はじめに
生成AIが広く普及する現代において、機械学習は日常的に利用されていますが、その予測モデルの安定運用は難易度の高いテーマの一つです。
QiitaにもMLOpsツールは多々紹介がありますが、機械学習システムの安定運用に向けての方法論はあまり紹介がなかったので、筆者の私見1に基づき「システム監視、記録」2の観点で整理してみたいと思います。
こんな事ありませんか?
構築時
例えば、売上の予測やDM送付等のマーケティングに機械学習を活用している場合に、機械学習モデルやその実行を担うシステムを構築した直後は、在庫が適正化され、売上も上昇といったように順調だった。
しかし、数カ月後。。
構築から数ヶ月が経過し、機械学習による予測の精度が劣化してしまい、その予測結果を用いた販売施策やマーケティング施策がうまくいかなくなってしまった。

コンセプトドリフト/データドリフト
上記の様な現象は、コンセプトドリフトやデータドリフトとして説明され、機械学習を用いたプロジェクトでは不可避な現象です。
コンセプトドリフト
「売上の発生メカニズム」や「出力(売上)と入力(説明変数)の関係性」が変化してしまった為、当初の目的や想定した予測精度が達成できなくなってしまった。
データドリフト
出力(売上)と入力(説明変数)の関係性は変わらないが、入力である説明変数の分布等が変化してしまった為、当初の目的や想定した予測精度が達成できなくなってしまった。
監視や記録の重要性
コンセプトドリフト/データドリフトは不可避の現象ではありますが、それらを検知することで、機械学習パイプラインの改良やモデルの再学習等といった対策が可能です。
この背景で、機械学習を継続的に利用するシステムでは、大変地味ではあるのですが、予測システム対する 「監視や記録」 が重要となります。
では、「監視や記録」はどのように行えばよいでしょうか?システムの構成要素を整理した上でそれらの方法論を検討していきたいと思います。
何を監視するか?
普通に考えれば、予測精度の劣化が問題なので、予測精度だけを監視や記録しておけば良さそうですが、実際にはそれではうまくいきません。何を監視するか?の議論を進めたいのですが、その前提として機械学習システムがどういった構成か?の理解を合わせたうえで議論を進めたいと思います。
機械学習システムの構成要素(想定)
目的に応じ様々な構成や要素があると思うので、それらを一般化するのは難しいので、ここでは上述した、機械学習を用いたマーケティングを例にその構成を検討します。
まずは、売上データ、顧客データ といった既存システムに格納されているデータが必要となるのでそれらを取得し、前処理の上で、各商品の予測売上数や、販売が見込める見込み客を推定し、売上が見込める商品 について、その購入が見込まれる顧客に対し、カタログやクーポンを送付する様なマーケティング用途の機械学習システムについて考えてみます。
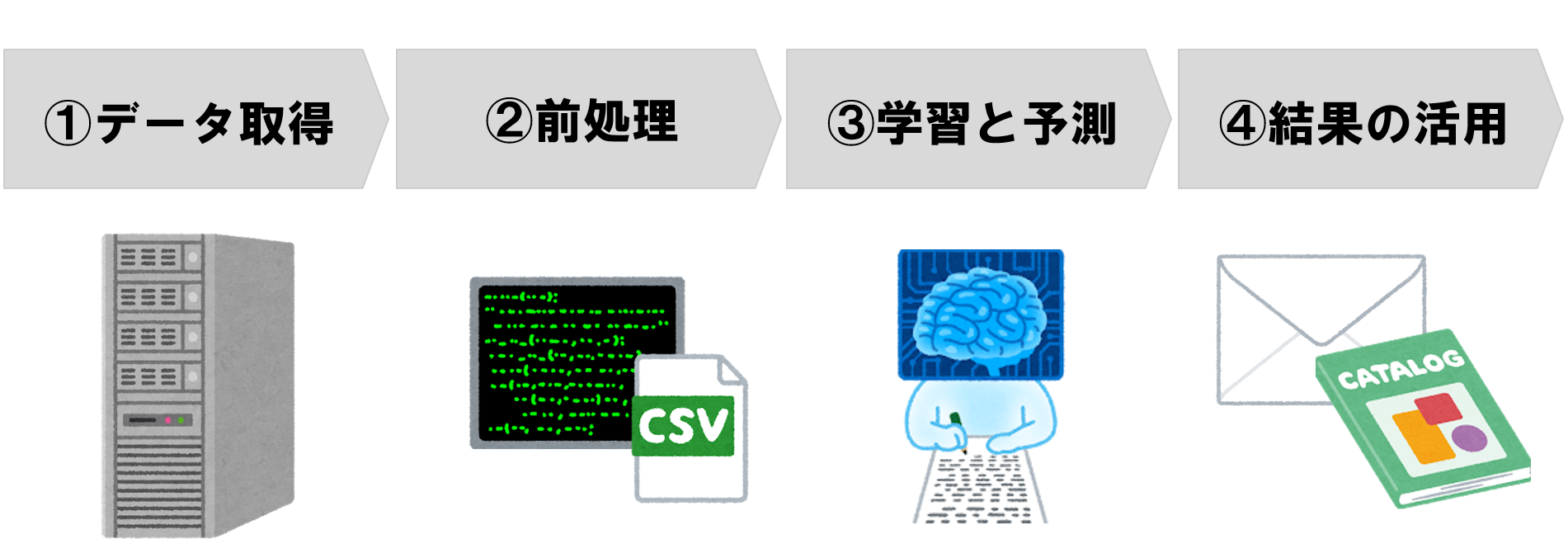
このシステムは上記のように4段階の処理で構成されます。
| ステップ | 内容 |
|---|---|
| ①データ取得 | 売上データや顧客データを既存システム、APIから取得。 |
| ②前処理 | データの結合やカラム追加、集計処理、特徴量作成等。 |
| ③学習と予測 | 作成した特徴量を用いてモデルを学習、未知のデータを予測。 |
| ④結果の活用 | 予測結果に基づくマーケティングの実施。 |
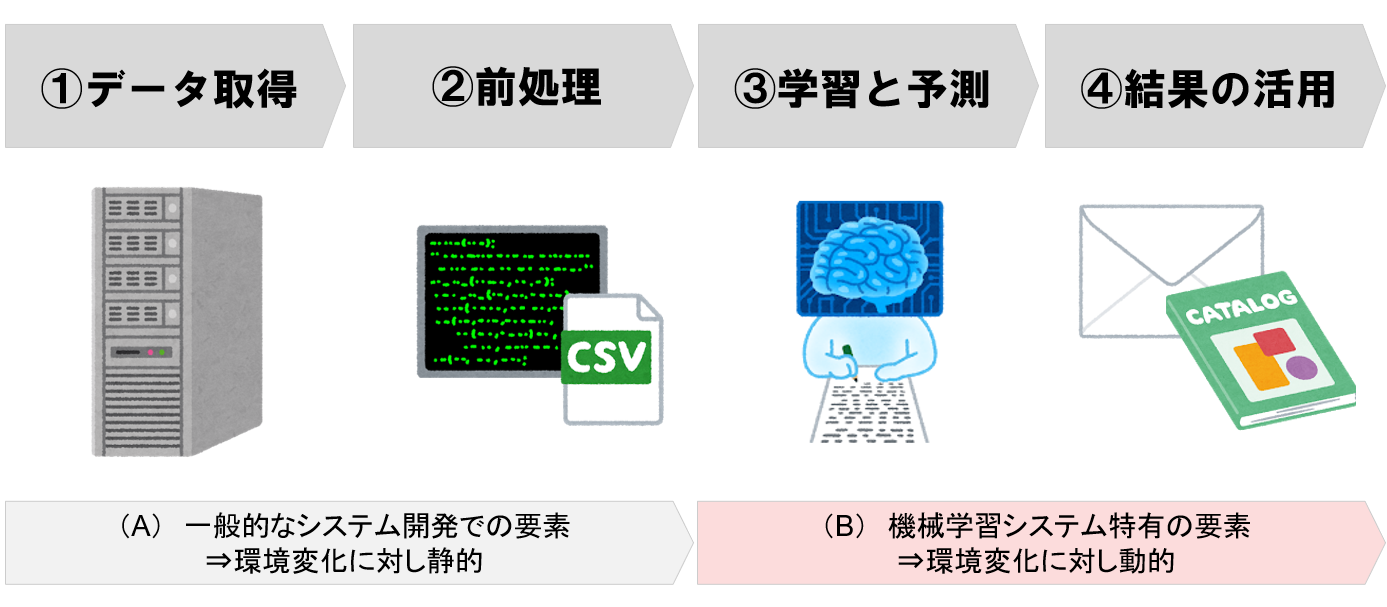
初期構築時は問題なく動作しますが、数ヶ月~数年が経つと、売れる商品、顧客の購入傾向、ものが売れる仕組みも徐々に変化していく為、前半の①②と比較し、後半の ③機械学習モデルよる予測や推定 と ④その結果を活用 は環境変化の影響を大きく受け、実用に耐えない状況となってしまいます。
つまり、ビジネス環境変化に対し静的な、(A)一般的なシステム開発での要素(①データ取得、②前処理)と共に、ビジネス環境変化に対し動的で大きく影響を受ける(B)機械学習システム特有の要素(③モデルの学習と予測、④予測結果の活用)の両者をいかに監視し、環境変化を捉えて先手で対策を打つか?が重要となります。
環境変化による影響の波及
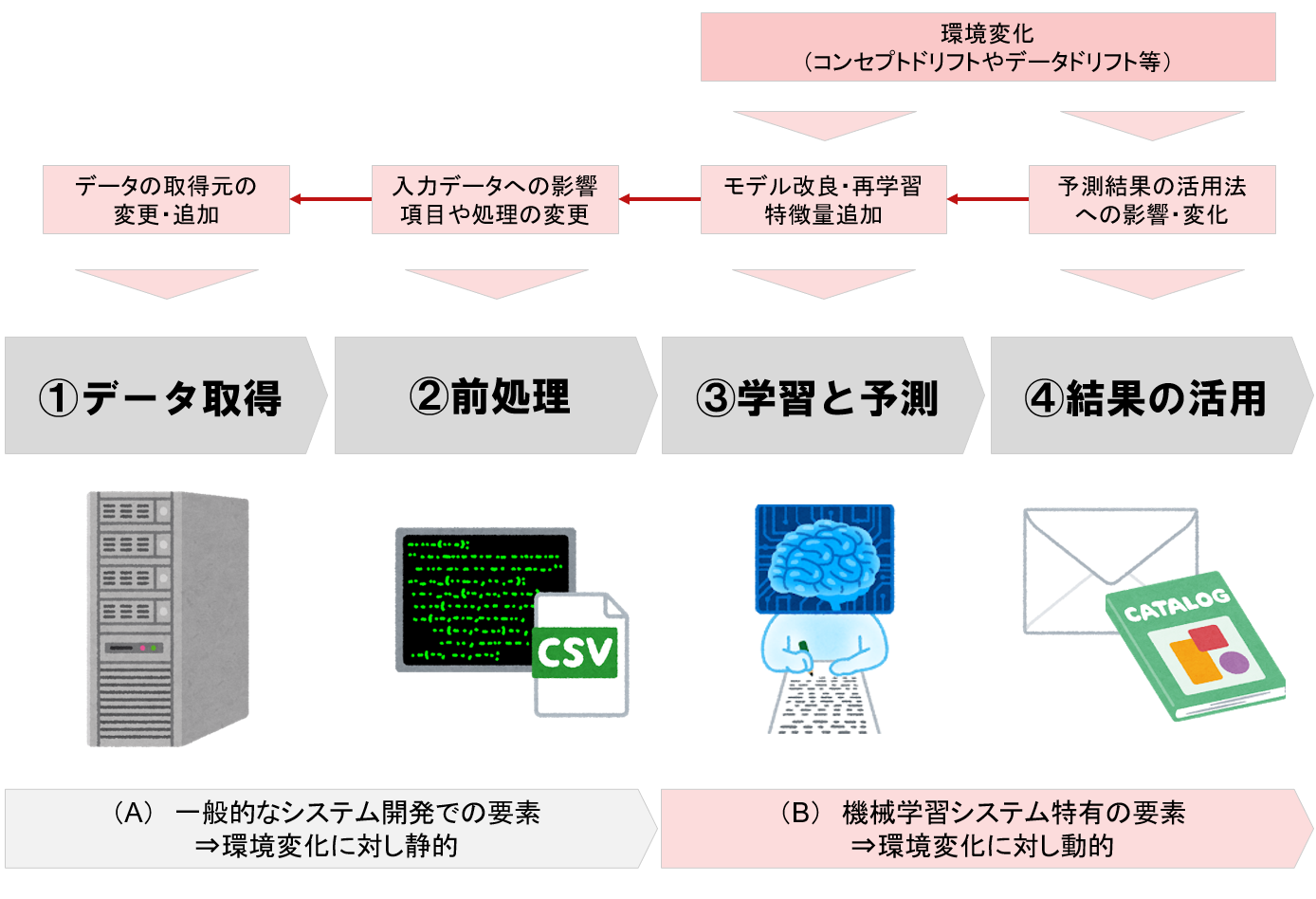
コンセプトドリフトやデータドリフトといった環境変化が精度劣化を引き起こしますが、その環境変化はこの機械学習システムのどこに影響を及ぼすでしょうか?普通に考えると、「③学習と予測」 にのみ影響がありそうですが、実際にはより広い範囲に影響を及ぼします。
データのフローとしては「①→②→③→④」ですが、環境変化は直接的には③④のプロセスに影響を及ぼすので、どういった影響があるかをその逆順の「④→③→②→①」で確認していきたいと思います。
④結果の活用
予測結果に基づいて郵送でDMやカタログを送付している場合に、その販売におけるKPIとなる「購入率、リピート率」といった指標が劣化した状況を考えます。
劣化の原因は、機械学習起因の可能性もあれば、そもそもの事業環境が変化してしまっている可能性もあります。機械学習起因であればモデルの再学習や特徴量の追加といった対策が考えられますが、事業環境起因である場合は、新たな予測モデルを構築する必要があるかもしれません。
郵送によるカタログ送付は手元に紙面が届く為、高齢層向けには良い施策です。一方で、コストが掛かる割に「購入、リピート」に至る前の段階である、「DMを開いたか、反応したか」の計測はできません。若年層向けには郵送より、メールやSNSによるDM送付のほうが馴染みがあり、「反応率」も測定できるのでこちらのほうが適切かもしれません。

仮に、このブランドがビジネス環境の変化に追随し直近で、購買層の若返りを狙っていた場合は、購買年齢層が変化しており、既存の高齢層向けの郵送DM予測モデルのみでは機能が足りない可能性があります。若年層向けにEmailやSNSによる「反応率」も加味したDM予測モデルを新規に開発する場合、「結果の活用方法」の変化により、③→②→①は影響を受けます。3
③学習と予測
KPI劣化の原因が事業環境起因でなく、機械学習の予測精度起因であれば、この③のフェーズの改良で改善する可能性があります。具体的にはモデルの改良、再学習、特徴量の追加等です。これらの対策は、②→①のフェーズに影響を及ぼします。
②前処理
仮に、③のフェーズで新たな特徴量を追加する場合には、その前処理が追加となるので、②のフェーズにも影響が出ます。その新設の特徴量の元データが既存のデータソースに存在しない場合、①のフェーズに影響を及ぼします。
①データ取得
②のフェーズで新たなデータを使いたいといった場合に、データ取得元のシステムやAPIの追加といった作業が必要となります。
課題感をまとめると
一見すると、環境の変化は③④にのみ影響を及ぼすように見えますが、モデル追加、特徴量追加、データソースの追加といったように下図の上段に示す通り影響が波及するため、環境変化に対して静的に見える①②を含めて①~④に横断して影響が発生します。
具体的にどう進めるか?
環境変化に合わせて①~④に横断的に改修を加えなければ行けない状況にて、システムの安定運用に向けてはどういった監視が適切でしょうか?
機械学習システムの安定運用に向けては 精度(以下E)だけではなく、このフェーズ①~④に横断する「監視や記録」 が重要です。具体的な「監視や記録」のポイントを示すと以下のA~Fとなります。
監視や記録のポイント
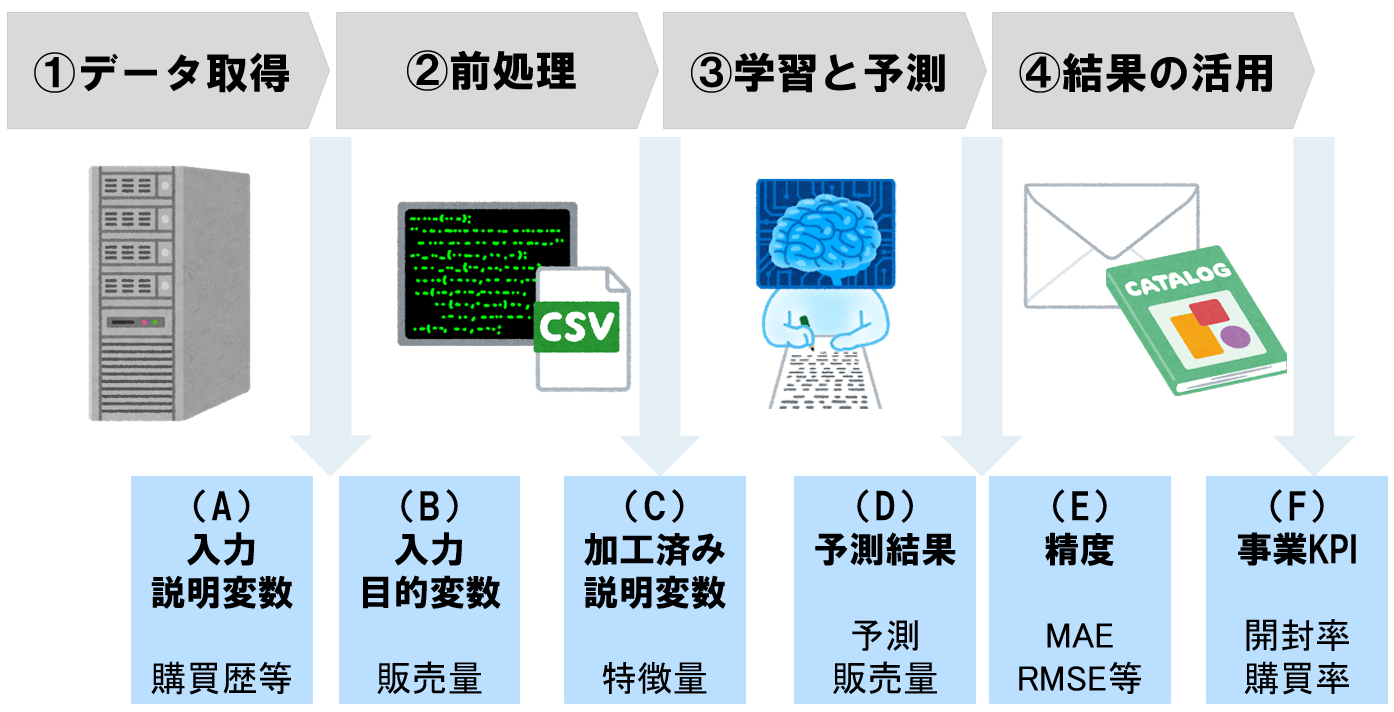
監視
「(B)目的変数、(D)予測結果、(E)精度、(F)事業KPI」といった 定量評価しやすい項目 については、しきい値を決めてその値の上限、下限を超過した場合にはアラート(メール、Chat等)を通知するガードレールの様な運用を構築します。なお、しきい値が決定できない場合には、仮の値で運用を開始し、運用中に見直しを進めます。
「(A)説明変数、(C)加工済み特徴量」といった、その項目 単品では定量評価しにくい項目については、本番運用中にサンプリングでデータを採取し、実際の予測傾向を人の目で確認するような運用も構築できると様々な予兆に早く気づくことができます。
また、後述の通りデータの分布の変化は、それを検知できるようは指標を計算し、監視する運用を構築します。
記録
A~Fでの断面のデータを「学習時、予測運用時」の両タイミングで記録、保管します。
事業KPIが達成できない、予測精度が劣化した等の際に、機械学習パイプライン上のどこに問題があったかを特定できるよう各種エビデンスを保全します。
ストレージ容量の都合で、予測トランザクションの全量を保存できない場合は、サンプリングで保存するという方法もあります
では、このA~Fについて具体的にどういった狙いで、どういった監視や記録をするかを整理していきます。
(A) 入力説明変数
変数の説明
モデルの学習に用いる、$y=f(x')$ の前処理による加工前の元データの $\color{blue}{x}$です。
$\color{blue}{x}\stackrel{②前処理}{\to}x'$
「年齢、性別」といったデモグラフィや、これまでの個人毎の「購買歴」といった、過去の目的変数$y$(販売数や販売先といった結果)を説明できる変数です。
監視や記録の狙い
-
外部システム、APIの仕様変更の検知
- 外部システム、APIからデータを取得してくる背景で、それらのシステムのデータ仕様が変更される可能性があり、これらを早期に検知することが重要です
- よく発生するケースとして、
- 位取りが勝手に変更された(円 → 千円)
- 日付や日時の書式が勝手に変更された(yy/mm/dd → yyyy/mm/dd)
-
加工前の説明変数の保全
- フェーズ②にて入力された説明変数を前処理し特徴量を作成しますが、この特徴量に問題が発見された場合に、「元データの問題か?前処理プログラムの問題か?」 の切り分けが必要になります
- 加工前の説明変数を保全することで、問題発生時にこの切り分けをスムーズに進めることができます
(B) 入力目的変数
変数の説明
モデルの学習に用いる、$\color{blue}{y}=f(x')$ の $\color{blue}{y}$です。
(A)の$x$に対応した$y$で、目的変数で「販売数や販売先」といった「結果」を示す変数です。
監視や記録の狙い
-
外部システム、APIの仕様変更の検知
- (A)と同様に、対向システムの仕様変更の可能性があり、それに備えます
-
ビジネスや商材の変化の検知
- 過去半年分~1年分の売上実績データを用いて、今後の売上や販売先を予測する際に、ある商品について、2023/12は1200個、2024/11は10個の様に実績データに、10倍、100倍の差異がある場合、 機械学習では捉えられない 「何か」 が発生しています
- 例えば、「競合製品が市場を破壊するような値下げを行った」 といった場合もあれば、「製品が、単品からダース売り(12個パック)に変更された」 といった場合もあるかもしれません
(C) 加工済み説明変数
変数の説明
モデルの学習に用いる、$y=f(\color{blue}{x'})$ の $\color{blue}{x'}$です。
$x\stackrel{②前処理}{\to}\color{blue}{x'}$
前処理により入力説明変数を加工した、学習に用いる特徴量である加工済み説明変数です。
監視や記録の狙い
-
前処理の妥当性確認
- 上述の通り前処理に問題がある場合に、(A)と(C)を対比することで、データ or 処理のどちらに問題があるかを切り分けることができます
-
特徴量の分布の変化の検知
- 学習時と運用時で特徴量の分布に変化を検知することを目的に特徴量の分布の変化や差を評価できる、以下の様な指標を計算し、データドリフトを検知します
- Kullback–Leibler Divergence
- Jensen-Shannon Divergence
- Population Stability Index
- 学習時と運用時で特徴量の分布に変化を検知することを目的に特徴量の分布の変化や差を評価できる、以下の様な指標を計算し、データドリフトを検知します
なお、データドリフトの検知に用いる指標については以下の記事にまとまっていたのでリンクさせていただきます。
また、このようなツール活用も良いかもしれません。こちらもリンクさせていただきます。
(D) 予測結果
変数の説明
モデルにより予測された、$\color{blue}{\widehat{y}} = f(x')$ の $\color{blue}{\widehat{y}}$ です。
予測された「販売量」や「販売先」等の、④のマーケティング(結果の活用)のインプットなるデータです。
監視や記録の狙い
-
予測傾向の理解
- 「販売量」や「販売先」といったビジネスサイドでも理解しやすいデータなので、可視化等を用いることで、機械学習の予測傾向を理解するのに用いることがでます
-
学習時の予測傾向との乖離確認
- 今回の予測のインプットに類するデータが、学習のデータセット(train/valid/test)のうち、testのデータセットに含まれる場合、両者の入力と出力を突き合わせることで、学習時と同様の傾向で予測できているかのサンプリング確認にも使えます。
(E) 精度
変数の説明
予測の精度や正解率です。問題に合わせ適切に設計する必要があります。
回帰問題であれば、MAE、RMSE、RMSLE等、分類問題であればAUCやf-measure等です。
なお、以下、以前にまとめた記事があるので貼っておきます。
監視や記録の狙い
-
精度の監視
- 当初設計した通りの予測精度が継続的に達成できているかを監視します
- ただ、問題によっては、(E)と共に、(F)の事業KPIによる監視が適切な場合もあるので、何をもって「期待の挙動」とするかは設計時に検討が必要です
- 例えば、機械学習による販売量の予測と合わせて、その予測販売量を用いた販売発注シミュレーションを実施するような場合、各商材の単品の予測販売量以上に、商材毎の在庫回転率や在庫回転日数、欠品率といった指標のほうが重要な論点となるかもしれません。こういった場合は、Eと共にFの事業KPIも同時に監視します
(F) 事業KPI
変数の説明
事業上、機械学習において達成したいKPIです。
本稿で取り上げたマーケティングの場合、「DM開封率、商品クリック率、購買率、リピート率」等です。
機械学習システムの外側の指標ですが、事業環境の変化等の検知のためには重要な指標となります。
監視や記録の狙い
-
ビジネスや商材の変化の検知
- 機械学習を適用した際に、予定していた事業上のKPIと実際のKPIが乖離する場合、機械学習システム自体の異常に加えて、(B)と同様に商材の単位やビジネスがそもそも変化しており、予測に意味が無くなっている可能性があり、これを検知します
-
ビジネス vs システムの切り分け
- マーケティング、販売施策が計画通りに進捗しない際にその要因が、機械学習システムにあるのかビジネスや事業環境側にあるのかを切り分けるには、この事業KPIも監視や記録が必要です。
まとめ
これまでの議論を以下に表で整理し、まとめとさせていただきます。
| 監視箇所 | 例 | 監視や記録の狙い |
|---|---|---|
| (A) 入力説明変数 | 購買歴、年齢や性別等 のデモグラフィ |
外部システムやAPIの仕様変更の検知 加工前の説明変数の保全 |
| (B) 入力目的変数 | 過去の販売数量 過去の販売先等 |
外部システムやAPIの仕様変更の検知 ビジネスや商材の変化の検知 |
| (C) 加工済み特徴量 | 前処理で作成した特徴量 | 前処理の妥当性確認 特徴量の分布の変化の検知 |
| (D) 予測結果 | 予測された販売量 予測された販売先 |
予測傾向の理解 学習時の予測傾向との乖離確認 |
| (E) 精度 | MAE、RMSE、RMSLE AUC、f-measure 等々 |
精度の監視 |
| (F) 事業KPI | 開封率、購買率 回転率、欠品率 等々 |
ビジネスや商材の変化の検知 ビジネス vs システムの切り分け |
監視箇所の図も再掲します。
最後に
機械学習パイプラインの中を細かく監視、記録することで、トラブルの事前検知、事後検証の両者に役立ち、機械学習システムの安定運用が実現できると考えています。あくまでも私見に基づく整理ですので、これが正解といったものでは到底ありませんが、皆様の参考になれば嬉しく思います。
なお、今回は「データ」や「ドリフト」の観点での監視ポイントをまとめさせて頂きましたが、実際の運用では、「プロセス、リソース、応答速度、バイアスや公平性、プライバシ」といった非機能の監視もあるのでこれらについては、いつかガッツが湧いたらまとめたいと思います。
以上、長文にお付き合い頂きありがとうございました。
アドベントカレンダーということで、「皆様、メリークリスマス!&良いお年を!」
※本稿の内容は個人の見解であり、所属する組織の公式見解ではありません。
おまけ
所属組織で以下のアドベントカレンダを開催しています。
ご興味あるものがあればご笑覧いただければ幸いです。
-
本稿は、著者の私見に基づくため、その裏付けとなる論文、書籍等は無く、妥当性は無いかもしれません。あくまでも、経験則くらいなのだな。程度で読んで頂けると助かります。 ↩
-
本稿では主に「データ」と「ドリフト」の監視に重きをおいて整理しますが、実際の運用では「まとめ」で述べるように、「プロセス、リソース、応答速度、バイアスや公平性、プライバシ」といった非機能の監視も必要になります。 ↩
-
こういった、コンセプトドリフトに類する変化があると、モデルは作り直しになり、監視や記録を続けたとしても、意味が無いではないか。といった主張もありますが、監視をしていなければそういった大規模な改修が求められている事実にも気づくことができないので、その意味でも監視と記録は機能します。また、モデルの全面的な改修となった場合、それまで運用されてきたモデルの改善で予測性能にどんな変化があったか、その時のFeature Importanceはどうだったかといった情報は、新たなモデルの開発やモデルの全面改修の際にも役立つ情報となります。その意味でも後述するポイントにて必要な情報を保全することは重要となります。 ↩