はじめに
目的
本記事の目的は、オープンソースで開発されているGraphQLサーバーHasura GraphQL Engine(以下、特別な文脈がない限りHasuraと表記)の概要について紹介することです。
筆者はここ半年ほど、業務・プライベートの開発でHasuraを使用しています。Hasuraを一通り触った段階で、自分の知識の整理と、まだまだ少ない日本語情報の充実の一助になればという動機で本記事を公開しました。
本記事を通して
- 「聞いたことはあるけど、日本語情報が少なくてよく分かっていない」
- 「技術選定の判断軸として、他事例を元に便利/つらみポイントを把握しておきたい」
という方の参考になれば幸いです。
構成
本記事は、以下のように構成されています。
- 前半:Hasura公式ドキュメントの内容を交えて、Hasuraの概要について簡単に述べた内容
- 後半:筆者の開発・運用体験に基づいてメリット・デメリットをまとめた、いわゆる「使ってみた」内容
目的に応じて、読む必要のある部分を選択してください。
対象読者
本記事の対象となる読者は、以下に当てはまる方々です。
-
Hasuraとは何かを把握したい方
-
Hasuraを使用するメリット・デメリットを知りたい方
以下に当てはまる方は、本記事はご期待に添えない内容となっています。
-
GraphQLとは何かを知りたい方
-
Hasuraを使ったサンプルや、チュートリアルを学びたい方
GraphQLの概要について知りたい方は、CircleCIブログ GraphQL 入門ガイド等の記事をご参考ください。また、Hasuraを使ったアプリケーションのサンプルコードやチュートリアルを学びたい方は、Hasura公式ドキュメントが参考になります。
こちらの公式ドキュメントはかなり内容が充実しており、チュートリアルも豊富に用意されています。Hasura単体でのチュートリアルに加え、各種言語・ライブラリとセットになったチュートリアルも用意されているので、自分の技術スキルと合わせた内容を選んで学ぶことができます。
Hasuraとは
Hasuraは、PostgreSQLなどのデータベースエンジンのスキーマからGraphQL APIを構築してくれるオープンソースエンジンです。似たようなミドルウェアに、PostGraphileがあります。Hasuraの提供元はサンフランシスコに本社を置くスタートアップのHasura社で、直近では2020年にシリーズBで26億5500万円の調達1をしたことが話題となり、非常に今後の成長が期待されています。
Hasuraのコアとなる機能はオープンソースで開発されているため、誰でも無料で使用できます。また、本記事では扱いませんが、本番環境に必要な機能が一通り揃ったSaaS版のHasura Cloudもあります。こちらも基本は無料で使用可能で、プロダクト規模に応じてカスタマイズしていく形になります。
さて、現在のWeb開発においてGraphQLサーバーを構築するには
-
ライブラリを使用して自分でGraphQLサーバーを書く
-
マネージドサービスを使用する
などの方法があります。具体的な例では、前者はNode.jsならApollo・Goならgqlgenといったライブラリ、後者はAWS AppSyncなどが挙がります。これらの技術と比較して、Hasuraを選ぶ理由を一言でまとめると、**"セキュアでハイパフォーマンスなGraphQL APIを迅速に構築できる"**点にあります。
次章では、他の技術と差別化を図るために、Hasuraがどのような問題を解決しようとしているのか・その問題に対してどのようなアプローチをしているかを紹介します。
Hasuraのデザイン哲学
Hasura公式の記事**「Hasura Design Philosophy」**では、Hasuraの技術設計や技術アプローチについて説明されています。
ここでは、Hasuraが必要とされる背景や、解決しようとしている問題について理解するために、記事中のいくつか重要なトピックをかいつまんで説明します。
ここに記載している内容は「Hasura Design Philosophy」を筆者が独自解釈したものになります。
翻訳の許可等は頂いておりません。オリジナルの記事は参考記事として本文中にリンクとして記載しているので、原文をお求めの方はそちらを適宜ご参照ください。
Hasuraは何を解決しようとしているのか
Hasuraは最近の技術の進化において、対処すべき主要なボトルネックはデータへのアクセスだとしています。特に、過去数年間の技術トレンドに見られる重要な傾向は以下の2点と置いています。
- **運用データは単一のデータソースではない。**Saasや内部サービスなど、複数のソースにまたがって構成される
Data is no longer in a single data-source. Operational data is increasingly split across multiple sources viz. workload-optimised databases, SaaS solutions and even internal services
- 開発者は、安全でなく無許可&ステートレスで同時実行のコンピューティング環境でデータを消費している
Developers are consuming data in insecure & unauthorized compute environments (eg: web/mobile apps) and increasingly stateless & concurrent compute environments (eg: web/mobile apps, containers, serverless functions).
このような背景において、現代のWeb開発者は以下の条件を満たすようなAPIを構築する必要があります。
-
複数のデータソースに接続
-
ドメイン固有のロジックを吸収
-
セキュリティとパフォーマンスを担保
しかし、上記を実現するためには膨大なテーブルをマッピングするコードを書いたり、承認のルールをロジックに埋め込んだりする面倒な作業が必要になるため、開発者の多くの時間を浪費してしまいます。
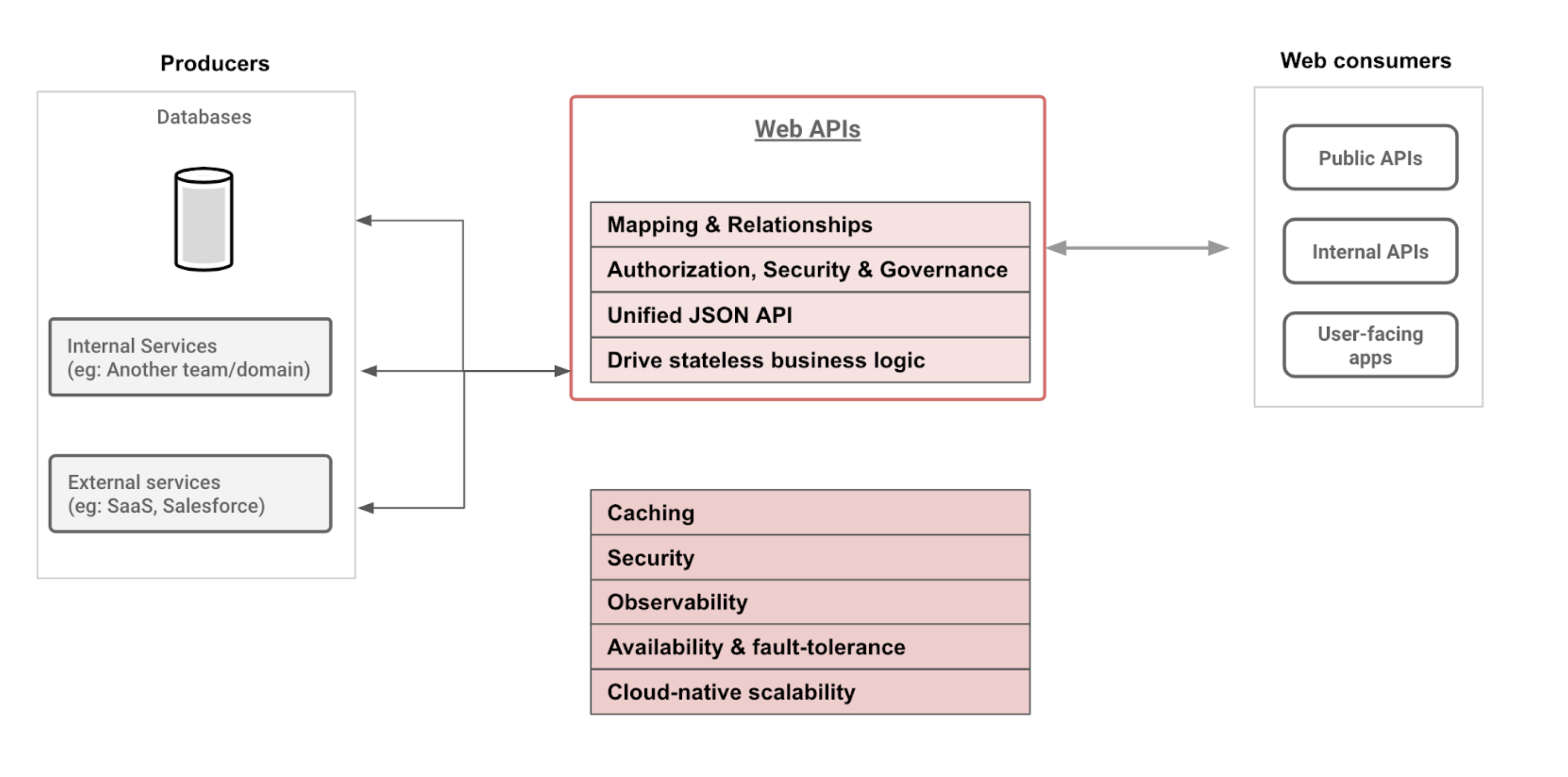
Hasuraは、このようなAPI構築にかかる作業をサービスとして提供することで、時間の無駄を解消しアプリケーションの構築を迅速にすることを目指しているようです。
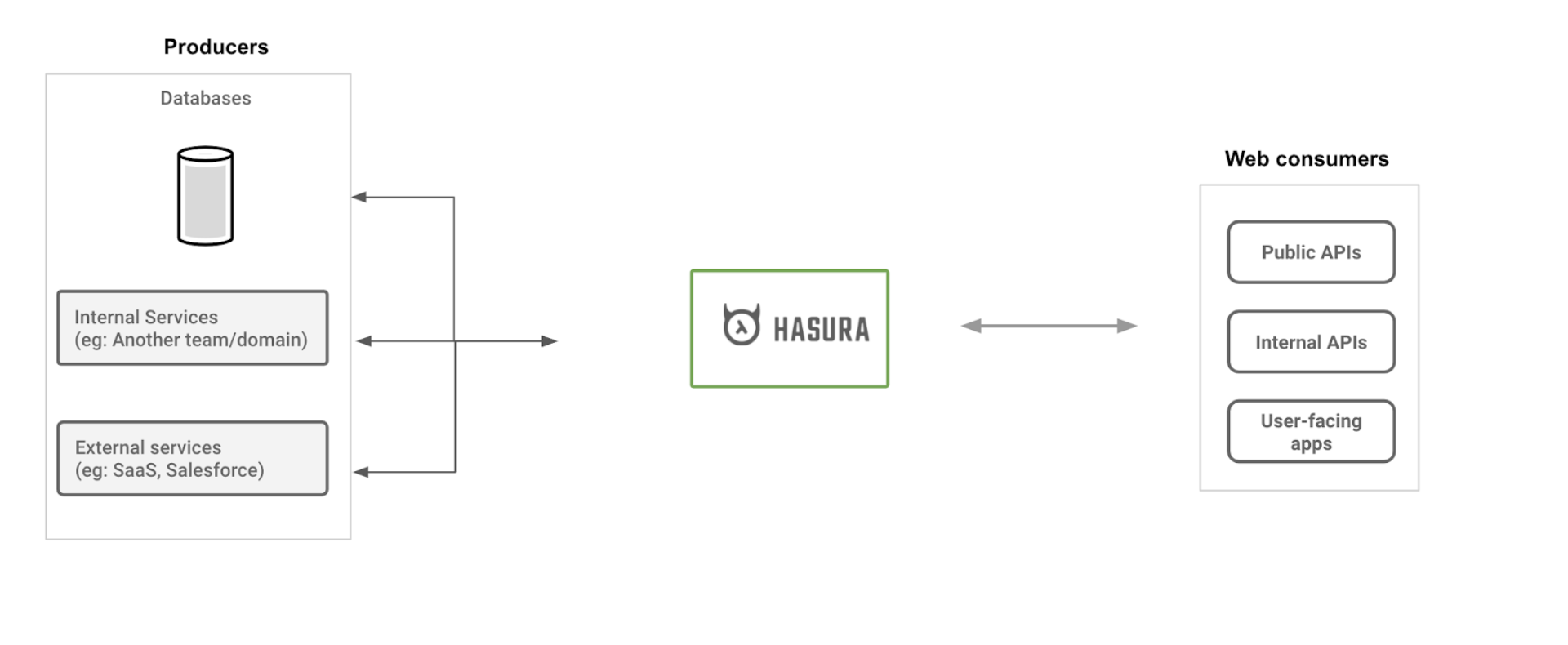
※図はHasura公式ブログの記事より転載。
Hasuraの技術的アプローチ
Hasuraのアーキテクチャは、データベースシステムに影響を受けています。Hasuraでは、GraphQLスキーマの情報や認証情報が入ったメタデータを読み込むことで、GraphQLサーバーを起動できます。これは、データベースエンジンがメタデータ2を読み込むことで、開発者が作業することなくデータベースサーバーをサービスとして起動できるところから着想を得ているようです。
Hasuraの記事中では、"ウェブ層で動作する分散データベースエンジンのフロントエンド"として、Hasuraを表現しています。
A convenient way to think about Hasura is that it is the frontend of a distributed database engine that works at the web-tier to support
もっと具体的な表現としては、「もうAPIを自分で開発するのは古い?Hasuraの強烈な有効性について紹介する」の執筆者の方の記述を引用すると、"フロントから呼べるSQLクライアント"3が適当だと思います。HasuraはPostgresやBigQueryなど、様々なデータベースをサポートしており、それぞれのアーキテクチャも多種多様です。
Hasuraは、これらの異なるデータ操作処理(SQL等)の差異を吸収・秘匿し、GraphQLスキーマの形で扱えるように変換することで、フロントエンドから簡単に様々なデータを扱えるようにしています。
Hasuraの便利な点
ここからは、筆者が業務・プライベートそれぞれでHasuraを半年ほど実際に使用してみて、感じたメリット・デメリットを述べていきます。
基本的なリゾルバは工数0で作成可能
他の技術と比較して、大きくメリットを感じるのはこの部分です。
Hasuraでは、データベースのテーブルを定義するだけで、基本的なCRUDのGraphQLリゾルバを作成してくれます。それだけでなく、集計用のリゾルバ(aggregate)やupsert mutationも自動で用意してくれるので、複雑な処理がなければ工数ゼロでAPIの開発ができることになります。
Hasuraの"API構築にかかる面倒な作業をなくす"という思想が最も如実に表れている機能です。
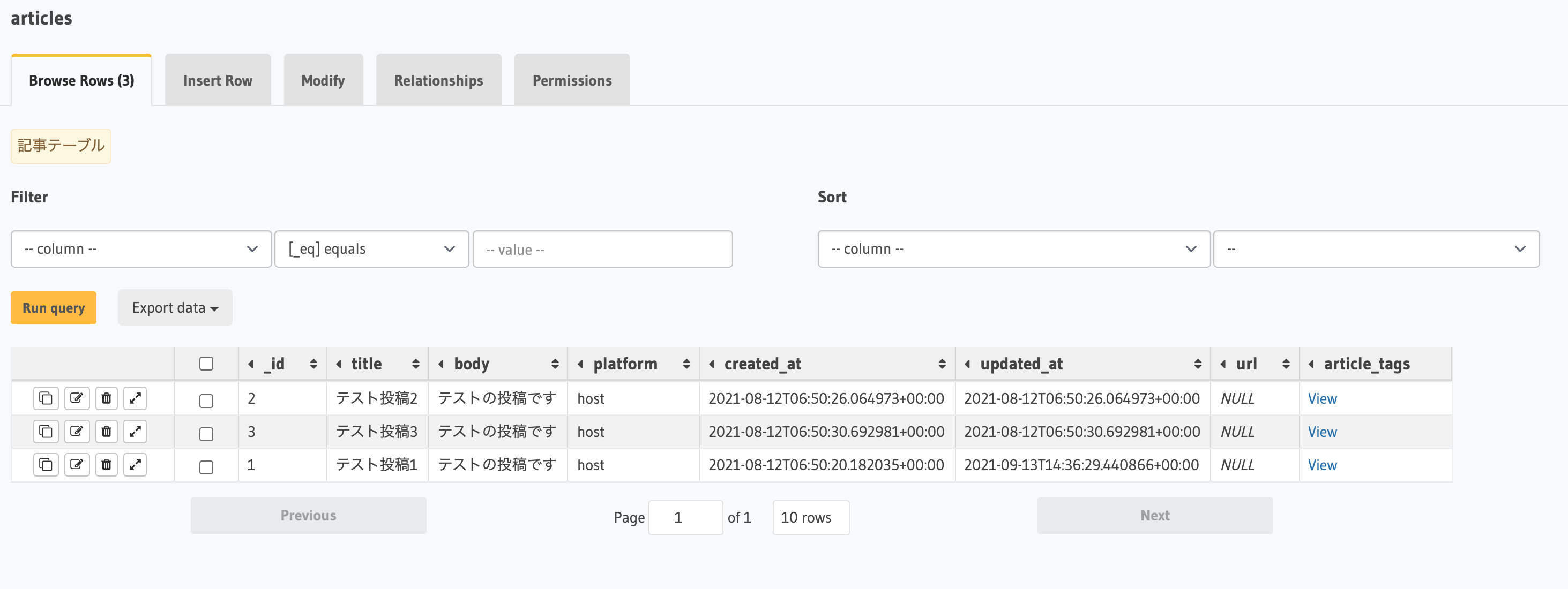
DB操作(マイグレーション管理・シードデータ適用など)がHasura上で完結する
マイグレーションは何らかのO/Rマッパーを使用することが多いですが、Hasuraでは付属しているWebコンソール画面でテーブル・カラムの作成・編集が可能です。また、SQLエディタが用意されているのでSQLを書いたり、データの閲覧・追加・削除も全てこのWebコンソール画面で完結できます。
ただ、この運用だとマイグレーション履歴が手元で把握できません。マイグレーション履歴を管理したい場合はHasura CLIというコマンドラインツールを使うことになります。Hasuraは、マイグレーション履歴やカラムごとの権限・Hasura Action(後述)等の情報をメタデータとして管理しています。Hasura CLIでこのメタデータをインポート・エクスポートすることで、Gitでマイグレーション履歴の管理ができます。
また、シードデータを作成するSQLファイルを用意しておけば、コマンド一発でシードデータの流し込みができるhasura seed apply機能など、Hasura CLIには便利な機能が一通り揃っています。
認証・認可機能が組み込みでサポートされている
Hasuraには、認証・認可機能が組み込みでサポートされています。この機能がかなり便利で、テーブルのカラムや、Hasura Actionのクエリ(後述)単位でのCRUDの許可・不許可を細かく設定できます。
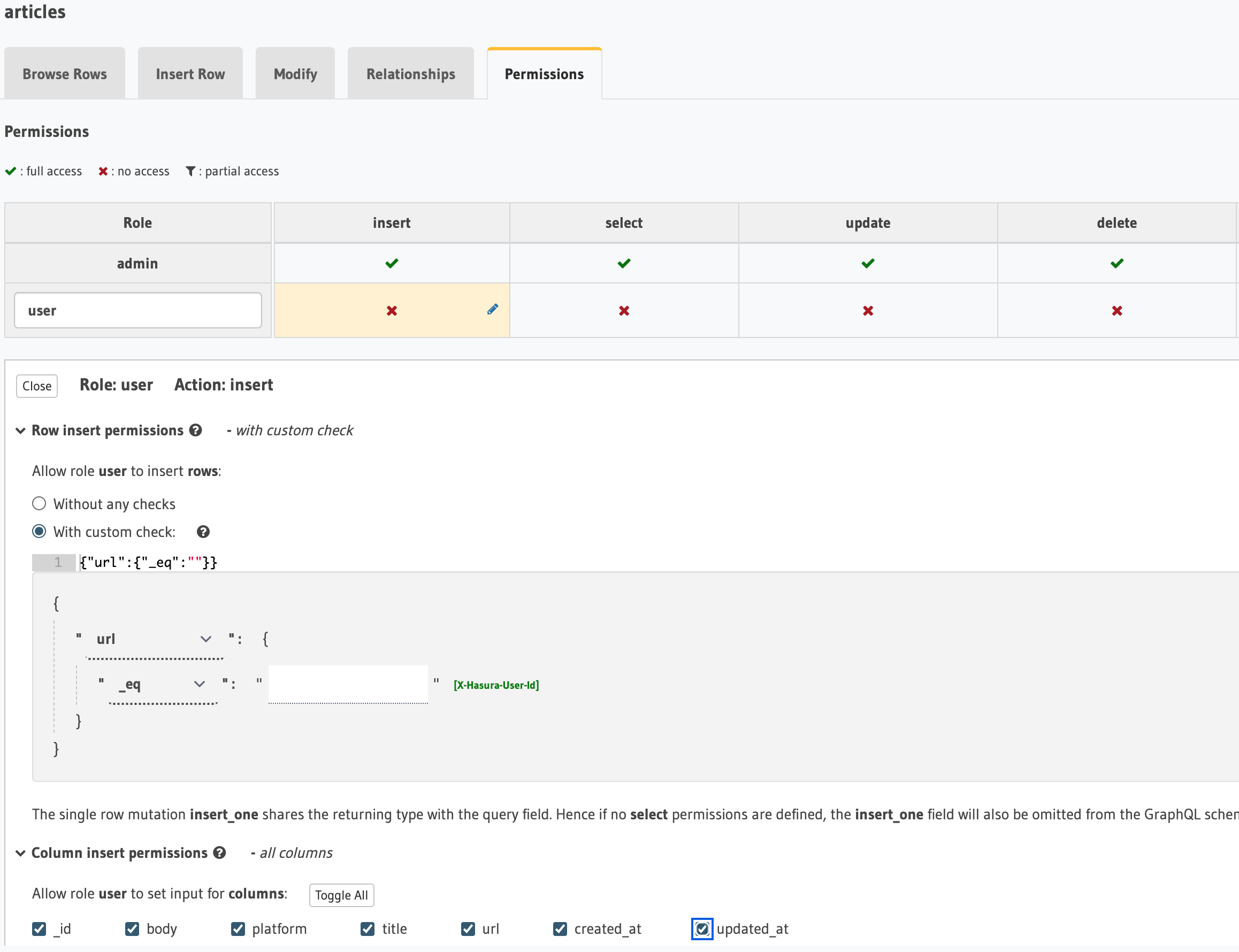
他認証サービスとの相性も良く、Firebase Authenticationの例を挙げると、Firebaseの認証情報(UID)とUserテーブルのIDが一致しているデータのみ、UPDATEを許可するといった細かな認証認可の仕組みも簡単に実現ができます。
ビジネスロジックは外部APIで拡張可能
基本的なCRUDは自動作成されることを先に述べましたが、〇〇の処理結果を□□と計算して返したいといったカスタムロジックを組み込むには、Hasura Remote Schema・Hasura Actionという機能を使います。
前者はGraphQL API・後者はREST(ful) APIに対応しており、どちらも外部APIの処理結果をスキーマとして埋め込む機能です。そのため、フロントエンドで「この部分では既存のREST APIの処理を使いたい」「この部分ではGraphQL APIを叩く必要がある」という場合に複数のAPIを叩く必要はなくなり、全てHasuraのエンドポイントにまとめることが可能です。
その裏返しとして、Hasuraが単一障害点となるため、運用には注意が必要です。
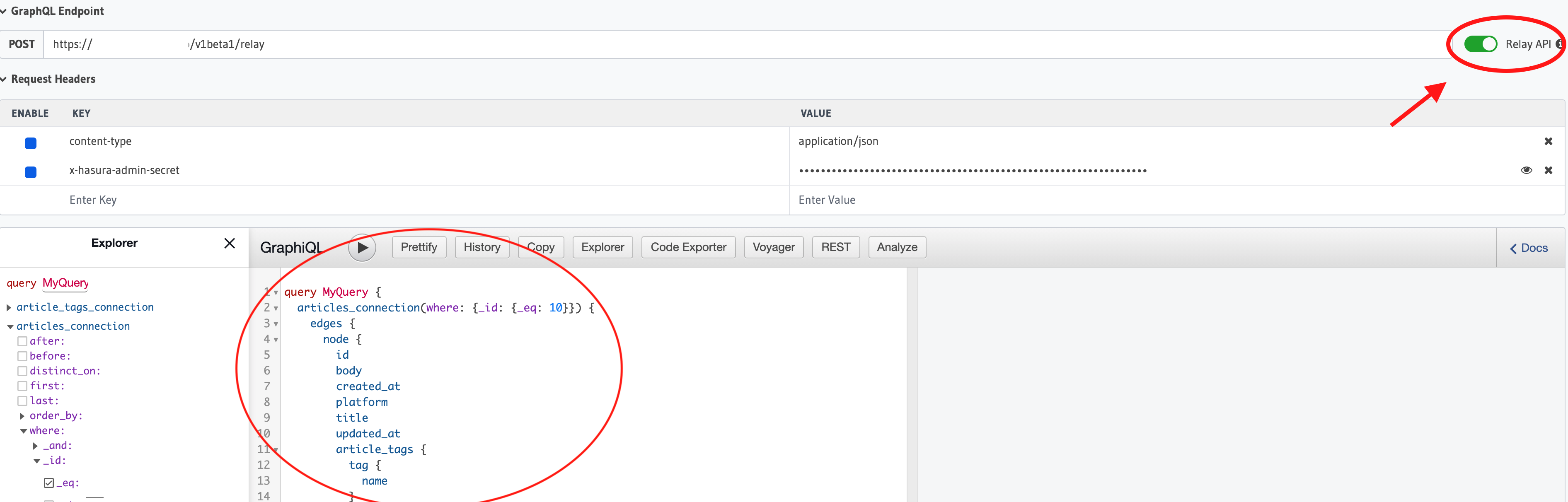
Relayがサポートされている
Beta版ですが、効率的なデータの再取得とページネーションのGraphQLのベストプラクティスである、RelayのGraphQL Server Specificationもサポートしています。
コンソール画面のRelay modeスイッチボタンを押すと、DBテーブルから自動生成された型がそれぞれNodeインターフェースに準拠した型へ変換され、cursorフィールドも自動生成されます。このとき、それぞれの型のIDはユニークな識別子(Nodeインターフェースのidフィールド)に自動変換されています。
Hasuraを使う上での注意点
ここからは、筆者が実際に使ってみて感じたデメリットや、運用に工夫が必要な点について紹介しています。
以下に述べる内容は、この記事を執筆した2021年9月時点のものです。Hasuraのアップデートに伴い加筆修正していきますが、実際と異なる記述になっている場合があります。
それぞれ関連Issueを付しておりますので、最新状況は適宜リンク先の対応ステータスをご参照ください。
MySQLのサポートがプレビュー版
Hasuraと接続するデータベースは、2020年9月現在、以下がサポートされています。
- Postgres
- MS SQL Server
- Citus / Hyperscale
- BigQuery
MySQLはサポートされていません。現在、プレビュー版が公開されていますが、MySQLのバージョンが8.0.14以降のみのサポートとなっています。また、プレビュー版ではDBスキーマからのCRUDのリゾルバの自動作成&APIを試すことはできますが、コンソール画面でのマイグレーション・データ操作はできません。
このMySQLサポートの状況はプルリクエスト#5655 (Draft)で確認ができます。
Relayモード(Beta版)での一部機能制限
先に述べたRelayモードですが、現在その使用方法にはいくつか制限がかかっています。
Hasura Actionが使用できない
まず、Remote Schema・Hasura Actionで作成したスキーマはrelayモードでは公開できません。そのため、relayモード時はHasuraが自動生成したCRUDのスキーマしか使用できず、カスタムロジックは使用できません。
関連issue: #4703・#5088
ただ、対応漏れなのかどうかが定かではないのですが、なぜかMutationタイプのHasura Actionのスキーマはrelayモードでも使用できます。そのため、裏技的でGraphQLの設計に反する形ではありますが、全てをMutationタイプのHasura Actionとしてロジックを記述してしまえば、強引にrelayモードでも使用できます。
トップレベルのクエリではaggregate(集計)スキーマが使用できない
また、トップレベルのクエリではaggregate(集計)スキーマが使用できないという制限もあります。対象のテーブルに紐づく子テーブルの集計はできますが、対象のテーブルのカラムの集計はできないため、注意が必要です。
例:Userに紐づくItemの集計(そのユーザーのItemの最小値取得)はできるが、トップレベルでのItemの集計ができない
query MyQuery {
users_connection(where: {name: {"testUser1"}}) {
edges {
node {
items_aggregate {
aggregate {
min {
Likes
}
}
}
}
}
}
}
query MyQuery {
items_aggregate { // 公開されないため使えない
}
}
Hasura Actionの接続先APIにかかる制限
REST(ful)APIと自由に繋ぐことができる便利なHasura Actionですが、いくつか制限があります。
入れ子構造になった返り値のスキーマを定義できない
2022/02追記
Hasura v2.2.0のリリースにより、入れ子構造になった返り値を返せるようになりました!
詳細は以下を参考にしてください。
マイグレートとメタデータ操作の運用
Hasuraと接続したDBのマイグレーションを行うには、
-
Hasuraコンソール上でテーブル・カラムを編集
-
マイグレートのSQLファイルを用意し、
hasura migrate applyでマイグレート情報をGraphQL Engineにインポート
の2通りの方法があります。
多くの場合、前者の方法でマイグレーションを行い、マイグレーションファイルをローカルでGit管理する方法になります。しかし、「カラムを1つ追加」「型を変更する」という単位でマイグレーションが発生するため、自動的にマイグレーションファイルがどんどん作られてしまいます。
例:「テーブルAに間違った名前でカラムを作成したあと、正しい名前に修正する作業を行なった」場合、以下の4つのファイルが作られる
-
間違ったカラム名にするマイグレーション(
xxx_up.sql・xxx_down.sql) -
間違ったカラム名を修正するマイグレーション(
yyy_up.sql・yyy_down.sql)
そのため、綺麗なマイグレーション履歴にするためには、migrate squashという複数のマイグレーションを1つにまとめるコマンドを使用して、都度適切な粒度にする作業が発生します。
まとめ
ここまで、Hasuraの概要及びメリット・デメリットについて説明しました。
認証認可やCRUD・集計リゾルバの開発コストが全くかからないため、小〜中規模プロジェクトの開発においては、かなり恩恵を得ることができます。特に、複雑なロジックが多く絡まない場合は、自分で1から書く場合と比較して、9割ほど工数が削減できるでしょう。
また、公式ドキュメントが充実していて、ドキュメントを読めば機能が大体把握できることも、大きなメリットの1つです。
一方、いくつかデメリットがあります。Hasura ActionやRelay modeの機能が不十分なことから、
- Hasura Actionでスキーマをガンガン拡張する
- RelayのGraphQL仕様に乗っ取った構成にする
のは避けた方が良いでしょう。とはいえ、精力的に開発が行われており、一週間単位でパッチアップデートが行われるなどリリースサイクルはかなり早いため、デメリットが改善される見込みは高いです。
総じて、Hasuraは多機能なGraphQLサーバーという印象です。技術記事の増え方や開発コミュニティの盛り上がりを見ると、これからどんどん使用人口が増えていくと感じました。個人・社内サービスの採用技術の候補の1つとして、チェックしてみてはいかがでしょうか。
コメントや編集リクエストによるアドバイス・間違い修正等大歓迎です。
引用・参考情報
-
"Hasura raises $25 million Series B and adds MySQL support to its GraphQL service", Tech Crunch September 9, 2020 ↩
-
データを管理するためのデータのこと。
Postgresだとシステムカタログやpg_controlファイル、OID/XID/TIDなどがそれにあたる(参考:https://www.postgresqlinternals.org/chapter3/ ) ↩ -
https://qiita.com/yuno_miyako/items/4a4f68a473231f8c07cd#:~:text=%E3%81%A7%E8%A8%80%E3%81%86%E3%81%A8%E3%80%8C-,%E3%83%95%E3%83%AD%E3%83%B3%E3%83%88%E3%81%8B%E3%82%89%E5%91%BC%E3%81%B9%E3%82%8BSQL%E3%82%AF%E3%83%A9%E3%82%A4%E3%82%A2%E3%83%B3%E3%83%88%E3%80%8D,-%E5%AE%9F%E9%9A%9B%E3%80%81Hasura%E3%81%AF ↩