この記事はレイトレアドベントカレンダー 2022 ⧉ + レイトレ合宿9アドベントカレンダー ⧉の記事として書かれました。
はじめに
2018年末にGPUにレイトレーシング支援のハードウェアが搭載されてから約4年、2022年9月にNVIDIAから新たなGPUであるRTX 40シリーズが発表されました。RTX 40シリーズではレイトレーシングに関してなんと3つもハードウェア的な拡張を伴う新機能が実装されています。
- Opacity Micro-Map (OMM)
- Displacement Micro-Map (DMM)
- Shader Execution Reordering (SER)
いずれも現時点(2022/11/23)ではRTX 40シリーズのGPUかつNVIDIA専用拡張(だったりOptiX)からしか使えませんが、少なくともWhite PaperによればSERはDirectX Raytracing (DXR)やVulkanの将来のバージョンで使えるように協議が進められているらしいですし、OMMやDMMもおそらく標準化を見越しての実装でしょう(どこかでこれも言っていたかも)。NVIDIA専用拡張やOptiXと将来のDXRなどが同じ仕様になる保証はないですが、少なくとも似たような仕様にはなるでしょう。多分。
Ada Lovelaceアーキテクチャー == RTX 40シリーズのWhite Paperはこちら ⧉。
この記事では上記3つの技術についての解説を行います。
追記1: RTX 40シリーズから2年少々経った2025年1月、RTX 50シリーズとともに発表されたClusters API、通称RTX Mega Geometryの登場にあわせてDMM APIがDeprecated扱いになりました。DMM用のハードウェアがClustersに使えるのか不明ですが、少なくともソフトウェア観点でのDMMは普及を待たずして消えそうです。
追記2: 2025年3月、GDC 2025に合わせてDXR 1.2の仕様が発表 ⧉され、OMMとSERが晴れて標準機能に取り入れられました。
追記3: Mega Geometryに関して紹介記事 ⧉を書きました。
Opacity Micro-Map
元となっている手法の論文はこちら。
"Sub-triangle opacity masks for faster ray tracing of transparent objects" ⧉
レイトレーシングにおけるアルファテスト
葉っぱやフェンスのような細かい形状はポリゴンで真面目に表現すると、レイトレーシングの場合BVHのようなAcceleration Structure (高速化機構)のビルド時間・サイズの増大を招きます。そこでレイトレーシングの場合も従来のラスタライズによるレンダリングと同様に、テクスチャーなどを用いたアルファテストを行います。つまりベースとなるポリゴンは下図のように少数に留めておいてAny-Hit Shaderによってレイとポリゴンの交叉をテクスチャーの値に応じて採択もしくは棄却します。
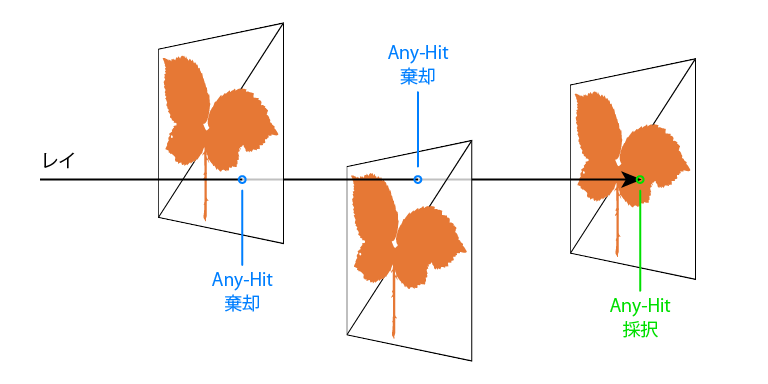
トラバーサルが終わるまでに必要なアルファテストが少数ならば良いのですが、葉っぱのように複雑に折り重なったジオメトリに対してレイトレースを行うとたった1本のレイに対しても大量のテクスチャーフェッチが必要となるため、このようなケースではAny-Hit Shaderの評価はかなり高コストになってしまいます。またトラバーサルが専用ハードウェアで実行されている場合、Any-Hit Shader評価の度に汎用的なシェーダーコアに対してリクエストをかけないといけないため効率が低下します。

森のようなシーンではAny-Hitシェーダーのコストが非常に大きくなります。
OMMによるAny-Hit Shader呼び出し削減
典型的なアルファテスト用のテクスチャーはテクセル単位で乱雑にいろんなアルファが散らばっているのではなく、完全に不透明な領域と完全に透明な領域がはっきりと分かれています。この特性に着目すると各三角形を一様に分割することで多くの領域において完全に透明、完全に不透明という状態を持てることがわかります。具体的には一様な分割は下図のように三角形の重心座標(Barycentric Coordinates)で考えます。分割後の小さな三角形をMicro Triangleと呼びます。

各Micro Triangleは完全に不透明、完全に透明、不明といった状態、つまり2-bitで表せる情報を持ちます。ひとつの三角形における各Micro Triangleの状態をまとめたものをOpacity Micro-Mapと呼びます。 重心座標における一様な分割なので、重心座標が得られる状況であれば単純な処理で対応するMicro Triangleを特定することができます。読み取ったビットが完全に不透明もしくは透明なのであればAny-Hit Shaderにおける高コストな処理を回避できるというのがOMMのアイディアです。(ただしOMM自体の評価も当然コストがかかるので元論文ではハードウェア実装があればより良いと述べられています。)
下に葉っぱの形状のアルファテクスチャーに対して各Micro Triangleの状態を可視化した図を示します。2枚の三角形がありますが、右下の三角形と左上の三角形は左下の頂点を1頂点目として反時計回りに次の頂点が続きます。色が塗られていない領域が完全に透明(Fully Transparent)な領域、葉っぱ内側の暗い領域が完全に不透明(Fully Opaque)な領域、青と緑は不明だがそれぞれ透明寄り(Unknown Transparent)、不透明寄り(Unknown Opaque)な領域を表しています。このケースでは多数のMicro TriangleがFully Transparent/Opaqueに分類されるので多くのAny-Hit Shader呼び出しを削減できることがわかります。

分割レベルにもよりますが、例えば三角形あたり64個のMicro Triangleに分割する場合、OMMのサイズは64x2=128 [bit]、つまり16 [B]になります。OMMの代わりに多数の三角形を用いてアルファテクスチャーの不透明部分にメッシュを沿わせることも考えられますが、単純な三角形表現だと3頂点で36 [B]消費することになるので単純計算でメモリ消費が増えそうなことがわかるでしょう。
先述の森のシーンにおける、プライマリーレイに関するAny-Hit Shader呼び出し回数をOMM無し/有りで可視化したものが下の2つの図になります。青い領域はAny-Hit Shader呼び出しが少なく、緑の領域は中程度、赤い領域は非常に多いことを示しています。OMMを適用することでAny-Hit Shader呼び出し回数が削減できていることがわかります。OMMの分割レベルを増加させることで呼び出し回数をさらに削減することができますが、メモリ使用量とのトレードオフになります。キャッシュヒット率などに影響を与えるはずなので、増やせば増やすだけ性能が伸びるという訳でもないと思います。


RTX 40シリーズではOMMをハードウェア処理するユニットであるOpacity Micro-Map Engineによってアルファテストジオメトリーにおけるレイトレーシングが2倍高速になったと紹介されています。この「レイトレーシング」というのがシェーディングも含めた全体なのか、シャドウレイトレース部分だけなのか等不明ですが、単純にシャドウレイのトラバーサル部分だけならハードウェアサポートされているAdaなら2倍も可能でしょう。
OptiXにおけるOMMの仕様
OptiX 7.6.0 ⧉におけるOMMは以下のような仕様となっています。おそらくDXRやVulkan Ray Tracingにおいても同様の仕様だと思います。
- Opacity Micro-Map Arrayという複数のOMMをまとめて保持するオブジェクトがある。
- OMM Array中の各OMMは異なるフォーマット(Micro Triangleあたり1 or 2-bit)と分割レベル(Base Triangleあたり4のべき乗個のMicro Triangles、1 ~ 16777216個)を持てる。
- 1-bitの場合の各Micro Triangleの状態はFully OpaqueかFully Transparentの2種類。
- 2-bitの場合の各Micro Triangleの状態はFully Opaque, Fully Transparent, Unknown (Opaque), Unknown (Transparent)の4種類。おそらくUnknownの2種はUnknownながらもどっち寄りかによって使い分ける。
- BLASの三角形メッシュジオメトリ入力に追加でOMM Arrayを指定する。
- OMMへのインデックスバッファーを使うこともできる。インデックスバッファーを使う場合はOMM Array中のOMM数と三角形数が一致する必要はない。
- Pre-defined Indexという特殊なインデックスが4種類あり、これらを使う場合OMMを参照する代わりにMicro-Triangleと同じ4状態を表現する。
- MipMapのように複数レベルのOMM Arrayをひとつのジオメトリに関連付けることはできない。
- BLASアップデート時にOMM Arrayを更新可能なようにも設定できる。
- レイフラグやインスタンスフラグによって4状態の解釈を2状態に強制変更可能。
- TLASのインスタンスからBLASのOMMを無効化できるようにも設定できる。
- ただのバイト列としての生のOMM列と各OMMのフォーマット・分割レベル、バイトオフセットを示したOMM Descriptor列、出力バッファー、スクラッチバッファーをAPIに渡すことでASと同じようにGPUによってOMM Arrayが生成される。
- 生のOMM列自体を計算するAPIは用意されていない。
データ格納順
空間的に近傍のMicro Trianglesがメモリ上でも近傍になるように、データの格納は次に示すような"Bird Curve"順に従います。最初のMicro Triangleは重心座標(1, 0, 0)を含み、最後のMicro Triangleは(0, 0, 1)を含みます。

OptiX Programming Guide ⧉から引用。
OMM列の作り方
前述の通り、生のOMM列自体を計算するAPIは用意されていないので三角形メッシュとアルファテクスチャーの対応付けを見て自分で計算する必要があります。前述のOMMの元となっているであろう論文では、ジオメトリシェーダーとインスタンシングを用いたラスタライザーによるOMM列の生成が提案されています。ただしOptiXのOMMとは仕様が微妙に異なっており、各Micro Triangleあたり2-bitなのは同じですが、4状態ではなく、それぞれのビットがFully Opaque/Transparentという表現になっています。
- OMM列をゼロクリア。
- 各Micro Triangleのラスタライズ
- 頂点シェーダー: ベース三角形のテクスチャー座標を出力に使用。
- ジオメトリシェーダー: インスタンスインデックスを用いて対応するMicro Triangleの重心座標を計算、ベース三角形の座標を補間して3頂点を出力。三角形インデックスとMicro Triangleインデックスもピクセルシェーダーにわたす。
- ピクセルシェーダー: 三角形インデックスからOMMを特定。各ピクセルでテクスチャーフェッチ、アルファを評価して透明か不透明かによって2-bitのうち一方をセット(この時点ではPartially Transparent/Opaqueの意味を持つ)。Micro TriangleインデックスからOMM中のDWordを特定してAtomicOr。
- OMM列をビット反転してPartially Transparent/OpaqueではなくFully Opaque/Transparentのビット列に変換する。
下に手法の概略図を示します。この図中で着目しているベース三角形はテクスチャー座標(0, 1), (1, 1), (1, 0)を持っています。緑色のMicro Triangleの状態を決定するためには青で囲ったテクセルの評価を行う必要があります。(図のわかりやすさのために超低解像度のアルファテクスチャーとしています。)

この手法の注意点として、ピクセルシェーダーで評価するテクセルとラスタライズで評価されるピクセルが一対一対応になるようにビューポートサイズを予め適切に設定しておく必要があります。また厳密にOMMを生成するならConservativeなラスタライザーも必要です。さらにOptiXのような仕様だとUnknownに関しても二通り判定する必要があったり、OMMごとに異なるフォーマット・分割数を持てるため、もっと処理を追加・工夫する必要があります。データ格納順も元論文とOptiXで変化しています。
OMM列の生成は結構なコストがかかりますが、三角形メッシュの各頂点のテクスチャー座標や使用するアルファテクスチャーが動的にでも変わらない限りOMMは静的なものなので事前計算しておくことができます。事前計算を考える場合、DXR等における標準化の際に前述のMicro Triangle Indexの対応付け等、どこまでが仕様に含まれるかが気になります。
NVIDIAからOpacity Micro-Map SDK ⧉というものがリリースされているので、実際にはこれを使用すると楽にOMM列を作成できるかもしれません。
Displacement Micro-Map
追記: 前述の通りClusters APIの登場にあわせてDMM APIがDeprecated扱いになりました。 もともとVulkanやDXRでは拡張止まりでしたが、OptiXも9.0のリリースノート曰く将来のバージョンで機能が削除されるとのことです。DMMではなくOMMはRTX 50シリーズのWhite Paperにもしっかり言及があるので残りそうです。
記事執筆時点ではDMMに関しては3つの技術のなかで最も情報が少なかったです。 DMM SDKがリリースされたのでレイトレ合宿9アドベントカレンダー ⧉として更新しました。
元となっていると当初思っていた手法の論文はこちら。
"Tessellation-free displacement mapping for ray tracing" ⧉
NVIDIAのDMM(とOMM)紹介ページ ⧉を見るとAdobeの方からコメントが出ていて、かつ同じ方がこの論文の最終著者でもあります。また、同論文の目的はDMMと同じレイトレーシングにおけるディスプレイスメントマッピングの評価であり、さらにはハードウェア化についても言及されていたため当初はDMMはハードウェア的にはこれなのかな、と勘違いしていました。
レイトレーシングにおけるディスプレイスメントマッピング

AdaのWhite Paper, Figure 9より引用。
ディスプレイスメントマッピングを用いると比較的低ポリゴンのベースモデルに対してテクスチャーなどによって複雑なディテールを簡単に与えることができます。似た技術にバンプマッピングがありますが、バンプマッピングはシェーディングのみに影響を与えるため、ジオメトリを近くで見たときや掠めて見たときに不自然さが露呈しやすい欠点があります。ディスプレイスメントマッピングは実際にジオメトリを変形させるためそのような欠点はありませんが、一方でベースモデルを十分に細分割しないとテクスチャーなどで表現された変位に追従することができません。細分割によって生まれる高ポリゴン数のモデルはレイトレースにおいてトラバーサル時間の増加に繋がります。が、幸いにして実用的なレイトレーシングではAcceleration Structure、典型的にはBounding Volume Hierarchy (BVH)を使用するため、三角形数Nに対するトラバーサルの計算量はlog(N)のオーダーで済みます。そのためジオメトリの三角形数を100倍に増やしたところでトラバーサルの計算時間は基本的にはそこまで増えません。しかしメモリ使用量は三角形数Nに比例してしまいます。 またリアルタイムレイトレーシングにおいては動的なジオメトリのBVHのビルドやリフィットが常に発生します。 BVHのビルド時間も三角形数Nに比例します。 そのため超ハイポリゴンのジオメトリを扱うためには、ラスタライズにおけるテッセレーションのようにオンザフライでハイポリ化する仕組み、もしくはビルド時間やメモリへの影響が軽微な表現がレイトレーシングにも欲しくなります。また、ディスプレイスメントマップに対するレイトレーシングを効率的に扱う仕組みがあれば、逆の考え方としてベースとなるジオメトリ・ASは簡素なものにしておいて、ディスプレイスメントメントによって形状を表現することも考えられます。
DMMによる効率的なディスプレイスメント表現
ディスプレイスメントマップで与えたいジオメトリの詳細は典型的には細かい凹凸であり、反り返った形状や穴の空いた構造はベース形状の時点で表現しておくと思います。またそのような細かい凹凸の周期は特定方向に偏ったものよりは比較的等方性のあるものが多いでしょう。この特性に着目すると各三角形を一様に分割し、分割後の各頂点において一般的な3次元の頂点座標のかわりにスカラーの変位量を持つことで(レイトレーシングの高速化については一旦置いておいて)3次元の形状をコンパクトに表現することができます。一様分割は具体的にはOMM同様に三角形の重心座標上の等分割を考えます。OMMでは分割後の三角形をMicro Triangleと呼びましたが、DMMでは同様に分割後の頂点をMicro Vertexと呼びます。DMMではベース三角形あたり1 ~ 1024個のMicro Trianglesを表現することができます。
ひとつのベース三角形における各Micro Vertexのスカラー変位量をまとめたものをDisplacement Micro-Mapと呼びます。 またDisplacement Micro-Mapによる変位を加えたメッシュのことをDisplaced Micro-Meshと呼びます。ディスプレイスメントマップによる変位は典型的にはベースの三角形で構成されるメッシュ全体に対してかなり小さなスケールであることが多く、それ故精度もそこまで重要ではないことが多いと思います。DMMでは各スカラー変位量を32-bit floatではなく、32bit未満のunormで表現することでDMMをさらにコンパクトに表現します。unormは正規化された実数表現なので値の範囲は0 ~ 1でありそのままでは絶対的な変位量を表現できません。また、ベース三角形に対して常に垂直な変位だと隣接する三角形間でディスプレイスメント方向が不連続になってしまい不自然に見えてしまいます。そこでDisplaced Micro-MeshではDMM自体に加えて、ベース頂点において変位量スケール、変位量バイアス、変位方向をfloatやhalf floatで与えます。 各Micro Vertexの最終的な位置はこれらベース頂点における量を重心座標補間して求めます。
具体的にはベース頂点における補間前の諸量が次のように計算されます。
- (補間前の位置) = (入力位置) + (変位方向) * (変位量バイアス)
- (補間前の変位方向) = (変位方向) * (変位量スケール)
難しいことはしていないですが、ひとつ着目するならベース頂点の位置(入力位置)を直接補間に使うのではなく、バイアスと変位方向によって一旦別の位置に移動させたものが補間に使われる点があるでしょう。これは入力メッシュへの制約を緩める他にも後述のレイトレーシングの効率化のためにも必要です。
超ハイポリメッシュとDMMを使ったメッシュのレンダリングの比較が下の2つの図になります。左は約361万頂点、722万三角形の通常メッシュを、右は約17000頂点、34000三角形のベースメッシュとDMMを使用しています。少々アセットの作り方が雑だったゆえ異なって見える箇所もありますが、ジオメトリの密度は全く遜色なく表現できていることがわかります。


モデルデータはThe Stanford 3D Scanning Repository ⧉よりAsian Dragonを拝借。
BVHサイズとビルド時間は左が200[MiB]、21.4[ms]に対し、右は12[MiB]、1.27[ms]といずれも20分の1近くまで削減されました。一方でトラバーサル速度(レイトレースの速度)はRTX 4080の場合2倍近くかかるようになりました。トラバーサルは遅くなりますが、毎フレームリビルドやリフィットが必要なメッシュの場合がある場合にはDMMが効果的にはたらきます。ビルド時間やメモリ消費の恩恵に預かりつつ、トラバーサル速度低下を最低限に抑えるために、ベース頂点に設定するディスプレイスメントのバイアスやスケールはディスプレイスメント適用後のメッシュを可能な限り小さく囲むように設定すべき、とNVIDIAの発表資料に書かれています。
RTX 40シリーズではDMMをハードウェア処理するユニットであるDisplaced Micro-Mesh EngineのおかげでBVHビルドが10倍速くなり、BVHサイズが20分の1になったとあります。これは従来のBVHと同じものを超高速かつ超コンパクトに作れるようになったという意味ではなく、細かい凹凸を表面に持つオブジェクトなど、ディスプレイスメントで代替が効く形状であれば、頑張って詳細なBVHを作らなくともコンパクトなBVHとDMMで置き換えられるという意味でしょう。
Displaced Micro-Meshのトラバーサル
DMM表現の交差判定方法については詳細はわかりませんが、想像だけなら書くことができます。例えばベースの三角形を数千のMicro Trianglesに分割する場合、それぞれのMicro Triangleとレイの交叉判定を総当りでやっていては処理が重すぎて話にならないので、何らかのAcceleration Structure的な仕組みは使っているはずです。一方で汎用的なASを使うと結局メモリ使用量の観点でメリットが無いので、前述のAdobeの論文のようにディスプレイスメントに特化したASを使用していそうです。
Adobe論文ではディスプレイスメントテクスチャーのミップマップと併せて、対応するテクセル中のディスプレイスメントの最小値最大値を格納したMinMaxミップマップを保持、暗黙的なASとして使用しています。交叉判定を行う際は、ベース三角形とMinMaxミップマップの粗いレベルを合わせてMicro TrianglesのConservativeなAABBを計算、レイが交叉するようであればより詳細なミップレベルを見て再帰的に交叉判定、ターゲットのレベルに到達したらディスプレイスメントテクスチャーから実際のMicro Triangleとの交叉判定を行う、という手順になっています。
OptiXにおけるDMMの仕様
OptiX 7.7.0 ⧉におけるDMMは以下のような仕様となっています。おそらくDXRやVulkan Ray Tracingにおいても同様の仕様だと思います。
- Displacement Micro-Map Arrayという複数のDMMをまとめて保持するオブジェクトがある。
- DMM Array中の各DMMは異なるフォーマット(後述)と分割レベル(ベース三角形あたり4のべき乗個のMicro Triangles、1 ~ 1024個)を持てる。
- BLASの三角形メッシュジオメトリ入力に追加でDMM Arrayを指定する。
- DMMへのインデックスバッファーを使うこともできる。インデックスバッファーを使う場合はDMM Array中のDMM数と三角形数が一致する必要はない。
- 隣接する三角形のエッジにおける変位量はユーザー責任で一致させる必要がある。
- 隣接する三角形間のDMM分割レベル差は1以内にする必要がある。
- 三角形間でメッシュにクラックが発生しないよう、高いレベルの三角形の該当エッジにDecimationフラグを設定する必要がある。
- MipMapのように複数レベルのDMM Arrayをひとつのジオメトリに関連付けることはできない。
- ただのバイト列としての生のDMM列と各DMMのフォーマット・分割レベル、バイトオフセットを示したDMM Descriptor列、出力バッファー、スクラッチバッファーをAPIに渡すことでASと同じようにGPUによってDMM Arrayが生成される。
- 生のDMM列自体を計算するAPIは用意されていない。
DMMフォーマット
DMMのフォーマットは3種類から選ぶことができます。最も単純なフォーマットは各スカラー変位量を11-bit unormで表現したものをそのままバイト列に詰めたフォーマットで最大64個のMicro Triangles (45個のMicro Vertices)の変位を512-bit (== 64B)で表現できます。具体的には次のようなビットレイアウトになっています。
| フィールド | エントリー数 | エントリービット数 | ビットオフセット |
|---|---|---|---|
| 変位量 | 45 | 11 | 0 |
| 未使用領域 | 1 | 15 | 0 |
| 予約領域 | 1 | 2 | 510 |
残り2つのフォーマットは自然なディスプレイスメントの周波数特性が周波数に反比例するという(つまり低周波な特徴ほど変位量が大きく、高周波な特徴は変位量が小さい)特徴を利用した圧縮フォーマットとなっています。これら圧縮フォーマットではベース三角形を重心座標上で再帰的に分割するプロセスを考え、各変位量を「上位分割レベルからの予測」と「補正」にわけて考えます。あるMicro Vertexにおける変位量の予測は
(予測値) = (A + B + 1) / 2
として求めます。ここでA, BはMicro-Vertexが属するエッジの細分割前の両端Micro-Vertexの変位量を表します。+1は変位量がunorm(整数値)による表現なので切り上げを表しています。補正量は本来表したかった変位量と予測の差(負の値は2の補数表現)になります。ある分割レベルにおける補正量が全体的に小さければそのレベルの変位量を少ないビット数で表現することができます。ただしDMMではハードウェア実装の都合やGPU実行の効率化のためか、各レベルの補正ビットの幅は可変にはなっておらず各レベル決め打ちになっています。その場合でも(精度はさておき)正しい補正ができるようにレベル全体の補正値をビットシフトによってスケールできるようになっています。したがって、これら圧縮フォーマットにおける変位量のデコード値は次のように計算されます。
(デコード値) = (予測値) + (SignExtend(補正値) << (レベルのシフト量))
SignExtendは任意のビット数表現でも常に同じ負の値を表現し続けるための符号拡張を表しています。
圧縮フォーマットはそれぞれ256個、1024個のMicro Triangles (153個、561個のMicro Vertices)を1024-bit (== 128B)で表現できます。具体的には次のようなビットレイアウトになっています。
- 256 Micro Trianglesのフォーマット
| フィールド | エントリー数 | エントリービット数 | ビットオフセット | |
|---|---|---|---|---|
| アンカー | 頂点0 | 1 | 11 | 0 |
| 頂点1 | 1 | 11 | 11 | |
| 頂点2 | 1 | 11 | 22 | |
| 補正 | レベル1 | 3 | 11 | 33 |
| レベル2 | 9 | 11 | 66 | |
| レベル3 | 30 | 10 | 165 | |
| レベル4 | 108 | 5 | 465 | |
| レベル5 | N/A | N/A | N/A | |
| 未使用領域 | 1 | 1 | 1005 | |
| シフト | レベル5 | N/A | N/A | N/A |
| レベル4 | 4 | 3 | 1006 | |
| レベル3 | 4 | 1 | 1018 | |
| レベル2 | N/A | N/A | N/A | |
| 予約領域 | 1 | 2 | 1022 |
- 1024 Micro Trianglesのフォーマット
| フィールド | エントリー数 | エントリービット数 | ビットオフセット | |
|---|---|---|---|---|
| アンカー | 頂点0 | 1 | 11 | 0 |
| 頂点1 | 1 | 11 | 11 | |
| 頂点2 | 1 | 11 | 22 | |
| 補正 | レベル1 | 3 | 11 | 33 |
| レベル2 | 9 | 8 | 66 | |
| レベル3 | 30 | 4 | 138 | |
| レベル4 | 108 | 2 | 258 | |
| レベル5 | 408 | 1 | 474 | |
| 未使用領域 | 1 | 88 | 882 | |
| シフト | レベル5 | 4 | 4 | 970 |
| レベル4 | 4 | 4 | 986 | |
| レベル3 | 4 | 3 | 1002 | |
| レベル2 | 4 | 2 | 1014 | |
| 予約領域 | 1 | 2 | 1022 |
ベース頂点に対応する変位量(レベル0)のみ圧縮ではなく11-bit unormでそのまま記録するようになっています。上ではシフト量はレベル全体でひとつかのように説明しましたが、隣接する三角形間でクラックを発生させないために三角形の内側、エッジ3つであわせて4つのシフト量を持てるようになっています。
データ格納順
空間的に近傍のMicro Verticesが(分割レベルごとに)メモリ上でも近傍になるように、データの格納は次に示すような"Bird Curve"順に従います(ただしOMMとは違って頂点が対象)。最初のMicro Vertexの重心座標は(1, 0, 0)、最後のMicro Vertexの座標は(0, 0, 1)になります。

OptiX Programming Guide ⧉から引用。
Displacement Block
前述のようにDMMフォーマットは3つあり、それぞれ64, 256, 1024個のMicro Trianglesを表現することができます。DMMではベース三角形あたり最大1024個のMicro Trianglesを表現することができますが、例えば1024個のMicro Trianglesの場合でも64個や256個のMicro Trianglesのフォーマットを使用することができます。この場合同じフォーマットをかたまりを複数個並べることですべてのMicro Trianglesをカバーします。例えば1024個のMicro Trianglesに対して256個のフォーマットを使う場合は4つ並べることになります。このときの1つのかたまりをDisplacement Block、Blockがカバーする範囲をSub Triangleと呼びます(Micro Triangleと紛らわしいですね)。まとめると、「ベース三角形ひとつあたりDisplacement Micro Mapがひとつあり、最大1024個のMicro Trianglesに分割される。ひとつのDMMは(フォーマットによっては)複数のDisplacement Blocksからなり、ひとつのBlockがカバーする範囲をSub Triangleと呼ぶ。」になります。Sub Trianglesの順番と空間的な位置の対応付けは次の図のようにBird Curveに従います。

OptiX Programming Guide ⧉から引用。
DMM列の作り方
前述の通り、生のDMM列自体を計算するAPIは用意されていないので三角形メッシュとハイトマップの対応付けだったり、ベースメッシュとハイポリメッシュの対応付けを見て自分で計算する必要があります。基本的なDMM列の作り方自体はベース三角形を重心座標上で一様分割したMicro Vertices上でハイトマップの値を評価したり、レイトレースをハイポリメッシュに対して行い距離を取得、変位量を記録するだけなので概念的にはOMMより簡単かもしれません。ただし、隣接三角形間でクラックが発生しないように変位量や分割レベル、フラグを調整したり、圧縮フォーマットのことを考えるとOMMよりかなり面倒な処理になります。
NVIDIAからDisplacement Micro-Map Toolkit ⧉がリリースされているので、これを使うのも手でしょう。
Shader Execution Reordering
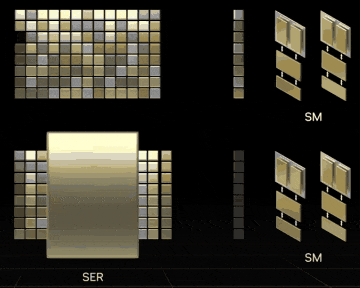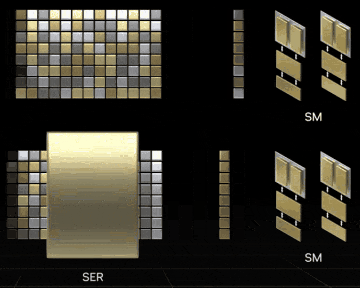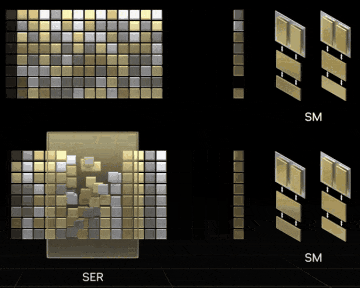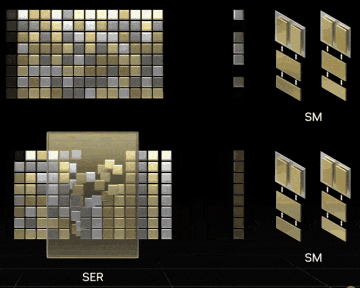
SERの概念動画。RTX 40シリーズが発表されたキーノート ⧉より引用。
SERのWhite Paperはこちら ⧉。
現代のGPUの実行スタイルとダイバージェンス
SERの意義を説明するためにはまず現代(2022年時点)のGPUの命令実行スタイルとダイバージェンスという概念について説明しなければなりません。
昨今のGPUはひとつの命令を異なるデータに対して並列に実行するSIMD (Single Instruction, Multiple Data、シムディー) という実行形態をとっています。またSIMDという言葉の原義とは独立した概念だと思いますが、現代の(2006年くらいから?)GPUプログラミングの特徴として、プログラム自体はCPUコードにおけるシングルスレッドプログラミングのように、SIMDの並列性を特に意識せずに自由に書けるようになっていることがあります。具体的にはif文やfor文による分岐やループなど、読み取るデータによってコードパスが変わる可能性があるものも自由に書けるようになっています。コンパイラーやGPUドライバーがそのようなプログラムを機械語にコンパイルする際にうまくSIMDの並列性を活かせるようにコードを生成します。並列に実行と言ってもGPU全体で同じ命令を実行してるわけではなく、ある程度のまとまりをもって同じ命令を実行します。このまとまりの単位のことをNVIDIA用語ではWarp、AMD用語ではWave (過去にはWavefront)と呼びます。WarpやWaveを構成する処理単位のことをレーン(Lane)やスレッド(Thread)と呼び、Warpは32レーン、Waveは32/64レーン(GPU世代・設定によって異なる)の集まりになっています。1 レーンとスレッドはほぼ同じ意味で使われますが、スレッドはあるシェーダーにおいてGPU全体でグローバルに一意なものだったり、複数のwaveをまとめたグループ内ローカルに一意なものだったり汎用的に使われる一方、レーンはWarp/Wave中ローカルの意味が強いかもしれません。このSIMD + それを意識させないプログラミングスタイル・ハードウェア実装のことを区別してSIMT (Single Instruction, Multiple Threads)とも呼びます。
SIMTでは単一の命令を逐次複数のデータに対して並列実行していきますが、スレッドごとに異なるif分岐やforループがあるとスレッドによっては実行しなくて良い命令、コードブロックに出会うことになります。無関係な命令を素直に実行してしまうと当然スレッドごとに保持しているデータが意図しないものに書き換えられてしまうため、無関係なスレッドにはマスクをかけて命令がデータに影響を与えないようにします。そして共通のコードブロックに戻るとまた全スレッドが有効なことを表すマスクに戻ります。if文による分岐がどのように処理されるかを下記コード・下図に示します。
A;
if (threadIdInWave < 16) {
B;
}
else {
C;
}
D;

ここでは幅32のwaveを例にしています。threadIdInWaveは文字通りwave中のスレッドのIDを表しておりスレッドごとに異なる値を持っています。最初のコードブロックAから条件分岐式の評価まではwave中の全スレッドが有効ですが、コードブロックBは全スレッド命令実行しているものの、実際に有効なのは前半16スレッドのみです。逆にコードブロックCに関しては後半16スレッドのみが有効になっています。コードブロックDではまた全てのスレッドが有効になります。この仕組みによってSIMTスタイルのGPUプログラムはシンプルな記述ながらもSIMDの並列度を活かすことができます。しかし上の図を見て気づいたかもしれませんが、スレッドごとに異なる分岐があると単純計算それぞれの分岐を処理しただけの実行時間がかかります。このようにスレッドごとに異なる分岐によって生じるペナルティのことを実行ダイバージェンス (Execution Divergence)と呼びます。 異なるデータや異なるコードパスを経て生成される値をベクター値、共通のデータ・共通のコードパスから生成される値をスカラー値(もしくはUniform値)と呼びます。ベクター値による分岐でも全スレッド同じ分岐をとる場合や、そもそもスカラー値による分岐の場合、そして異なるwave間では実行ダイバージェンスは発生しません。スカラー値による分岐でも命令キャッシュ周りで多少ペナルティがあったりしますが、実行ダイバージェンスに比べると一般的には軽微です。なのでたまに見るGPUは分岐に弱い云々の話をより正確に言うならば、「ベクターな値による分岐には弱いがスカラーな分岐には大したペナルティが無い。」 ということになります。
SIMDの各スレッドで全く同じデータを処理しても当然無意味なので、同じ命令でも異なるデータを扱いますが、データの持ち方によっても性能が変わります。隣接するスレッドがメモリ空間上で遠く離れた場所にアクセスするとキャッシュのヒット率に悪影響を与え性能が低下します。このペナルティのことをデータダイバージェンス (Data Divergence)と呼びます。 隣接するスレッドがメモリ空間上で連続したデータにアクセスしていればキャッシュヒット率も向上しますし、GPUによってはコアレッシング(Coalescing)といってより効率的なデータアクセス手段を使用してくれるようになります。
現代のGPUの実行スタイルの説明として、もう一つ重要なレイテンシー隠蔽戦略の話があるのですが、SERの説明のためにはそこまで関与しないため省きます。
→レイトレ合宿9 ⧉で行ったセミナーでこのあたりの話を簡単に紹介しました。興味のある方は以下の資料をどうぞ。
現代のGPUの実行スタイルとレイトレ (2023) ⧉
レイトレーシングにおけるダイバージェンス
レイトレーシング(によるレンダリングアルゴリズム)におけるダイバージェンス発生要因は実装するアルゴリズムによっても変化しますが、典型的なものとしてまず挙げられるのがマテリアルの評価です。従来のラスタライゼーションパイプラインではオブジェクトごと、マテリアルごとにシェーダーやテクスチャーを切り替えながらレンダリングするのが一般的でダイバージェンスは発生しにくいものした。DXRなどのGPUレイトレーシングAPIでシーン全体を内包したAcceleration Structureに対してレイトレースを行う場合、レイトレース結果からジオメトリやマテリアル情報を取り出してみるまでマテリアルの種類やテクスチャーが確定しません。これまでのDXRなどでは予め設定しておいたシェーダーテーブル ⧉にもとづいてレイトレース後にはそのまま対応するマテリアルのシェーディングが実行されていました。したがって、同じwave中の各スレッドで異なるマテリアル種別や異なるテクスチャーを評価する状況になり、実行ダイバージェンスとデータダイバージェンスの双方が発生します。 下図に示すようにカメラからトレースするプライマリーレイであれば、同じwave中で評価するマテリアル・テクスチャーは似たようなものになってダイバージェンスはまだマシかもしれませんが、例えばパストレーシングなどでセカンダリーレイ以降の評価を行う場合はスレッドごとに全く異なるマテリアル・テクスチャーとなり激しくダイバージェンスが発生します。

なお、同じマテリアルのシェーダーだとしてもシェーダー内にベクターな分岐があれば依然実行ダイバージェンスが発生します。マテリアルの評価以外にもパストレーシングなどでスレッドごとに異なる経路長を扱うと、waveごとのSIMD利用率が低下し効率が悪化します。
実行ダイバージェンスの発生を理解した上で前述のSERの動画を見ると、SERが何を行おうとしているのか想像がつくのではないでしょうか。
SERによるダイバージェンス抑制
今までのDXR等では次に示すようにレイトレースを実行するとそのままClosest-HitもしくはMissシェーダー、つまり典型的にはマテリアルの評価が行われていました。
// Ray-Gen Shaderなどからのレイトレース
TraceRay(scene, ..., ray, payload);
// ヒット情報に基づいてレイごとにClosest-Hit or Miss Shaderが実行されて返ってくる。
NVIDIAが提案しているShader Execution Reordering (SER)ではTraceRayがレイトレースとシェーダーの実行の2フェーズに分解され、ユーザーが間に介入してスレッドを並び替えられるようになっています。 具体的にはTraceRayHitObjectとInvokeHitObjectへの分解とReorderThreadの導入が行われています。
// Ray-Gen Shaderなどからのレイトレース
HitObject hitObj = TraceRayHitObject(scene, ..., ray, payload);
// ヒット情報に基づいてスレッドを並び替える。
ReorderThread(hitObj);
// Closest-Hit or Miss Shaderの実行。
InvokeHitObject(hitObj, payload);
HitObjectにはヒットに関連づいたシェーダーIDやレイの交点に関する情報が含まれており、ReorderThreadはシェーダーIDを優先的に、続いて位置情報に関して並べ替えを行います。waveより広い範囲でシェーダーIDに関して並べ替えを行えば、あるwaveにおいて単一のシェーダーを実行する可能性が高まりますし、さらに位置に関して並び替えも行うことで空間的に近いテクスチャーの評価──メモリ空間でも近いことが期待される──に繋がります。
ReorderThreadにはいくつかバリエーションがあり、ユーザー定義の並び替えヒント(コヒーレンスヒント)も与えられるようになっています。これによって例えば分岐が多いUberシェーダーなマテリアルの評価のダイバージェンスも抑えることができます(すなわち、並べ替えの優先度はシェーダーID > コヒーレンスヒント > 位置情報の順番)。
// Ray-Gen Shaderなどからのレイトレース
HitObject hitObj = TraceRayHitObject(scene, ..., ray, payload);
// マテリアル情報を少し読み出す。
uint matFlags = hit.LoadLocalRootTableConstant(0);
// ヒット情報と追加のマテリアル情報に基づいてスレッドを並び替える。
const uint matFlagsBitWidth = 4;
ReorderThread(hitObj, matFlags, matFlagsBitWidth);
// Closest-Hit or Miss Shaderの実行。
InvokeHitObject(hitObj, payload);
ReorderThreadはHitObjectだけでなく呼び出し時点でまだ生きているローカル変数などのLive Stateの並べ替えも行ってくれるそうです。おかげでReorderThread呼び出し後のシェーダーコードも透過的に処理を続行することができます。同じwave内で並び替えてもダイバージェンスの解決にならないので、SERの並べ替えはもっと広い範囲で行われるはずですが、具体的にどの範囲なのかとかwave間での同期はどうなるのか等は現時点では不明です(あとGPUによっても変えられうる)。ただLive Stateの並べ替えはメモリシステムを通じて行われる、等White Paperに書いてあるので結構広い範囲で並べ替えが実行されるのかもしれません。
SERはWhite Paperを見る限りかなり簡単に使うことができそうです。Closest-Hitが高コストかつダイバージェンスが激しい場合はSERによって性能が伸びそうですが、スレッドが並び替えられることによって却ってデータダイバージェンスが増えるケース(RayGenシェーダー最後の画像書き込み等)もありそうかつ、ReorderThreadもそれなりにコストがかかりそうなので、簡単には使える一方でReorderThreadがどうダイバージェンスに影響するかの把握は必要そうです。
-
ちなみにWarpは日本語だと縦糸(経糸)という意味で縫い糸の意味もあるThreadに関連付けて名付けられていそうです。Wave(front)は波ですが、幅を持って並列に命令を実行していく様を波になぞらえたのでしょうか。元はAMD用語ですが最近はHLSLでも使われておりリアルタイムレンダリングの世界では事実上の標準用語になっています。 ↩