『データエンジニアリングの基礎』を読んだので、学んだ内容を書き記していく。
自分自身データ分析業務に従事しているが、データの欠損や、複数のデータソースにデータが散在していることなどにより、分析するまでの過程で苦労することが多く、ひいては分析精度にも影響するといった場面に出くわすことが多々ある。
自分自身(または周りのアナリスト含め)分析までの過程で苦労しないため、適切なデータ分析基盤を構築する知見を得ようとこの本を手に取った。
※なお、自分自身の要約、感想をまとめているので本記事内の各項目のナンバリングは本書の実際の目次とは一致していません。ご了承ください。
また、今回は本書のごく一部の内容のみ取り上げているので、気になった方はぜひ本書を実際に手に取っていただけると幸いです。
1.データエンジニアリングライフサイクル
まず、本書の核となる概念がデータエンジニアリングライフサイクルと言われる下の図。
サイクルはまずデータが生成されるところから始まり、データを取り込み、分析できる形に変換、そして分析者へ提供という流れとなるが、データエンジニアはこの一連の流れを管理する役目を持つ。そして、この一連のライフサイクルを適切に構築する上で、図底流の6つの概念についても深い知見を持つ必要がある。

本書はこの図の1つ1つのプロセスおよび概念について、それぞれ深掘っていく構成となっている。
取り込み、変換、提供のプロセスについて以前別記事にもまとめていたので、併せてご参照ください。
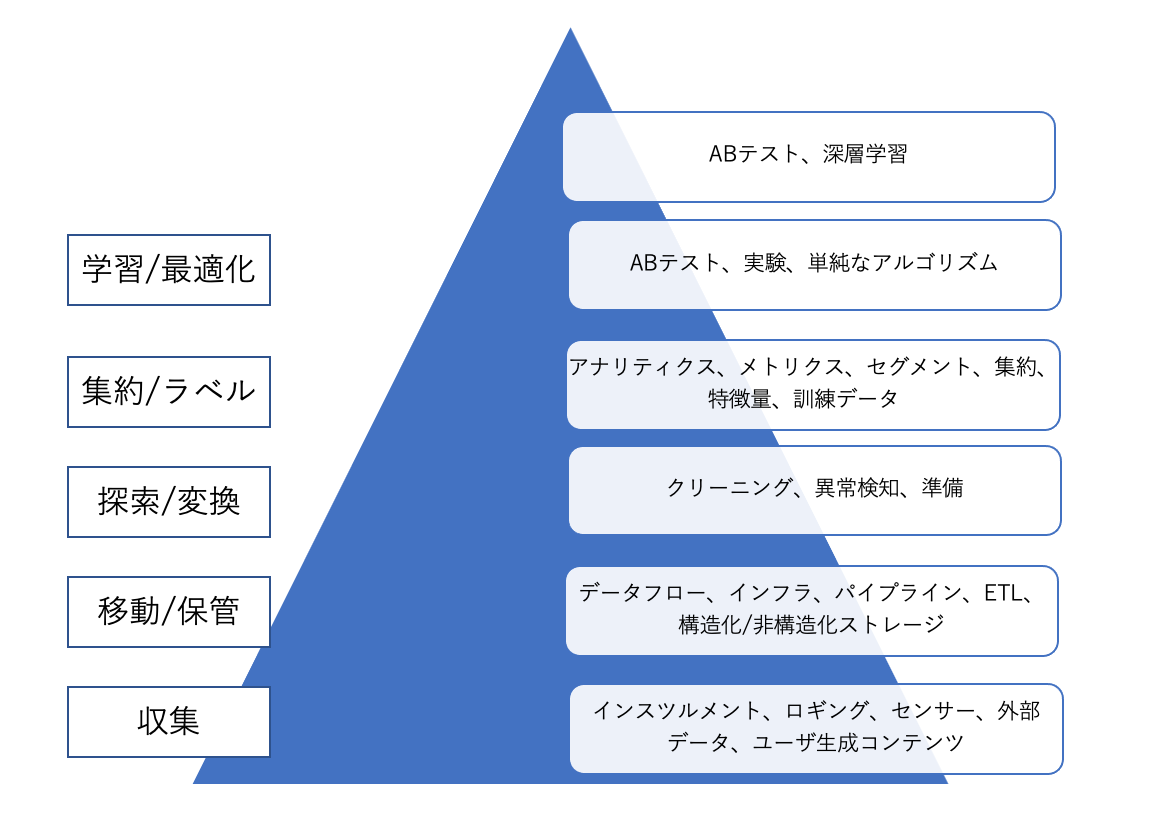
2.データサイエンスのニーズ階層
本書では下記のような図も紹介されている。
データサイエンティストやデータアナリストといったいわゆる「分析者」は90%以上の時間をピラミッドの最上層である分析、実験、機械学習に集中することが理想である。データエンジニアがこの階層の下層部分に注力することで、分析者が分析を成功させるための強固な基盤が構築できる。
データサイエンスが高度なアナリティクスやMLを行うのに対して、データエンジニアリングはデータの取得とデータからの価値の取得の間の溝をまたぐ役割を果たす。
3.データエンジニアリングライフサイクルの各プロセス
3-1.生成
データの生成を知るには以下を理解する必要がある。
・大元のソースシステムがどのように動作しているか。
・データはどのような方法で生成されるか。人が入力、IoTデバイスからetc
・データ生成の頻度と速度
・生成されるデータのバラエティ
ソースシステムの評価について:重要なエンジニアリング上の考慮点
ここでは、データの保存される期間、エラーの発生頻度、データの遅延有無、上流システムの特性、データ品質チェックなどについて考慮する必要がある。
3-2.保存(ストレージ)
データ保存を知る際に重要な概念としてデータアクセス頻度が挙げられている。
ホットデータ
最も頻繁にアクセスされるデータ。
例えばECサイトの売上データなど。
ウォームデータ
週1や月1などたまにアクセスされるデータ。
例えば月一の売り上げレポートなど
コールドデータ
いざという時以外は、ほとんどアクセスされないデータ。
例えば、コンプライアンスや障害に備えて保存しておくデータ
ストレージシステムの選択
ストレージシステムはどのような視点で選択、採用すべきだろうか。それはユースケース、データ量、取り込み頻度、取り込むデータのフォーマット、サイズなどにより変わってくる。高性能であれば良いわけではなく、職場のデータ環境を分析し、適切なシステムを選択することが重要。
ストレージシステムの評価について:重要なエンジニアリング上の考慮点
アーキテクトが要求を満たす書き出し・読み込み速度、下流が要求するSLA、規制コンプライアンスに対応できるかなどを考慮する必要がある。
SLA(サービスレベルアグリーメント)については、以前別記事で取り上げていたので、そちらも併せてご参照ください。
3-3.取り込み
本書ではデータエンジニアリングライフサイクルの中で最大のボトルネックは、ソースシステムとそこからのデータ取り出しであると強調されている。
データ取り込みステージにおける重要な考慮点
ここでは取り込むユースケース、再利用の可否、誰に渡すデータか、アクセス頻度、データサイズなどについて考慮する必要がある。
3-4.変換
データ変換の第1段階:
まずデータを正しい型にマッピングし、レコードを標準的なフォーマットにし、おかしなデータを削除する。
データ変換の第2段階:
後続のステージでは、データスキーマを変換し、正規化を行う場合もある。
データ変換の第3段階:
更に下流では、レポート作成のための大規模な集計を行ったり、ML処理のためにデータを特徴量化することがある。
変換フェーズで考慮するべき点
・変換のコストとROIは?ビジネス的な価値は?
・変換は可能な限り簡潔で、自己完結するようにできているか
・変換がサポートするビジネスルールは?
3-5.データの提供
1、アナリティクス
以下3分野がある。
・BI
・オペレーショナルアナリティクス
・組込みアナリティクス
2、機械学習
機械学習のプロフェッショナルである機械学習エンジニア、データサイエンティストなどとコミュニケーションしコラボレーションできるのが大事である。そのためにはMLの基本技術や関連するデータ処理要件、社内でのそのモデルのユースケース、社内の様々な分析チームの役割に精通している必要がある。
また、データエンジニアが他のチームと連携して、どちらのチームも単独で作れないようなツールを作ることが理想。
3、リバースETL
リバースETLとは、データエンジニアリングライフサイクルで処理され出力されたデータを、ソースシステムにフィードバックするもの。分析結果やスコアリングされたモデルなどを実運用システムやSaaSプラットフォームにフィードバックすることができる。
4.データエンジニアリングにおける主要な底流
データエンジニアリングサイクルの過去と未来:
これまではテクノロジレイヤに焦点が置かれていたが、ツールとプラクティスの継続的な抽象化と簡素化により、データエンジニアの視点はよりバリューチェーンの上流へと遡り、データ管理やコストの最適化といった従来の企業活動や、DataOpsのような新しい活動を含むようになっている。
つまり、データエンジニアとして、技術よりもよりビジネス側の視点に焦点を移すべき(移すことができる)時が来たということだろうか。
4-1.セキュリティ
データセキュリティとアクセスセキュリティの両方を理解し、最小権限の原則を実行する必要がある。
最小権限の原則とは、簡単に言えば必要な時に必要な人にだけ権限を与えるというもの。
データは通信中であれ保存された状態であれ、不必要に可視状態になるべきではない。そのためには、暗号化、トークン化、データマスキング、難読化、シンプルで堅牢なアクセス制御を用いる。
また、クラウドとオンプレミス両方のセキュリティのベストプラクティスを理解する必要がある。
ユーザーとIAMのロールポリシー、グループ、ネットワークセキュリティ、パスワードポリシー、暗号化など。
4-2.データ管理
データ管理のキーワードは以下:
データガバナンス
人、プロセス、技術を用いて、適切な安全性制御でデータを保護しつつ、組織全体でデータの価値を最大化させること
発見可能性
エンドユーザは業務に必要なデータに迅速かつ確実にアクセスできる必要があるので、データの出所や他のデータとの関連、データの意味を知ることができるようにしなければならない。
メタデータ
データに関するデータ。
データ品質
望ましい状態に向けてデータを最適化することであり、「期待したものが得られたか?」という問いに答えるもの。
正確性: 事実として正しいか。重複はないか。数値は正しいか。
完全性: レコードは完全か。全ての必須項目に有効な値が得られているか。
適時性: レコードは期限内に得られたか。
4-3.DataOps
DataOpsとはDevOpsと統計的プロセス制御をデータに適用すること。
初期の段階で手間をかけておけば、プロダクトの迅速なデリバリー、データの信頼性と精度の向上、ビジネス全体の価値の向上などの形で、長期的に大きな利益が得られる。
DevOpsには主に以下が含まれる
・自動化
・観測と監視
・インシデント対応
4-4.データアーキテクチャ
データエンジニアがやるべきこと:
ビジネスからの要請を理解し、新ユースケースから来る要求を集める
↓
これらの要請を翻訳し、データ取り込みする新しい方法を設計する
この際、コストと簡潔なオペレーションとの間でバランスを取る必要がある。
したがって、以下領域間のトレードオフを考える力必要がある。
・デザインパターン
・テクノロジ
・ソースシステムのツール
・データの取り込み
・補完、変換、提供
4-5.オーケストレーション
オーケストレーションとは多数のジョブを、事前に決められた感覚で可能な限り素早く効率的に動作するように調整すること。
4-6.ソフトウェアエンジニアリング
データの取り込み、変換、データサービスのいずれであっても、データエンジニアは、Spark、SQL、Beamなどのフレームワークや言語に精通し、活用する技術を持っていなければならない。
本書の後半について
今回は、本書の前半部のさわりの部分だけ触れた。本書の後半部では、データエンジアリングライフサイクルの書くプロセス、概念についての個別具体的な技術スタックなどにも触れている。
5.所感
データエンジニアリングを極めていくためには以下が重要だと実感
バランス感覚
データ基盤を構築するにあたっては、コスト、セキュリティ、使いやすさ、速度などなどを考慮する必要があるが、それぞれにトレードオフが発生する。そのため、組織の戦略を理解し、コストと使いやすさの最適解を求める力が求められている。
原理原則の理解
本記事では個別のツールについては触れていないが、データエンジニアリングに関わるツール群は膨大であり、栄枯盛衰が激しい。そのような分野においてどうキャッチアップしていけば良いだろうか。
本書では以下の金言があった。
変わらないものを理解するために基礎に注力すること、そしてこの分野の将来を知るために起こりつつある発展に注意を払うことだ。
例えば、あるプログラミング言語のスキルを習得する場合、ただその言語が使えるではなく、データ基盤を構築する上での最適なアルゴリズムを組む力をつけることができれば、別の言語を使うことになったとしても応用できるのではないかと考える。
すぐに役立つものはすぐに役立たなくなるというが、変化の激しいデータエンジニアリングの世界においても、時間をかけてでもずっと役立つ基礎を身につけていきたい。