Z Lab Advent Calendar 2023 一日目の記事になります。
今年も全記事が埋められるかわかりませんが、社内で行っている多くの技術に関する記事を公開しようと思いますので最後までお楽しみください。
はじめに
2年前の記事でも弊社の自分が所属するチームのデプロイパイプラインはGithub ActionとArgoCDなどを利用して構築していると紹介しましたが、運用を重ねるうちにデプロイパイプラインが複雑になってきて、色々と課題が出てきたためKubernetes Operatorで感じている課題の解決を試みた話を紹介します。
背景
以前の状態
弊社の自分が所属するチームの環境ではすべてのシステムをArgoCDでデプロイするように管理しています。このArgoCDで扱えるようにほぼすべての環境のシステムがマニフェストファイルで表現され管理されている状態になっています。
環境ごとの差分なども可能な限りArgoCD ApplicationSet, Kustomize, Helmなどで実現していますが、それだけでは表現できないワークフローも当然ありそれらはGithub Action上でシェルスクリプトなどで実現していました。
感じていた課題
このGithub Actionで実現しているワークフローは複数のリポジトリにまたがり様々なトリガーで発火するようにしているため、ワークフローの全体図が分かりづらいこと、またそれによりワークフローの一部が失敗した際に何処を直せばよいのか、何処から再開し直せばよいのかというところが分かりづらいという課題がありました。
複数のリポジトリにまたがり様々なトリガーで発火するようにしているワークフローというのは例えば特定のソフトウェアがリリースされたことをGithub Releaseをトリガーに検知し、リリースバージョンをworkflow_dispatchで通知して、マニフェストファイルのバージョンを書き換えるということを実施していますが、この部分などが増えてきたり複雑なフローが増えると管理しきれなくなり上記のような課題に繋がってしまいました。(もちろんこの方式でも発火元を記録するように厳密なルールを敷いたりすることで管理することもできるとは思います)
解決案
上記の課題を解消するために我々はワークフローの一部をKubernetes Operatorに置き換えるということを試してみることにしました。
これにより以下の効果を期待しています。
- Kubernetes Resourceでワークフローの各ステップを実現し、ステップ間の依存関係を有向グラフで可視化することで全体図の把握をしやすくする
- Operatorによるreconcile loopでステップの冪等性を強制することによって復旧時の原因把握や復旧作業が簡単になること
- golangで実装することで可読性やメンテナンス性の向上
解決方法は色々とあると思いますが単純に試してみたかったという気持ちとチームメンバーは日常的にOperatorを書いていて慣れていることなども理由になります
実装
Kubernetes Operatorで実現するとなるとCRDとコントローラをどのように分けて管理するかというところがありますが、今回我々は以下のような特徴を持つ形に切り分けて実装しました。
主な特徴
- 他の仕組みなどとの連携のしやすさなどを考えてSecretリソースを基本的なインターフェイスとして、複数のリソース間のデータのやり取りを実現するようにした
- 汎用的なステップと独自ロジックを含むステップをコントローラ単位で分けてある程度使い回せるようにした
これだけ書いてもいまいちイメージがつかないと思いますので、簡易的にしたワークフローの実装例を紹介します。
この例では次のワークフローを置き換えることとします。
- Github Releaseでリリースを検知
- リリースされたバージョンでマニフェストファイルのリリースバージョンを書き換える
- 書き換えられたファイルをリポジトリにコミットしてPullRequestを出す
上記の内容を分解してCRDに落とし込んでいきます。
実装したCRD・コントローラの一例
GithubLatestReleaseRepoFile
Github Release APIから情報を取得して最新のreleaseのバージョン(名前)とそのreleaseのファイルを取得してSecretリソースに保存する
ReplaceString
Secretリソースを入力として受け取り、指定した文字列を指定された内容に置換して別のSecretリソースに保存する
GithubPullRequest
Secretリソースを入力として受け取り、指定したリポジトリのパスとその内容を比較して差分があればPullRequestを作成して更新する。
このような3つのCRDとコントローラを作成し、これらを組み合わせることで例で上げたワークフローを実現するようにします。
この例を可視化すると以下のような形になります。
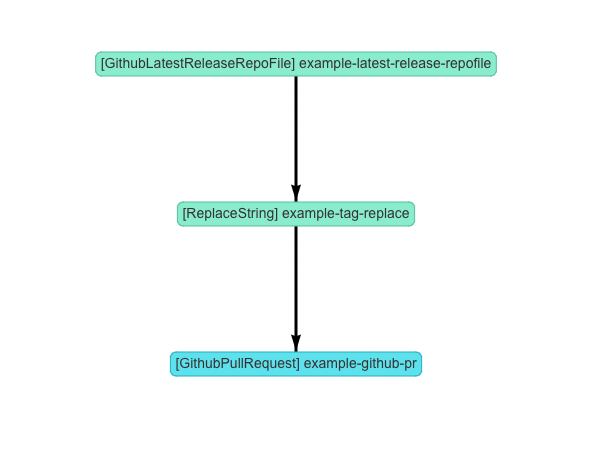
色はステータスを表していて、上2つはsuccess, 一番下はupdating(要はPRレビュー中)の状態を示しています。
実施してみて
- 全体のワークフローは可視化でき、全体図が把握しやすくはなった
- ただ合わせてパイプライン自体も整理したこともあり思ったよりも簡素なフローが多くなって可視化する価値があったかは微妙なところに

- ただ合わせてパイプライン自体も整理したこともあり思ったよりも簡素なフローが多くなって可視化する価値があったかは微妙なところに
- reconcile loopでステップの冪等性を強制することによる効果は得られたと思っている
- 常時動かしている状態になるので、壊れたらすぐわかり原因の特定がしやすくなる
- Operatorでの実装はやはりそれなりに手間がかかり、初期実装にはシェルスクリプトより体感にはなるが2,3倍のコストがかかる
- メンテナンス性はシェルスクリプトよりは上になると思いますがコントローラを書くのに慣れていない人はなれるまでより時間がかかる気はします
- シェルスクリプトではなくgolangでの実装になってので可読性やテストやメンテナンスはしやすくなったと感じている
- reconcile loopでの実現でパイプラインの実行速度は上がった
- 上記のような例だと一瞬すぎて可視化しても経過を追うことができない状態に
- 予想しなかった不具合があってやや困っている
- GithubのAPIのバグやレスポンスが安定しないことがあり、その場合の対処が必要になってしまった
- ポーリングしている関係で短時間でも不具合があるとそのタイミングでこちらの動作が安定しなくなってしまうので例外条件を追加して回避するなどの対応が必要になっている
- 特に偶にファイルやRelease自体が実際はあるのに404が返ってくることがあり、404のケースと場合分けが難しい点が課題に感じている
- GithubのAPIのバグやレスポンスが安定しないことがあり、その場合の対処が必要になってしまった
上記のような感想で、メリット・デメリット両方があり、Operatorでの管理がよいかはチームメンバーや実現したいワークフローの規模などにもよるので一概に良いとは言えないと思いますが個人的には総合的には良い選択だったのかなと感じています。