これは株式会社マイホム アドベントカレンダー2023の 25日目の記事です。
記事の内容は会社の業務とは一切関係ありません。
前置き
最近、初心者のエンジニアさんとやりとりする機会がありまして、その中で出てきた、そういえば入門書的なものを読んでもこういった部分の考え方をフォローされることってあまりないかもしれないなぁ、という点について書いてみようと思いました。
前提とする状況
話の要点を絞るために使用例の多いパターン、MVCタイプのフレームワーク(Laravel)を使って、なるべくシンプルなCRUD(作成、読み出し、更新、削除)操作を行うWeb APIについて考えてみます。
シチュエーションとしては、同じチームに所属したユーザ間で記事を共有、コメントなどができるよくあるWebアプリケーションを想定してみます。
サンプルコードを簡単にするために実用性は一旦横に置いて、ユーザは必ず一つのチームに所属するという単純構造のデータベースで考えます。
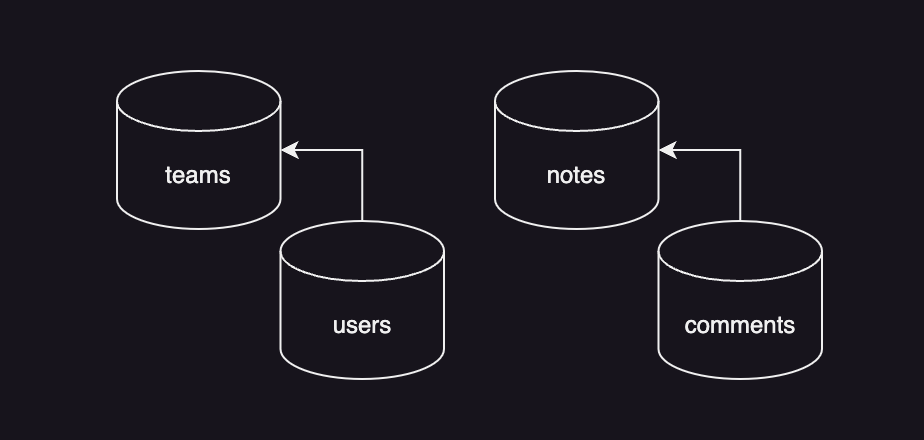
Schema::create('teams', function (Blueprint $table) {
$table->id();
$table->string('name');
$table->timestamps();
});
Schema::create('users', function (Blueprint $table) {
$table->id();
$table->foreignId('team_id')->constrained()->onDelete('cascade');
$table->string('name');
$table->string('email')->unique();
$table->timestamp('email_verified_at')->nullable();
$table->string('password');
$table->rememberToken();
$table->timestamps();
});
Schema::create('notes', function (Blueprint $table) {
$table->id();
$table->foreignId('team_id')->constrained();
$table->string('title')->nullable();
$table->text('content')->nullable();
$table->foreignId('created_by')->constrained('users');
$table->foreignId('updated_by')->nullable()->constrained('users');
$table->timestamps();
});
Schema::create('comments', function (Blueprint $table) {
$table->id();
$table->foreignId('note_id')->constrained()->onDelete('cascade');
$table->text('content')->nullable();
$table->foreignId('created_by')->constrained('users');
$table->foreignId('updated_by')->nullable()->constrained('users');
$table->timestamps();
});
C,U,Dの責任範囲
C(作成),U(更新),D(削除)とこれらの操作については、役割はわかりやすいですね。
アプリケーションの仕様に沿った値を正しく構成して、データベースを操作(作成、更新、削除)する、というところまでの責任を負っています。
これを投稿された記事に対してコメントを追加するというユースケースにおいて具体的に表すと、「チーム内の指定した記事に対してコメントを作成できる」となります。
コードで書くと以下のような内容になります。
// POST: /notes/{note_id}/comments
public function store(StoreRequest $request, int $note_id)
{
$user = Auth::user();
$param = $request->validated();
$param['team_id'] = $user->team_id;
$param['created_by'] = $user->id;
$param['updated_by'] = $user->id;
// チーム内の記事であることを保証するために、自分の所属チームという制限が必要
$note = Note::where('team_id', $user->team_id)->findOrFail($note_id);
$note->comments()->create($param);
return response()->json();
}
この処理の責任範囲を模式図にするとこんな感じですね。
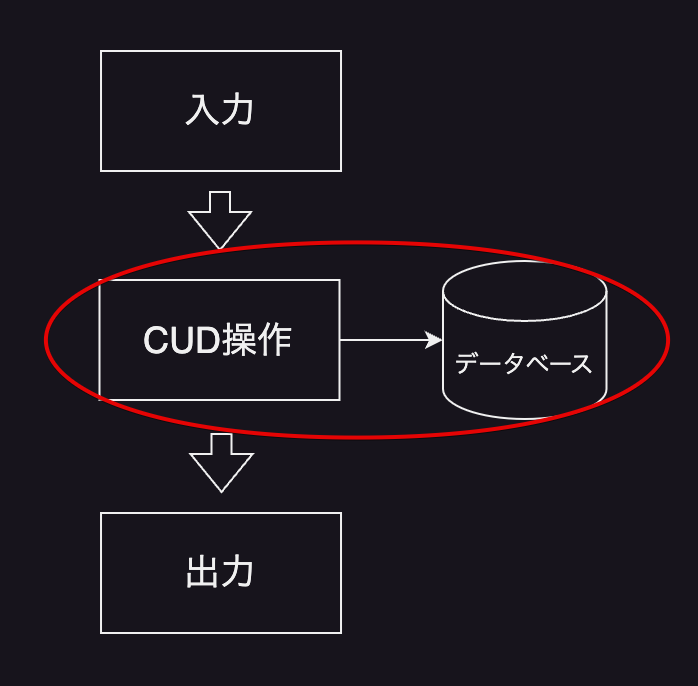
UもDも責任範囲という考え方では上記と基本的には変わりませんので省略します。
Rの責任範囲
実は先述のCUD処理の責任範囲については前振りのようなものでして、今回主題としてお話ししたいのはこちらだったりします。
CUD処理については初心者でも何を保証すれば良いのかわかりやすい話だと思います。
翻ってR(読み出し)についてはどうでしょう。
こちらはアプリケーションの仕様通りにデータを正しく読み出す、ということに責任を負っています。
特定の記事をコメントと共に読み出すというユースケースにおいて具体的に表すと、「チーム内の指定した記事とそれに紐づくコメントを読み出す」となります。
コードでは以下のようになるでしょうか。
// GET: /notes/{note_id}
public function show(int $note_id)
{
$user = Auth::user();
// NoteモデルからUser,Commentモデル、CommentモデルからUserモデルへリレーションが設定されているものとします
$note = Note::with([
'createdBy',
'updatedBy',
'comments',
'comments.createdBy'
])
->where('team_id', $user->team_id)
->findOrFail($note_id);
return response()->json($note);
}
こちらも模式図にしてみます。
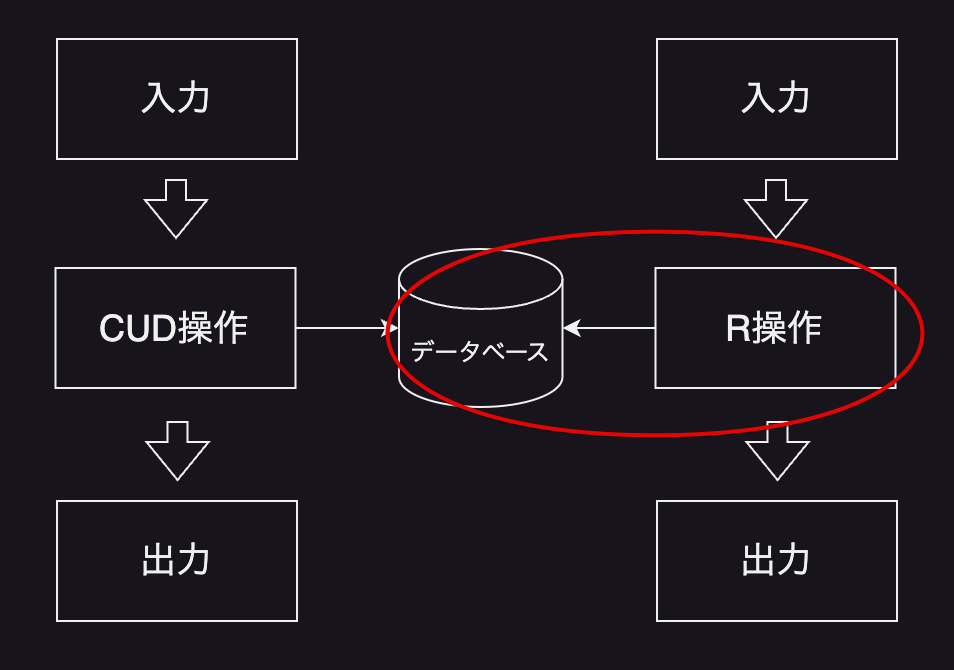
さて、CUD処理はデータベースに正しい仕様のデータを投入することを責務としていました。
であるならば、読み出し処理では改めてデータを検証する必要はないのでしょうか?
結論から言ってしまうと、読み出し処理は読み出し処理で可能な範囲のデータ検証(あるいは制限)はすべきです。
そして上記の読み出し処理では、可能な範囲のデータ検証(制限)という観点からは不十分といえます。
その点を加味して書き換えるとこうなります。
// GET: /notes/{note_id}
public function show(int $note_id)
{
$user = Auth::user();
// NoteモデルからUser,Commentモデル、CommentモデルからUserモデルへリレーションが設定されているものとします
$note = Note::with([
'createdBy' => fn ($query) => $query->where('team_id', $user->team_id),
'updatedBy'=> fn ($query) => $query->where('team_id', $user->team_id),
'comments',
'comments.createdBy' => fn ($query) => $query->where('team_id', $user->team_id),
])
->where('team_id', $user->team_id)
->findOrFail($note_id);
return response()->json($note);
}
※これはリレーションを使ってデータを取得する場合の制限方法です。アプリケーションの仕様によってはテーブル結合等を使って、SQL的に制限するといった方法もあるでしょう。その辺りは状況に応じて判断することになります。
読み出し側でもデータ検証(制限)をすべき理由としては、端的に言ってしまうとCUD処理とR処理は責任範囲が違うから、ということになるのですが、これは理念的な話だけではなく、明確なリスク低減という効果をもたらしてくれます。
データベースはアプリケーションとは独立したシステムであること
通常はアプリケーションを通じての入力しかないとしても、データベースにはSQLクライアントで直接アクセスすることができます。
システムを運用していけば、メンテナンスやサポート対応作業等でデータベースの値を直接操作するということはままあることです。
そんな時はアプリケーションによる検証を回避してしまうことになります。
こうして入り込んだ値には間違いが発生しているということは考えられるリスクでしょう。
機能追加、仕様変更などに伴う改修がある
開発当初のままで運用し続けるアプリケーションというものは稀です。運用を継続していけば、ほぼ必ず改修をおこなうようになります。
いつの間にか機能が追加されて対象テーブルへの入り口になる処理が増えているかもしれませんし、既存機能の改修を行えば今まで問題がなかった処理もおかしな値を送り込んでくるようになるかもしれません。
まとめ
今回のサンプルで考えると、記事とコメントの作成、更新者のIDがチーム外のユーザIDと取り違えが起きていても、読み出し処理側もデータを検証(制限)する仕組みを持っているので、間違ったユーザ情報を提示してしまうという事態を防げる可能性があります。
(作成、更新者の表示を間違っただけといっても、実際にユーザ目線での現象としてはいきなり誰とも知らない人が出てきてしまうわけなので、いざ発生すれば、まあ大ごとに発展するのが目に見えますね…)
このように各の責任範囲において適切な制御を行っておくことで、データベース操作に不備があっても大丈夫(かもしれない)、バグにより想定外の値を設定してしまっても大丈夫(かもしれない)、というように安全対策を多重にしておくことができるのです。