まずはおさらい
AWSにおけるWell-Architected Freamworkの5つの原則のうちの1つの信頼性(Reliability)は以下の通りである。
- インフラサービスの障害復旧の自動化を図る
- 復旧手順の検証を行う(BDPに復元/フェイルオーバーの手順を追記で作成し、実際に行って復旧までどれだけ時間がかかるかテストする等)
- 需要変化に応じて水平スケーラビリティを行う
- キャパシティの推測をやめる
- モニタリングと自動化を推進する
これらを実現するために必要な主要なサービスは以下の通りである。
- IAM
- VPC
- Auto Scaling
- ELB
- Cloud Formation
- Cloud Trail
- Cloud Watch
またベストプラクティスで考えると
- スケーラビリティの確保
- 単一障害点の排除
- コンポーネントの疎結合
- 環境の自動化
が信頼性の確保につながるものになる。
高可用を求める
信頼性を確保するための手段の1つとしてサービスの可用性を高くするということが考えられる。
スケーラビリティや単一障害点の排除の考え方はこれにあたる。
高可用性の非機能要件
以下の点が要件となる。
- RTO(Recovery Time Objective)……目標復旧時間
- RPO(Recovery Point Objective)……目標復旧時点、つまり復旧する場合はどの時点のバックアップデータまで遡るかという基準
- 耐障害性
- 復元可能性……システム障害や災害発生時にサービス復旧に関わる機能とプロセスとポリシー
- 拡張性
なおこれらは突き詰めれば突き詰めるほど、コストとインフラ構成の複雑さが上がる。
AWSでの高可用性を求めるには?
サービス配置という視点
- サービスを単一リージョンに配置するのか、マルチリージョンに配置するのか
- マルチAZでフェイルオーバー、レプリケーションを図るのか
- VPC設計(複数VPC、サブネット設計)から考える、例えばマルチAZで負荷分散を図った場合、NATゲートウェイを双方のパブリックサブネットに置くがそれぞれのプライベートサブネットからアクセスできるようにルートを通しておくなど。
AWSサービスの利用
- Route53を利用してフェイルオーバーをできるようにする
- ELBでロードバランシングする
- Cloud Watchでモニタリングする(キャパシティを推測せず、適切に管理する)
- Auto Scalingによってスケーラビリティを確保する
- Lambdaでスケーリング処理を行う
- ElasticCacheを利用して、キャッシュアクセスを活用する
また、常々触れられて来ているがAWSサービス自体が高い可用性があるマネージド型のものが多かったりする。
単一障害点が起きやすいサービス
以下のサービスはELB、Route53などを利用して高可用の設計を行う必要がある。
- EC2(マルチAZ等でELBを使って負荷分散とフェイルオーバー体制を整えるかマルチVPCで同じ環境を作っておく)
- DirectConnect
- RDS(EC2と同じでフェイルオーバー体制を整え、プライマリ・スレーブの関係を構成しつつリードレプリカを作成し負荷軽減を行う)
例を上げると単一VPCかつ単一AZにEC2とRDSを置いた場合、VPC・AZ・EC2・RDSのどれか一つでも障害が起きた場合はシステムダウンとなる。
またインスタンス障害に対しては、Elastic IPを設定することで同じパブリックIPを持つ別のインスタンスにElastic IPを移し替えることでRoute53からの処理をそちらへ迂回させるということも有効である。
ELBとAuto Scaling
まずはフェイルオーバーやレプリケーション等をやる前提条件として必要となるマルチAZ構成アーキテクチャの設計を考える上で必須と言ってもいい、ELBとAuto Scalingを見ていく。
ELB
マネージド型のロードバランシングサービスでEC2インスタンスの処理を分散する際に標準的に利用するもの。
主な特徴は以下の通り。
- インスタンス間の負荷を分散する(負荷分散)
- 異常なインスタンスを認識して対応する(ヘルスチェック)
- パブリック/プライベート両サブネットに対して使える
- ELB自体にも負荷に応じてキャパシティを自動でスケーリングすることができる
- 従量課金制
- Auto Scaling、Route53、Cloud Formation等と連携できる
主要な機能は以下の通り。
ヘルスチェック
EC2インスタンスの状態を確認して、異常が見られる場合は利用するEC2の振り分けを行う。
例えば2つAZでフェイルオーバー体制を作っている場合は、メインのインスタンスに異常が見られた場合にRDSなどと合わせてサブのインスタンスへ自動でフェイルオーバーさせることもできたりする。
負荷分散
配下のEC2の負荷に応じて、複数のAZにまたがるEC2インスタンスの負荷分散を行う。
スケーラビリティの確保に関わる部分で具体的にトラフィック量を指定して分散させることもできる。
SSLサポート
ELBでSSL Terminationできる。
SSL経由でSSL認証を行える。
ステイッキーセッション
セッション中に同じユーザーから来たリクエストをすべて同じEC2インスタンスに送信する。
Connection Draining
インスタンスが登録解除されるか異常が発生した場合に、そのバックエンドインスタンスへの新規リクエスト送信を中止する。
つまり、異常が確認されたインスタンスにおいて既存の処理がまだ残っている場合はそれを完了させることが優先される。
S3へのログ保管
ELBのアクセスログを指定したS3に自動保管
ELBのタイプ
CLB
初期に提供されたELBで現在はあまり使われない。
特徴としては以下の通り。
- HTTP/HTTPS及びTCP/SSLプロトコルのL4とL7に対応している
- Proxyプロトコルによる発信元IPアドレス識別
- ELBとバックエンドのEC2インスタンス間でHTTPS/SSL使用時にはサーバー証明書認証を実施
- CLB配下の新スタンスは、全て同一の機能を持ったインスタンスが必要
- 異なる機能に対してコンテンツベースルーティングができない
コンテンツベースルーティングはリクエストがどのように転送されるかを条件とアクションで定義してルーティングする仕組み。
後述のALB等と違って、パスルーティングができないので1つのLBに対しては同一の機能のインスタンス(1つのLBに対して1ドメイン)に対してしかバランシングを行えないので、複数機能(この場合だと例えば商品注文と発送管理の機能とでドメインを分ける)の場合はLBを機能の分だけ作って管理しないといけないということになる。
ALB
現在の標準的なELBタイプ。
レイヤー7の対応が強化された単一ロードバランサーで、異なるアプリケーションへのリクエストをルーティングできる。
特徴としては以下の通り。
-
コンテンツベースルーティングの他にURLのパスに基づいて、ルーティングが可能なパスベースルーティングが可能
-
WebSocketとHTTP/2のリクエストを受付
-
1インスタンスに複数のポートを登録できる
-
EC2インスタンスをターゲットグループに割り当てることで、複数ポートを個別のターゲットとして登録できるため、ポートを利用するコンテナに対してもロードバランシングが可能となる
-
ターゲットグループでのヘルスチェックが可能
-
アクセスログの情報を追加
-
EC2と同様に削除保護ができる
-
ALB自体が自動的にキャパシティを増減できる
CLBと違ってEC2インスタンスをグルーピングすることでそのグループごとで異なるロードバランシングを行えたり、パスルーティングが行えるので1つのLBで複数機能のバランシングを管理できる。
CLBでの例で行くとパスでルーティングできるので同一ドメインでも/order、/shippingというパスをALBが自動で判断してバランシングしてくれるということになる。
NLB
ALBよりも高負荷が想定されるインスタンスにおいてのバランシングをする際に使用する。
主な特徴としては
-
超低遅延・高スループットを維持しつつ秒間数百万リクエストをバランシングすることが想定されている
-
開放型システム間相互接続(OSI)モデルの固定IPアドレスを持つL4ロードバランサー
-
揮発性和ワークロードを処理し、毎秒数百万のリクエストに対応
-
VPC外のターゲットを含めたIPアドレスや静的IPアドレスも登録ができる
-
複数のポートで各インスタンスまたはIPアドレスを同ターゲットグループに登録可能
-
大規模アクセスが予想される際にCLBやALBで必要だったPre-warming申請が不要
-
ALBやCLBはX-Forwarded-Forでアクセス元IPアドレスを判断していたが、NLBは送信元IPアドレスと送信元ポートの書き換えを行わないという仕様のため、パケットからアクセス元を判断することができる
-
NLBはフォルトトレランス(構成要素の一部が故障、停止などしても予備の系統に切り替えるなどして機能を保ち、正常に稼動させ続けるための仕組みを用意したり、設計しようという考え方)機能を内蔵したコネクション処理を持ち、数ヶ月から数年のオープンなコネクションを処理できる
-
コンテナ化されたアプリケーションをサポートしている(Docker)
-
各サービスの個別のヘルスステータスのモニタリングをサポートしている
GLB
Gateway Load Balancerの略。
1番新しいLBで、東京リージョンでの解禁も2021/05/25と直近の出来事である。
AWS Gateway Load Balancer のご紹介
[新サービス]セキュリティ製品等の新しい展開方法が可能なAWS Gateway Load Balancerが発表されたので調査してみた
セキュリティ、ネットワーク分析、およびその他のユースケースでサードパーティーのアプライアンスを操作するのに最適です
と公式の説明であるのと上記参考記事を見るにサードパーティ製のセキュリティ製品をAWSで扱う場合にNLBまででは、複雑な構成であったものをこちらを利用することでよりシンプルにしつつ、高可用性を保つことができるLBということ。
Auto Scaling
リソースを利用状況を分析した結果によってスケジューリングしたり手動でそのキャパシティを調節するための仕組み。
ベストプラクティスの話でいうと、ELBと合わせて信頼性・パフォーマンス効率に跨るスケーラビリティの確保の分野の機能となる。
その特性上(自動的に増やしたリソースを必要なくなった場合、自動で削除する等の仕組みがあったりする)、EC2とともに使い捨てリソースの使用などと言われたりもする。
実際にはELBで負荷分散等をした上でそれでもトラフィック量の増加に対応できないことがあった場合、ヘルスチェックで異常と判断され、それに応じて自動でキャパシティを拡張することで障害を回避するという使用方法になってくる。
また、Cloud Watchでリソースの利用を分析し、アラートを作成してそれに基づいてスケーリングを行うということも考えられる。
スケーリングのタイプ
スケーリングには垂直と水平と2種類のパターンがある。
垂直スケーリング
アップ(拡張)、ダウン(軽減)となる。
また、スケーリング対象はCPU及びメモリになるのでインスタンスの性能を変化させるタイプのスケーリングとなる。
EC2やRDS等のスケーリングはこちらに当てはまる。
- スケールアップでメモリ・CPU等の拡張
- スケールダウンでメモリ・CPU等の削減
水平スケーリング
アウト(拡張)、イン(低減)となる。
垂直に比べてやや紛らわしい感じがするが、スケーリング対象がサーバー・機器となるので、
最初に決めたスケールから超えてしまうからスケールアウト、一方でスケールに余裕がある(できた)ので中に収められるからスケールインと覚えるとわかりやすい。
- スケールアウトで機器・サーバーの増設
- スケールインで機器・サーバーの削減
Auto Scalingの機能
Auto Scalingグループ
スケールするインスタンスの最大数など基本情報を設定するための機能。
- 起動インスタンスの最小数と最大数を設定する
- 現時点で必要な最適なインスタンス数(Desired Capacity)の数量になるようにインスタンスを起動・終了を調整する
- 起動台数をAZ間でバランシングする
- AZ障害時は障害のない別のAZにその分のインスタンスを起動する
Auto Scaling configuration(起動設定)
スケールアウト、つまり増設の際に起動するインスタンスの内容の設定を行う。
内容としては以下の通り。
- AMI
- インスタンスタイプ
- セキュリティグループ
- キーペア
- IAMロール
ターミネーションポリシー
需要減に基づくスケールインの際にどのインスタンスから終了するかを設定する。
-
OldestInstance(最も古いインスタンスから終了する)
-
NewestInstance(最も新しいインスタンスから終了する、既存のインスタンスに対してAuto Scalingを適用したい場合はこちらの設定を適用しないとスケールアウトした後、スケールインした場合既存のインスタンスを削除されてしまう)
-
OldestLaunch Configuration(最も古い起動設定により起動しているインスタンスから終了)
-
Closest To Next Instance Hour(次の課金がハイz丸タイミングが最も近いインスタンスから終了)
-
デフォルト(OldestLaunch Configuration → Closest To Next Instance Hourの順で適用したあと、ランダムに終了する)
Auto Scaling Plan
スケールのやり方やスケジューリングに関しての設定を行う。
- Auto Scalingグループのサイズの維持(現在のAuto Scalingグループでのインスタンスの最小台数を維持する)
- 手動スケーリング(設定外で予期せぬスケーリングが必要となった場合、手動でも行える)
- スケジュールベース(需要増が予め見込まれる時期に対して、スケーリングをスケジューリングできる)
- 動的スケーリング(想定外の需要増に対して、予めスケーリングポリシーにスケール方針を設定して、動的にスケールアウトを行うことができる)
これらは複数組み合わせることもできるので、スケジューリングしたスケーリングに対して、それでも想定以上に需要が見込まれた場合に動的スケーリングを行う……なんてこともできる。
Auto Scalingの設定
プロセスは以下の通り。
- ELBの作成
- 作成したELBでターゲットグループを作成する
- 起動インスタンスを設定及びAuto Scaling起動設定を行う
- Auto Scalingグループを設定
- ターミネーションポリシー、Auto Scalingポリシー、スケジューリングの設定を行う
またポイントとしては以下の通り。
-
インスタンスの最大/最小の設定は慎重に行う(キャパシティの推測は行わないの原則)
-
ステートフルなアプリケーションへの設定には、Auto Scaling Groupでの自動設定が必要
-
ライフライクルフック(起動時または削除時にインスタンスを一時停止してカスタムアクションを実行できる機能、例えば起動・削除時に応じてログを取得するようにするなど)を使用する
-
Auto Scalingスラッシングを避ける(急なスケールインによる影響のことをAuto Scalingスラッシングという)
RDS
AWSではEC2インスタンスに直接DBを作ることでDBサーバーとすることもできるが、RDSを利用することでEC2に直接DB程度を作らずにEC2インスタンスをDBサーバーにすることもできる。
RDSは様々なデータベースソフトウエアに対応したフルマネージドなリレーショナルデータベース。
以下のようなデータベースソフトウェアを選択して、そのDBを構築することができる。
- MySQL
- ORACLE
- Microsoft SQL Server
- PostgreSQL
- MariaDB
- Amazon Aurora
マネージド型のサービスのため、管理・運用はEC2インスタンスに直接DBを作るケースに比べて楽になるがその分制約もある。
主な制限としては
- 利用するDBソフトウェアのバージョンが限定される(例えば最新のバージョンは利用できないことがある)
- キャパシティに上限がある
- OSへのログインはできない
- ファイルシステムへのアクセスはできない
- IPアドレスが固定できない
- DBの一部の機能が使えないことがある
- 個別にパッチを適用できない
RDSを選択しない理由になりそうなのはファイルシステムへのアクセス不可と個別にパッチを適用できない部分。
これらが必要な場合は、EC2インスタンスに直接DBを作るしかない。
特徴としては以下の通り。
-
マネージド型サービスかつ高可用性がAWSに保証されている
-
プライマリ・スレーブ関係をマルチAZに用意に構築できるので、同期レプリケーション等も容易に構築できる
-
自動フェイルオーバー機能がある
-
リードレプリカ(データ参照専用のレプリカ、これを作ることで参照時にDB本体へ負荷がいかないので負荷分散につながる)を作成でき、さらにそれ対して非同期でレプリケーション(一部例外で同期レプリケーション)を行うことができる。
-
リードレプリカは別のAZ(プライマリだけでなく、スレーブの方)にも作れる
-
リードレプリカは5台(Auroraの場合は15台)まで作れる
-
スナップショットやトランザクションログをS3に保存することでバックアップを取ることもできる
RDSのスケーリング
マネージメントコンソールやAPIからスケールアップが可能。
- インスタンスに対してスケーリングする(垂直スケーリング)
- CLIやAPIからストレージを用意にスケーリングすることができる
- 一時的にインスタンスタイプを大きくして、その後スケールダウンすることも可能
- ストレージサイズは拡張はできるが縮小はできない(DBの整合性の問題)
- スケールアウトはリードレプリカ等で実現する
また、シャーディングと呼ばれるソフトウェアを利用することでRDSの書き込み処理をスケーリングすることもできる。
(ex. IDが1001~2000まではRDS1、IDが2001~3000まではRDS2に書き込む等。スケーリングというより、ルーティングとかバランシングな気もする)
RDSにおけるスケールアップ
以下の3パターンに分かれる。
- インスタンスサイズの変更(同タイプ内でのスケールアップ。例えばmicroからlargeへと変更するなど)
- インスタンスタイプの変更(インスタンスタイプ自体が合わない場合はDBインスタンス性能自体をスケールアップする)
- ストレージタイプを変更(プロビジョン度IOPSが必要であるならそちらへ変更する)
なお、前述の通りストレージタイプのスケールダウンはできない。
インスタンスタイプはインスタンスの性能領域、つまり得意分野を決める部分。
インスタンスサイズはそのインスタンスタイプ内でのパフォーマンス幅を決める部分。
RDSにおけるスケールアウト
EC2インスタンスとは違い、直接RDSを増設するのではなく以下の3パターンで行われる。
- リードレプリカの増設(読み込み処理のアクセス集中を分散化するため、読み込み専用インスタンスとなるリードレプリカを増設して、負荷分散する)
- キャッシュの利用(ElasticCacheを連携または、MYSQL Memcached機能(インメモリな機能、SQLクエリに対してキャッシュを使用することができるようになる)を利用してキャッシュを増設し、読み込み処理の高速化を実施する)
- Auroraへの移行(スケールアウトとは厳密には違う。同じMySQLでもAurora MySQLの方が高性能なので移行すると性能がアップするという理屈)
リードレプリカについて
- フェイルオーバー設定を有効にすると自動でフェイルオーバーしてくれる
- 最大5(Auroraを利用する場合は15)台まで作成可能
- マルチAZ、クロスリージョンなどと併用もできる。つまりプライマリDBがあるAZやリージョン以外のそれにも作成できる
- インスタンスやストレージをDBとは別のタイプでも設定できる
- 障害対応などでリードレプリカから、スタンドアロンのDBインスタンスに手動で切り替え可能
- Auroraを利用する場合はリードレプリカをプライマリーインスタンスに昇格させることもできる
キャッシュの利用
- ElasticCacheを利用することで一度行われたクエリ処理をインメモリDBに保持することができる
- MySQLの場合はMemcached機能を使う
つまり、これらの機能を有効にしておくとEC2インスタンスからの処理をキャッシュのあり無しで振り分けして、ElasticCacheで処理できるようであればクエリは実行されずに済む……ということで高速化につながる。
人間でいうと脊髄反射みたいな感じ。
RDSにおけるインスタンスタイプ
以下の2つに分かれる。
- 汎用(標準的なやつ。多様なワークロードに対応できる)
- メモリ最適化(メモリ内の大きいデータセットを処理することが想定される場合に使う。つまり、高速データベースにする必要がある場合はこちら)
また例によってインスタンスファミリーが存在する。
汎用インスタンスタイプ
以下はいずれも汎用的に使えるが、その中でも得意とする領域がある。
-
T2
→
標準的な汎用バーストパフォーマンスインスタンス。
ベースラインレベルのCPUパフォーマンスを提供し、ベースラインを超えてバーストする機能を有するもの。
マイクロサービス、テスト及びステージングDBなどに適している。 -
T3
→
T2の上位版。
使用中に一時的なスパイク(瞬間的に値が上昇すること)が生じる中程度のCPU使用率を持つDBワークロードに適している。 -
M4
→
オープンソース、エンタープライズアプリケーション用の小規模~中規模DBに適している。 -
M5
→
汎用インスタンスの中でも特に最新世代となるインスタンス。
M4の上位版になる。
メモリ最適化インスタンス
メモリ負荷の高い処理や高速データベース処理に適しているという特徴があるがその中でも各インスタンスごとにも強みがある。
-
R4
→
メモリ最適化インスタンスの中でも安価。 -
R5
→
R4の上位版。
R4に比べて、vCPUあたり5%大きいメモリを提供するインスタンス。
最大で768GiBのメモリを提供する。
R4と比較してGiBごとの価格はさらに10%安くなっているが、CPUパフォーマンスは最大で20%ほど高くなっている。 -
X1
→
大規模アプリケーションやエンタープライズクラス(大企業~中堅企業及び官公庁向けという意味)のアプリケーション、インメモリアプリケーション(ディスクではなく、データストレージ用メモリに保存することで、データアクセスをメモリ上で行うことができ結果高速になるやつ)用に最適化されたインスタンス。
RDSのインスタンスタイプの中でもRAM1GiBあたりの価格が最も低いインスタンスの1つでもある。 -
X1e
→
X1のマイナーチェンジ版。
高性能データベースに最適化されていて、RDSのインスタンスタイプの中でもRAM1GiBあたりの価格が最も低いインスタンスの1つでもある。 -
Z1d
→
クラウドインスタンスの中でも最も高速で、すべてのコアの周波数を最大4.0Ghzで持続可能なインスタンス。
つまり、高いコンピューティング性能と大容量メモリが求められるリレーショナルデータベース向き。
RDSのストレージタイプ
-
汎用(標準的なやつ。SSD。GBあたりの容量課金。通常のパフォーマンスに加えてバーストを実施して100~10000IOPSを実現可能)
-
プロビジョンドIOPS(SSD。GBあたりの容量課金に加えてプロビジョンドを適用したIOPSに対して課金が行われる。サイズによって変わるが、バーストによって1000~30000IOPSを実現可能)
-
マグネティック(レガシーなタイプ。HDD。GBあたりの容量課金に加えてIOリクエストに対して課金。平均100~最大数百IOPS)
RDSの暗号化
DBなので当然暗号化の仕組みも用意されている。
特徴としては以下の通り。
- リードレプリカにも同じ鍵を利用しないといけない
- インスタンス作成時にのみ暗号化の設定は可能
- スナップショットのコピーにも暗号化・リストアが可能
暗号化の対象は以下の通り。
- DBインスタンス
- 自動バックアップ
- リードレプリカ
- スナップショット
暗号化の方式は以下の通り。
- AES-256
- AWS KMS
マルチAZでRDSを利用する
- 利用目的…… 高可用性を求める
- 同期方法…… Auroraは非同期レプリケーション、それ以外は同期レプリケーション
- アクセス…… Auroraはすべてのインスタンスがアクティブとなるが、それ以外はプライマリインスタンスのみ
- バックアップ…… 自動バックアップが利用可能、Auroraの場合は共有ストレージレイヤーから、それ以外はスタンバイから取得
- 配置…… 1つのリージョン内に常に2つ以上のAZを展開することが前提
- フェイルオーバー…… Auroraの場合はリードレプリカ、それ以外はスタンバイ(レプリケーション先)への自動フェイルオーバー
マルチリージョンでRDSを利用する
- 利用目的…… 災害復旧とローカルパフォーマンスの向上
- 同期方法…… 非同期レプリケーション
- アクセス…… すべてのリージョンにアクセスでき、読み取り用として利用できる
- バックアップ…… 各リージョンで自動バックアップを取得可能
- 配置…… 各リージョンに対してマルチAZ配置が可能
- フェイルオーバー…… Auroraを利用している場合は、セカンダリリージョンのプロモーションをマスターに昇格可能
上記2つと比較したリードレプリカ
- 利用目的…… スケーラビリティ
- 同期方法…… 非同期レプリケーション
- アクセス…… すべてのリードレプリカにアクセス可能であり、データ読み込みという点に対してのスケーリングに利用できる
- バックアップ…… デフォルトではバックアップは作成されない
- 配置…… AZ内、AZ間、リージョン間に配置できる
- フェイルオーバー…… 手動でスタンドアロンのDBインスタンスとして昇格させることができる。Auroraの場合はプライマリインスタンスにすることもできる
ハンズオン
ELB周り
ウィザードで作ったあと別AZにも同じものを作る。
ウィザード外でサブネットを作った場合は、パブリックサブネットの方に自動割当IPの設定をしておく。
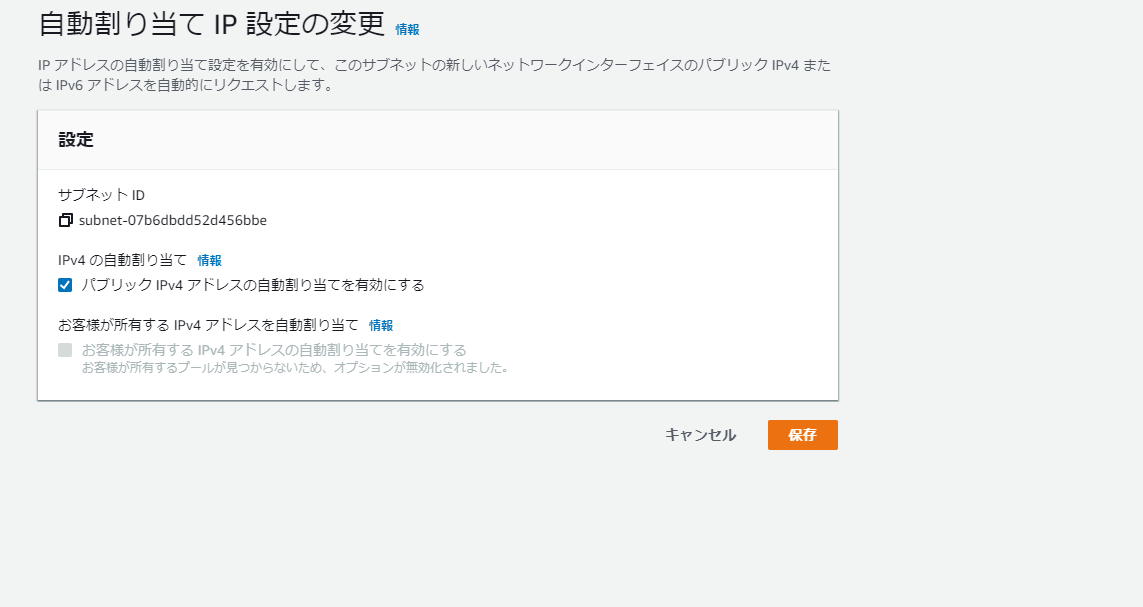
あとはCLI等で確認、インスタンス作成ウィザードでbashコマンドを予め入れておくとよい。

無事できたことが確認できる。

あとは作ったインスタンスからイメージ(AMI)を作って

作ったAMIから別AZに同じインスタンス構成を作る。

ロードバランサー選択は以下の通り(2021年5月現在)
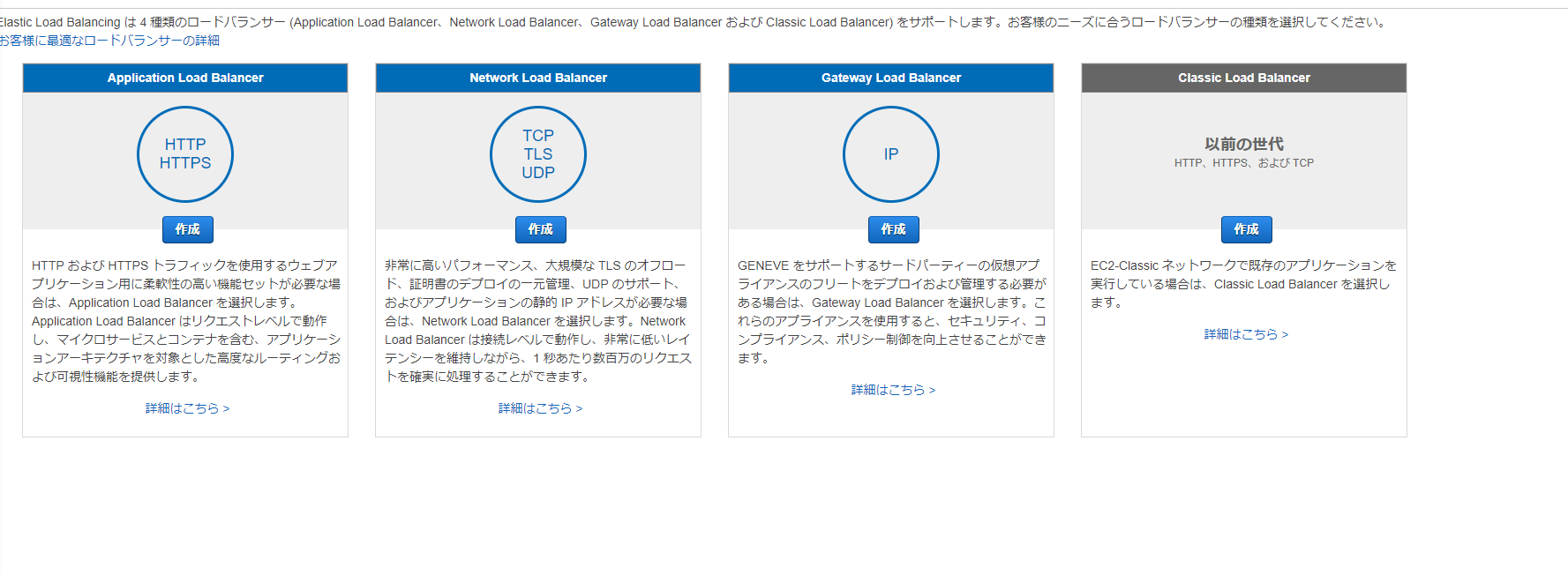
あとはウィザードに従って作っていく

ヘルスチェックは以下の通り。
タイムアウトは指定秒数を超えたらヘルスチェックをタイムアウトさせる。
間隔はヘルスチェックを行う間隔を指定。



ターゲットグループの設定。
インスタンスを指定して作る。


Auto Scaling
まずは起動設定。




次にAuto Scalingグループの設定。

ELBとセットで使いたいことが見て取れる。
またAuto Scalingでもヘルスチェックが指定できる(スケーリングはここで判断される)



編集もできる。
以下はターミネーションポリシーやスケールイン保護(新規にスケールアウトしたインスタンスをスケールインさせないようにする設定)

既存のインスタンスにアタッチさせることもできる。
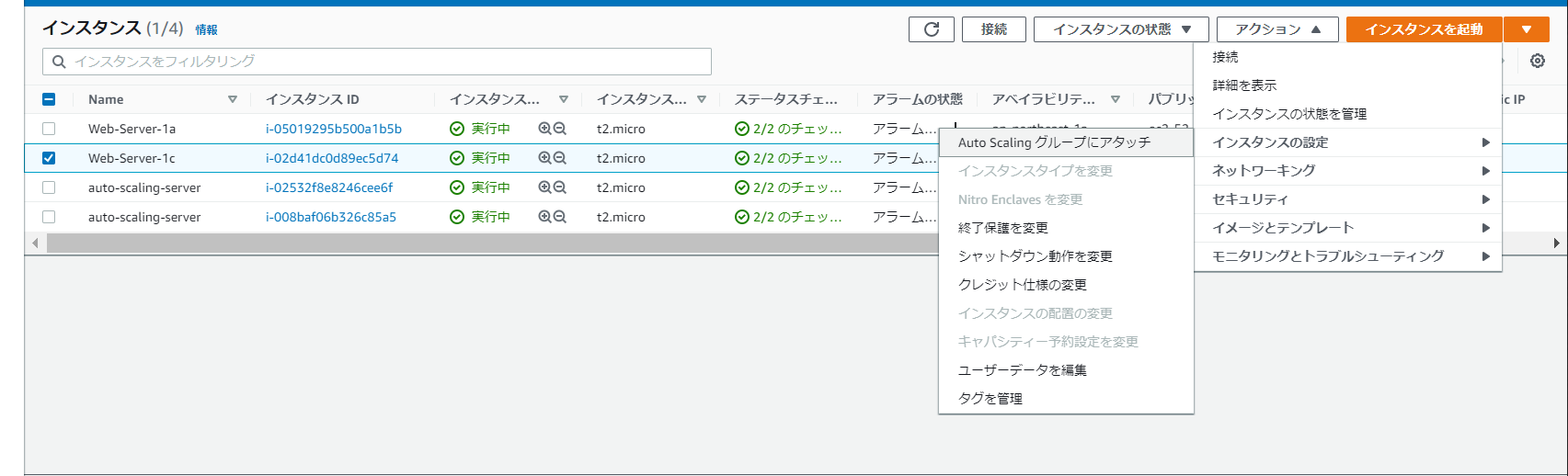
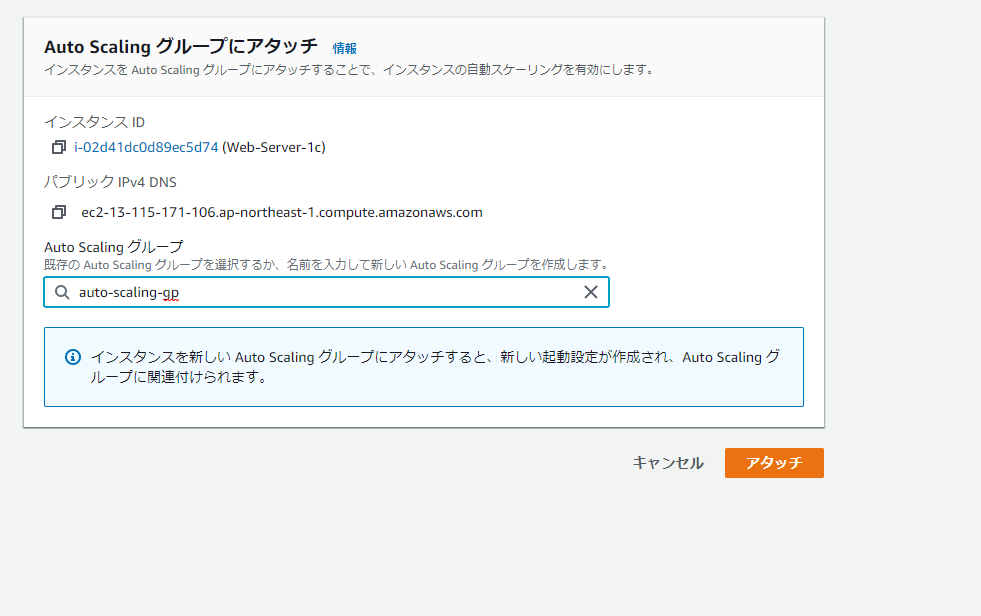
スケーリングの範囲(グループサイズの指定)はこちら。
ここで指定した範囲内でスケールイン・アウトが行われる。
つまり、希望する容量の部分は最小・最大の範囲内で動的に変化することになる。

スケールアウトの例。


EC2インスタンス側でも時間をおいて終了が反映される。

次に負荷テストを行う。

負荷がかかる。

するとスケーリングが行われ、もとのインスタンスと合わせて4つのインスタンスが実行されているのがわかる。

負荷が下がると希望容量が変化しているのがわかる。

次第に最低容量となり

もとのインスタンスの実行状況へスケールインされる。

ログはこちら。

スケールインの保護設定をしているとスケールインは行われないということと、スケールイン処理の反映にはラグがある(ヘルスチェックがあるため)ことに注意。
無事にスケールインされてるかどうかは5~15分くらい様子を見てから判断するといい。
RDS
まずはRDSをどこに置くかという設定。
ちなみにAZは上から優先されることに注意。
つまりこの場合は東京リージョンの1cというAZのサブネットにプライマリDBが配置されることになる。

次にデータベースの作成、ウィザードに従っていく。
ちなみに開発/テストで選択し、さらにマルチAZオプションを利用して放置した場合、えげつない課金が待っているので注意。
必ず用が済んだら即削除しよう。
無料枠ではマルチAZでの利用ができない。
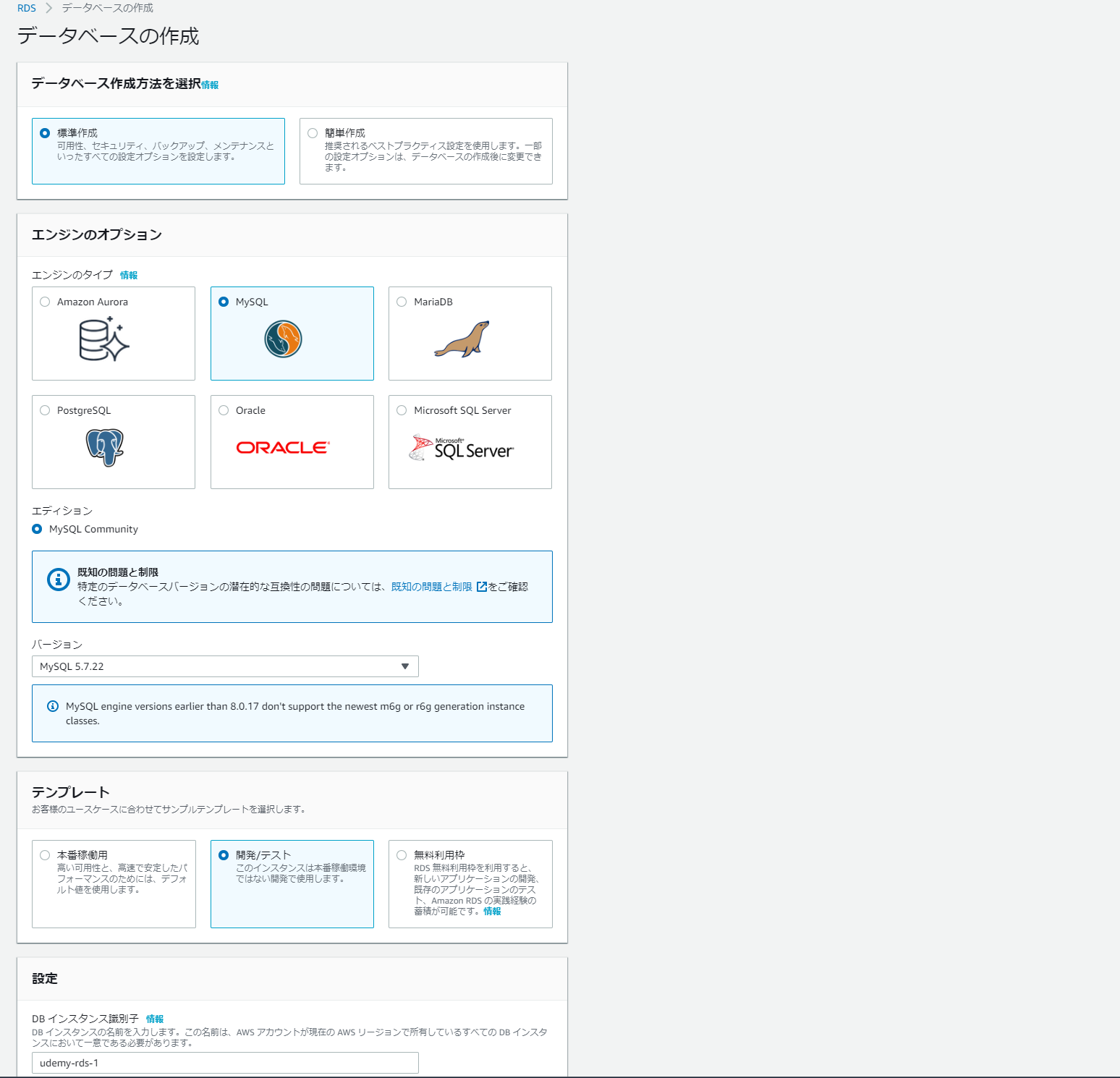
MySQL等で使うマスターユーザーのユーザー名等をここで設定、あとでDBに入るときに使う。


EC2とかS3のようにコンソールがある。




CLIからDB操作。
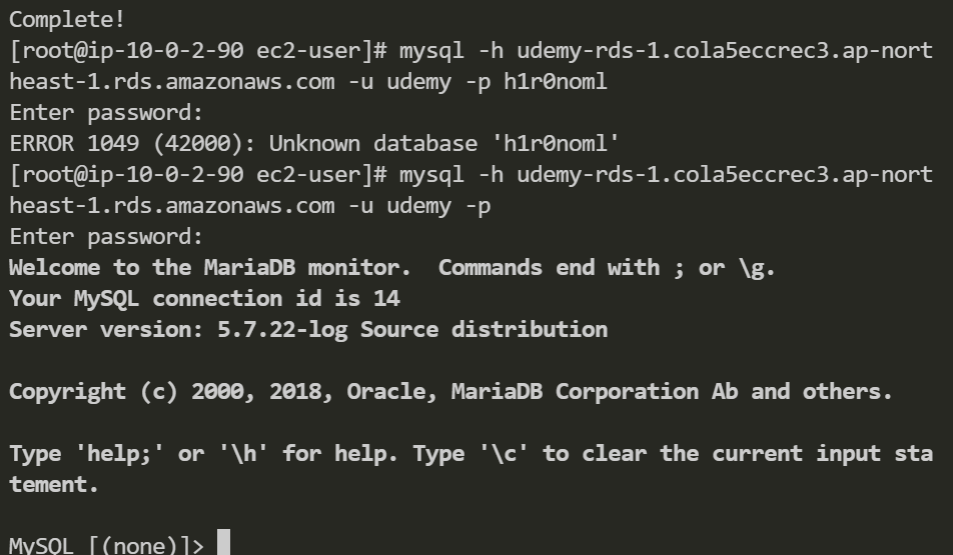
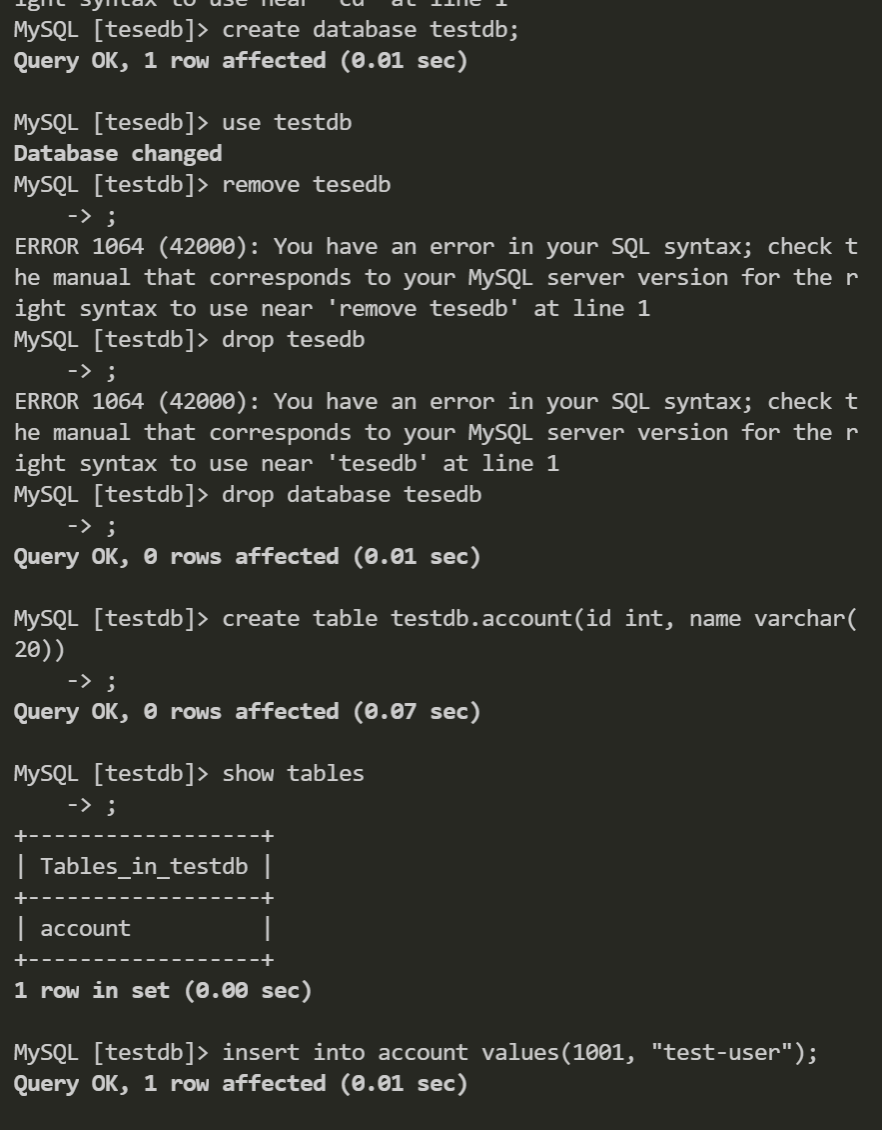
スナップショットは手動でも作成できる。
保存場所はリージョン内のS3。

またスナップショットからではなく、直近あるいは指定可能な日付と時刻を指定した復元もできる。
スナップショットは本当にある特定の状態のDBを切り抜いて保管しておけるという点で重要になる。

リードレプリカは以下のような感じ。


次にフェイルオーバーを確認してみる。


よーく見ると再起動後、1aの方でDBインスタンスが起動していることがわかる。
