは1スレッドですが比較のため合わせています)。
データサイズが小さいと計算時間はOpenMP<Chunked Microsoft PPL<Sequential STL<Parallel STLs<Microsoft PPLの順ですが、ある程度データサイズが大きくなるとOpenMP=Chunked Microsoft PPL=Parallel STLs<Sequential STL<Microsoft PPLとなりました。Core i7 9700KのL2キャッシュが256KB(コア当たり)なので、図1の128~512KBの間の屈曲はL2キャッシュを超えてしまったことが原因と考えています。
データサイズと速度向上率
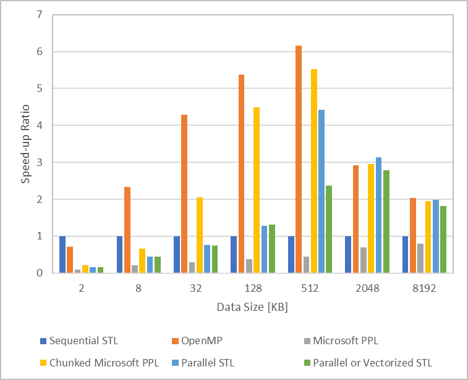
上図は同じデータサイズのSequentialに対する速度向上率を示しています。
データサイズが小さい(512KB未満)ではOpenMPが最も早く、次にマニュアル調整したChunked Microsoft PPLが続きました。データサイズが大きくなるとSTLもOpenMPとChunked Microsoft PPLとほぼ同程度の速度が出ています。小さなループではOpenMPが非常に強いですね…