はじめに
模擬試験を繰り返してきてまとめておいたほうがいいかなというところをBlack Beltを見たりしてまとめたものです。
AWSの基本的なアーキテクチャを作成するためのサービス
- EC2
- VPC
- S3
- Route53
- AutoScaling
- ELB
- CloudWatch
- CloudFront(コンテンツ配信を行うようなサービスの場合)
特にサーバレスなアプリケーションを構成する場合のサービス
Lambda
SQS
SNS
APIGateway
ElastiCache
DynamoDB(非ステートレスであれば)
Step function
(分散アーキテクチャの疎結合を助ける、特にオンプレミスのワークロードとの連携もできる)
データ分析ワークロード
Lambda
SQS
S3
Redshift
Athena
Glue
EMR
Kinesis
LakeFormation
アプリケーションやワークロードの自動化、テンプレート
OpsWorks
Cloud Formation
Step function(分散アーキテクチャやマイクロサービスでの疎結合化を図るが、本質はワークロードの設定や管理の自動化。タスクで構成されるワークフローを簡単に作成できる)
SWF(Step FunctionのEC2インスタンスを使う版。)
コンテナサービスによるマイクロアーキテクチャ
Elastic Beanstalk(ECS、EKS、ECRと連携して自動化)
ECS
EKS
リポジトリ管理からデプロイまでのワークロード
CodeCommit(リポジトリの管理、つまりソースコード管理)
CodeBuild(コードのビルド及びテスト担当)
CodeDeploy(ビルドに成功したモジュールのデプロイ担当)
CodePipeline(上記の3工程をCI/CD化するサービス)
EC2
インスタンスファミリー
- 汎用
- コンピューティング最適化(HPC、バッチ処理、動画エンコーディングを行うワークロード)
- ストレージ最適化(ビッグデータ処理や分散型ファイルシステム用途のワークロード)
- メモリ最適化(ハイパフォーマンスDBのインスタンスを作りたい、インメモリDBを使いたいといったワークロード)
- 高速コンピューティング(AI、3D、画像レンダリング、機械学習・ディープランニング・ゲノム処理、リアルタイムビデオ処理……等々超高性能やGPUが必要になるワークロード)
以上に分類される。
インスタンスファミリーの個別については正直覚えきれないので箇条書きにして試験ではお祈りする。
- 汎用…… A、T、Mシリーズ
- コンピューティング最適化…… Cシリーズ
- ストレージ最適化…… Hシリーズ(分散型ファイルシステム及びビッグデータ処理向け)、Iシリーズ(NoSQL、DWH向け)
- メモリ最適化…… Rシリーズ、Xシリーズ(インメモリDB向け)、Zシリーズ(電子設計(EDA)、RDB向け)
- 高速コンピューティング(アクセラレーテッド)…… Gシリーズ(レンダリングなど)、Pシリーズ(機械学習、ディープラーニング)、Fシリーズ(ゲノム分析、リアルタイムビデオ処理、リスク計算)
ちなみにT2・T3はバースト性能あり(ベースラインを下回る負荷のときクレジットを貯め。ベースラインを超えるとクレジットを消費して一時的に性能を上げる仕組み)
Bare MetalとDedicatedとハードウェア専有の違い
以下の通りとなる。
頻出なので整理しておく。
Bare Metalは仮想環境を経由しないでAWSが提供するハードウェアへアクセスができるインスタンス。
ハードウェアのOSからカーネルを利用するコンテナ式の仮想環境化とは違い、EC2のような仮想環境は以下のように構築されていて、EC2インスタンス(つまり仮想マシン)でOSが動く形式になる。
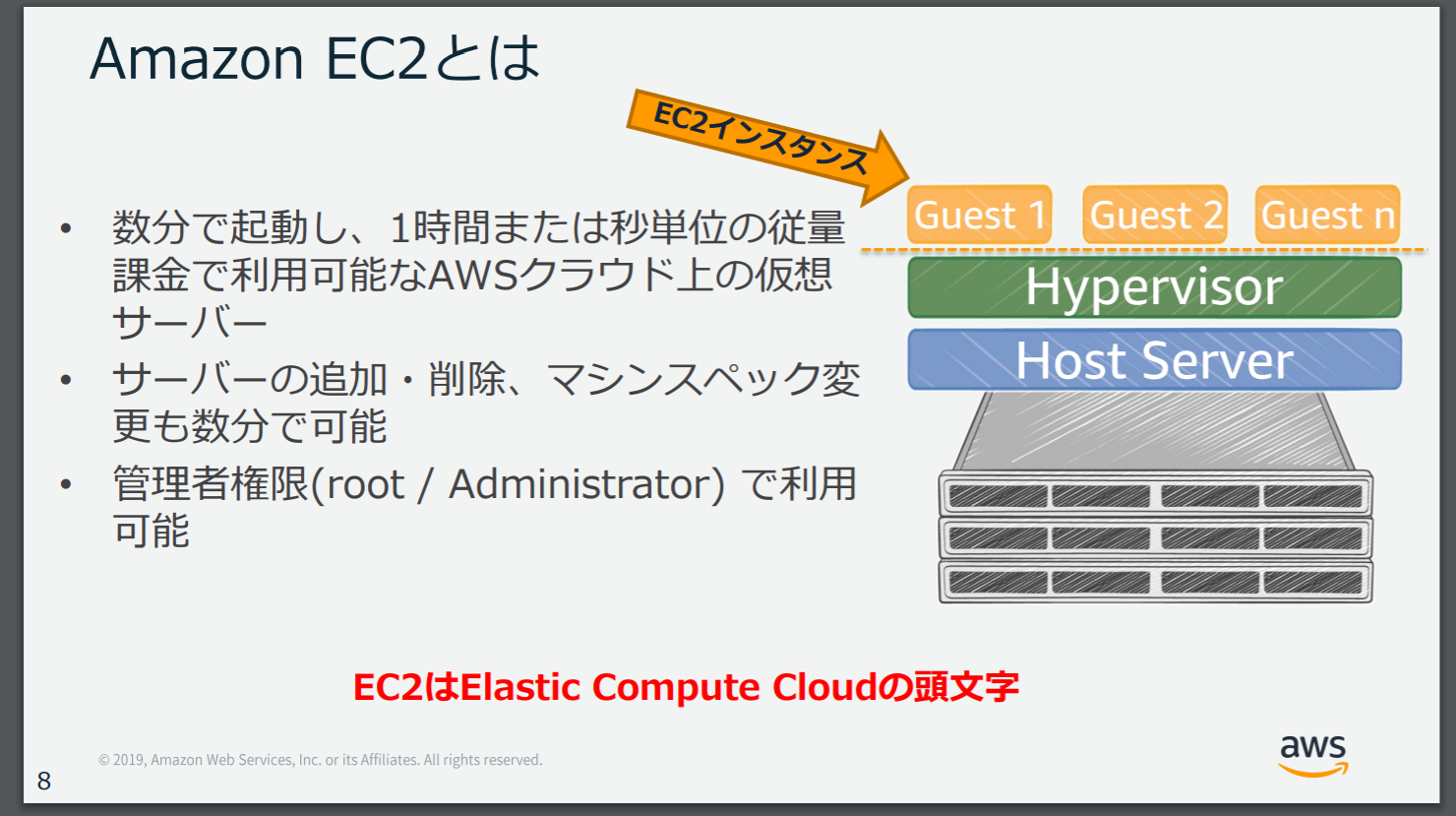
出典:【AWS Black Belt Online Seminar】Amazon EC2
Bare Metalはこの仮想マシンのOSが下層にあるHyperVisorを経由せずに直接HostServer(ハードウェア)へアクセスができるというインスタンスの形式になる。
なので、AWSのホストサーバーのハードウェアレベルまで自分達で管理したい、あるいは管理する必要がある場合や仮想環境下で実行できないワークロード等のユースケースで使う。
ただし、HyperVisor等仮想化ソフトウェアはプリインストールされていないことに注意。
Dedicated Hostは通常のEC2インスタンスの利用のように仮想環境下のワークロードではあるが、コンプライアンス上他のユーザーどころか自社所有の他アカウントであっても同一ハードウェア内に混在してリソースを作ってはいけないような行けない場合、ハードウェアを専有して任意のアカウントのリソースのみ展開させるという場合に使う。
ハードウェア専有インスタンスは他のユーザーのリソースはダメだが、自社が所有するアカウントのリソースであれば展開して良いといったDedicatedよりも緩い条件で専有したい場合に選択する。
まとめると
- BareMetal…… 仮想環境下で行えないワークロードやハードウェアまで自己管理する必要があるので物理サーバーごと専有する
- Dedicated…… 仮想環境下でのワークロードだが、任意のアカウントのリソースのみ展開する必要があるので物理サーバーごと専有する
- ハードウェア専有インスタンス…… 物理サーバーごと専有するけれども、自社内アカウントのリソースのみ展開したいなど、Dedicatedよりは緩い条件で専有している
ということになる。
プレイスメントグループ
複数EC2インスタンス間の通信に関してより最適化するための設定方法のようなもの。
- クラスタープレイスメント
インスタンスを密に配置することでネットワークパフォーマンスの最適化を図る。
結果低レイテンシーと高スループットを期待できる。
AZを跨いで設定することはできず、このグループに入っているインスタンスは他のグループには属せない。
- スプレッドプレイスメント
EC2インスタンスを別々の物理サーバー(ハードウェア)に分散して配置することで、AZ障害等物理的な障害に対し被害を軽減させるためのグループ。
同一AZでクラスターレベルでEC2を展開していてかつ、クラスタープレイスメントを使っていない場合有効。
特性上AZを跨いで設定できて、1AZにつき7インスタンスまで設定可能。
- パーティションプレイスメント
インスタンスをパーティションして配置するグループ。
パーティションが異なるEC2インスタンスはスプレッドプレイスメントのように分散して物理サーバーに配置されるので、ハードウェア障害が起きた場合単独パーティションのみに被害を抑えることができる。
EBS
忘れやすいところ
- ブロックストレージであり、一時記憶領域であるインスタンスストアとEBSボリュームとに分かれる
- EBSはAZごとに独立しているので同一AZのインスタンスのみアタッチ可能
- 1インスタンスに複数EBSをアタッチすることは可能(RAIDを組むことも可)だが、1つのEBSを複数のインスタンスで共有するEFSのような使い方はできない
どのボリューム使えばいいの?
個人的にわかりやすいフローチャートは
- 高スループットが必要であるか? → (必要なら)500Mib以上のスループットまたは高いIOPSが必要か
だと思う。
なぜならAWSリソースは基本的にコスト最適化に則って利用するように作られているので、スループット能力が必要なら必然的にプロビジョンドIOPSかスループット最適に絞れるからだ。
まとめると判断基準は以下の通り。
- 高スループットが必要
→ スループット性能またはIOPSがどこまで必要かで判断
具体的には高いIOPSが必要か、IOPSは必要ないが500Mib以上のスループットが必要ならプロビジョンドIOPS。
それ以外ならスループット最適化を選択。
- 高スループットはいらない
→ 汎用SSDを選択。ただし、ログ・バックアップ・コピーのコピー等重要度やアクセス頻度が低いものの保管用とであればコールドを選ぶ。
ちなみに、プロビジョンド以外はバースト機能あり。
プロビジョンドはある程度処理負荷を予測して自分でIOPSを設定して使うボリュームなのでない。
EBSパフォーマンスの改善ポイント
詳しくは【AWS Black Belt Online Seminar】Amazon EBSを確認。
ボトルネックとなるポイントは以下の3点らしい。
- EC2インスタンス側のスループット性能が低い → インスタンスタイプを上げて改善する
- EBSボリュームのIOPS性能が低い → EBSボリュームの変更で改善する
- EBSボリュームのスループット性能が低い → EBSボリュームの変更で改善する
いずれもCloudWatchでメトリクスを確認し、性能上限に達しているかで判断する。
Snapshotについて
Snapshotは整合性を保つために静止点を設けた上で作成することが推奨されているが、実は静止点を設けてSnapshotの作成を指示したあとレスポンスが返ってきたら動作を再開してもいい。
たまに、Snapshot作ってる間EBSボリュームは動作していいのか?ということを聞かれることがあるので覚えておくと助かるかも。
暗号化について
KMS(AES-256)またはCMKで実行可能。
ちなみにボリューム作成後に行いたい場合はSnapshotを暗号化してそこから新しいボリュームを作ってアタッチし直す形でできる。
新規作成したEBSを利用するには?
A. EC2インスタンスにアタッチし、ファイルシステムを作成してフォーマットする
外付けドライブを使う時と同じ感覚。
VPC
セキュリティグループとネットワークACL
問題文の書き方がややこしいとどっちで制限かけるか間違えるポイント。
基本的に
- セキュリティグループはサーバー単位(つまりEC2インスタンス)に対して効果を発揮する
- ネットワークACLはサブネットレベルで効果を発揮する
この2点に注目する。
なので、インスタンス同士で接続がうまく行かないとかの場合はセキュリティグループ。
特定のIPアドレスを拒否したい場合や異なるサブネット間に跨がるインスタンス同士の通信がうまく行かないなどのケースはネットワークACLを疑う。
他にも
- SGはステートフルだが、ネットワークACLはステートレス(常に同じレスポンスを返す必要がある)なのでアウトバウンドのルールも明示的に設定する必要がある
- SGはすべてのルールを適用するが、ネットワークACLはルールは番号順で(つまり先に設定したルールから)評価されて適用される
- SGはインスタンスに対して個別にSGを適用するが、ネットワークACLはサブネットに対して設定するので、サブネット内すべてのインスタンスがルールの管理下になる
という違いがある。
CIDRについて
基本的に/16(VPCに設定)~/28(/18から+2した数値で設定、サブネットに設定できる)。
サブネットマスクが2ずつ上がるごとに使用できるIPアドレス数が約1/4ずつ少なくなる。
- /18…… 16379
- /20…… 4091
- /22…… 1019
- /24…… 251
- /26…… 59
- /28…… 11
AZについて
AZは互いに地理的にも電源的にもネットワーク的にも分離されたデーターサーバー群。
VPCエンドポイントについて
グローバルIPをもつAWSのサービスに対して、VPC内部から直接アクセスするための出口となる。
ちなみにオンプレミスなど外部との接続に関してはVPN(Site-to-Site、Client VPN)や専用線を用いたDirect Connectがある。
VPCエンドポイントはGateway型(S3、DynamoDBに対して利用)、PrivateLink型とがある。
ちなみにGateway型は同一リージョン内の接続のみ。
詳しくは下記引用スライドより。
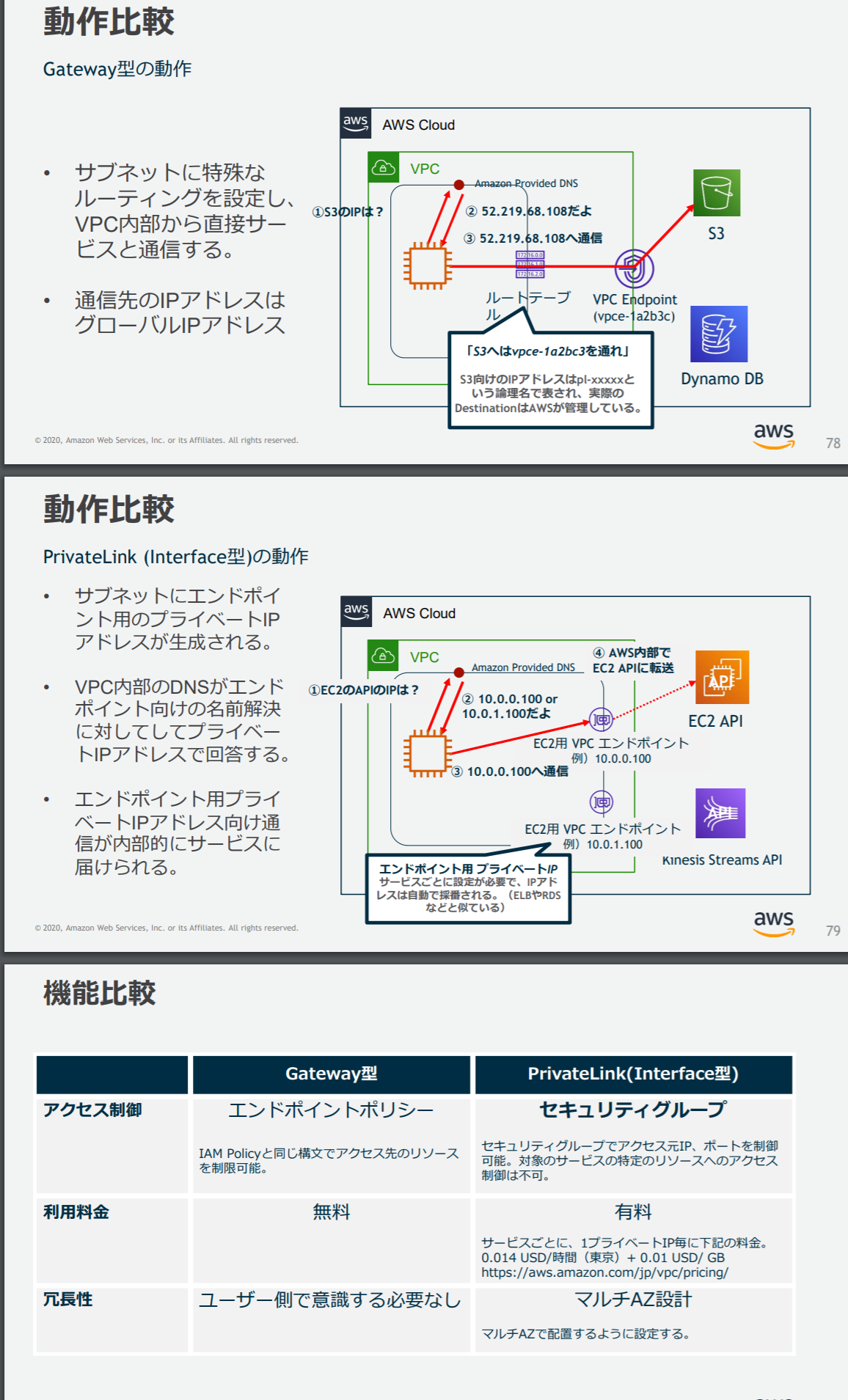
出典:【AWS Black Belt Online Seminar】Amazon VPC
VPCフローログ
ネットワークトラフィックをキャプチャしてCloudWatch LogsやS3に反映させることができる仕組み。
もっというとインスタンスの通信(セキュリティグループ及びネットワークACLのルール内でのaccepted/reject)のログを取得する。
これを設定しておかないとインスタンスの通信をロギングしたり詳細にモニタリングできなかったりする。
無料では10分間隔、有料だと短くできる。
ちなみにミラーリングするなら Traffic Mirroringという機能を使う。
AutoScaling
基本的には
- 静観(希望容量=現実の起動台数)
- スケールアウト
- スケールイン
の3つの状況をメトリクスして現実の起動リソースが希望容量(リソースが理想的に動作するキャパシティやその状態)に合致するように推移させるためのサービス。
EC2に付随するサービスであったが、現在はECS・DynamoDB・Aurora・EMR……と他のサービスでも利用できるようになってきていて、それらを統合して独立したサービスとして成立させようとする傾向が見られる。
基本的には動的なスケーリングを行いたいという場合がほとんどなので
- Min Capacity(最低これだけは起動していないといけない台数)
- Max Capacity(最大スケール台数)
- Desired Capacity(希望容量、なおこれは動的スケーリングの場合Min~Max間で推移することになる)
を設定して使うことになる。
速やかなスケーリングを行いたい場合はCloudWatchのモニタリングを詳細(有料)に設定する。
またELBを利用している場合はEC2ヘルスチェックと合わせてELBEヘルスチェックもスケーリングの際適用するように設定しておく。
スケーリングの種類
たまに聞かれるのでざっと押さえておく。
-
簡易スケーリング(1つのメトリクスに対し、1種類だけのスケーリング条件を設定してスケーリング。なお現在は非推奨)
-
ステップスケーリング(1つのメトリクスに対し、複数のスケーリング条件を設定して細かくスケーリングできる。現在の主流)
-
ターゲットスケーリング(1つのメトリクスに対し、CPU使用率を40%に維持するといった目標値を指定してそれを遵守するようにスケーリングさせる)
-
予測スケーリング(2週間分のメトリクスから機械学習で需要予測を行いそれに合わせてスケーリングする。仕様上24時間分のメトリクスが必須なのでAuto Scaling Groupを作成した直後には利用できない)
-
スケジュールスケーリング(ある決まったタイミングで1度限りor定期的なスケーリングを実施するように設定できる)
以上からわかるように利用にはCloudWatchによるメトリクスが必須となる。
ステップスケーリング補足
ステップスケーリングで気をつける話。
複数のスケーリング条件を指定できるということは
- CPU使用率50%を超えたら1台追加
- CPU使用率60%を超えたら2台追加
- CPU使用率70%を超えたら3台追加
というようにスケーリング条件を指定できることになる。
しかし、インスタンスの起動には時間がかかるので例えば50%を超えると1台追加マシンが起動を始めるわけだがそうこうしているうちに70%になってしまった……なんてこともある。
そうなると4台もマシンが追加されてしまい余計なスケーリングを行ってしまうことになる。
これを避けるためにウォームアップ期間を設定し、追加マシンが起動するまでの時間を予め設定しておくことでAutoScalingに今、マシン起動中だからそれを考えてスケーリングしてねと伝えることができるようにする。
すると、AutoScalingはこのケースの場合、1台追加で起動中に70%だから……じゃあ2台追加で大丈夫かと判断してスケーリングを行ってくれる。
詳しくは引用スライドを。
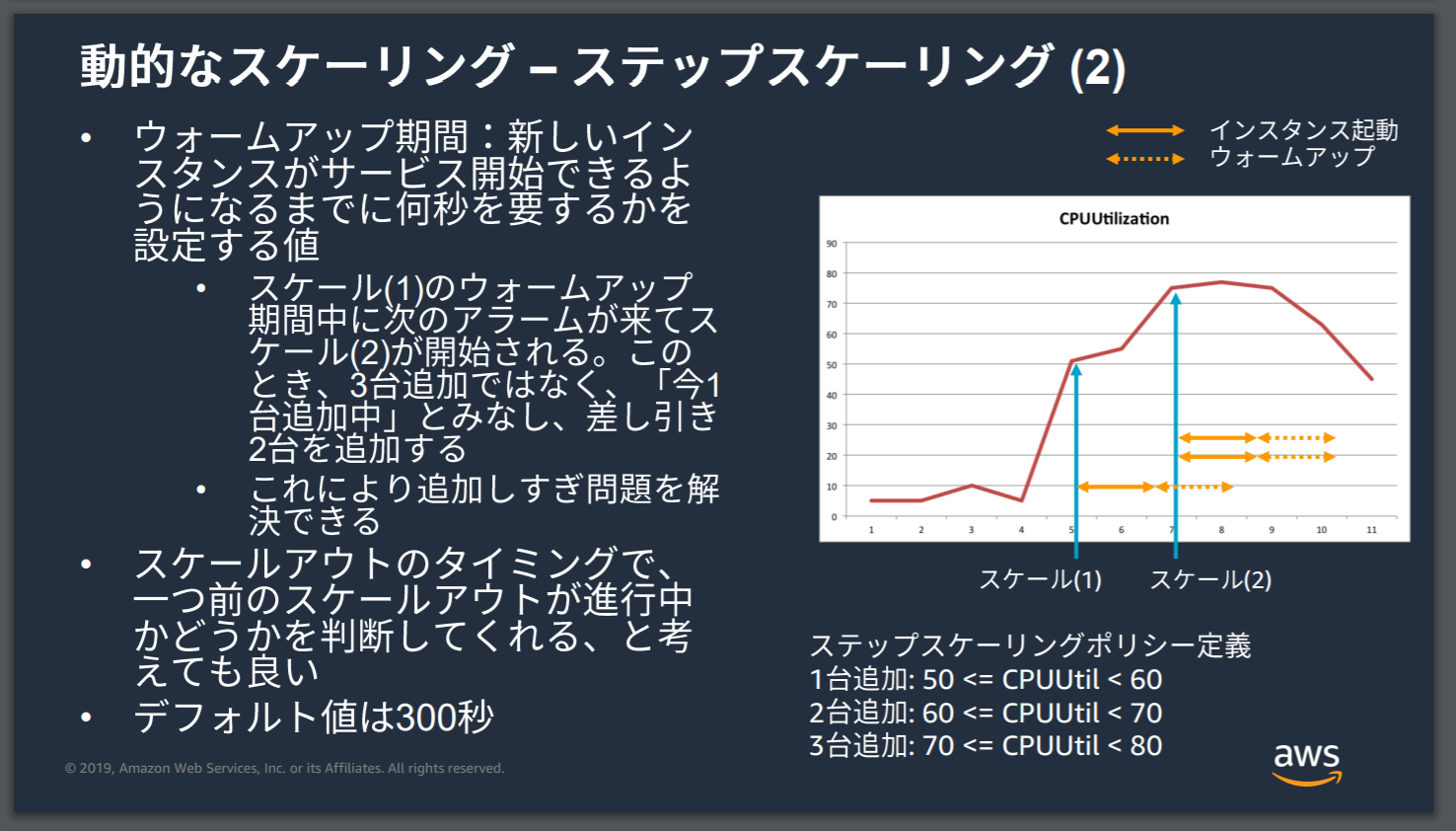
出典: 【AWS Black Belt Online Seminar】Amazon EC2 Auto Scaling and AWS Auto Scaling
スケールアウト、インで通信やデータベースへのアクセスができなくなる
この手のトラブルはスケールアウト、インの度にIPアドレスが変更されていることが原因である。
スケールアウトしたインスタンスで通信やアクセスが不可となっている場合はElastic IPを付与するように設定することで起動のたびにIPアドレスが変わること問題に対処する。
スケールインしたあとでも通信やアクセスが不可となっている場合は、ターミネーションポリシーでOldestInstanceから削除するように設定されている可能性があるのでそこを見直す。
ELB
割と危なさそうだなというところを簡潔に。
多分SAA試験レベルではこのサービスの30%くらいしか理解できないだろうなというくらい内容が厚い。
Route53と同じくネットワークに関する知見が求められるな……とひしひしと感じる。
特徴としては
- 同一インスタンスで複数ポートに負荷分散可能
- IPアドレスをターゲットに設定可能
- ELB自体も自動でスケーリングする(ロードバランサーノードの仕組み)
というものがある。
ただし、AutoScaling等々との兼ね合いもあり、スケーリングするとIPアドレスが変わってしまうこともあるので基本的はAZ、リソース、DNS名をターゲットにすることが推奨されている。
IPアドレスをターゲットにするケースはオンプレミスサーバーに対してもバランスを行いたい時。
クロスゾーン分散
基本的にELBは複数AZに負荷分散するためのサービス。
仕組みとしてはVPC内にELBがあり、さらにそこからAZごとあるいはインスタンスごとにさらにELBを置く(これをロードバランサーノードという)2段階での分散を行っている。
1段階目はELBからELBノードへ処理を分散、2段階目はノードからインスタンスへ負荷分散。
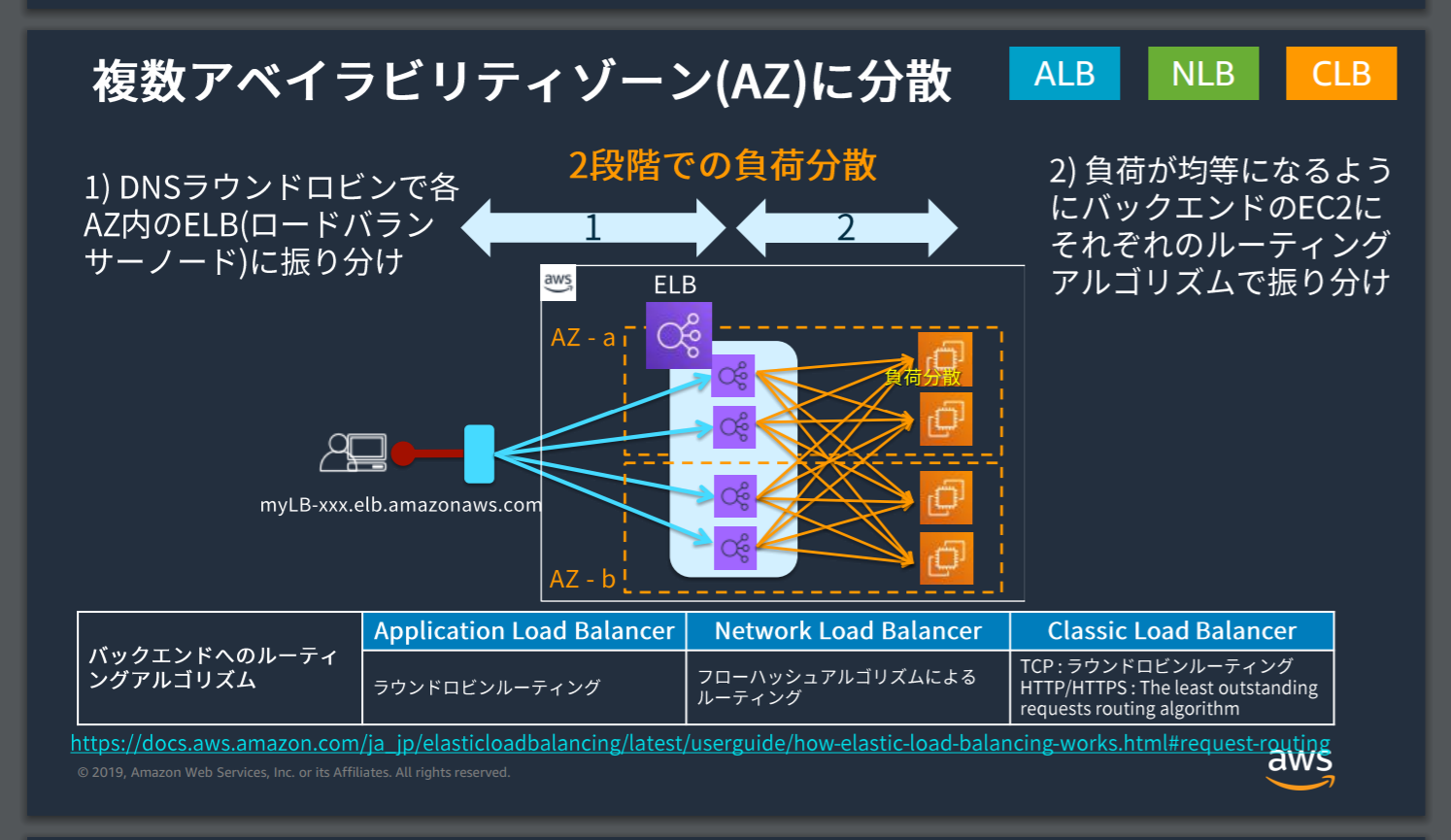
出典: 【AWS Black Belt Online Seminar】Elastic Load Balancing (ELB)
これとは別にさらにクロスゾーン分散を行うことで、リージョン内の複数AZに対して負荷分散を行うことができる。
利用する目的としてはAZ間でリソース(例えばインスタンスの数)が不均等である場合にAZの負荷を元に分散することで均等化したいというところにある。
ちなみにRoute53と合わせて使うらしい。
コネクション
トラブルシューティング等で聞かれるのでまとめておく。
-
コネクションタイムアウト…… 設定した秒数無通信状態が続くとそのコネクションを自動で切断する
-
Connection Draining …… バックエンドのEC2インスタンスをELBから登録解除したり、ヘルスチェックが失敗するなどリクエストのタイミングで空白が生まれてしまった場合、指定した秒数新規リクエストの割り振りを中止し、処理中のリクエストが終わるまで一定期間待機させる
-
スティッキー・セッション…… 同じユーザーから来たリクエストを全て同じインスタンスに送信する
セキュリティ
SSL/TLS Terminationを利用すればバックエンド(EC2インスタンスなど)でSSL処理せずにELBで解決できる。
また、ACMを利用することでHTTPS/SSL証明書を利用することもできる。
ちなみに、ELBを使用しない場合ACM発行の証明書は使えないのでサードパーティ制の証明書をインポートして利用する。
例えばALBにおいてクライアントとの通信中のデータ保護を行う場合は、ACMを利用してSSL証明書を発行し、その証明書を使ってHTTPS通信を利用できるようにすることで実現できる。
ALB
アプリケーション層、つまりL7でのロードバランサー。
なので、HTTP、HTTPS、HTTP/2プロトコルでの通信をバランシングする。
急激な負荷が見込まれる場合は暖気申請をする。
ちなみにスケーリングするときはIPアドレスが変わる。
WAFを適用してALBを保護することもできる。
NLB
TCP/UDP……つまりトランスポート層でロードバランシングしてくれるL4ロードバランサー。
高可用性、高スループット、低レイテンシーである。
暖気申請は必要なく、IPアドレスもAZ毎に1つ固定で付与される。
CloudFront
アクセス制限周りについて間違えるところをまとめる。
SSL証明書
ELBと同じようにACMと合わせて利用できる。
ELBと合わせて使わない場合はサードパーティ製の証明書をインポートして使うケースがある。
署名付きURL/Cookie
発行されたURL/Cookie以外からのリクエストを拒否する仕組み。
これを利用して特定のユーザーのみアクセスできるコンテンツ配信ができる。
フローの例としては以下の通り。
- ユーザーが認証リクエストを行う
- 認証成功なら署名付きURLやCookieを発行して、そこへリダイレクトしコンテンツへアクセス
- 認証失敗なら403
ちなみにCookieの場合はワイルドカードでパス指定できるので、単一コンテンツの場合は署名付きURL、複数の場合は署名付きCookieを使う。
特定のユーザーやIPアドレスのみアクセスを許可したい
特にS3のコンテンツへのアクセスに対して行うケース。
OAI(Origin Access Identify)をホワイトリスト形式で設定し、対象のS3バケットを用いるディストリビューションに紐つけることでこれを設定したユーザーのみが対象のバケットへアクセスできるようにバケットポリシーを作る。
そうすると、そのバケットはCloudFront経由でのみしかそのバケットにはアクセスができなくなりかつOAIで設定したユーザーのみが対象のバケットへアクセスできるようになる。
ちなみにIPアドレス制限をかけるならWAFも使う。
またオンプレミスで展開していたアプリケーションをAWSへ移行する際にホワイトリストで管理していたIPアドレスも移行させたい場合はROA(Route Origin Authorization)を使う。
Referer制限やサイト保護かけたい
WAF、AWS Shieldを使う。
特にReferer制限はWAFと連携しないと使えないことに注意。
ロードエラーに対してフェイルオーバーを実行したい
Route53でフェイルオーバールーティングを設定し、CloudFrontディストリビューションを作成する際にフェイルオーバーオプションを設定する。
サイト単位ではなく、オブジェクト単位のフェイルオーバーになる。
Route53
このサービスが1番苦手分野なのでちょっとまとめておく。
まず基本的な考え方としてRoute53は広義的にはDNSに関するマネージドサービスであり、主要な役割の1つとしてName Serverのマネージドサービスがあることを押さえておく。
ではDNSとかName Serverって何? となるので確認していく。
DNSって?
FQDN(ドメインを一意に特定できるような形式で書いたもの、例えばwww1.sub.example.com.など。必ず「.」で終わる)をキーに対応するIPアドレスなどの情報を取得する仕組みのこと。
詳しくはBlack Belt資料の以下の図を見てほしい。
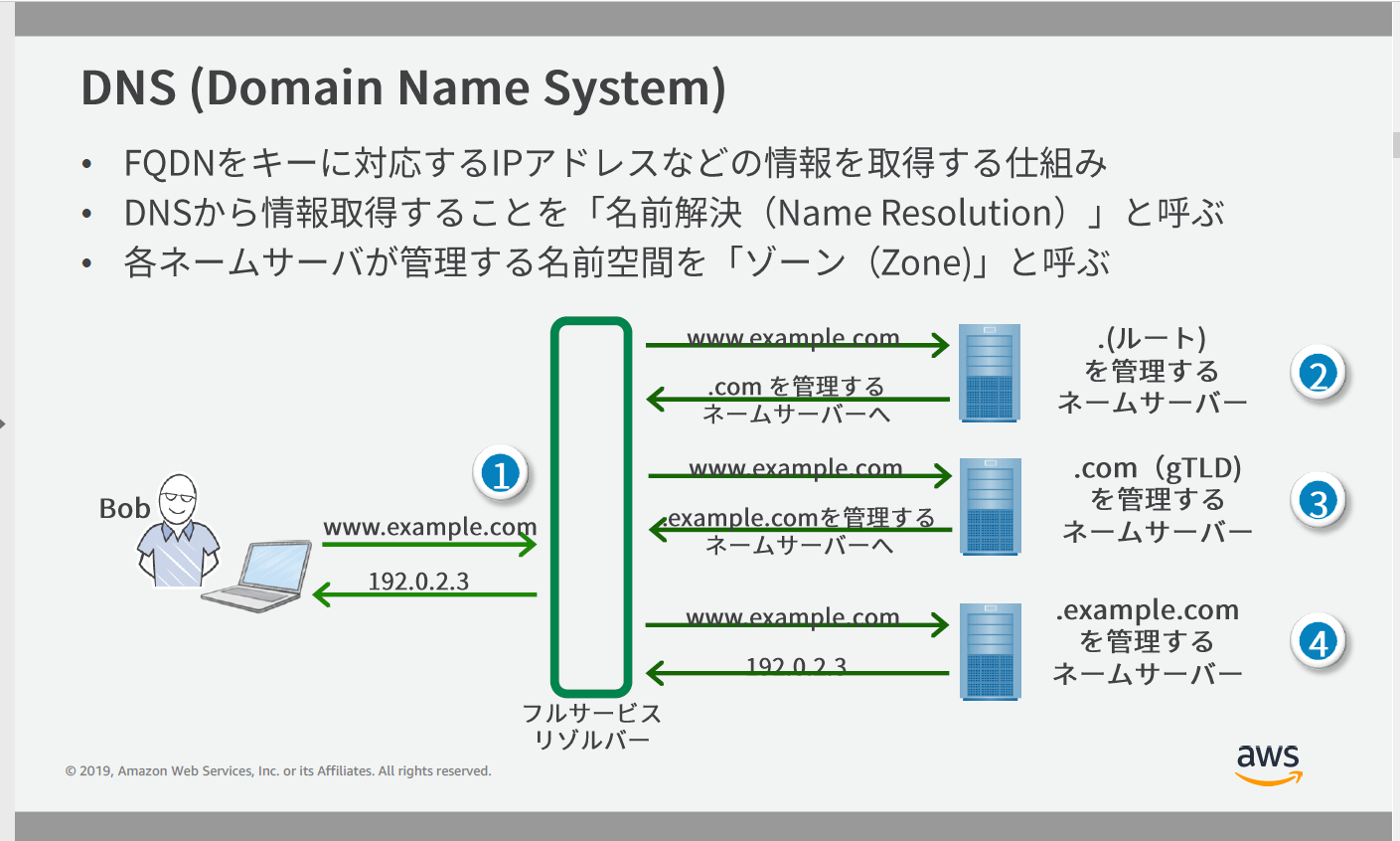
出典:【AWS Black Belt Online Seminar】Amazon Route 53 Resolver
そして、このDNSを構成する要素の1つにName Serverという仕組みがある。
Name Serverとは
先程のFQDNを「.」を起点にしてすべて探索できるように構成された分散データベース、およびそれを成す一つ一つのNameSeverのことを指す。
権威DNSサーバーやAuthoritative Serverなんて呼ばれることもある。
詳しくはBlack Belt資料の以下の図を見てほしい。
出典:【AWS Black Belt Online Seminar】Amazon Route 53 Resolver
親ゾーンから子ゾーンへと権限移譲をするという形式で成り立っている。
レコードについてはあとで纏めるが、そのレコードで権限移譲を表すと以下の通り。
NSレコードはゾーンを管理するネームサーバーのFQDNを指し示すレコード。
ゾーンについてはName Serveが管理する名前空間(例えば.comのName Serverであれば.comとつくFQDNに関しての情報を返してくれる(名前解決)ような空間)のこと。
example.com. 3600 IN NS ns1.example.com.
example.com. 3600 IN NS ns2.example.com.
この場合はexample.com.が親ゾーン、ns1.example.com.やns2.example.com.が子ゾーンとなり、これをNSレコードにおいて結びつけている。
そして最終的に欲しいIPアドレスを返してもらうために移譲先で以下のようにAレコードを定義する。
ns1.example.com. 3600 IN A 192.0.2.1
ns2.example.com. 3600 IN A 192.0.2.2
ではRoute53って?
上記のような仕組みをAWSがマネージドで提供してくれる。
Name Server以外にもDNSを構成する要素である
- Full Service Resolver
- Stub Resolver
- Forwarder
以上の機能も提供してくれる(Route53 Resolver、Route53 Resolver for Hybrid Cloudsなど)があるが今回は割愛する。
Route53、正確にはRoute53 Hosted ZoneはNameServerの役割を担うと先程書いたが正確には以下の2種類に分類できる。
- Public Hosted Zone(インターネットに公開されているDNSドメインのゾーンに対応する)
- Private Hosted Zone(VPC内のPrivateなネットワークでのDNSドメインゾーンに対応する)
レコードについて
これもよくわからなくなるので主要なところを簡単にまとめておく。
- SOAレコード
ゾーンの管理主体(ゾーンの起点や権威)であることを宣言するためのレコード。
ゾーンの管理、応答するRRSetに関わる情報や設定が含まれる。
- NSレコード
前述の通りゾーンを管理するNameServerのFQDNを示すレコード。
ゾーンからゾーンへ権限移譲する場合はこれを使う。
- AまたはAAAAレコード
そのFQDNに対応するIPアドレスを定義する。
AレコードであればIPv4、AAAAレコードであればIPv6が紐付けられる。
www.example.com. 3600 IN A 192.0.2.3
www.example.com. 3600 IN AAAA 2001:0DB8::1
- CNAMEレコード
あるドメイン(ホスト名)に別名をつけたいときに使う。
役割としては名前解決する場合、CNAMEで指定した名前に置き換えて継続できるようにするレコード。
ちなみにSOAやNSで定義しているドメイン名(ホスト名)は通常CNAMEレコードで新たに定義することはできないが、後述のALIASレコードを用いることでそれを回避できる。
例えば下記のようなRRsetだと最終的に192.0.2.3が返ってくる。
info.example.com. 3600 IN CNAME www.example.com.
www.example.com. 3600 IN A 192.0.2.3
- MXレコード
IPアドレスをメールサーバーのFQDNと紐つける。
- ALIASレコード
CNAMEでやっていたようなことをCNAMEを利用することによるZone Apexの制約を受けずに行えるRoute53固有の機能。
ただし、AWSリソースに対しての利用に限る。
- S3バケット
- CloudFront ディストリビューション
- Route53ホストゾーンの他のレコード
以上のリソースに対して利用できる。
例としては以下の通り
www.example.com. 60 IN CNAME www-a.example.com.
www-a.example.com. 60 IN CNAME xxxx.cloudfront.net.
xxxx.cloudfront.net.60 IN CNAME 192.0.2.3
以上のRRsetで行っていることをALIASレコードとして定義した以下のレコードで同じように実行できる。
www.example.con. 60 IN A 192.0.2.3
トラフィックルーティング
Route53でよく出てくる機能なので改めて。
- シンプルルーティング
レコードで設定したIPアドレスへとルーティングする。
例は以下の通り。
以下のようなRRsetの場合、3つのIPアドレスから都度ランダムで1つ応答がある。
www.example.con. 60 IN A 192.0.2.4
www.example.con. 60 IN A 192.0.2.3
www.example.con. 60 IN A 192.0.2.1
- 加重ルーティング
トラフィックを指定した比率でリソースに振り分けるためのルーティング。
A/BテストやBlue/Greenデプロイによる段階的な環境、バージョン移行に使ったり単純にサーバーごとの負担を平準化するために利用する。
- フェイルーオーバールーティング
ヘルスチェックの結果に基づいて利用可能なリソースにルーティングする。
アクティブ/アクティブ(常にどちらの環境も動いている)構成かアクティブ/パッシブ(フェイルオーバー先はコールド状態)構成を選択できる。
ヘルスチェックは複数結果を結合でき、それをフェイルオーバー条件とすることもできる。
主に複数リージョンにまたがる冗長構成、災害時のクロスリージョンフェイルオーバー、S3静的WebホスティングのError Pageの表示に利用できる。
ちなみにこのルーティングを利用するにはCNAMEレコードをして移行先のリソースのホスト名と移行元のホスト名を紐つけておく。
- 複数値回答(マルチバリュー)ルーティング
最大8つのランダムに選択された正常なレコードから応答するようにするルーティング。
シンプルルーティングでRRsetを構成したような状態と似ているが、こちらはヘルスチェックを行い、各リソースが正常かを確認して正常なリソースからのみ応答させる。
ちなみに応答をキャッシュした後であるなら、当該リソースが利用できなくなった場合は他のIPアドレスを利用できる。
- レイテンシールーティング
ネットワークレイテンシーが最も低いAWSリージョンのリソースへとルーティングする。
- 位置情報ルーティング
クライアントの位置情報に基づいて、ルーティングする。
具体的には特定の地域・国からのDNSクエリに対して、特定のアドレスを応答させるようにする。
これはクライアントの地域によって適切な言語でコンテンツを提供したり、CloudFrontにおいて地域制限をかけたいといったときに利用する。
- 物理的近接性ルーティング
ユーザーとリソースの緯度経度情報に基づいて、地理的場所的にルーティングする。
トラフィックフローを使わないと作成できない。
RDS
RDSでマルチAZを有効化すると?
A. 自動的に別AZに同期レプリケーション及び自動フェイルオーバーを実現するスタンバイ状態のDBインスタンス(スレーブ)が構成される
ただし、スタンバイ状態ではアクセスはできないので負荷分散はリードレプリカを作成して行う。
この機能によって単純にAZやインスタンス障害発生時のフェイルオーバーに限らず
- パッチ適用等のメンテナンス
- 手動でマスター側をリブートする
といったような通常はサービスの停止が必要な場合においてもそれを回避したり、その影響を軽減できる。
リードレプリカの昇格について
リードレプリカはRDS採用しているDBエンジンによって実は仕様が異なる。
主な違いは以下の通り。
- レプリケーションの仕様の違い…… MySQLとMariaDBは論理レプリケーション、Oracle・Postgre・SQLは物理レプリケーション。
- トランザクションログの削除
- リードレプリカにWriteできるか…… MySQLとMariaDBは可能。OracleとSQLは不可(DBインスタンスに昇格させれば可)、Postgreは不可
- リードレプリカのバックアップ…… MySQLとMariaDBは可能、Postgreは可能(自動バックアップ機能は使えない)、OracleとSQLは不可
- 並列レプリケーション(レプリケーション処理のマルチスレッド化)…… Postgre以外は可能
- リードレプリカのマウント状態の維持…… Oracle以外不可
そしてRDSのリードレプリカは以下の状況に応じてスタンドアロンDBインスタンスに昇格することができる。
- DDL操作(MySQLとMariaDBのみ)
- シャーディング(データベース……というよりテーブルの分散配置)
- DR対策としてプライマリDBの障害に対してリードレプリカを昇格させフェイルオーバーする
ただしリードレプリカはクロスリージョンに配置することもできるがここが少しややこしいので次項で解説。
クロスリージョンリードレプリカとフェイルオーバー
マルチAZの場合、構成を有効化すると自動でスタンバイDBが出来上がりプライマリDBと同期レプリケーションを行い自動フェイルオーバーの体制が整う。
しかし、マルチAZの場合でもそうだがリードレプリカを昇格させるのは基本的には手動で行わないといけないのでクロスリージョンリードレプリカを使ったフェイルオーバーは自動ではできない。
ただし、RDSのDBエンジンでAuroraを使用していてかつGlobal Databaseを有効にしてクロスリージョンレプリケーションを作成している場合は設定要件に従って自動でフェイルオーバーすることもできる。
クロスリージョンレプリケーションの基本的な構成は以下の通り。
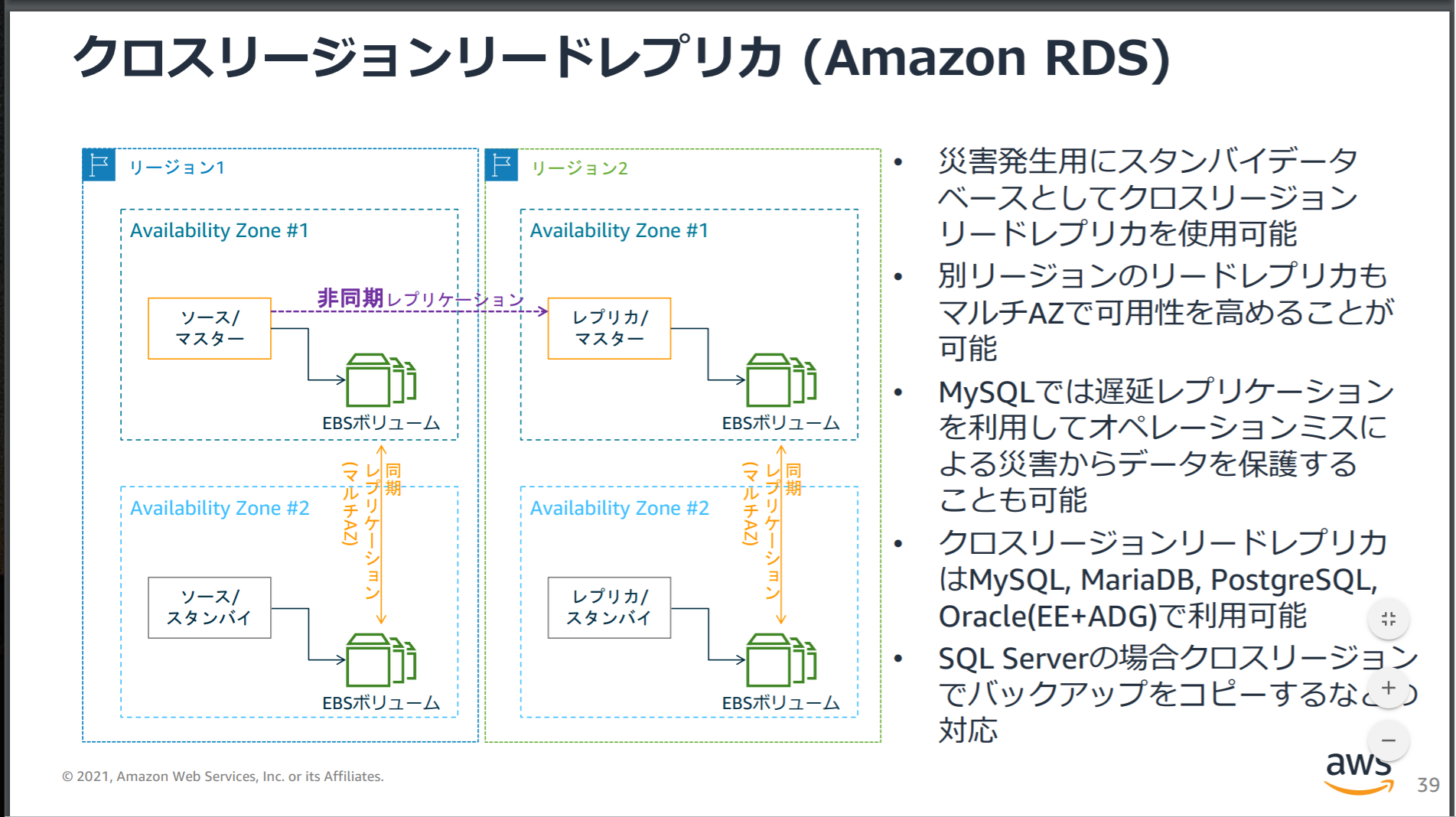
Auroraのクロスリージョンフェイルオーバーに関してはこちらの記事が参考になります。
Amazon Aurora Global Databaseをリージョン間でフェイルオーバーさせてみた
ちなみにマルチAZにしろクロスリージョンにしろフェイルオーバーはレプリケーションを伴うので単純にDBインスタンスのリソースを2倍用意しないといけないのでコストはかなりかかることに注意。
特にクロスリージョンはデータ転送料もかかるので余計にかかる、ホットスタンバイ構成の場合は目も当てられない。
バックアップってどうなってるの?
DB自体は自動バックアップ機能あり(リードレプリカのそれはDBエンジンによって異なる)。
バックアップはSnapshot形式で行われて、リストアもそれで行う。
Snapshotはリージョン、またはアカウント間、両方を経由しての別リーションの別アカウントへのコピーも可能。
ただし、リストアしたDBはエンドポイントの名前が変わるのでアプリケーション側でエンドポイントの接続名の修正を行うか、エンドポイントのリネームを忘れないようにする。
モニタリングどうなってるの?
A. 基本的にはCloudWatchと連携。ただし、OSメトリクスやプロセスのモニタリングやCloudWatch Logsへの出力、特定メトリクスへのアラート、メトリクスの60秒以下単位での取得をしたい場合は拡張モニタリングを有効にする。
その他
カスタムサインインコードや独自のユーザーIDを管理したくない
A. Web ID フェデレーションの設定を行いSTSを利用する。
これで、OpenID Connect互換の外部IDプロパイダ(早い話がGoogle等)からサインインし、そのユーザーにSTSで認証トークンを付与しそれと引き換えにIAMロールをマッピングするという処理ができる。
OpenID Connectを利用しない場合は、SAML フェデレーションの設定を行う。
フルマネージドに依存せず、自社基盤のオペレーティングシステムにアクセス可能なAWSサービスを利用したい
A. EC2インスタンスを利用したAWSサービスを利用する。
基本的にフルマネージドサービスではなく、アンマネージドなサービスを利用すればいい。
代表的なものがEC2になる。
ただし、EMRのようにマネージド型ではあるが、EC2を利用してリソースが構築されるため要件に合致するというケースもある。(マネージドではあるが、フルではないというケース)
アクセスがほとんど発生しないデータの保存先としてGlacierってコスト最適じゃないの?
A.90日は必ずデータを保持するため、特に30日以内に削除するデータの場合についてはIAなストレージの方がコスト最適。
これはかなり罠かつ問題文でもアクセスや更新は保存後殆ど発生しないデータに対してのS3の保存先をコスト最適を考えてを選択してくださいみたいな書かれ方しかしないので判断しづらかったりする。
こういうのはちょっと卑怯だと思った。
S3で403エラーが出る
A. バケットポリシーで読み取り権限が設定されていない or パブリックアクセスブロックの無効化がなされていない。
よく間違えるところですが、パブリックアクセスの許可設定の有効化という設定は存在しない。
あくまでバケットはデフォルトではパブリックアクセスブロック状態であり、静的Webホスティング等でパブリックなアクセスを許可する必要がある場合にこれを無効化する設定を行うということを覚えておく。
S3でバケットの暗号化を有効にしているのになぜか失敗する
A. バケットポリシーやACLで暗号化なしのPUTリクエストを拒否している可能性があるので見直す
データ登録は
バケットポリシーで評価 → バケットに追加
のフローで行われる。
つまり、登録前データが暗号化されていないものの場合はバケットポリシー等で暗号化なしのPUTリクエストを拒否していると評価のフェーズで当然拒否されてしまうので。バケットの暗号化設定を行ってたところで意味がない。
なので、ポリシーを見直す。
S3のバージョンニングを有効にしているバケットにおいてHTTP503エラーが発生している
A. ライフサイクル管理でバージョンに有効期限をつけて削除する
オブジェクトをバージョニングで管理している場合、例えばあるオブジェクトでバージョンが数百万もできている……という状態になるとS3が過剰なリクエストトラフィックから保護するためにバケットへのリクエストを調整してしまい、結果としてサーバーエラーが起きてしまう。
なので、ライフサイクル管理においてNonCurrentVersionとExpiredObjectDeleteMarkerのポリシーを有効にして、バージョンに有効期限を設けて期限切れのものを削除するようにする。
AとBのVPCでVPC Peeringを行っているが、オンプレミスと接続しているAのVPCをの接続を冗長化させたい
気をつけることは以下のポイント
- VPC Peeringはあくまで1対1のVPC間接続であってA-B、B-CでピアリングしてもA-Cの関係にはならない
- 同様にエッジ間ルーティングもサポートしていないので、今回のケースのようにA-オンプレミスで接続関係にあってもBからオンプレミスへ接続することはできない
なので、A-オンプレミスの接続を冗長化、フォールトトレランスを実現したい場合は
- Direct Connectを利用している場合は、仮想インターフェース(オンプレ側のルーターやファイアウォール)を増設して接続先を増やして動的ルーティングを行う
- VPNを利用している場合は同じ理屈でカスタマーゲートウェイを増設する
- Direct ConnectとVPNを併用する
といったように接続パターンを複数用意することで、実現できる。
オンプレミスでActive Directoryを使っているのでAWSでも利用したい
A .AWS Directory Service AD Connectorを利用する
具体的には次の2ステップ。
- AD Connectorを利用してオンプレ側のMicrosoft Active DirectoryとIAMユーザーを連携させる
- 次に連携させたユーザーやグループに対してIAMロールを付与して権限管理を行う
オンプレミスのストレージとEFSでデータ移行を行いたい
A. AWS DataSyncを使う
EFSではなく、S3や同じファイルシステムでもWindowsファイルシステムならFSx、あるいはテープボリュームを利用したい場合やボリュームゲートウェイを利用してプライマリーは自社データセンターに残すが、S3にバックアップを保存したい、またはS3をプライマリーにして自社データセンターにはキャッシュを残す……等々の利用方法の場合はStorage Gatewayを使う。
ACMがサポートされていないリージョンでSSL証明書を使いたい
A. IAMで外部プロパイダーから取得したSSL証明書をデプロイする
オンプレミスのデータセンターのサーバーの使用率等のデータ、依存関係のマッピングを収集したい
A. AWS Application Discovery Serviceを利用する
オンプレミスのワークロードをAWSに移行したい
A. AWS Server Migration Service利用する
ちなみにデータベースの移行だとDatabase Migration Serviceを利用する。