Cloudera Data Science Workbench (以下CDSW) 上で、PyArrowからHDFSに接続するための方法をまとめておく。
PyArrowからHDFSに接続するための基礎知識
PyArrowは libhdfs.so を使ってHDFSに接続する。
そのため、このライブラリが正しくロードされるかどうかが重要となる。
PyArrowは、デフォルトでは $HADOOP_HOME/lib/native 以下を参照して libhdfs.so を検索するが、存在しない場合は ARROW_LIBHDFS_DIR 以下を検索する。
インストール
以下のファイルを作成しておく。
requirements.txt
pyarrow
セッション起動時に以下のコマンドを実行する。
!pip3 install -r requirements.txt
環境変数の設定
libhdfs.so は、デフォルトでは /opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/lib64 以下に存在するので、これを ARROW_LIBHDFS_DIR に指定する。
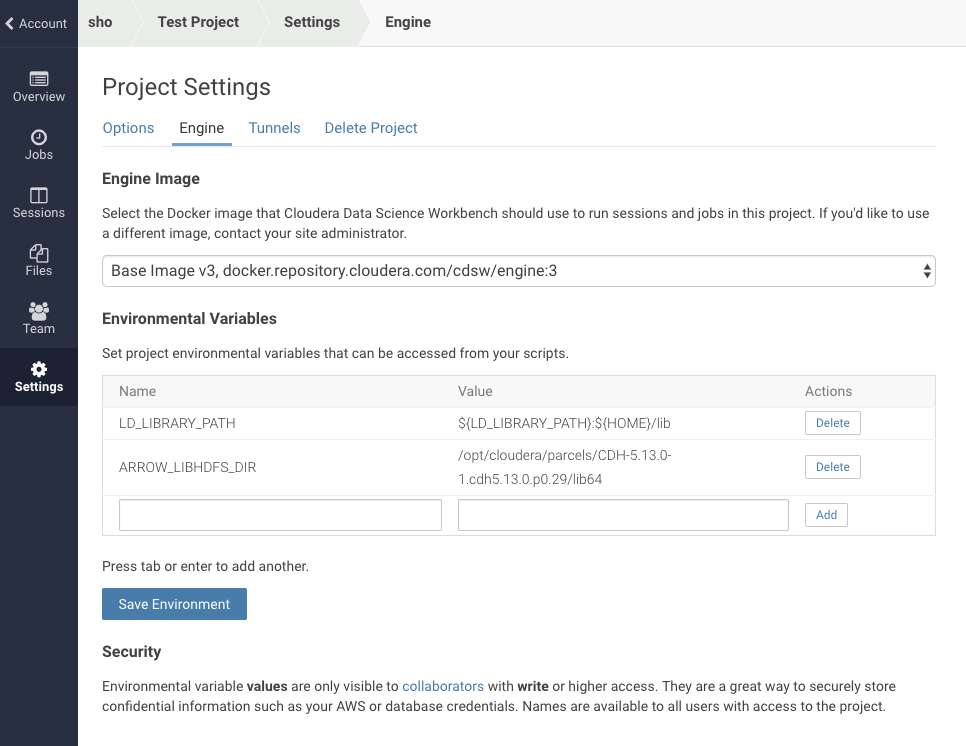
Settings → Engine を選択すると、セッション起動時に読み込む環境変数を指定できるので、以下のように入力する。
| 変数 | 値 |
|---|---|
| ARROW_LIBHDFS_DIR | /opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/lib64 |
Addするだけでなく、Saveしなければいけないことに注意。
また、セッションは再起動する必要がある。
Kerberosのチケットの場所の確認
!klist を実行することで簡単に確認できる。
!klist
Ticket cache: FILE:/tmp/xxxxxx
接続する
import pyarrow as pa
fs = pa.hdfs.connect(host, port, user=user, kerb_ticket='tmp/xxxxxx')
これで、HDFSのデータをPyArrow上で取り扱えるようになる。