目的:
データパイプライン構築の学習
実装内容:
JリーグのデータをWebサイトから抽出し、加工、データベースへの格納とそこからの抽出・集計・分析までの一連の流れを実装。
分析テーマ:
ボールポゼッション率が試合の勝敗に影響するか
データ取得元:FootyStats
世界各国のリーグの統計情報が豊富に閲覧できるサイト
使用技術:
Python3
SQL (PostgreSQL)
実行環境:Jupyter Notebook
今回の実装をベースに今後、他の視点での分析、またクラウドや他の技術などでの実装パターンも考え中。
1、データ抽出〜加工
1-1.ライブラリインポート
元データ例:
#各種ライブラリをインポート
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
1-2.試合データの結合
今回はJリーグの2022年~2024年の3シーズン分のデータを見ていくこととする。
一旦、全て合算。念の為最後に各ファイルと合算後ファイルの行数を表示し、試合数と齟齬ないかを確認。
なお、日付のデータを持っているので、後工程で「年」を取り出し、合算データ上ではそちらを使ってどのシーズンかを判別するようにする。
#試合結果データをインポート
df_game_2022 = pd.read_csv('j1_matches_2022.csv')
df_game_2023 = pd.read_csv('j1_matches_2023.csv')
df_game_2024 = pd.read_csv('j1_matches_2024.csv')
#3年分を結合
df_game_all_season = pd.concat([df_game_2022, df_game_2023, df_game_2024], ignore_index=True)
print("試合数")
print(f"2022年:{df_game_2022.shape[0]}行")
print(f"2023年:{df_game_2023.shape[0]}行")
print(f"2024年:{df_game_2024.shape[0]}行")
print(f"合算:{df_game_all_season.shape[0]}行")
結果:
2022年:306行
2023年:306行
2024年:380行
2022年〜2023年は18チームhome&away総当たりなので306試合
2024年は20チームhome&away総当たりなので380試合
なので、試合数としては足りていることは確認できた。
1-3.その他欠損値の確認
欠損値が存在する列を抽出する。
# 欠損値の確認
missing_cols_game = df_game_all_season.columns[df_game_all_season.isnull().any()]
# 欠損値がある列の名前をリスト形式で表示
print("試合結果データで欠損値が含まれる列:", missing_cols_game.tolist())
結果
['attendance','referee', 'home_team_goal_timings', 'away_team_goal_timings','studium_name']
観客数、主審、ホームチームの得点時間、アウェイチームの得点時間、会場名では欠損データを含んでいるようだが、いずれも今回の分析テーマでは影響なしと判断。
1-4.開催日から「年」だけ抜き出し、新たに作成したyear列に格納
シーズンを判別するため「〜年」の形としたい。
# 日付をdatetime型に変更
df_game_all_season["date_GMT"] = pd.to_datetime(df_game_all_season["date_GMT"], format="%b %d %Y - %I:%M%p")
# そこから年を抜き出し、新たな列に格納する
df_game_all_season["year"] = df_game_all_season["date_GMT"].dt.year
# 確認
print(df_game_all_season["year"].unique())
結果:[2022, 2023, 2024]
1-5.スコアの列を作成
ホームチーム得点、アウェイチーム得点とカラムが分かれているため、それとは別に1つのスコアとしてまとめたい。
#ホームチーム得点とアウェイチーム得点の値を結合し「スコア」として新たな列に入れる
df_game_all_season["score"] = df_game_all_season["home_team_goal_count"].astype(str) + "-" + df_game_all_season["away_team_goal_count"].astype(str)
df_game_all_season[["home_team_goal_count","away_team_goal_count","score"]].head()
結果:

1-6.「Game Week」カラムの名称を修正
データベースのの命名規則にも関わってくるので、後々の運用のことを考えて、「Game Week」を「game_week」に修正
# Game Weekの列名を修正
df_game_all_season = df_game_all_season.rename(columns={'Game Week': 'game_week'})
1-7.チーム名を正式な形に修正
「FC」が抜け落ちていたり、通称となっている名前は正式名称に修正。
FootyStatsから取得できる他データでは、通称ではなく正式名称となっているものもあるため、後々のことを考えて正式名称に統一しておく。
# チーム名を修正
df = pd.DataFrame({
'team_name': ['Tokyo','Urawa Reds','Yokohama']
})
mapping = {
'Tokyo': 'FC Tokyo',
'Urawa Reds':'Urawa Red Diamonds',
'Yokohama':'Yokohama FC'
}
# replace()を使って複数の置換を一括実施
df_game_all_season['home_team_name'] = df_game_all_season['home_team_name'].replace(mapping)
df_game_all_season['away_team_name'] = df_game_all_season['away_team_name'].replace(mapping)
1-8.必要なカラムのみにする
今回は下記のカラムを使用することとする。
#必要なカラムだけにする
df_game_all_season = df_game_all_season[[
'year', # 年
'home_team_name', # ホームチーム
'away_team_name', # アウェイチーム
'game_week', # 節
'home_team_goal_count', # ホームチーム得点
'away_team_goal_count', # アウェイチーム得点
'score', # スコア
'home_team_corner_count', # ホームチーム コーナーキック数
'away_team_corner_count', # アウェイチーム コーナーキック数
'home_team_shots', # ホームチーム シュート数
'away_team_shots', # アウェイチーム シュート数
'home_team_shots_on_target', # ホームチーム枠内シュート数
'away_team_shots_on_target', # アウェイチーム枠内シュート数
'home_team_fouls', # ホームチーム ファウル数
'away_team_fouls', # アウェイチーム ファウル数
'home_team_possession', # ホームチーム ポゼッション率
'away_team_possession' # アウェイチーム ポゼッション率
]]
2、データベースへの格納、集計、加工
2-1.データベースに接続
整理済みのdf_game_all_seasonをデータベースに格納してみる。
PostgreSQL用の管理ツールであるpgAdmin上でfootball_analysisというデータベースを作成しておいたので、まずそちらへデータをLoadしてみようと思う。
pip install psycopg2-binary sqlalchemy pandas
from sqlalchemy import create_engine
from sqlalchemy.engine import URL
# 新しいデータベース 'football_analysis' に接続するエンジンを作成
db_url = URL.create(
drivername="postgresql+psycopg2",
username="postgres",
password="********", # 自身のパスワードを記述
host="localhost",
port=5433, # 通常5432だが、なぜか5433で設定していたのでそれに合わせる
database="football_analysis"
)
engine = create_engine(db_url)
データベースに接続したのでデータを格納する。
データベース上で直接行うのと同様、if_exists='replace'で、既存データが入っている場合二重でデータが入らないようにする。
# 作成済みのDataFrameであるdf_game_all_seasonを格納
df_game_all_season.to_sql('df_game_all_season', engine, if_exists='replace', index=False)
2-2.データベースからのデータ抽出
格納したデータをデータベースから取り出してみる。
# PostgreSQL の接続情報を設定
db_config = {
"user": "postgres",
"password": "*****", # パスワード
"host": "localhost",
"port": "5433",
"database": "football_analysis"
}
# SQLAlchemy で PostgreSQL への接続エンジンを作成
engine = create_engine(f"postgresql+psycopg2://{db_config['user']}:{db_config['password']}@{db_config['host']}:{db_config['port']}/{db_config['database']}")
# SQLクエリを実行し、データを DataFrame として取得
query = """
SELECT *
FROM df_game_all_season
"""
# 試しに結果を表示
df = pd.read_sql(query, con=engine)
df.head()
2-3.新たな表を作成してみる
まず、df_game_all_seasonのデータ構造を改めて見てみる。
(今回の集計に関連のあるカラムだけ抜粋)
query = """
SELECT
year,
home_team_name,
away_team_name,
game_week,
home_team_goal_count,
away_team_goal_count,
score,
home_team_possession,
away_team_possession
FROM df_game_all_season
WHERE game_week = 1
"""
df = pd.read_sql(query, con=engine)
df.head()
「対戦カード」単位で集計されているので、「チーム単位」に直してみたい。
「対戦カード」毎でも勝敗とポゼッション率の紐付けは同テーブル内で可能であるが、表の視認性と今後の統計分析のやりやすさの観点から、別構造に置き換えるとする。
ホームチームとアウェイチームの勝敗を別々に判別し、それを結合してみる。
query = """
SELECT
year,
game_week,
home_team_name,
score,
home_team_possession AS possession,
CASE
WHEN home_team_goal_count > away_team_goal_count THEN '勝利'
WHEN home_team_goal_count < away_team_goal_count THEN '負け'
ELSE '引き分け'
END AS result,
CASE
WHEN home_team_goal_count > away_team_goal_count THEN 3
WHEN home_team_goal_count < away_team_goal_count THEN 0
ELSE 1
END AS points,
'ホーム' AS home_or_away
FROM df_game_all_season
UNION ALL
SELECT
year,
game_week,
away_team_name,
score,
away_team_possession AS possession,
CASE
WHEN away_team_goal_count > home_team_goal_count THEN '勝利'
WHEN away_team_goal_count < home_team_goal_count THEN '負け'
ELSE '引き分け'
END AS result,
CASE
WHEN away_team_goal_count > home_team_goal_count THEN 3
WHEN away_team_goal_count < home_team_goal_count THEN 0
ELSE 1
END AS points,
'アウェイ' AS home_or_away
FROM df_game_all_season
ORDER BY year,game_week,home_or_away DESC;
"""
# 変数game_summeryに入れる
game_summery = pd.read_sql(query, con=engine)
結果:
チーム毎に勝敗とポゼッション率を集計

3、分析:ポゼッション率の勝敗への影響
3-1.統計値の確認
# 年ごと & 勝敗ごとの possession の統計情報を計算
yearly_stats = game_summery.groupby(["year", "result"])["possession"].describe()
# 年ごと & 勝敗ごとの 平均 possession
yearly_mean = game_summery.groupby(["year", "result"])["possession"].mean().unstack()
# 結果表示
print("年ごとの possession 統計:\n", yearly_stats)
print("\n年ごとの 平均 possession:\n", yearly_mean)
結果:

今回データを取得した3年間とも統計値だけ見ると勝利したチームは「その試合ポゼッション率が低かった」と見受けられる。
3-2.分散分析
「勝利」「引き分け」、「負け」3つの試合結果が存在するため、分散分析により、ポゼッション率が「試合結果に影響を与えているか」の観点で分析。
import scipy.stats as stats
# 勝敗ごとに possession を抽出
win_possession = game_summery[game_summery["result"] == "勝利"]["possession"]
draw_possession = game_summery[game_summery["result"] == "引き分け"]["possession"]
lose_possession = game_summery[game_summery["result"] == "負け"]["possession"]
# ANOVA(分散分析)
f_stat, p_value = stats.f_oneway(win_possession, draw_possession, lose_possession)
# 結果表示
print(f"F値: {f_stat:.3f}")
print(f"p値: {p_value:.3f}")
# 判定
alpha = 0.05 # 有意水準
if p_value < alpha:
print("帰無仮説を棄却 → ポゼッション率は勝敗に影響を与えている可能性がある")
else:
print("帰無仮説を採択 → ポゼッション率は勝敗と関係がない可能性が高い")
結果:

3-3.ポゼッション率が「高い」「低い」の2値で分析
試しに中央値を境に「高い」「低い」を分類し、集計してみる。
# ポゼッション率の中央値(または閾値)でチームを分類
# 高ポゼッション(possession が中央値以上)
# 低ポゼッション(possession が中央値未満)
# ポゼッション率の中央値を算出
median_possession = game_summery["possession"].median()
# 低ポゼッション(中央値未満) or 高ポゼッション(中央値以上)で分類
game_summery["possession_category"] = np.where(game_summery["possession"] < median_possession, "低", "高")
# 勝敗データの集計
win_rates = game_summery.groupby(["possession_category", "result"]).size().unstack().fillna(0)
# 勝率の計算
win_rates["勝率"] = win_rates["勝利"] / win_rates.sum(axis=1)
# 結果表示
print(f"ポゼッション中央値: {median_possession:.2f}%")
print(win_rates)
結果:

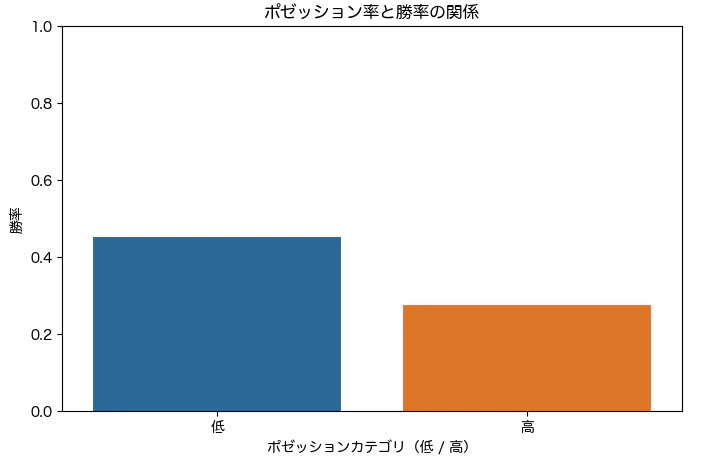
可視化
#ラベルがうまく表示されなかったので、以下を設定
plt.rcParams["font.family"] = "Hiragino Maru Gothic Pro" # mac版
plt.figure(figsize=(8, 5))
sns.barplot(x=win_rates.index, y=win_rates["勝率"])
plt.title("ポゼッション率と勝率の関係")
plt.xlabel("ポゼッションカテゴリ(低 / 高)")
plt.ylabel("勝率")
plt.ylim(0, 1)
plt.show()
結果:
3-4.カイ二乗検定
ポゼッションが低いチームと高いチームで 勝敗の割合に有意な差があるかを検定。
import scipy.stats as stats
# 勝ち vs 非勝ち(引き分け + 負け)のクロス集計表を作成
contingency_table = game_summery.pivot_table(
index="possession_category",
columns="result",
aggfunc="size",
fill_value=0
)[["勝利", "引き分け", "負け"]]
# カイ二乗検定の実施
chi2_stat, p_value, dof, expected = stats.chi2_contingency(contingency_table)
# 結果表示
print(f"χ²値: {chi2_stat:.3f}")
print(f"p値: {p_value:.10e}") # p値を指数表記で表示
# 判定
alpha = 0.05
if p_value < alpha:
print("帰無仮説を棄却 → ポゼッション率の違いは勝敗に有意な影響を与えている可能性がある")
else:
print("帰無仮説を採択 → ポゼッション率と勝敗の関係に統計的な差はない")
結果:

結果的には、ポゼッション率の違いは勝敗に有意な影響を与えている可能性があると言える。
近年では低ポゼッションがトレンドになっているとも言える。
なお、今回はあくまでポゼッション率にフォーカスを当てているが、完成度が高いチームがポゼッションに依存しない(守ってカウンター)の戦術を取っているとも言える。
チーム完成度をどのような指標で表せるのかなど、ポゼッション率以外にも様々な視点から分析を続けてみたいと思う。