はじめに
本記事はMachine&Deep Learning論文紹介 Advent Calendar 2020の19日目の記事です。
GANに興味があるので、紹介します。
[引用]
論文:https://arxiv.org/abs/2008.05865v1
GANとは
GANとはGenerative Adversarial Network(敵対的生成ネットワーク)の略です。生成モデルの一種であり、データから特徴を抽出することで実在しないデータを作り出すことが出来ます。
以下のように実在しない顔画像を生成することが出来ます。

論文の紹介
ここからは論文紹介になります。
DF-GANとは
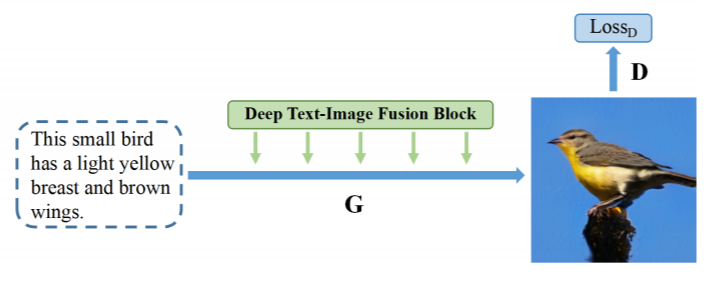
DF-GANではテキスト記述を高解像度の画像に直接変換することが出来ます。
これの何がすごいのかと言うと、既存のtext-to-imageモデルでは重大な問題がありました。それは、モデルが複雑なので学習プロセスに時間がかかり非効率でした。さらに、文章の意味的整合性のために、余分なネットワークを使用しており、訓練の複雑さと計算コストが増大しているという問題がありました。
既存モデルとの比較
既存のモデルは以下の通りになります。
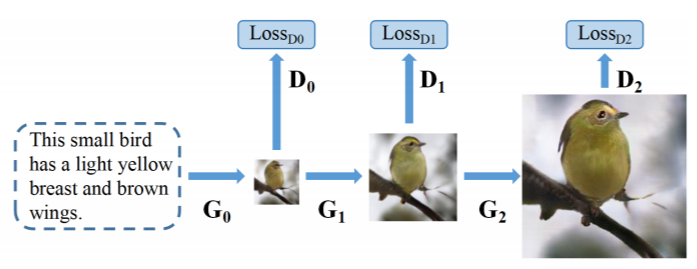
既存のモデルでは,複数の生成器と識別器を重ねて高解像度画像を生成しているため,最終的な結果は,異なる画像スケールの視覚的特徴の単純な組み合わせのように見えてしまいます。
DF-GANの構造
モデルの構造は以下の通りです。
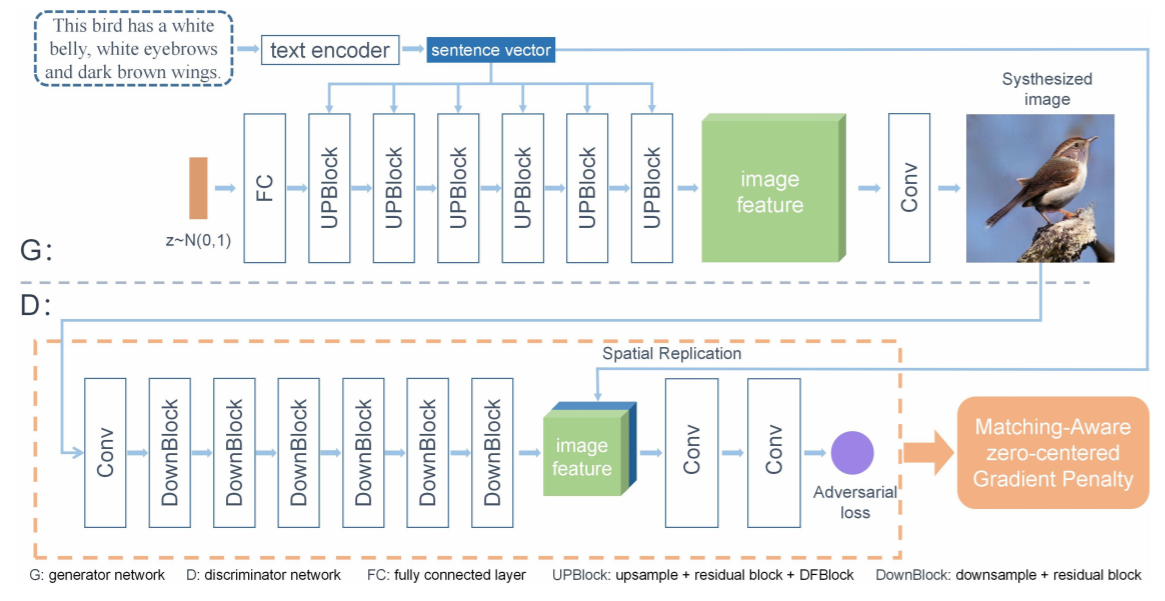
ネットワーク全体は、生成器(generator)、識別器(discriminator)、および事前に学習されたtext-encoderで構成されています。
Generator
本論文でGeneratorはtext-encoderによって符号化された文ベクトルと生成された画像の多様性を確保するためにガウス分布からサンプリングされたノイズベクトルの2つを入力としています。
ノイズベクトルはFCで変換し、UPBlockを適用して画像特徴をアップサンプリングします。
Discriminator
本論文のDiscriminatorは、複数のDownBlockとConvLayerから構成されています。
まず、画像を特徴量マップに変換し、その出力を一連のDownBlockでダウンサンプリングします。
その後、文ベクトルは画像特徴量上で複製され、結合されます。ここで、入力の視覚的リアリズムと意味的整合性を評価するために、敵対的損失の予測を行います。この損失により、生成された画像と実際のサンプルを区別することで、discriminatorはgeneratorがより高品質でテキストと画像の意味的整合性のある画像を合成することができます。
DF-GANの損失関数
DF-GANでは、学習プロセスを安定化するためにヒンジ損失を採用しています。ヒンジ損失はSVMの損失関数で使われるものです。以下の式がDF-GANの損失関数です。
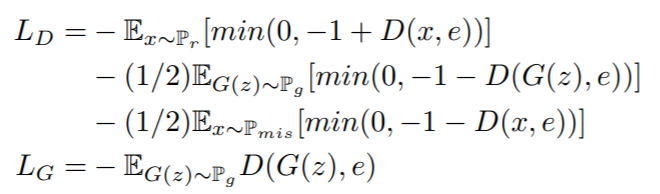
ここで、zはガウス分布からサンプリングしたノイズベクトル、eは文ベクトルです。Pg, Pr, Pmisはそれぞれ合成データ分布、実データ分布、ミスマッチデータ分布を表します。
DF-GANのポイント
DF-GANが高画質かつ意味的整合性を保てているのは以下のポイントがあります。
DF-Block
アフィン変換層、ReLU層、畳み込み層の3つの層から構成されています。
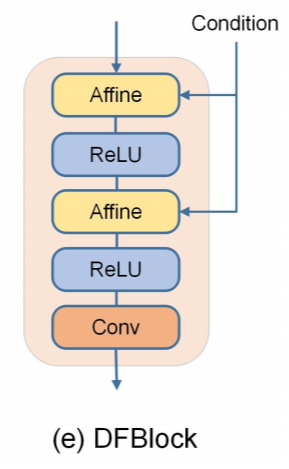
DF-Blockはテキストと画像の融合処理を深くするものです。ニューラルネットワークにとって、ネットワークの深さが深いことは、常により強い能力を意味します。
DF-Blockの利点は
- テキストと画像の特徴を融合させる機会が増え、テキスト情報を十分に活用できるようになる
- 融合プロセスを深めることにより、融合ネットワークがより多くの非線形性を持つようになり、異なるテキスト記述から意味的に一貫した画像を生成するのに役立つ
- 複数のアフィン変換を積み重ねることで、より複雑で効果的な融合処理の実現
の3つがあります。
MA-GP
本論文では、Discriminatorがより現実的なテキスト画像の半矛盾画像を合成できるようにするために、MatchingAware zero-centered Gradient Penalty(MA-GP)を提案しています。
ここでは、まず、明確な観点から、zero-centered gradient penalty (0-GP) を示し、それをテキスト画像生成タスクに拡張します。0-GPは次のように定式化されます。
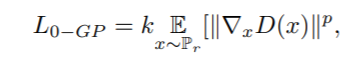
ここで、kとpは勾配ペナルティの効果をバランスさせるための2つのハイパーパラメータ、Prは実データ分布です。
ここで、0-GPを適用した図が以下の通りになります。
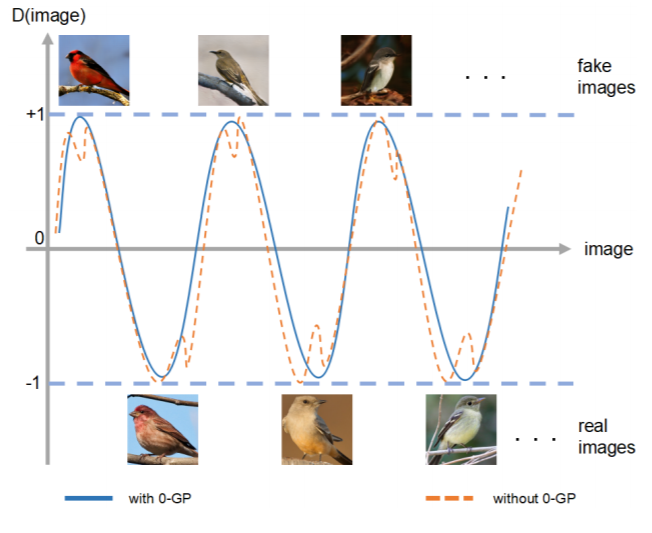
この図に示すように、実画像(real images)は低い識別損失に対応し、合成画像(fake images)は高い識別損失に対応します。ヒンジ損失は識別器損失の範囲を-1~1の間に制限するものであり、0-GPは、実データ点の勾配を小さくして、損失関数面の最小点に押し付ける。これにより、実データ点とその近傍の損失関数面が滑らかになり、generatorの収束に役立ちます。
次にMA-GPの式を下に示します。この式は上で挙げた損失関数に1つ式を足したものになります。

ここで、追加された式はこれまでと同じように、Ex~Prまでの分布からx,eそれぞれについての偏微分を足したものになります。これまでの手法と比較して、MA-GPは、テキストと画像の意味的類似度を計算するために余分なネットワークを使用していません。なぜなら、識別器自体が十分に強力なネットワークであると考えているからです。
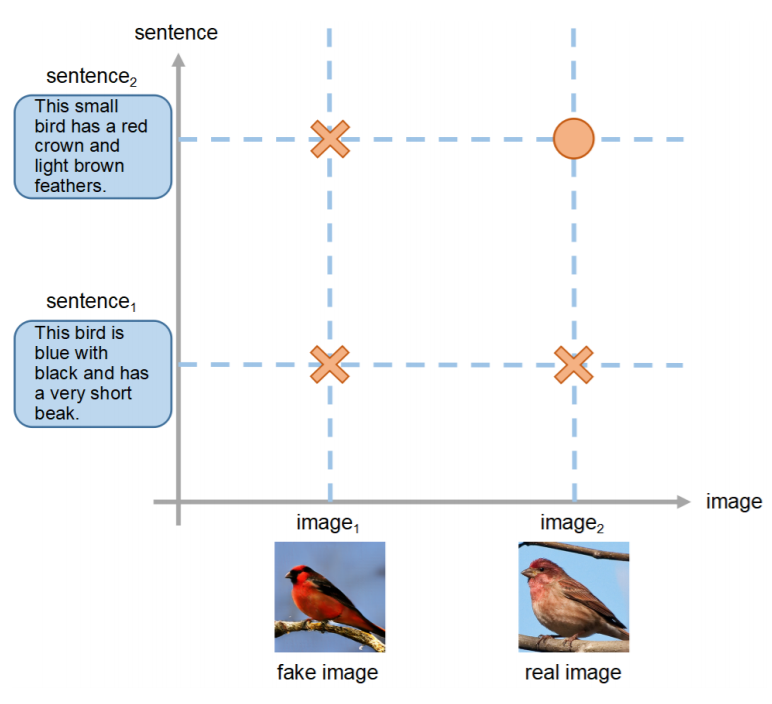
これがMA-GPを適用した図です。テキストと画像の一致、不一致を観測しています。与えられたテキスト記述からテキストマッチング画像とリアル画像を生成するためには、実データ点とマッチングデータ点の滑らかな近傍を確保する必要があります。MA-GPはそれに適していると考えられます。