この記事について

機械学習モデルを作成してみたけど、そのモデルを説明しようか?
そんな課題に応えてくれそうな、Shapashというツールを触ってみたいと思います。1
- github
- live demo
本記事では、ツール概要を説明しています。
可視化の詳細は別途、下記にまとめていますので、ご確認ください。
また、2021/01にv1.0として出たばかりのツールなので、まだ情報もあまり多くない状況です。
Qiitaに情報が色々集まれば良いな〜と。
何が表示できるか
どんな表示ができるか?を不動産価格予測のデータを例に説明していきたいと思います。
重要特徴量と予測への貢献度
作成した機械学習モデルに対して、下記を表示することができます。
- 特徴量の重要度(予測に貢献している列)を表示するとともに、
- その列の中で、どんなレンジのデータが、どういった予測値(不動産価格)となるか?
- また、予測精度に対してどれだけ貢献できているか?

また、表示領域のZoomと、個別項目の表示を行うこともでき、
各セグメントの詳細(データの値、予測値、予測への貢献度)を確認することも可能です。

フィルタリングによる絞り込み
データに対して絞り込みを行い作成したセグメント対して予測の傾向を確認することもできます
下記は、下記のような操作を行っています。
- BldgType:「Townhouse」を含むで絞り込み
- Feature Importanceの上位特徴量のみを表示して、
- 第1,2位の特徴量について、「全体 vs 部分集合」で傾向がどう異なるか確認

Shapashは、何をしているか?
Shapashは データの前処理はしませんし、機械学習モデルも作成しません。
機械学習に必要な手順1~5の情報を収集し、機械学習モデルを見える化するのがShapashです1
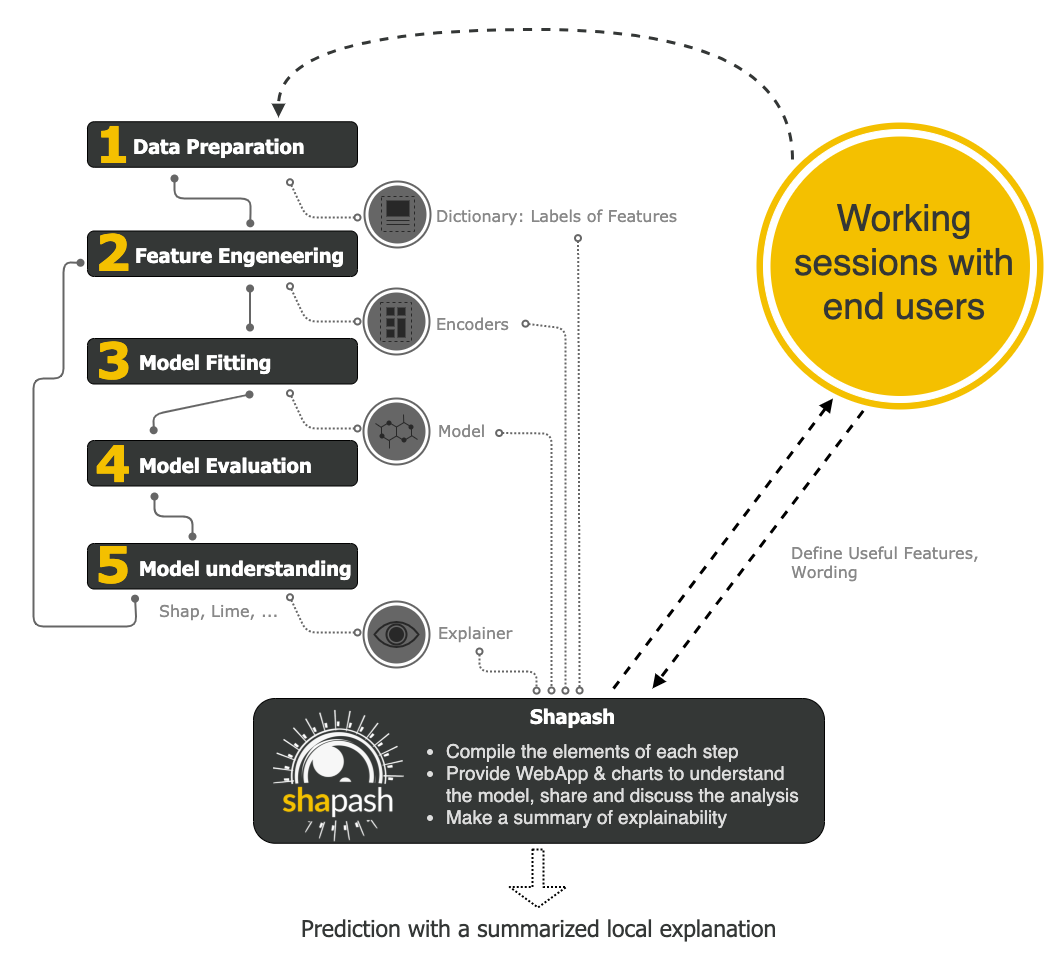
具体的に見ていくと、
①Data Preparation
学習データは列名以外に、列の説明を持っていることが多いと思います。
学習用データ作成時は、列の説明は不要ですが、モデルを考察するには重要な情報です。そこで
Shapashは、特徴量を表示する際に、列名を下記のように、説明文に変換し項目を表示します。
- OverallQual(列名) → Overall material and finish of the house(列説明)
- OverallCond(列名) → Overall condition of the house(列説明)
②Feature Engineering
一般に学習データは、機械学習モデルで扱うためにカテゴリ値→数値のエンコードを行います。
- New York(元データ) → 0001(数値、エンコード後)
一方、モデルを理解する際には、0001では何のことかさっぱりわかりません。
そこで、それらのデータは逆変換(デコード)し表示したいと言うのが一般的かと思います。
- 0001(数値) → New York(元データ、デコード後)
Shapashは、エンコードに利用したencoderを渡すことによりデータをデコードし表示します。
③Model Fitting & ④Model Evaluation
作成したモデルをShapashにわたすことで、下記を可視化しインタラクティブに確認できます。
- どの特徴量が予測に効いているか?(Feature Importance)
- その特徴量の中でも、どのセグメントが予測に対する貢献度が高いか?(Feature Contribution)
- その特徴量のデータで、モデルに対して+/-どう影響するか(Local Explanation&Filter)
⑤Model Understanding
Feature Importanceよりもより具体的にどういった説明変数のどういった値が予測に影響しているかを確認する目的で、SHAPやLIMEといったメトリックスを計算することがあると思いますが、これらを取り込むみ表示する事ができます。
- SHAP : SHapley Additive exPlanations
- LIME : local interpretable model-agnostic explanations
動かしてみる
インストール
インストレーションガイドはこちらにあるのですが、簡単に手順を整理すると、
まずは、pipしていただき、
pip install shapash
各環境に合わせて、ウィジェットのextensionをインストールしてください。
手順は、たとえば、jupyter-lab3ならこちら
チュートリアルを動かす
学習モデルを作るまで
下記チュートリアルに従って、動かして見たいと思います。
- https://github.com/MAIF/shapash/blob/master/tutorial/tutorial01-Shapash-Overview-Launch-WebApp.ipynb
パッケージのImport
import pandas as pd
from category_encoders import OrdinalEncoder
from lightgbm import LGBMRegressor
from sklearn.model_selection import train_test_split
from sklearn.ensemble import ExtraTreesRegressor
データのロード
- house_dfには、不動産価格予測に必要なデータが
- house_dictには、データの各列の説明
が入った状態となります。
機械学習にはhouse_dfを使いますが、Shapashでの表示にはhouse_dictを利用します(後述)
from shapash.data.data_loader import data_loading
house_df, house_dict = data_loading('house_prices')
データを、X(説明変数)とy(目的変数)に分離
今回、売価(SalePrice)を予測したいので、これをy_dfに、それ以外をX_dfに格納します。
y_df=house_df['SalePrice'].to_frame()
X_df=house_df[house_df.columns.difference(['SalePrice'])]
カテゴリー値を数値にエンコード
学習を行うために、X_dfの中のカテゴリー値をエンコードします。
エンコードに利用したencoderをShapashにわたすことでデコードし表示が可能です(後述)
from category_encoders import OrdinalEncoder
categorical_features = [col for col in X_df.columns if X_df[col].dtype == 'object']
encoder = OrdinalEncoder(
cols=categorical_features,
handle_unknown='ignore',
return_df=True).fit(X_df)
X_df=encoder.transform(X_df)
TrainとTestを分離し、学習
よくあるコードですが、LightGBMを用いて学習、予測を行いました。
Xtrain, Xtest, ytrain, ytest = train_test_split(X_df, y_df, train_size=0.75, random_state=1)
regressor = LGBMRegressor(n_estimators=200).fit(Xtrain,ytrain)
y_pred = pd.DataFrame(regressor.predict(Xtest),columns=['pred'],index=Xtest.index)
Shapashで表示する
Shapashの起動
機械学習モデルを作成する過程で利用した、下記を用いて機械学習モデルを見える化します。
| # | 変数 | 説明 | Shapashでの指定箇所 |
|---|---|---|---|
| 1 | house_dict | 説明変数の列名に対応する 列の説明文 |
SmartExplainerに指定 |
| 2 | regressor | 作成したLightGBMのモデル | xpl.compileで指定 |
| 3 | preprocessing | カテゴリー値のエンコードに 利用したエンコーダ |
同上 |
| 4 | Xtest | 予測に利用した説明変数 | 同上 |
| 5 | y_pred | LightGBMが出力した予測値 | 同上 |
from shapash.explainer.smart_explainer import SmartExplainer
xpl = SmartExplainer(features_dict=house_dict)
xpl.compile(
x=Xtest,
model=regressor,
preprocessing=encoder, # Optional: compile step can use inverse_transform method
y_pred=y_pred # Optional
)
app = xpl.run_app()
上記コマンド実行後に、ブラウザで下記にアクセスすることでShapashを表示します。
Shapashの停止
下記で停止することができます。
app.kill()
まとめ
機械学習モデルを見える化するShapashを動かしてみました。
正直、一部動作しない機能もあり、まだまだ発展途上という状況かとは思いますが、機械学習モデルの「見える化」には有用なツールかと考えています。
個別アプリとして8050ポートで起動する以外にJupyterにインラインで表示する方法もありますので、SHAPやLIMEを用いた表示と合わせて、次回以降で扱っていきたいと思います。
なにかあれば、コメントを。あと、よろしければ、LGTM頂ければ幸いです。
(更新):可視化の詳細に関しては下記の記事でタイタニックを例にまとめています
参考
- https://github.com/MAIF/shapash
- https://shapash.readthedocs.io/en/latest/index.html
- https://shapash.readthedocs.io/en/latest/installation-instructions/index.html
- https://shapash.readthedocs.io/en/latest/tutorials/index.html