警告と免責:ここで記載する内容は統計学について参考文献を読みながら勉強したことをまとめたノートであり, 著作物の内容をそのまま残したものも多々あります. オリジナリティ・正統性のある情報の拡散を意図として書いたものではありません.また, 随時更新予定の為, 内容の正当性に関しては保証しかねます.
はじめに
PythonやR, Julia等の言語の強力なパッケージや学習済みモデルを使えば, 誰でも「機械学習」ができるようになると思います.
しかし, 機械学習や統計処理のバックグラウンドとなる統計学の基礎を抑えておかないと, 自分が何をやっているのかがわからないまま, 表示されたモデル改善の指標や数値にただ一喜一憂することになりかねないのではないかと考えました.
表面的なツールの使い方だけを勉強するのは非常に危険だと思います.
そこで, 導入の導入として現代統計学の枠組みを勉強することから始めました. まずは, 現代統計学の**「記述統計」と「推測統計」という二つの側面について, そこから確率モデル**とはなにか・統計モデルとはなにかを把握することを目指します.
1. 記述統計
**記述統計(descriptive statistics)**とは要するに, 手元にあるデータを, 自分達に理解できるような形で要約する技術のことです.
1.1 代表的な統計量
データを要約する様々な指標(平均やバラツキなど)は統計量と呼ばれます.
1.1.1. 一変数統計量
例えとして、教室にいる学生の身長の特徴について知りたいとします.
標本平均
ある学生の身長が155cmだったとき, その身長データを$x_i = 155$と表すこととします. こうして身長を測定して得られた数値は, $x_1, x_2, ... x_n$と表すことができます.
このようにして集められたデータは標本(Sample)と呼びます.このとき, 標本の総和を標本数で割ると, 標本平均(Sample Mean)がわかります.
$$
\overline{X} = \frac{x_1 + x_2, ... + x_n}{n}
$$
標本分散
また, データのバラツキを示す指標として, 標本分散(Sample Variance)があります. それぞれのデータの平均からのズレを二乗して, その平均をとったものです.
$$
Var(X) = \frac{1}{n}\sum_{i}^n (x_i - \overline{X})^2
$$
二乗する理由は, 負のズレも正のズレも平均からの距離として正しくカウントするためです.
標準偏差
標本分散は二乗しているため, もとの単位より極端にズレが強調されてしまいます.
そこで, バラツキをもとの単位で知りたい場合には, 分散の平方根である標準偏差(Standard Deviation)が用いられます.
$$
sd(X) = \sqrt{Var(X)} = \sqrt{\frac{1}{n}\sum_{i}^n (x_i - \overline{X})^2}
$$
1.1.2. 多変数統計量
標本共分散
二つ以上の変数があるとき, それらの間の関係性を知りたいことがあります.
例えば, 身長Xがどれくらい年齢Yに伴って変化しているかを調べたいとします. それは標本共分散(Sample Covariance)によって調べることができます.それぞれのデータについてXからの平均からのズレ, Yからの平均からのズレを掛け合わせて, それらを総和します.
xとyが共に平均以上 or 以下ならプラス, 一方が平均以下で, 他方が平均以上ならマイナスになります. 要するに全体として, XとYが共に変化(covary)しているなら共分散はプラス, 逆向きに変化しているならマイナスになります.
$$
Cov(X, Y) = \frac{1}{n}\sum_{i}^n (x_i - \overline{X})(y_i - \overline{Y})
$$
相関係数
共分散をそれぞれの変数の標準偏差で割ったものを, 相関係数(Correlation Coefficient)と呼ばれます.
$$
corr(X, Y) = \frac{Cov(X, Y)}{sd(X)sd(Y)}
$$
「相関関係を見る」という場合には, 基本的にこの指標のことを指します.
相関係数はつねに $ -1 \le corr(X, Y) \le 1$の範囲におさまるため, 複数の変数間の関係性の強弱を比較する際に便利です. 相関係数がマイナスのとき負の相関, プラスのときは正の相関といいます.
回帰係数
共分散ないし相関係数がゼロから離れていれば, 一方の変化(例えば, 年齢)に伴って他方(身長)も変化していることがわかります. ですが, どのくらい変化するのか, 共分散や相関係数を見るだけではわかりません.
年齢が一つ上がるにつれ, 平均身長はどれだけ上がる or 下がるのか?これに応えるのが回帰係数(Regression Coefficient)です.
$$
b_{x,y} =\frac{Cov(X, Y)}{Var(Y)}
$$
↑をXのYへの回帰係数と呼び, Yの単位あたりのXの変化を表します. 例でいうと, データ上では年齢Yが1増えるごとに, 身長Xは平均して$b_{x,y}$だけ上がっていることになります.
2. 推測統計
記述統計が与えられたデータを要約するための手法だとすれば, 推測統計はそのデータを元に未観測の事象を予測, 推定する技術です.
2.1. 推測統計の考え方
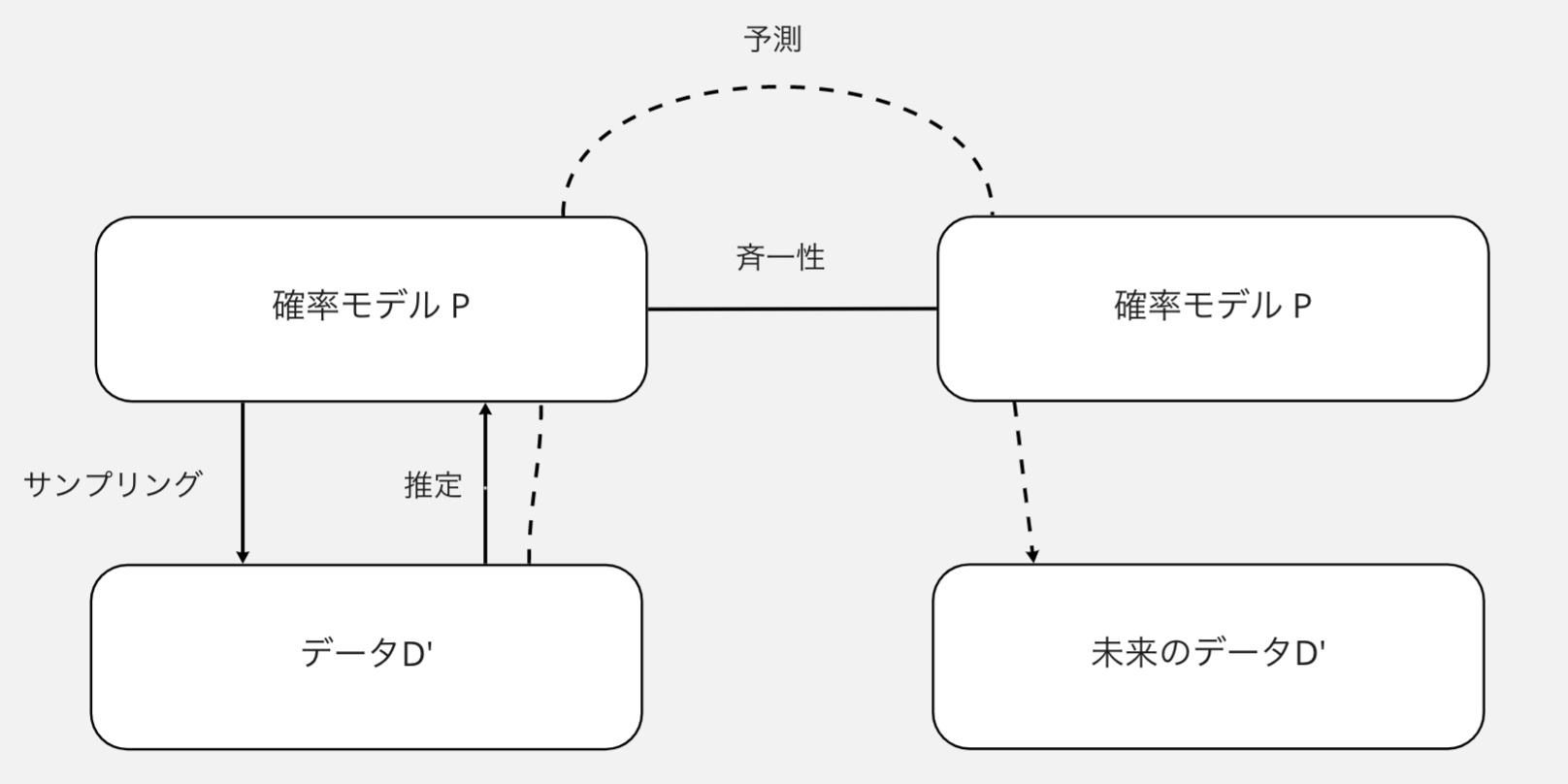
推測統計は上図の枠組みで語られることが多いです.
この枠組みでは, 自分たちが扱うデータはその背後にある確率モデル(probability model)から抽出されたサンプル/標本として捉えなおされます. 抽出はランダムになされるのでサンプルごとに内実は変わりますが, もととなる確率モデル自体は変わらない, という仮定です.
ただ, この確率モデル自体は観測できない(全知全能の知性を持った存在しかできない))ため, 自分たちは手元のデータをもとにそれを推測しなければなりません. そしてそのように推定された確率モデルを媒介として, 未来のデータを予測する. というのが推測統計の考え方です.
この「データをとってくる源」のことを, 母集団(population)あるいは標本空間(sample space)と呼びます.
2.3. 確率変数と確率分布
事象は標本空間(=母集団)の部分集合であることがわかりましたが, 一つ一つの事象に「名前」はついていません.
「サイコロを1回投げて偶数が出る確率」は, $P {2, 4, 6}$と表すことができますが, 「日本国民全員のうち, 18歳以上の有権者のみ」を抜き出したい場合, {20, 21, 18 ... }と列挙するのは面倒です.
そこで, 母集団から(例:「18歳以上の有権者」といった)性質を抜き出す方法として, 確率変数(random variable)という考え方があります.
確率変数を導入することで, 「18歳以上の国民」という部分集合を$Y \ge 18$と表すことができます. 部分集合には当然確率を割り当てることができるので, 全国民を無作為に選び出し, 選ばれた人が18歳以上であるという確率は$P ( Y \ge 18)$と表すことができます.
一般に, ある確率変数$X$について, その値が$x$をとる確率は$P(X = x)$で表されます. 上の例で行けば, $P(X > 18) = 0.83$ は選ばれた人が18歳以上の有権者である確率は83%である, ということを意味しています.
確率変数を導入することで何が嬉しいのでしょうか.
自分たちは大抵, 身長や年齢など, 何らかの属性や性質に関心があります. こうした属性を変数として表すことによって, 確率を変数の値の関数として表すことができます.
確率変数$X$の任意の値$x$に対して確率$P(x)$を与えるこの関数を, $X$の確率分布(provavility distribution)とよび, $P(X)$と表記します.
2.4. 連続確率変数と確率密度
性質によって, 離散値をとるか, 連続値をとるか変わってきます. 身長など, 連続的に変化する特徴は, 連続確率変数によって表すことが適切かもしれませんが, 注意点があります.
例えば, $X$を連続確率変数としたとき, それが特定の実数値$x$をとる確率$P(X = x)$はどれくらいでしょうか.
どれだけ人口が多くても, その身長がぴったり「170.00000....cm」となるような人は1人もいません. 連続確率変数の場合, その値の確率はゼロになってしまいます.
ですが, 例えば身長169cm から 170cm の間の確率はゼロ以上となりうるかもしれません. であれば, この区間をある点へと限りなく狭めていった結果も考えることができます.
これをその点における確率密度(probaility density)といい, 各点$x$に確率密度を与える関数を確率密度関数(probaility density function)と呼びます. 区間の確率は, この確率密度関数をその間で積分することで得られます.
例えば身長の確率密度関数を$f$とすると, 身長169cmから170cmまでの確率は
$$
P(169 \le X \le 170) = \int_{169}^{170} f(x)dx
$$
2.5. 期待値
確率分布は確率変数の値の関数となっています. この関数の全体像は自分たちにはわかりません(標本空間(=母集団)は観測したものだけではなく, およそ起こりうる全ての可能性を含んでいるため).
しかし, 分布を要約する値を考えることはできます. このようなある確率変数が持つ分布を特徴付ける値を, その期待値と呼びます.
母平均
確率分布の「中心」を与えるものとして母平均(population mean; $\mu$)があります.
$$
\mu = \sum_{x}x \cdot P(X=x)
$$
母分散
分布のバラツキは母分散(population variance; $\theta^2$)で与えられます.
$$
\theta^2 = \sum_{x}(x - \mu)^2 \cdot P(X=x)
$$
2.6 大数の法則と中心極限定理
もともとの分布が全く未知であったとしても, 無限にサンプリングをこなせばその平均$\bar{X_n}$の確率分布が特定の範囲(母平均の周辺)に収まります(大数の法則).※詳細は追記する
また, 同一の分布に独立にしたがう$X_1,X_2, ... X_n$の母分散が$\sigma^2$にであるとすると, $n$が無限大に近づくにつれ, 標本平均の確率分布$P(\bar{X_n})$は平均$\mu$, 分散$\sigma^2/n$の正規分布に近いものになっていく.
これを示すのが中央極限定理.
2.7 統計モデル
今までの話を整理すると,
-
手元のデータを超えた推論(例:全国民の平均身長を調査データから知りたい)をするため, 手元のデータの背後に, データを生み出している源として確率モデルを定義しました.
-
任意の事象を表す手段として確率変数を導入し, それが一定の分布を持つことを確認しました.
-
↑の分布は自分たちにとって未知ですが, それを要約するような期待値を考えることはでき, サンプルを数多く集めることによってこの期待値に近づくこと
が確認できました.
無限にデータをとり続ければ最終的には間違いなく真の分布に到達するという理論的なお墨付きをもらいましたが, 自分たちが手にできるのは有限個のデータです.
また, 真の確率分布は非常に複雑で, 有限個のパラメータで表せるものではないかもしれません.
よって, 推測統計では確率モデルにさらなる仮定を加えます. 特定の関数で表すことができる分布を仮定に置くことによって, 有限データでも効果的な推論ができるようにします.
2.8 パラメトリック統計とノンパラメトリック統計
統計モデルの立て方は大きく分けて2種類です.
ノンパラメトリック統計
ノンパラメトリック統計では, 対象となる分布のあり方について具体的な関数型を決めず, 「微分可能性」や「連続性」など非常にゆるい仮定だけを立てます.
パラメトリック統計
パラメトリック統計では, 対象となる分布がどのような形をしているかまでを具体的な関数型によって特定します. この分布の形の種類を分布族(family of distributions)と呼びます.
パラメトリック統計の方は具体的な関数型まで特定するので, 現実を歪めてしまうリスクが高いですが, 適切に分布族を定めることができればより詳細で効果的な推論が可能です.
2.9 代表的な分布族
一様分布
ある確率変数$X$がとりうる値$x_1, x_2, x_3 ...$にすべて同じ確率を割り当てる分布を一様分布(Uniform distribution)と呼びます.
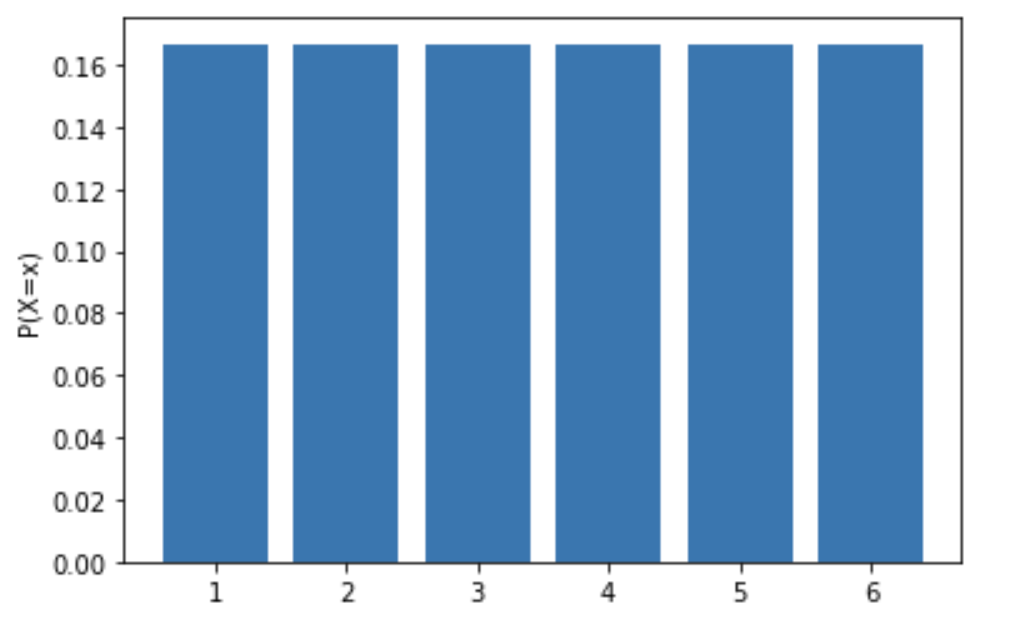
例:公正なサイコロのそれぞれの目が出る確率は$P(X = x) = \frac{1}{6}$の一様分布です.
また, $X$が$\alpha$から$\beta$までの連続値をとる場合, その一様分布は
$$
P(X=x) = \frac{1}{\beta - \alpha}
$$
の式で表されます.
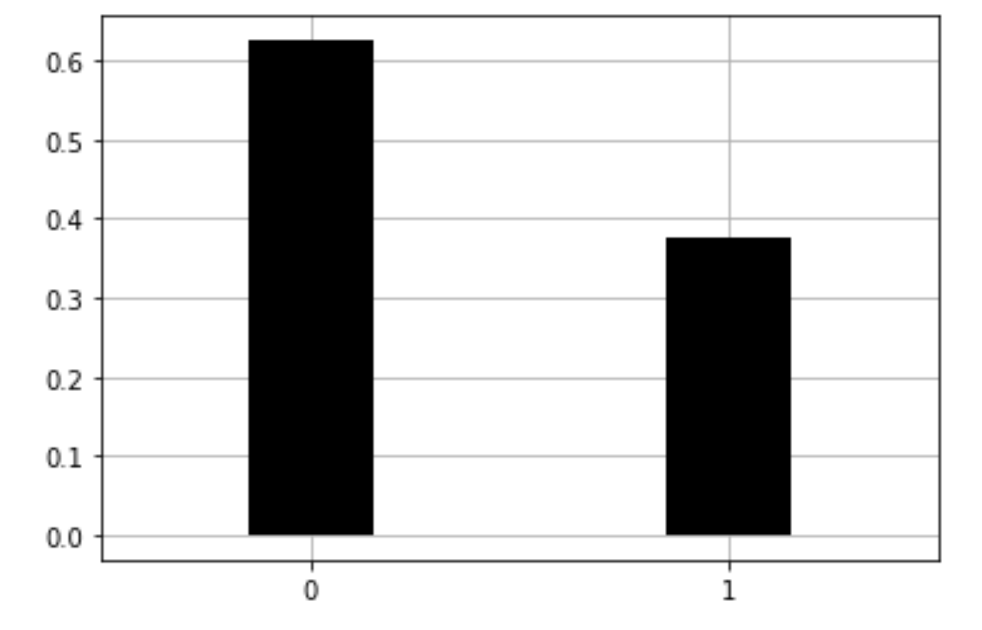
ベルヌーイ分布
コインを1回投げる結果を確率変数$X$で表し, 裏を$X=0$, 表を$X=1$のようにします. 表が出る確率が$P(X=1)=\theta$とすると, $X$の分布は
$$
P(X=0)=\theta^x (1-\theta)^{1-x}
$$
となり, このとき$X$はベルヌーイ分布(Bernoulli destribution)に従います.
二項分布
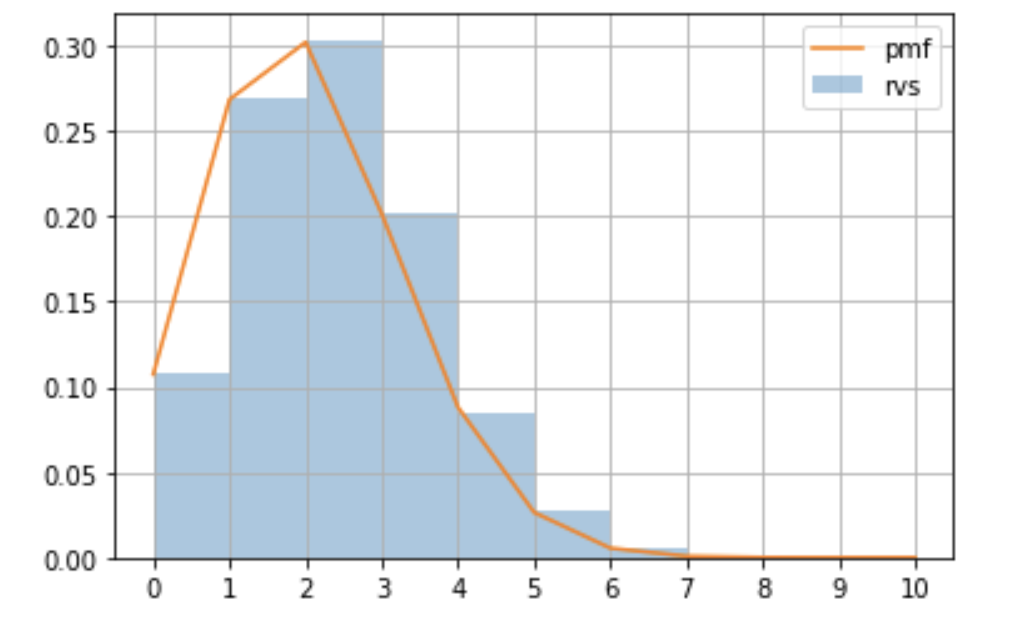
コインを1回ではなく, 複数回連続して投げて, 表が出た回数を記録する実験を考えます.
$n$回のコイン投げで表が$x$回出る確率が与えられ, こうして得られる分布を二項分布(Binomial distribution)と呼びます.
$$
P(X=x)= {}_n C _x \theta^x (1 - \theta)^{n-x}
$$
正規分布
データが平均値の付近に集積するような分布を表し, 確率密度関数は平均$\mu$と分散$\sigma$の二つのパラメータを持った次のような式で表します.
$$
f(x) = \frac{1}{\sqrt{2\pi \sigma^2}} \exp \left(-\frac{(x - \mu)^2}
{2\sigma^2} \right) \hspace{20px} (-\infty < x < \infty)
$$
正規分布は様々な統計的推測で使用されます. 正規分布 $N( \mu , \sigma^2)$からの無作為標本$x$を取ると、平均$\mu$からのずれが $\pm 1$ 以下の範囲に$x$ が含まれる確率は 68.27%、$\pm 2 \sigma$ 以下だと 95.45%、さらに $\pm3 \sigma $だと 99.73% となります.
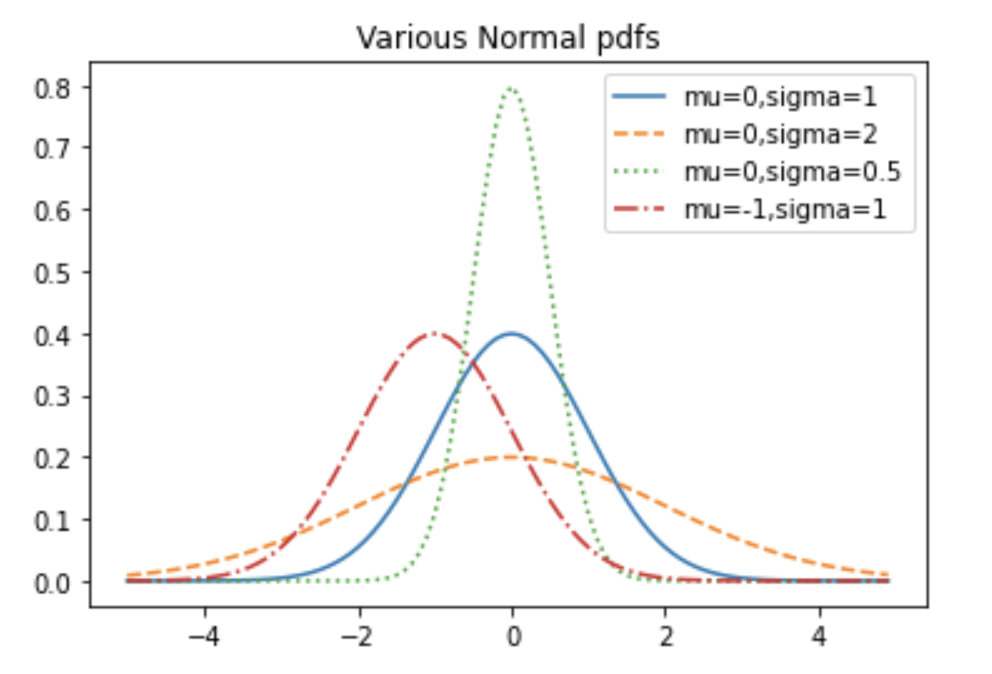
また, $\mu = 0$, $\sigma^2=1$の場合, 標準正規分布と呼ばれます.
確率密度関数は
$$
f(x) = \frac{1}{\sqrt{2\pi}} \exp \left(-\frac{x^2}
{2} \right) \hspace{20px} (-\infty < x < \infty)
$$
で表されます.
標準正規分布は正規分布$N(\mu, \sigma)$ に従う確率変数$X$が与えられたとき
$$
Z = \frac{X − \mu}{\sigma}
$$
と標準化すれば確率変数 $Z$ は標準正規分布に従います. $Z$値を求めることで標準正規分布表と呼ばれる変量に対応した確率を表す一覧表を用いて, コンピュータを使うことなく正規分布に従った事象の確率を求めることができます.
参考文献
- 大塚淳(2020) 『統計学を哲学する』名古屋大学出版会.
- 南風原朝和(2002)『心理統計学の基礎―統合的理解のために』有斐閣アルマ.