AWS Textractは、PDFデータや画像データに含まれるフォーム形式のデータ、または、表形式のデータを読み取り、機械判読可能なデータに変換するサービスです。
[https://aws.amazon.com/jp/textract/]
2019年8月現在まだ日本語をサポートしていませんが、どのようなデータをパースできるのか実際に使ってみました。
条件
Excelで作成したデータをPDF形式で出力し、PDFファイルをAWS Textractにアップロードして認識させた。現実バージョンのPDFデータは、tabula-javaのテストに用いられているPDFデータをそのまま利用した。
- シンプルな表(罫線あり)
- シンプルな表(罫線一部のみ)
- シンプルな表(罫線なし)
- 複雑な表(罫線あり)
- 複雑な表(罫線一部のみ)
- 複雑な表(罫線なし→これはありえないのでパス)
- テキストの列挙
- 同じ構造の繰り返し
- 現実バージョン1
- 現実バージョン2
- 現実バージョン3
- 現実バージョン4
結果
(1) シンプルな表(罫線あり)
入力
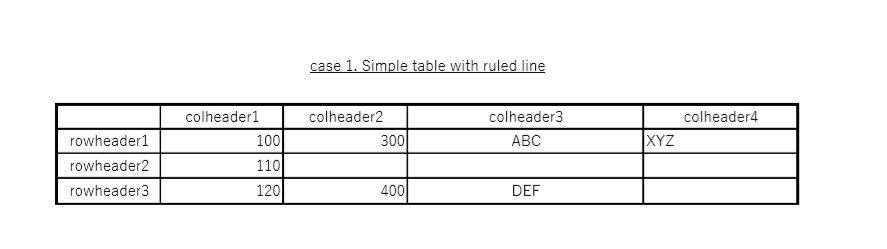
出力
なし
評価
表形式を認識できない。アラインメント(右寄せ)を調整してみたが認識できない。
(1-2) シンプルな表(罫線あり、大きなフォント)
入力
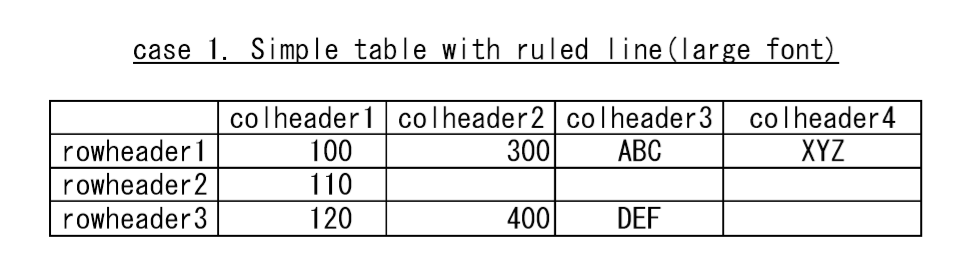
出力
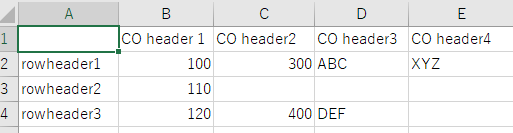
評価
大きなフォントに変換するとテーブルとテキストを認識する。ただし、認識されるテキストが一部間違っている。
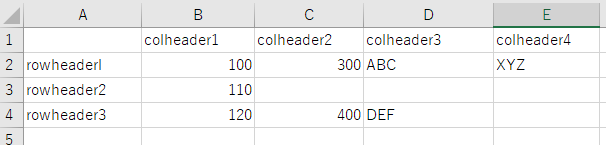
(2) シンプルな表(罫線一部のみ)
入力
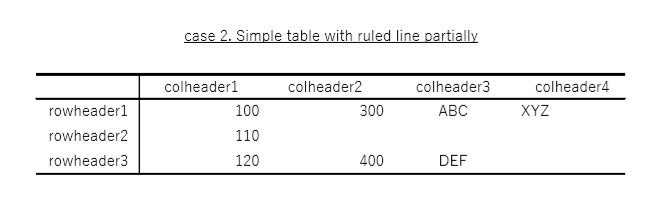
出力

評価
表形式は認識できたが、正しく文字を認識できない。”col" の半角小文字の"L"を罫線と認識してしまっている。
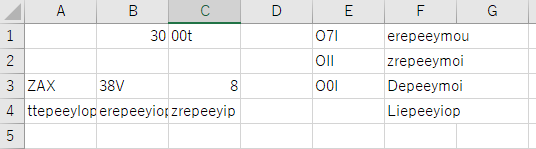
(3) シンプルな表(罫線なし)
入力

出力
評価
罫線がなくなると正しく認識できた!罫線が苦手のよう。
(4) 複雑な表(罫線あり)
入力
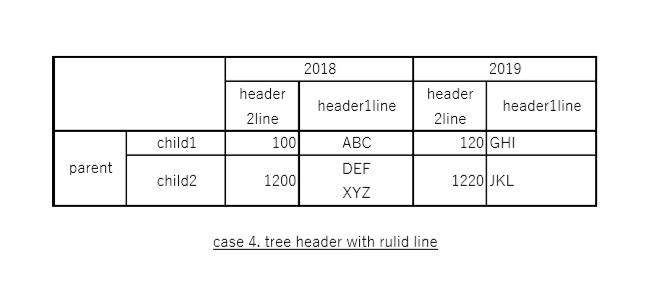
出力
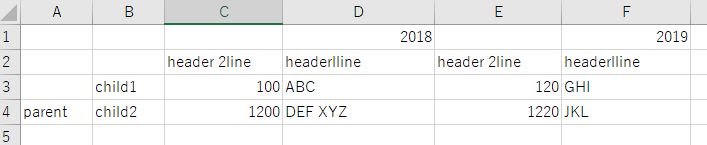
評価:
罫線があっても、parent, 2018, 2019を除くとほぼ正しく抽出できている
(5) 複雑な表(罫線一部のみ)
入力
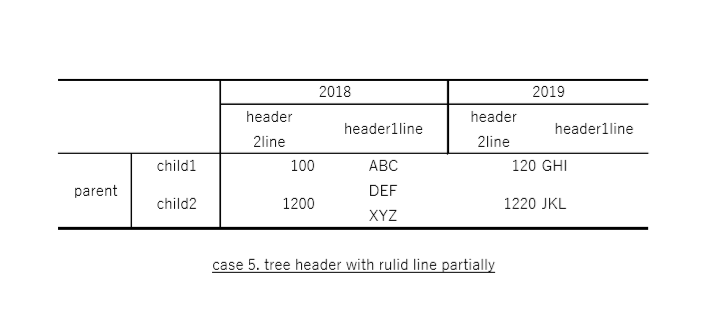
出力
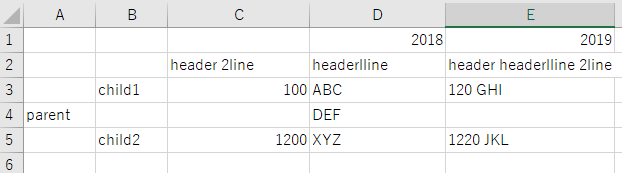
評価:
4に比べて精度が落ちている。
(6) 複雑な表(罫線なし→これは現実的にありえないのでパス)
(7) テキストの列挙
入力
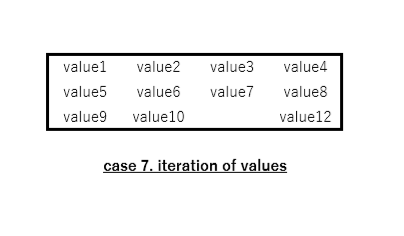
出力
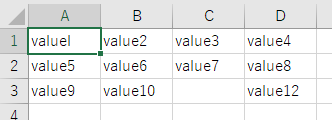
評価
パーフェクト
case7_2
入力

出力
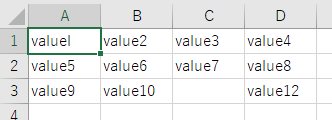
評価
パーフェクト
case7_3
入力
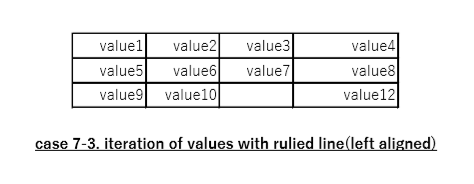
出力
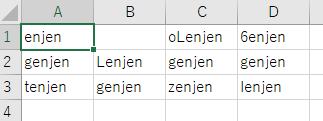
評価
急に文字が認識できなくなる。なんでよ?
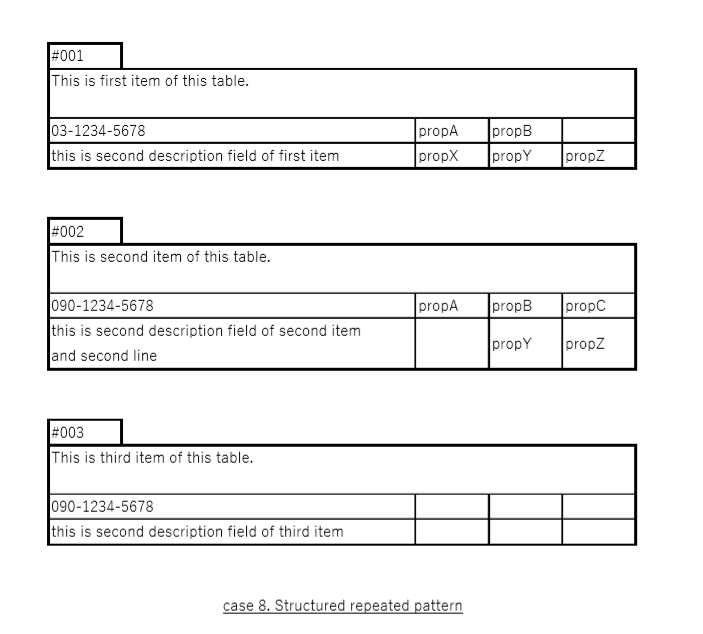
(8) 同じ構造の繰り返し
入力
出力
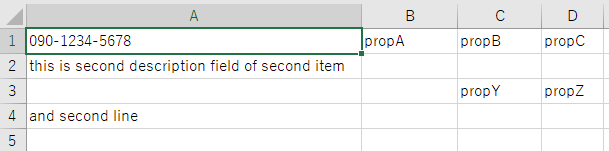
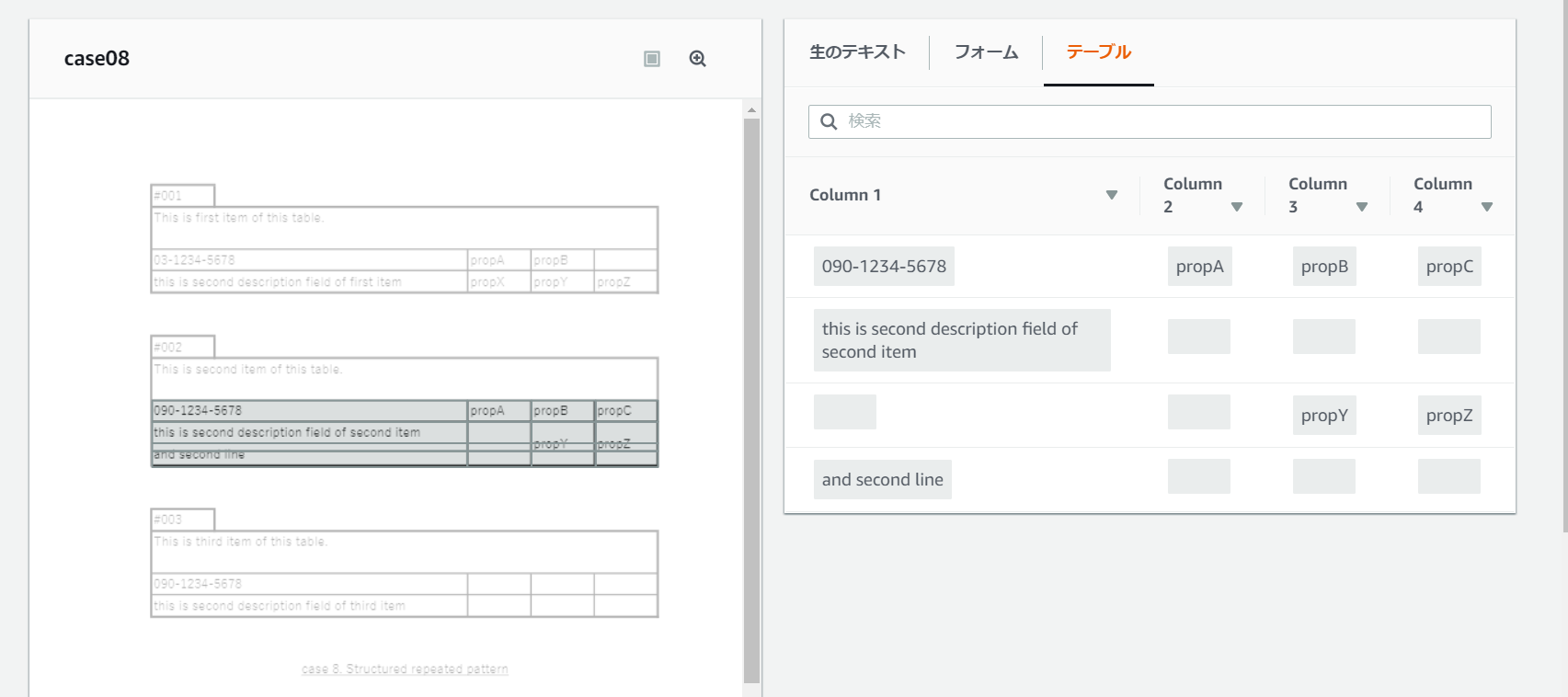
評価
そもそもこの同じ構造を繰り返す形式はサポートしていないよう
(9) 現実バージョン1
入力
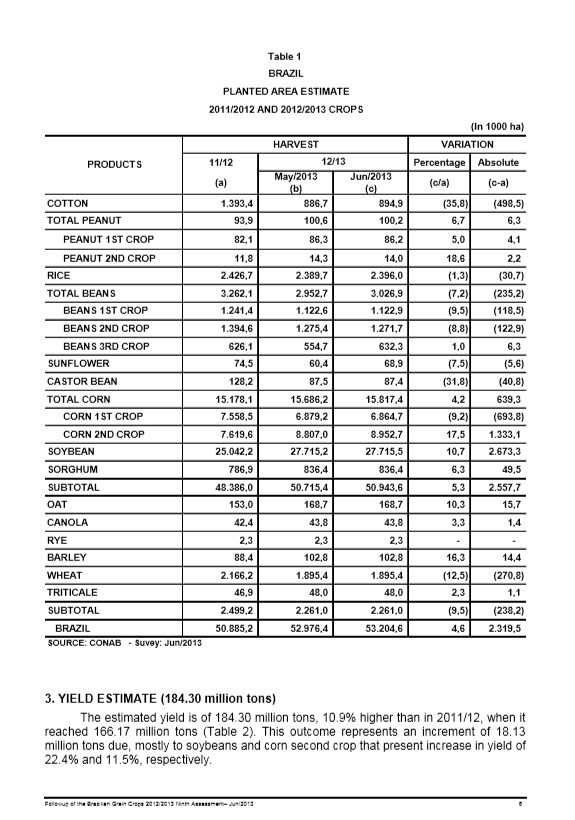
出力
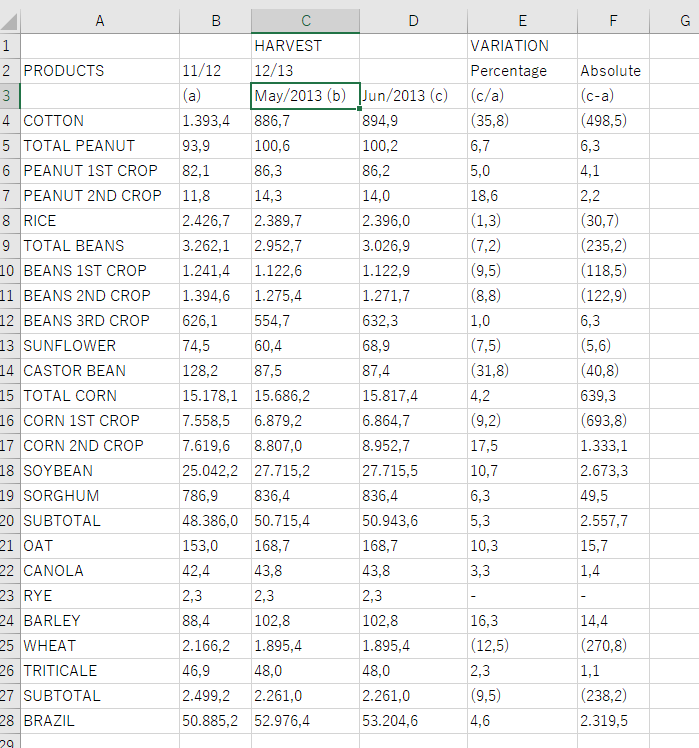
評価
親子関係が死んでいる以外はパーフェクト。フォントによるのかな?
(10) 現実バージョン2
入力
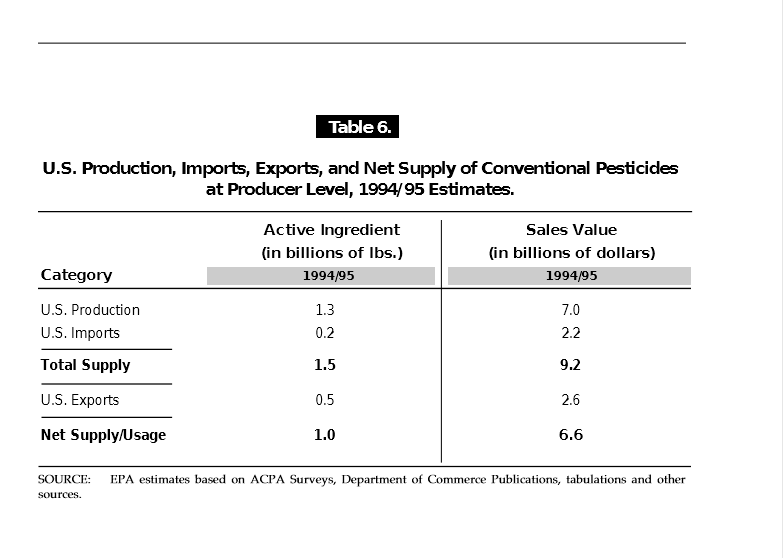
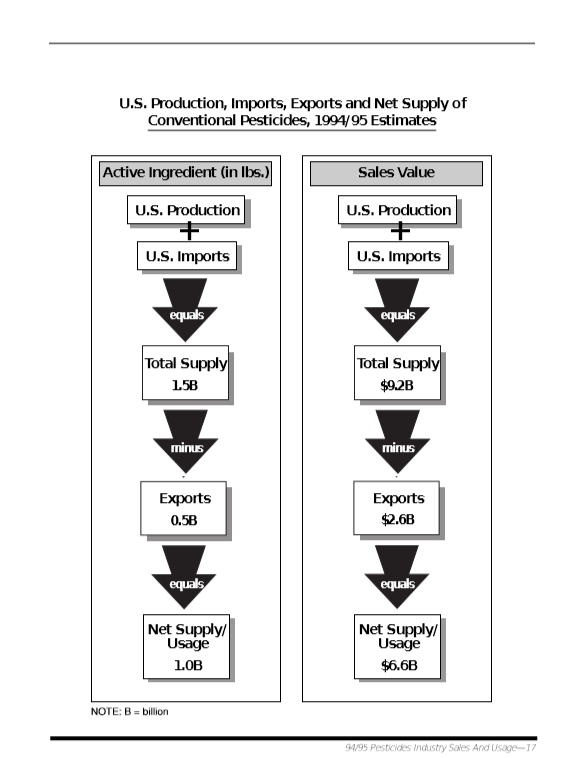
出力
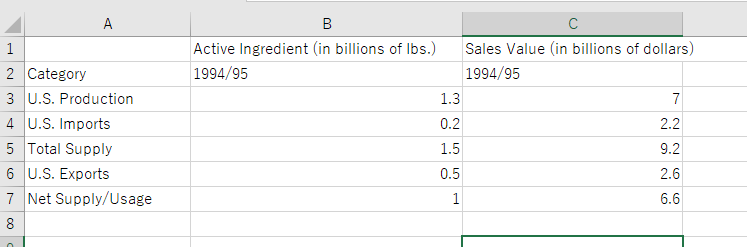
評価:
パーフェクト。2ページ目の図を表と認識しないのも正解。
(11) 現実バージョン3
入力
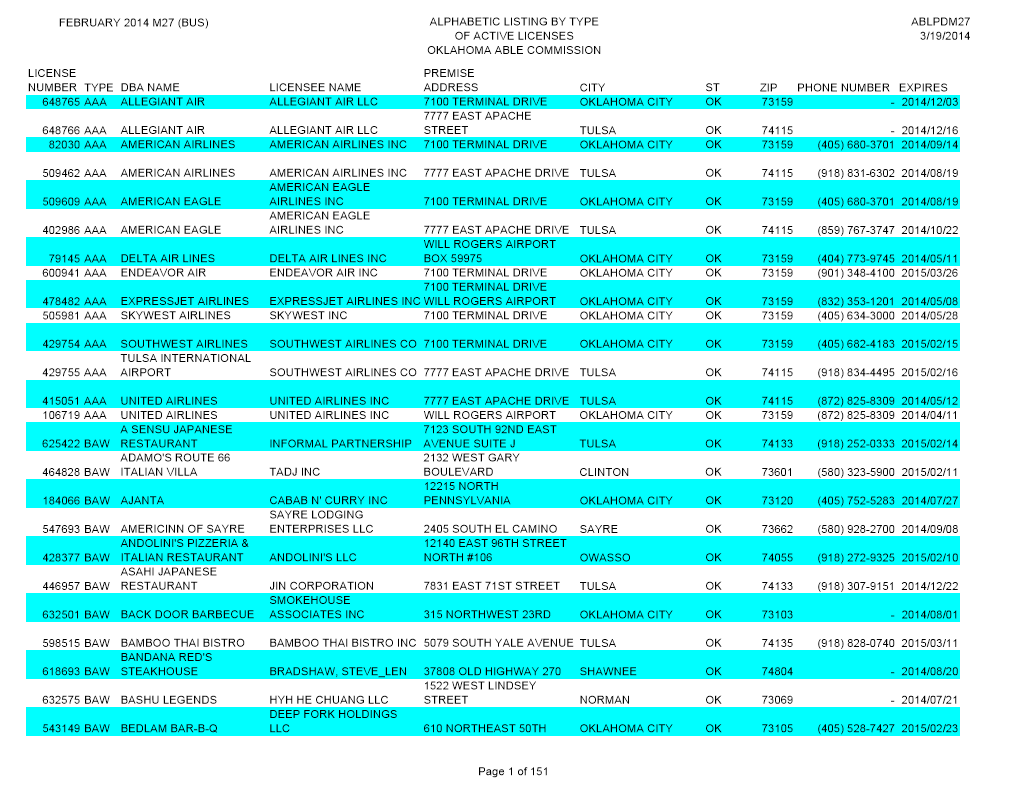
出力
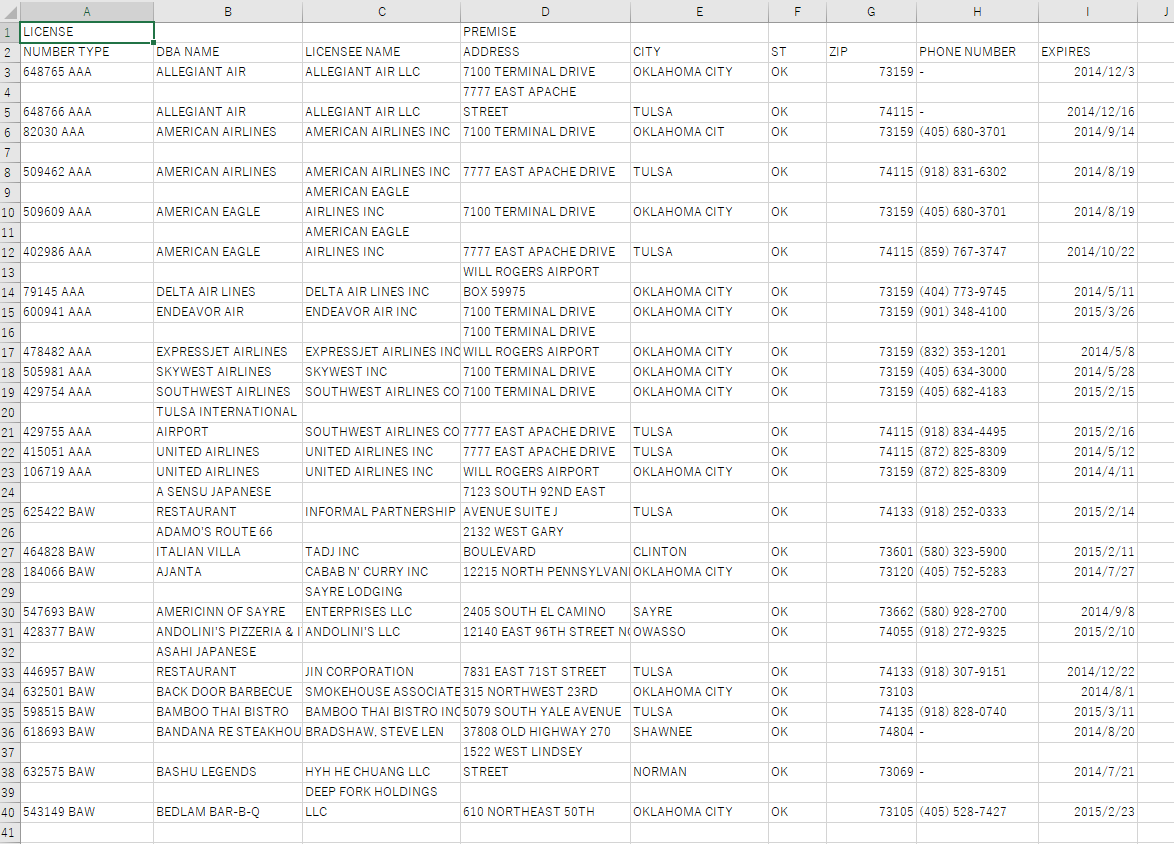
評価
行を正しく認識できていない(odd行even行の色違いを認識しない)
12. 現実バージョン4
入力
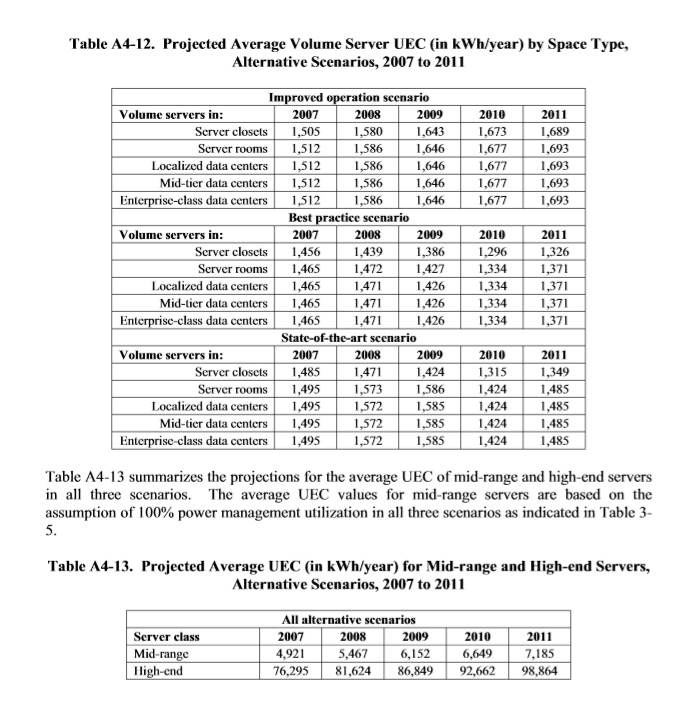
出力
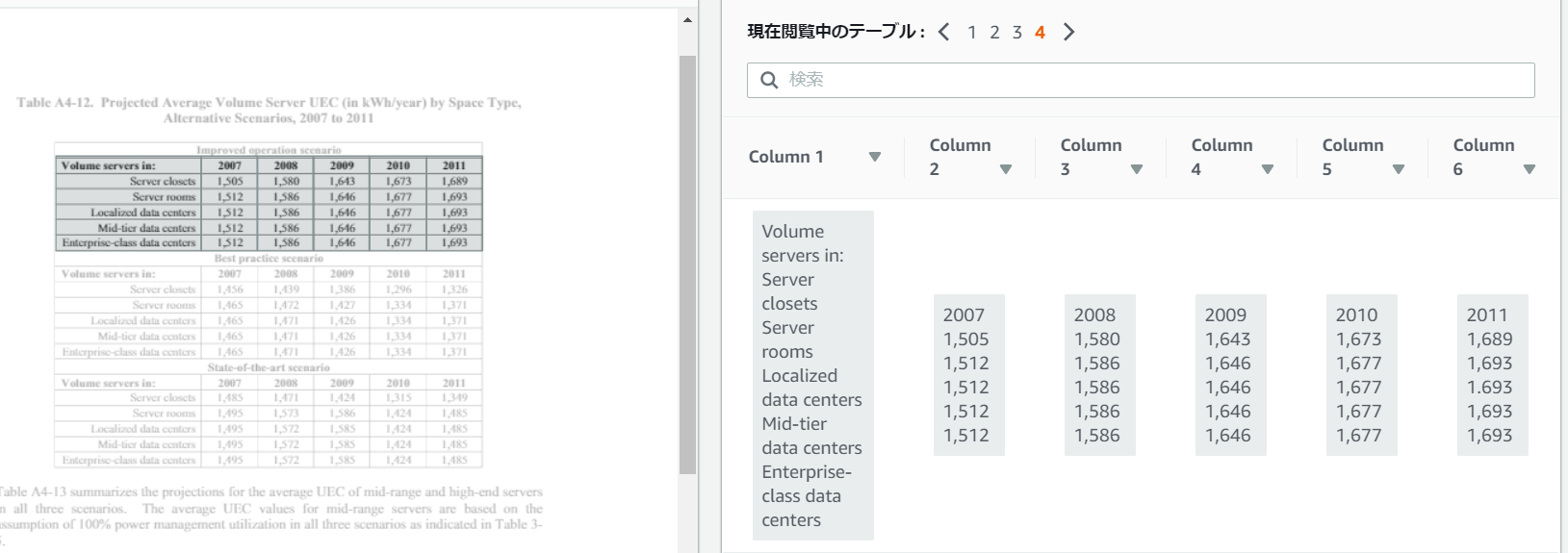
評価:
1ページ内の異なる4つのテーブルをそれぞれ認識できているが、テーブル内に複数の行が存在していることを認識できていない。
まとめ
- 飽くまで画像のOCR。一般的にPDFデータには文字情報が含まれているが、その文字情報は利用していないよう(もったいない)。
- テーブルにはキー(ヘッダ)とバリュー(データセル)が存在するが、現時点でのバージョンでは何がキーで何がバリューかを認識できない。
- 抽出できるかどうかはフォントに依存するよう。
- CSVを生成するところでミスが多い。
- 罫線がまだ苦手のよう。
- 色々試してたら300円くらいかかった。