この記事はTreasure Data Advent Calendar 2015の22日目の記事になります。
自己紹介
ymd_shyと申します。
仕事では去年まではシステム部に所属しておりました。
ですが今年からは分析室というところに所属して、Treasure Dataを使用したデータ分析やアプリケーションからデータを取得するための開発など、データ系の業務をしております。スキル的にはまだまだですが、この記事が役に立てばと思います。
Treasure Dataについて
Treasure Dataを業務で使っておりますが、素晴らしいサービスだなと思っております。
最近はいろいろな会社でビックデータを扱うことが多くなっているとは思いますが、大規模分散処理技術を扱える技術者は希少ですし、それに進化のスピードが早いHadoop、Hive、Prestoのアップデートへの対応、またその開発に貢献しているいけるエンジニアは、普通には雇えないと思います。そのエンジニアがバックに付いているサービスで自由にビックデータをコスト的にも優れている価格で使うことができます。また、他サービスとの連携のスピードも早く、Hivemallなどの機械学習を扱いやすくしてくれるツールの提案もしてくれます。社外に凄腕が揃うビックデータ系の部署と研究開発部署を持っているようなイメージでしょうか。こういったことを考えると非常に有り難いサービスだと思います。
それでは本題に入らせて頂ければと思います。
この記事ではTreasure Dataを利用して、サイトの分析で行うことの多い、UU、カート投入、CVの取得について説明させて頂きます。よろしくお願いいたします。
対象
初歩的な分析なので、バリバリ高度な分析をしている方には参考にならないと思います。
初心者的な内容です。
ただしTreasure Dataについての初歩的な内容は分かるものとします。
分析の概要
あるショッピングサイトのおせちページのページ別のUU、カート投入、CVを分析したいのでTreasure DataからROWデータを分析DBにエクスポートする。
また、3時間毎に最新のデータが分析DBにエクスポートされるようにする。
分析対象テーブルの説明
対象のテーブルは以下の3つでTreasure Data内のDBにあるものとします。
(1) access_log
(2) cartadd_log
(3) order_log
テーブルの内容は以下のものとします。
(1)access_log
・・・サイト全体のアクセスログが保持するテーブル
| DATA COLUMN | TYPE | PARTITION KEY | DESCRIPTION |
|---|---|---|---|
| time | int | ✓ | treasure data で発行する一意のキー |
| td_path | string | パス 例) http://www.example.com/ここ | |
| td_ip | string | ipアドレス | |
| td_client_id | string | treasure data client sdkで発行するクライアントで一意のid | |
| td_url | string | url | |
| customer_id | string | サイトの顧客ID | |
| device | string | デバイス |
(2)cartadd_log
・・・カートに商品を入れた時のログを保持するテーブル
| DATA COLUMN | TYPE | PARTITION KEY | DESCRIPTION |
|---|---|---|---|
| time | int | ✓ | treasure data で発行する一意のキー |
| td_path | string | パス 例) http://www.example.com/ここ | |
| td_ip | string | ipアドレス | |
| td_client_id | string | treasure data client sdkで発行するクライアントで一意のid | |
| td_url | string | url | |
| customer_id | string | サイトの顧客ID | |
| device | string | デバイス | |
| cartadd_url | string | カートに商品を入れた時のURL |
(3)order_log
・・・コンバージョン(注文)が上がった時のログを保持するテーブル
| DATA COLUMN | TYPE | PARTITION KEY | DESCRIPTION |
|---|---|---|---|
| time | int | ✓ | treasure data で発行する一意のキー |
| td_path | string | パス 例) http://www.example.com/ここ | |
| td_ip | string | ipアドレス | |
| td_client_id | string | treasure data client sdkで発行するクライアントで一意のid | |
| td_url | string | url | |
| customer_id | string | サイトの顧客ID | |
| device | string | デバイス | |
| order_id | string | 注文id | |
| cartadd_url | string | カートに商品を入れた時のURL |
アウトプット
Treasure Dataからアウトプットする情報は以下になります。
| DATA COLUMN | DESCRIPTION |
|---|---|
| td_client_id | |
| customer_id | ショッピングサイトの顧客ID |
| device | デバイス |
| lp_path | ランディングページのpath |
| cartadd_flg | カート投入が行われたか? |
| cv_flg | 注文があったか? |
sqlの作成
prestoで抽出する前提でsqlを作ります。
最終的なsqlは1本になりますが、抽出するデータがUU、カート投入、CVの3つなので
まずは3つのsqlを作りたいと思います。
UUの抽出SQL
SELECT
t1.td_client_id,
t1.td_path,
MAX(t1.device) AS device,
MIN(TD_TIME_FORMAT(time,
'yyyy-MM-dd',
'JST')) AS access_day
FROM
access_log t1
WHERE
t1.td_path LIKE '/osechi%'
AND TD_TIME_RANGE(
t1.time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'), '-1d-1h'),
TD_SCHEDULED_TIME(),
'JST'
)
GROUP BY
t1.td_client_id,
t1.td_path
select句から見ていきます。
抽出項目のtd_client_idは、クライアントで一意になるidです。treasure dataのclient sdkで発行していて、デフォルトだと確かcookieに2年保持されます。
このclient_idとtd_pathとdevice(pcとかsmartphone)とaccess_day(アクセス日)でユニークな値を1UUとします。
where句で
t1.td_path LIKE '/osechi%'
としている部分は見たとおりでおせちページのアクセスで絞りたいからです。
その後の以下の条件は1つのポイントとなりますので、後で説明します。
AND TD_TIME_RANGE(
t1.time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'), '-1d-1h'),
TD_SCHEDULED_TIME(),
'JST'
)
CART投入の抽出SQL
SELECT
t1.td_client_id,
url_extract_path(t1.cartadd_url) as cartadd_url,
min(t1.customer_id) as customer_id
FROM
cartadd_log t1
WHERE
TD_TIME_RANGE(
t1.time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'), '-1d-3h'),
TD_SCHEDULED_TIME(),
'JST'
)
GROUP BY
t1.td_client_id,
url_extract_path(t1.cartadd_url)
select句から見ていきます。
抽出項目のtd_client_idは、UUの部分で説明したとおりです。
cartadd_urlではurl_extract_pathを噛ませています。
これはpath以外の部分、urlクエリパラメータなどを除去したいためです。
詳しい使い方は以下を見せてくだい。
https://prestodb.io/docs/current/functions/url.html
where句の部分はUU同様で後で説明します。
group by句のt1.td_client_id、t1.cartadd_urlは
この情報で一意にしたいからです。同じお客様が何回同じページでカートに入れても1カート投入とします。
CVの抽出SQL
SELECT
t1.td_client_id,
url_extract_path(t1.cartadd_url) as cartadd_url,
min(t1.customer_id) as customer_id
FROM
order_log t1
WHERE
TD_TIME_RANGE(
t1.time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'), '-1d-3h'),
TD_SCHEDULED_TIME(),
'JST'
)
GROUP BY
t1.td_client_id,
url_extract_path(t1.cartadd_url)
select句から見ていきます。
抽出項目のtd_client_idは、UUの部分で説明したとおりです。
cartadd_urlの部分もカート投入のSQLで説明した内容と同じです。
where句の部分はUU同様で後で説明します。
group by句のt1.td_client_id、t1.cartadd_urlは
この情報で一意にしたいからです。同じお客様が同じページで何回注文しても1CVとしたいためです。
1つ忘れておりました。全体のアクセスからcustomer_idを抽出するクエリを作ります。
UU、カート投入、CV取得用のSQLからもcustomer_idを抽出することもできますが
これは全体のアクセスからの抽出ではないため、取得できない可能性があります。
customer_idを取得できるとできないとではデータの価値が全然違うので、私はその日の全体のアクセスからcustomer_idを取得するようにしています。
customer_idの抽出SQL
SELECT
t1.td_client_id,
min(t1.customer_id) as customer_id
FROM
access_log t1
WHERE
TD_TIME_RANGE(
t1.time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'), '-1d-3h'),
TD_SCHEDULED_TIME(),
'JST'
)
GROUP BY
t1.td_client_id
select句から見ていきます。
抽出項目のtd_client_idは、UUの部分で説明したとおりです。
customer_idのminはgroup by句に入れていない場合にデータを取得する時のテクニックです。
where句の部分はUU同様で後で説明します。
group by句のt1.td_client_idは
この情報で一意にしたいからです。
4つのSQLをまとめる。
さきほど作成した①UU、②カート投入、③CV取得、④customer_id取得のSQLを
まとめて1つのSQLを作りました。
どのようにまとめたかは①UUのSQLを軸にして、②③④のSQLをLEFT JOINしただけです。
①のSQLを軸にした理由は単純に①で取得できるデータが②③④にはない可能性があるからです。(④はあると思いますが、①が軸なのでLEFT JOINとしています。)
これで最初に決めたアウトプット通りにデータが抽出できると思います。
SELECT
t1.td_client_id,
t1.td_path,
max(t1.device) AS device,
max(COALESCE(t1.customer_id, t2.customer_id, t3.customer_id, t4.customer_id)) AS customer_id,
max(if(t2.td_client_id is NULL, '0', '1')) AS cartadd_flg,
max(if(t3.td_client_id is NULL, '0', '1')) AS cv_flg,
min(TD_TIME_FORMAT(t1.time,
'yyyy-MM-dd',
'JST'
)) AS access_day
FROM
access_log t1
--カート投入
LEFT JOIN (
SELECT
t1.td_client_id,
url_extract_path(t1.cartadd_url) as cartadd_url,
min(t1.customer_id) as customer_id
FROM
cartadd_log t1
WHERE
TD_TIME_RANGE(
t1.time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'), '-1d-3h'),
TD_SCHEDULED_TIME(),
'JST'
)
GROUP BY
t1.td_client_id,
url_extract_path(t1.cartadd_url)
) t2
ON t1.td_client_id = t2.td_client_id
AND t1.td_path = t2.cartadd_url
--CV
LEFT JOIN (
SELECT
t1.td_client_id,
url_extract_path(t1.cartadd_url) as cartadd_url,
min(t1.customer_id) as customer_id
FROM
order_log t1
WHERE
TD_TIME_RANGE(
t1.time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'), '-1d-3h'),
TD_SCHEDULED_TIME(),
'JST'
)
GROUP BY
t1.td_client_id,
url_extract_path(t1.cartadd_url)
) t3
ON t1.td_client_id = t3.td_client_id
AND t1.td_path = t3.cartadd_url
--customer_id取得
LEFT JOIN (
SELECT
t1.td_client_id,
min(t1.customer_id) as customer_id
FROM
access_log t1
WHERE
TD_TIME_RANGE(
t1.time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'), '-1d-3h'),
TD_SCHEDULED_TIME(),
'JST'
)
GROUP BY
t1.td_client_id
) t4
ON t1.td_client_id = t4.td_client_id
WHERE
t1.td_path LIKE '/osechi%'
AND TD_TIME_RANGE(
t1.time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'), '-1d-1h'),
TD_SCHEDULED_TIME(),
'JST'
)
GROUP BY
t1.td_client_id,
t1.td_path
SQLのポイント
さきほど説明を後回しにしていた以下について説明します。
AND TD_TIME_RANGE(
t1.time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'), '-1d-1h'),
TD_SCHEDULED_TIME(),
'JST'
)
この条件は、以下分析の概要に書いていたとおりで3時間毎に最新のデータが分析DBにエクスポートされなければいけないということを考えて、条件を作りました。
分析の概要
また、3時間毎に最新のデータが分析DBにエクスポートされるようにする。
それでTreasure Dataから3時間毎に最新のデータが分析DBにエクスポートすることを考えて、以下のパターンを想定しました。
①当日データをすべてエクスポートする。
②当日の差分データをエクスポートする。
③過去〜現在すべてエクスポートする。
③については毎回大量データをエクスポートすることは現実的にありえないので却下とし、①と②を考えました。②は毎回差分になるように設計しなければいけなく複雑で面倒なので、シンプルで設計も複雑でない①を選択しました。
条件としては、TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST')でSQL実行時間の時間部分をTRUNCATEします。例えば12/22 12:00:00に実行すると12/22 00:00:00となります。そして次ににTD_TIME_ADDで1日と1時間をマイナスしています。計算すると12/20 23:00:00になります。
AND TD_TIME_RANGE(
t1.time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'), '-1d-1h'),
TD_SCHEDULED_TIME(),
'JST'
)
まず'-1d-1h'でなぜ1時間マイナスしているかについて説明します。
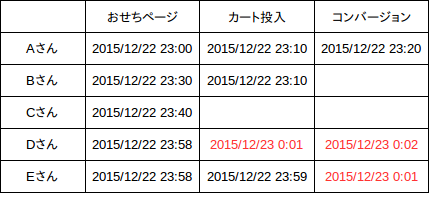
以下表のDさんとEさんのようなパターンの時を考えると、カート投入またはコンバージョンが上がった時間の日付が、次の日にまたいでいます。
このようなパターンの時に、最初におせちページにアクセスした日のカート投入、コンバージョンとしてカウントしたいので、日付またぎを考慮してマイナス1時間をしています。こうしないとUUはないけど、コンバージョンは上がってしまうので、CVRが高くなってしまうようなことが起こるためです。また、この辺をきちんと設計しないと2重にカウントしてしまうことが、起こったりもしますので、気を付けたい点でもあります。
※ユーザーの行動のアクセス時間
最後に'-1d-1h'で1日マイナスしている理由は、以下の表で説明したいと思います。
まず、3時間毎に最新のデータを分析DBにエクスポートするので、0時、3時、6時、9時、12時、15時、18時、21時の1日8回SQLが実行されます。それが左軸の実行時間の部分です。次に上の処理対象を見てみます。黄色の部分が実行時間に対する処理対象になります。ここで注目して頂きたいのが、実行時間が21:00の部分です。この部分は処理対象の18:00〜21:00の部分が、他の実行時間の時に1つもかぶらないので、この時間帯に1度でもクエリが失敗すると、リカバリーがされなくなります。もしリカバリーしたい場合は都度SQLを直すとか、Treasure Data側でスケジュールタイムをずらして実行しなければいけないため、リカバリーが面倒になります。もしマイナス1日していれば、例え失敗しても最低8回自動でリカバリーされるので、こちらの方が運用が楽なのでそのようにしています。
※1日マイナスしない場合のSQLの実行時間と処理対象

※1日マイナスした場合のSQLの実行時間と処理対象

まとめ
ちょっと長くなってしまいましたが、サイトの分析で良く行う、UU、カート投入、CVの取得について説明をさせていただきました。間違いがありましたら、申し訳ございません。ご指摘いただければ幸いです。