この記事では Kubernetes 1.20 よりベータで導入された API Priority and Fairness(APF)について紹介します。
APF は API Server のリクエストというすべての Kubernetes を利用するユーザに関連する機能なので Kubernetes を利用する方であれば理解しておくと役に立つかもしれません。
この記事は KEP やドキュメントの内容をまとめながら自分の理解した内容をまとめたものです。(あくまでも自分の理解なので誤りがある可能性がありますので留意ください。もしあれば指摘もらえると助かります。![]() )
)
- 公式ドキュメント: https://kubernetes.io/docs/concepts/cluster-administration/flow-control/
- KEP: https://github.com/kubernetes/enhancements/tree/master/keps/sig-api-machinery/1040-priority-and-fairness#implementation-history
概要
過負荷状態にある kube-apiserver の動作を制御することは、クラスタ管理者にとって重要なタスクです。kube-apiserver には、いくつかの制御機能(--max-requests-inflight および --max-mutating-requests-inflight)が用意されており、未処理の作業を受け入れる量を制限することで、インバウンドのリクエストが殺到して kube-apiserver がオーバーロードしてクラッシュすることを防ぎますが、これらのフラグでは、トラフィックが多い時に最も重要なリクエストを確実に通過させるが困難です。
API Priority and Fairness feature (APF)は、前述の max-inflight 制限を改善する代替手段として開発が進められています。APFは、より細かい方法でリクエストを分類し、分離します。また、限られた量の Queuing を導入することで、非常に短いバーストの場合でもリクエストが拒否されないようにします。リクエストは、Fair Queuing 技術を使用してキューからディスパッチされるので、例えば、お行儀の悪いコントローラが他のコントローラ(同じ優先度であっても)を飢えさせることはありません。
導入のモチベーション
- APF が存在しない状態の場合は以下の過負荷から API server を保護する機能があった
- mutating と readonly のリクエストに対する max-in-flight 機能
- それ以外にリクエストを区別することはなかった
- そのためリクエスト負荷のあるサブセットが他のサブセットを圧倒するようなことが発生する可能性がある
- 例えばバグのあるカスタムコントローラが大量にリクエストを投げ続けてしまい、controller-manager などの重要なリクエストが処理されないなど
- また、2つの独立した制限を入れると work-conserving にならない
ゴール
以下の悪いシナリオを防ぐ
- セルフメンテナンスの混雑
- 以下のようなシステムのセルフメンテナンスのためのリクエストの優先順が保証されていない
- Node の heartbeat
- Pod, Service, Secret などに対する kubelet や kube-proxy の動作
- Leader election
- 以下のようなシステムのセルフメンテナンスのためのリクエストの優先順が保証されていない
- 優先順位の逆転
- リクエスト A を処理する際に直接的または間接的に他のリクエスト B が発生することがある
- 例えば admission-control など
- その場合にリクエスト A が大量にリクエストされるとそれに関連してリクエストBが大量に発行されることがある
-
 このときにリクエストBの優先度が低いと結果として高優先度のAが処理されないということだと思われる
このときにリクエストBの優先度が低いと結果として高優先度のAが処理されないということだと思われる
-
- リクエスト A を処理する際に直接的または間接的に他のリクエスト B が発生することがある
- 低優先度のリクエストの保証
- より高い優先度のリクエストが何分も走っていることがある
- クラスタに接続している通常ユーザのリクエストが停止しないように高優先リクエストで全容量使い果たすことはなくす
- GC による高負荷
- controller-manager のコントローラのバグなどによって暴走した際に全体が停止してしまうこと
- 特定のノードなどに分散されたコントローラ(kubelet, kube-proxy)の一部の暴走が全ノードに影響してしまうこと
- 特定テナントが全体を専有してしまうこと
- テナントは Namespace やユーザ名や特定prefixのユーザ名、ユーザグループなどに対応する
上記の問題に対応することを想定した新しい機能を追加する。
機能の実装の優先順位は以下の内容で進める。
- 過負荷保護(Overload Protection)
- 公平性(Fairness)
- スループット
ノンゴール
- 複数の apiserver 間の連携
- 公平性は正確ではなく大まかに
- CONNECT リクエストは対象外
- apiserver の cpu とメモリの保護のみが対象で ネットワーク帯域、クライアントや etcd は含まれない
- 容量の自動調整
- event rate の制限
- 既存の admission control はそのまま
処理の流れ
APFは既存のリクエストハンドラをより広範囲に分類して、その分類ごとに優先度を付けて処理していくものとなります。
その為大まかに分類すると以下の2つの処理で構成されます。
- リクエストを分類する
- 分類したリクエストを優先度に従って処理する
まずはリクエストを分類するところから見ていきます。
リクエストを分類する
APF ではリクエストを FlowSchema というリソースで分類します。
FlowSchema 自体の spec は以下のとおりです。
KIND: FlowSchema
VERSION: flowcontrol.apiserver.k8s.io/v1beta1
RESOURCE: spec <Object>
DESCRIPTION:
`spec` is the specification of the desired behavior of a FlowSchema. More
info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
FlowSchemaSpec describes how the FlowSchema's specification looks like.
FIELDS:
distinguisherMethod <Object> # 分類したリクエストを更にコントロールする単位(サブセット)で分けるための対象を決める
type <string> # ByUser または ByNamespace が指定できる
matchingPrecedence <integer> # マッチングの優先順位を指定する。低いほうが先にマッチング処理を実施する
priorityLevelConfiguration <Object> # マッチしたリクエストの priorityLevelConfiguration を指定する
name <string>
rules <[]Object> # マッチさせたいリクエストのルールを記載する
nonResourceRules <[]Object>
nonResourceURLs <[]string>
verbs <[]string>
resourceRules <[]Object>
apiGroups <[]string>
clusterScope <boolean>
namespaces <[]string>
resources <[]string>
verbs <[]string>
subjects <[]Object>
group <Object>
name <string>
kind <string>
serviceAccount <Object>
name <string>
namespace <string>
user <Object>
name <string>
リクエストを受け取ったら FlowSchema の定義に従ってリクエストにマッチする FlowSchema を選びます。
以下の図はデフォルトで定義された FlowSchema と PriorityLevelConfiguration ですが、このように matchingPrecedence が低い FlowSchema から順番にマッチするか確認していき、マッチした FlowSchema があれば それに対応した PriorityLevelConfiguration のキューへ処理を渡します。
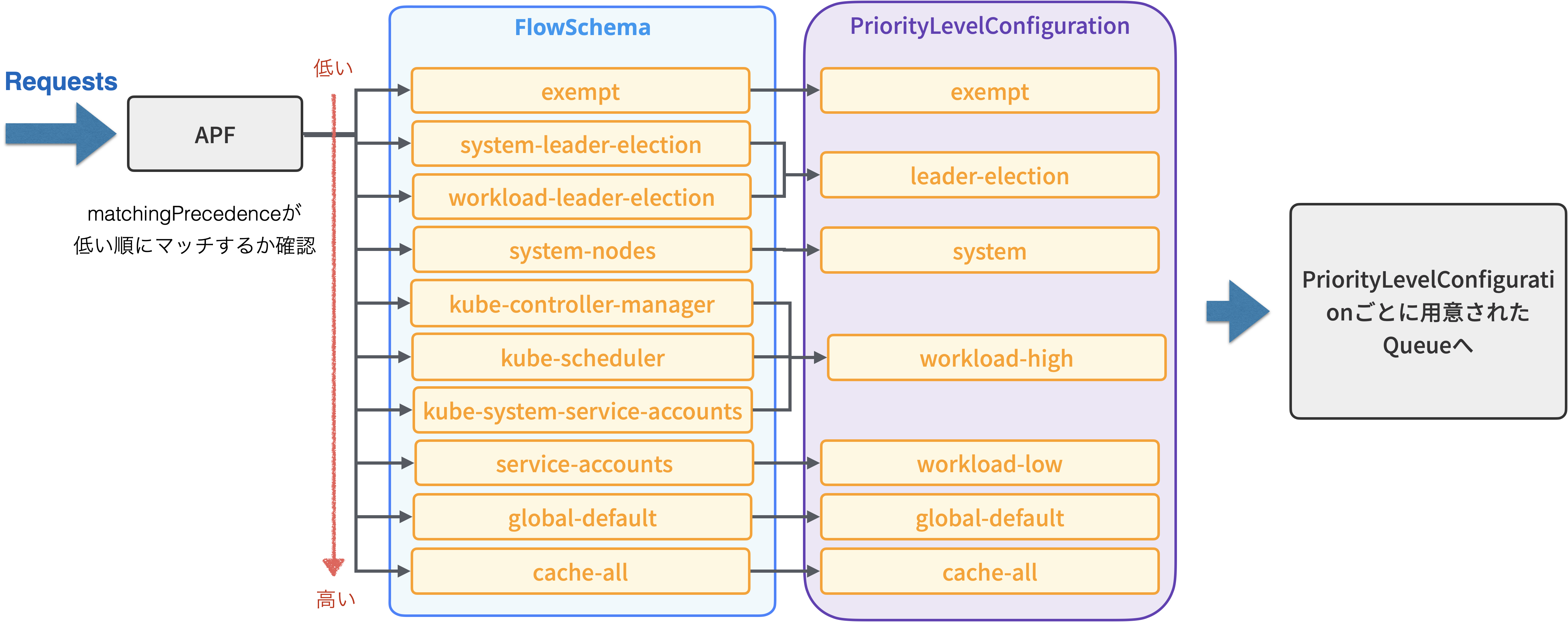
※ もし matchingPrecedence に同じ値が設定されていた場合は name 順にソートされて実行されますが、この仕様を期待するべきではないと公式ドキュメントに書かれているため同値の FlowSchema を作るのは避けたほうが良いでしょう
※ exempt だったり即時実行できる場合はキューには入らず実行される
デフォルトで設定されている FlowSchema を簡単に紹介します。
- exempt
- system:masters グループのリクエスト
- この FlowSchema だけキューに入らずに即時実行されます
- system-leader-election/workload-leader-election
- リーダー選出の際に利用するリクエスト
-
configmapやendpointsがまだ入っているので他のもまだマッチしてしまいそう?
- system-nodes
- kubelet からのリクエスト
- kube-controller-manager/kube-scheduler/kube-system-service-accounts
- コントローラやスケジューラ、または kube-system で動作している Pod からのリクエスト
- service-accounts
- 通常のサービスアカウントからのリクエスト
- ユーザのコントローラなどが大体このフローになる
- global-default
- クラスタ外からのリクエスト
- catch-all
- 上記に一致しなかったリクエスト全て
- ここまで来た場合はすべて Reject される
上記のようにデフォルトである程度のことには対応できるように設定済みなので、基本的にユーザは FlowSchema を追加したりする必要はないかと思います。
もし特別に優先させたいリクエストや隔離したいリクエストがある場合は FlowSchema を追加するとよいでしょう。
分類したリクエストを優先度に従って処理する
次に分類したリクエストを優先度に従って処理していくところ見ていきます
PriorityLevelConfiguration では以下のパラメータが設定でき、キューとその PriorityLevel に対してどの程度同時実行数を割り当てるかということを設定します。
具体的には以下の内容が設定できます。
KIND: PriorityLevelConfiguration
VERSION: flowcontrol.apiserver.k8s.io/v1beta1
RESOURCE: spec <Object>
DESCRIPTION:
`spec` is the specification of the desired behavior of a
"request-priority". More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
PriorityLevelConfigurationSpec specifies the configuration of a priority
level.
FIELDS:
limited <Object>
assuredConcurrencyShares <integer> # キューからディスパッチした後の同時実行数に影響します
limitResponse <Object>
queuing <Object>
handSize <integer> # シャッフルシャーディングで割り当てる一つのキューの数
queueLengthLimit <integer> # キューの長さ
queues <integer> # キューの数
type <string>
type <string>
これらのパラメータでキューを制御するわけですが、ここからが話が難しくなってきます。![]()
以下の話はドキュメントと実際の挙動を見て自分が理解した内容です。実際のソースコードなどで確かめたわけではないため誤っているかもしれません。
このキューの処理の部分は大きく分けて2つに部分に分けられます。
- どのキューに入れるか
- キューからどのように出すか
まずキューに入れる部分やキュー自体の部分を見ていきます。
キューに入れる部分はシャッフルシャーディングという手法を使って PriorityLevel 毎に用意された複数のキューに enqueue しています。
これはゴールにもあった 特定のサブセット(Namespace だったり、User などで分けられたリクエスト群)のリクエストが増え、その他のサブセットの処理がなかなか実行されないという部分を解消するために、利用されている手法のようです。
通常のシャーディングだとサブセット単位でシャードを選ぶわけですが、特定のリクエストが多いサブセットと同じシャードにあたってしまうとその影響を受けてしまいます。
これを回避するために考えられた手法がシャッフルシャーディングという方法のようで、サブセット毎に格納するキューを複数個ランダムに選び(この個数をHandSizeというらしい)キューに入れるようにします。この中のキューから一番空いているものに enqueue していくという方法のようです。
このようにすることで例えば下の図の左側のようにリクエスト数の多いサブセット(青)とリクエスト数の少ないサブセット(緑)があったとすると、青のサブセットに割り当てられたキューは溢れてしまいますが、それ以外空いているのキューがあるので、青のサブセットの高負荷の影響を受けにくくなります。
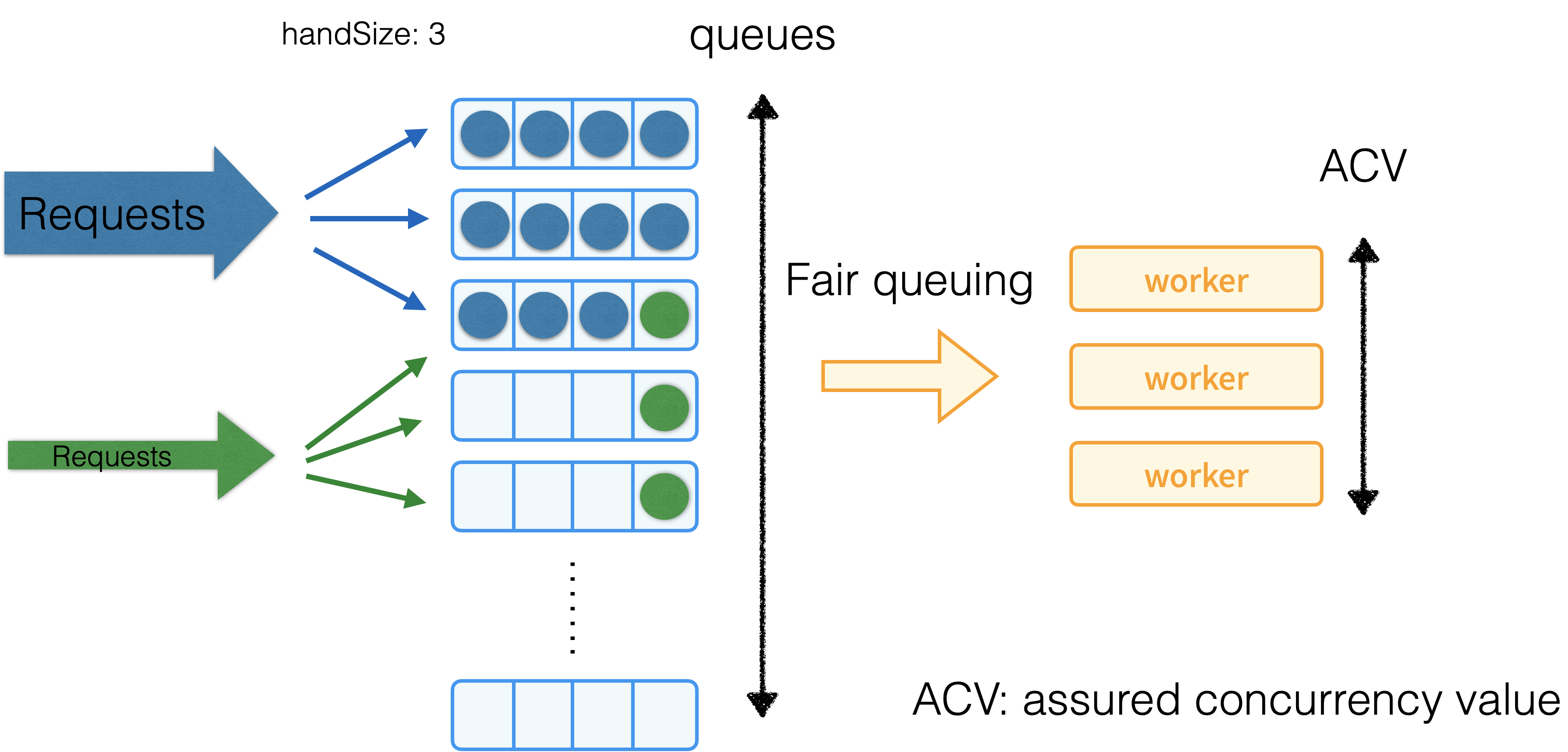
HandSizeとキューの数、リクエスト数が多いサブセット(elephant) パラメータの調整によってこの影響を受ける確率が結構変わるようで、公式ドキュメントにもその計算式やサンプルが紹介されているので興味があれば見てみると良いと思います。
次にキューからどのように出すかという部分です。ここでは Fair Queuing の手法を使っているそうです。この手法は、限られたリソースを共有する際に、公平性を実現するように設計されているようです。例えば、大きなパケットを持つフローや、小さなジョブを生成するプロセスが、他のフローやプロセスよりも多くのスループットやCPU時間を消費しないようにするようになっているらしいです。
詳しくは論文(ACM, MIT)があるみたいなので興味がある方は見てみるとよいかと思います。(筆者は見ていません)
KEP を見るとこのオリジナルの Fair Queuing から以下の 3 点でストーリーが異なるため、変更を加えているとのことです。
- 送信されるパケットではなく受信するリクエストを処理するということ
- 複数のリクエストを処理できること
- 実際の処理期間は実行してみないとわからないこと
詳しく知りたい方は KEP の方を参照してみると良いと思います。
そしてキューから選ばれたリクエストは実行されるわけですが、API server は複数のリクエストを同時に処理できるためリソースを使い果たさない程度に同時にリクエストを効率的に処理します。
この同時実行数はCPUとメモリを効果的に保護しながらどちらも低すぎない値を設定することが期待されています。
1.22 時点では同時実行数の制御は apiserver では専用の設定パラメータを用意されてなく、max-mutating-in-flight と max-readonly-in-flight の合計値で決めています。
今後専用パラメータも計画しているようです。
この合計値と各 PriorityLevel の毎に設定されたspec.limited.assuredConcurrencyShares (ACS)で計算した値が各 PriorityLevel の実際の同時実行数になります。
具体的な値は以下の式によって計算されます。
ACV(l) = ceil( SCL * ACS(l) / ( sum[priority levels k] ACS(k) ) )
まとめ
この記事では API Priority and Fairness (APF) がどのようにリクエストを処理しているかという部分を紹介しました。
正直この辺の話はシャッフルシャーディングや Fair queuing などのアルゴリズムを知っている方であればすんなり理解できるのかもしれませんが、自分はそのへんの知識はなかったのでなかなか理解が難しかったです。
デフォルトでかなり細かく設定されているので今の所これ以上調整を必要とすることはあまりないかもしれませんが、特別扱いしたいカスタムコントローラなどがあれば FlowSchema と PriorityLevelConfiguration を追加することで調整が可能です。(正直パラメータ調整がかなり難しそうですが... ![]() )
)
kube-system などはデフォルトで保護されているので弊社では特別な設定は今のところ入れなくても良さそうに思っています。
今回の調査では全ては理解できていないのでまた時間があるときに余力があれば見てみたいと思います。
参考文献
- https://kubernetes.io/docs/concepts/cluster-administration/flow-control/
- https://github.com/kubernetes/enhancements/tree/master/keps/sig-api-machinery/1040-priority-and-fairness
- https://itnext.io/kubernetes-api-priority-and-fairness-b1ef2b8a26a2
- https://cloud.ibm.com/docs/openshift?topic=openshift-kubeapi-priority