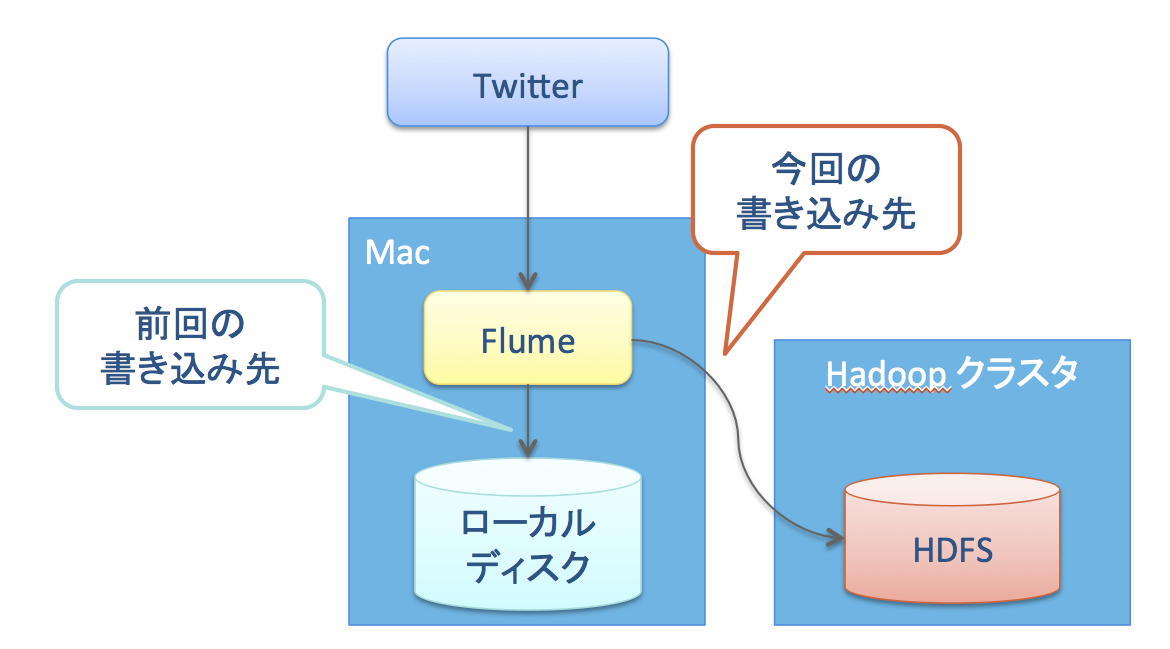
前回はFlumeを使ってMac上でTwitterのツイートをローカルファイルに保存する方法を説明した。
今回はMac上のローカルファイルシステムではなく外部のHadoopクラスタのHDFSに書き込む方法を紹介する。
環境
- Flume バージョン: CDH 5.4.2 (1.5.0 ベース)
- OS: Mac OS X 10.10.3
準備
前提条件
- Flumeからローカルファイルシステムへの書き込みの設定が完了していること。
- Cloudera Manager を使用して 外部のHadoopクラスタの構築が完了していること。環境を持っていない場合はQuickstart VMの設定を元に構築すること。以下の記事では外部HadoopクラスタとしてQuickstart VMを用いている。
以下の記事で使用する前提を再掲する。
Flume のホームディレクトリ = ~/lib/flume
Hadoopクライアントのダウンロード (Mac側設定)
Cloudera のリポジトリからHadoopのtar.gzを取得する。 最新版へのリンク
適当な場所に Hadoop を設置し、展開する。私は ~/lib/hadoop にしている。
flume-env.sh の作成 (Mac側設定)
~/lib/flume/conf/flume-env.sh.template を元に、 flume-env.sh を作成し、以下の設定を追加する。
export JAVA_OPTS="-Xms100m -Xmx1000m -Dcom.sun.management.jmxremote"
export HADOOP_HOME=~/lib/hadoop
Hadoop の設定ファイルの取得 (Mac側設定)
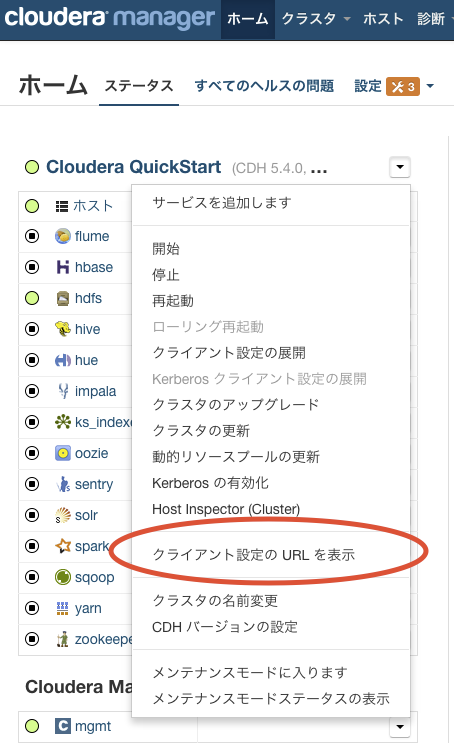
Cloudera Manager のホームページをMacのブラウザから開く。アドレスは http://<CMのアドレス>:7180/。
下図の通り、メニューからクライアント設定をダウンロードする。
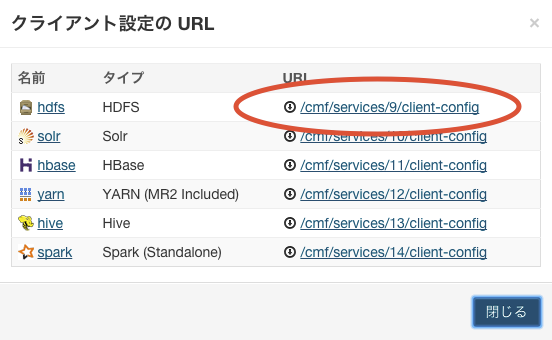
ダウンロードした hdfs-clientconfig.zip を ~/lib/hadoop 以下に展開し、conf にリネームする。
設定ファイルの作成 (Mac側設定)
適当なファイルを作る。ここでは ~/etc/flume/twitter-hdfs.confとする。
以下の情報を入力する。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = org.apache.flume.source.twitter.TwitterSource
a1.sources.r1.channels = c1
a1.sources.r1.consumerKey = YOUR_CONSUMER_KEY
a1.sources.r1.consumerSecret = YOUR_CONSUMER_KEY_SECRET
a1.sources.r1.accessToken = YOUR_ACCESS_TOKEN
a1.sources.r1.accessTokenSecret = YOUR_ACCESS_TOKEN_SECRET
a1.sources.r1.maxBatchSize = 50000
a1.sources.r1.maxBatchDurationMillis = 100000
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://<NameNodeのアドレス>/user/flume/tweets/%y-%m-%d
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.inUseSuffix =
a1.sinks.k1.hdfs.inUsePrefix = _
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.batchSize = 1000
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 600
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.serializer = avro_event
a1.sinks.k1.hdfs.serializer.compressionCodec = snappy
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
前回の例とは異なり、Sink を file_roll から hdfs に変更している。これにより HDFS にログを書き出すようになる。
ディレクトリを %y-%m-%d と指定することで、「年-月-日」というディレクトリに書き出すようになる。日付が変わると別ディレクトリを作成する。
データの保存ディレクトリの作成(Hadoopクラスタ側設定)
この例ではHDFS上の /user/flume にデータを保存するので、ディレクトリを作っておく。
HDFSクラスタにログインして、以下のコマンドを実行する。
パーミッションを 777 にしているが、書き込みができればどのようなパーミッションでもよい。
$ sudo -u hdfs hdfs dfs -mkdir /user/flume
$ sudo -u hdfs hdfs dfs -chmod 777 /user/flume
ログの取得と閲覧
Flume の起動 (Mac側設定)
Mac上で、~/lib/flume に移動して以下のコマンドを実行すればログの収集が始まる。
$ bin/flume-ng agent -n a1 -c conf -f ~/etc/flume/twitter-hdfs.conf -Dflume.root.logger=INFO,console
hdfs dfs -text によるログの閲覧 (Mac側設定)
hdfs dfs -text は Avro フォーマットを閲覧できる。Mac上で ~/lib/hadoop に移動し、以下のコマンドを実行すれば、ログファイルを閲覧することが可能。
dfs -ls コマンドでファイル名を確認し、dfs -text でそのファイルを指定する。
$ bin/hdfs dfs -ls hdfs://172.16.146.148/user/flume/tweets/
$ bin/hdfs dfs -text hdfs://172.16.146.148/user/flume/tweets/15-05-29/FlumeData.XXXXX