受験結果

復習
EBSの性能選択について
課題.スループットとIOPSの違い、及びそれに伴う汎用SSDとスループット最適化HDDの違いがいまいちわからない。
→
参考
参考
IOPSはInput Output per Secondの略、つまりストレージが1秒あたりに処理できる読み書きアクセスの数。
つまり。1秒間のストレージ読み書き性能のこと。
対して、スループットは一定時間にどれだけのデータを転送できるか、或いは単位時間あたりで処理能力がどれくらいあるかという指標。
つまり、1秒間の最大データ転送量のこと。
ちなみにディスクのスループット、あるいはIOPSが高ければパフォーマンス自体が上がるかというとそうではないというのが下記の話に繋がってくる。
つまり、ストレージの性能というと市井の人からすると読み書きだけで考えてしまうが、ルーターのようにスループットの指標もあるのだというところをまず理解すれば違いがわかってくる。
つまり、SSDとHDDでは当然SSDの方が読み書き性能が高いのでそれはよしとして、スループット性能でもそれがそのまま当てはまるとは限らないというところが肝だったのだ。
現に汎用SSDとスループット最適化HDDとではグレードによっては下記のようにHDDのがスループット性能が勝るケースが存在する。
なので、問に書かれているユースケースをしっかり把握して何を1番重視するのかを把握することがこの手の問題のコツ。
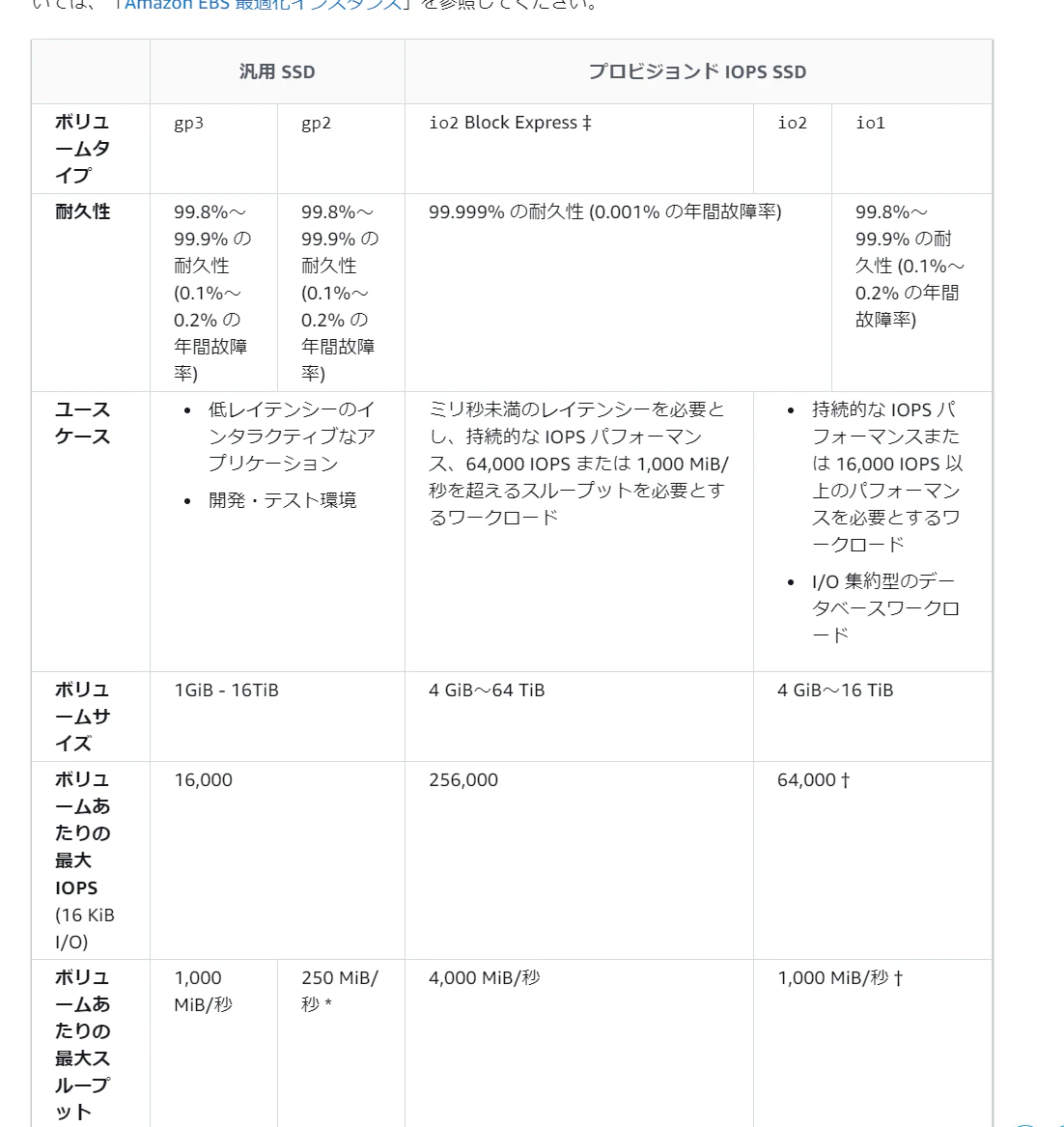

ストレージの種類について
Q.ストレージの数が多すぎる
→
こればっかりはもうひたすら問題周回して脳に叩き込むしかないと思ってる。
-
Amazon FSx……EFSの亜種みたいなもの。Microsoft アプリケーションが依存する互換性と機能が必要で、SMBプロトコルを利用したNTFSファイルシステムを構築するときに選択。
-
EFS……レイテンシーの影響を受けやすい単一スレッドのワークロードに可能な限り高いスループットを必要とする、高度に並列化されたスケールアウト型ワークロードの多様なユースケースに使う。キーワードはNFSv4プロコトルの利用、アタッチはできずエンドポイントを介した接続、階層ディレクトリ構造
-
S3……AWSのストレージの基本。EC2インスタンスでDBインスタンスを立てる、RDSを使うに並ぶ基本的なAWSストレージの選択になる。プロトコルはSFTP。
-
EBS……DBインスタンスやそもそものインスタンスのボリュームとして利用するブロックストレージ。キーワードはスループット及びトランザクションに強い。
CloudFrontでの言語切替
→
クエリ文字列パラメーター値に基づいて言語を決定すればいい。
ちなみにサイトの言語をユーザーに合わせて切り替えるみたいなことは他のサービスでもできる(ex. Route53の位置情報ルーティング)
メッセージングサービス
Q.メッセージングサービスって通知サービスじゃないの?
A.正確には違う。
私は通知サービスと聞いて、スマホのプッシュ通知みたいなものなのだなと思ってたらどうやら違うらしい。
正確にはプッシュ通知の役割も内包しているが、アプリやサービス間での橋渡し役という方が正しい。
橋渡しするものはメッセージングサービスによって違うがRequest、Responseなどの通信やエラーメッセージ、任意のデータと色々ある。
ここを勘違いしているといつまでもSQSとSNSが理解できないので注意したい。
参考
これを加味してSQSとSNSとの比較をしていくと、SQSは
メッセージをキューとして保存することでポーリング処理ができるサービス。
Pull型であり、かつRequest、Responseもメッセージとして扱えるので双方向な通信も可能である。
よって、分散アーキテクチャにおいてマイクロサービス間の処理の引き継ぎなどに利用できる。
という特徴があり、SNSは
Push型でありプロデューサー(送信側)をコンシューマー(受信側)がサブスクライブするタイプのメッセージジングサービスで、当然一方通行な通信になる。
こちらもイベント処理をトリガーにして処理通知することで、それをトリガーにコンポーネント間の連携を行うことができる。
ただし、その連携を確実に行うのであれば並列処理で負荷分散できるSQSのが適している。
という特徴がある。
実際にはSNS→SQSでポーリングというパターンも珍しくないそうな。
ちなみに、メッセージングサービスがここまで充実しているので、その役割でLambdaを使うのは非効率とされている、注意。
KinesisのストリームデータがS3に送られてこない?
KinesisからS3へのストリームデータの送信でトラブルがあった場合は、即時に処理エラーが通知される。
よって障害等でなければKinesis側の設定を確認する。
デフォルトではKinsesisのストリームデータは24時間以内でなければアクセスできない設定になっている。
なので、Kinesisのストリームデータ処理がアーキテクチャでどう行われているか確認し、S3に送信されるまでに時間がかかっているようならそこを見直すというのがトラブルシューティングの基本となる。
ちなみにストリームデータははIoT端末からのフィードバックであったりも分析・解析に利用でもリアルタイム性を求められることも少なくないので、即時に処理されるのが望ましいことが多い。
Route53のルーティングパターン
この試験ではBlue/Greenデプロイメントを行う場合適切なルーティングは?という問題だった。
そもそもBlue/Greenデプロイメントがわからなかったのでそこから。
Continuous Deliveryからの発展である。
コード変更を行うとビルド・テスト・デプロイ・リリース準備までの工程を自動化する……といった仕組みを作る、或いはそういう設計をしようという考え方をContinuous Delivery(継続的デリバリー)なんていうということは講義でもやった。
ここから派生したのがはBlue/Greenデプロイメントという手法で上記に加えて
- デプロイの自動化
- サーバーのダウンタイムゼロ
を目標とする。
特にこのサーバーのダウンタイムゼロというのが肝で、例えばテスト環境と本番環境、また或いは旧バージョンと新バージョン……という関係性があるような2つの環境をダウンタイムなしで切り替えたいというのが目的になる。
で、Route53が関係することからわかるようにリクエストを切り替えることでそれを実現することになる。
大まかなフローとしては
- ブルー環境とグリーン環境を作成
- ブルー環境(こっちが新バージョン環境)にルーターをアタッチ
- リクエストをグリーンからブルーに行くように切り替える
- ブルーの動作が安定したら完了。問題が起きた場合はグリーンへロールバック
AWSでのモデルケースとして以下の図が紹介されている。
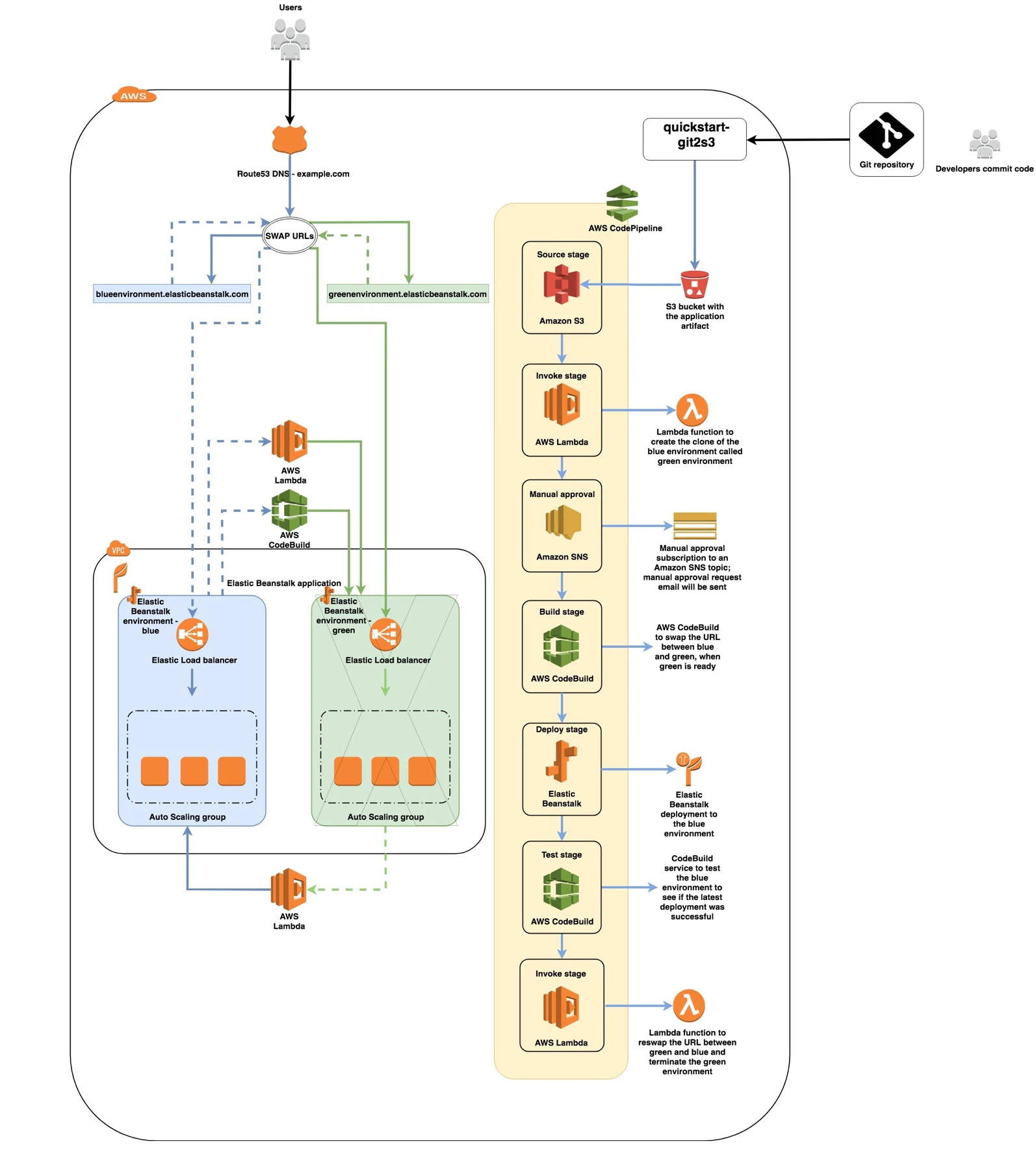
-
コードはGitHubなどでリポジトリで管理し、Pushされてコードに変更があった場合はS3のバケットへ放り込まれる。
-
放り込まれたことを感知したLambdaがブルー環境のクローンとしてグリーン環境を作れと発火
-
SNSがTopicを送信する
-
Topic送信と連携して、CodeBuild起動。ブルー環境とグリーン環境とでURLを入れ替える準備をする。
-
Elastic BeanStalkをブルー環境に導入する
-
CodeBuildでデプロイがうまく行ったかの確認としてブルー環境のテストが始まる
-
テストで問題なければ、Lambdaでブルー環境とグリーン環境とでURLを入れ替える。
-
上記の工程をCodePipelineで管理・自動化。
というフローで紹介されている。
あとはRoute53でルーティング切り替えということになる。
ではRoute53ではどれを選択すればいいか?
A.加重ルーティング
複数のリソースを単一のドメインかそれに伴うサブドメインに関連付けることで、ルーティングに重み付けを行うことができるというのが加重ルーティングだった。
したがって、負荷分散や今回のようなBlue/Greenデプロイメントのケースではこれが適しているということになる。
マルチAZを間違えない
課題.マルチAZを負荷分散目的で構成するものと思ってしまっている。
これにはELBをマルチAZに……という思い込みをしていることに原因がある。
マルチAZにするからといってELBを使うとは限らない、問題文や解答選択肢に書いていない限りは。
なので、どのサービスやユースケースでマルチAZを利用するのかということを問題文から読み取る。
実際には使わないということはあまりないとは思うし、前述Blue/GreenデプロイメントのケースのようにマルチAZとELBはセットが基本だとは思うが、
RDSの読み取り処理が重い場合、拡張手段はどうするか?
という問いに対しての最適にはならないということだ。
この場合はRDSはリードレプリカの作成とSharingによる水平分割ができるのでそれによって負荷分散を行う。
マルチAZを構成する意味の大前提は可用性の確保、耐障害性の確保、冗長性の確保そしてレプリケーションの3点、具体的にはシステムのフェイルオーバーやDBのレプリケーションの仕組みを構成するためにあるということを覚えておく。
AWSの解析・分析シリーズ(EMR)編
詳しいことは下記参考ページやBlack Belt参照。
専門要素と実務経験の必須度満載で詳細に理解することは今の私には難しい。
参考: [初心者] EMRとは何ですか/とりあえずざっとまとめてチュートリアルしてみる
AWSチーム社内勉強会「EMRおじさんに聞いてみよう」レポート
AWS再入門 Amazon Elastic MapReduce編
EMRとは?
動的でスケーラブルにEC2インスタンス全体で膨大な量のデータ処理を簡単、高速、費用対効果を高くした分散処理に適したアプリケーションを提供してくれるサービス。
ちなみにアプリケーションはHadoopやSparkといった分散処理に強いフレームワークで構成される。
ざっくりいうと
下記に別途まとめていますが、先に簡単にEMRがやってくれることをざっくりまとめてしまうと、この3つだと思われます。
1.前提: 大量のデータがあります or 続々とデータが追加されていきます。
2.大量のデータをうまく分散処理してくれるマシンクラスターを作ります。
3.分散処理に適したアプリケーションを実行します。
※ 2の部分をブラックベルトだと、「分散処理基盤」と称しています。
本来は2,3を自力で色々考慮した上で、設計して実装しなければならないものを、EMRはポチポチするだけで構築してくれるという優れものなわけですね。
※ 上記参考記事から引用
ということらしい。
要はデータさえ用意すれば、あとはウィザードでポチポチするとうまいことそのデータを分散処理するクラスターを作成し、そのクラスターを使ってHadoopやSparkでアプリケーションを作ってくれるというサービス。
-
データ蓄積……S3、Kinesis(つまりストリームデータも可)、DynamoDB
-
マシンクラスター……Master、Core、Task node(MasterがCoreとTaskを監視する)
-
アプリケーションフレームワーク……Hadoop、Sparkなど
という構成で成り立つ。
で、この分散処理のアプリケーションで何をするのかというと
- Webインデックス作成
- データマイニング
- ログファイル分析
- 機械学習
- 財務分析
- 科学シミュレーション
- バイオインフォマティクス
というデータ集約タスクを実行する。
特にELBで結合されたログファイルやCloudFrontからのアクセスログ収集・分析、機械学習によるレコメンデーションエンジンの構築というところは得意。
S3を経由せず、Kinesis、DynamoDBと直接連携することもできるのでストリーミング処理も可能。
ちなみにKinesis Analyticsはストリームデータのリアルタイム処理得意だが、ログ解析には不向き。
S3バケットに対するリクエスト(トラフィック)処理要求に対して
パフォーマンスを上げたいならオブジェクト名を日付ベースの順次命名で設定するようにする。
以前はオブジェクト名の前にハッシュキーまたはランダム文字列を使用だったが過去の対応。
Amazon S3 にはどのようなオブジェクトキー命名パターンを使用する必要がありますか?
オンプレミスとAWSリソースを連携させたい
A.高スループットを実現したいなら専用線でDirect Connect。それが不要ならAWS VPN。
CloudFrontの配信処理コストを削減したい
A. エッジロケーションでファイル圧縮処理をすることでファイルサイズを縮小し、DL時間を短縮する。
なお、キャッシュ保持時間の削除は有効そうに見えるが、逆にファイルアクセスの数が増えることが懸念され逆効果になる。
S3に可用性とAZ喪失に対しての可用性がほしい
A.S3は高可用性が担保され、AZに依存しないので特に対応が必要ない。
ひっかけなので注意。
冗長性をさらに高くしたいならレプリケーション(リージョンに対する障害に強くなる)を行えるように設定する。
パイロットライトって?
停止した状態の最小限の構成を別のリージョンに用意しておき、障害発生時に立ち上げる構成。
コールドスタンバイさせておくだけのコストがかかる。
マルチサイトアーキテクチャって?
複数のデータセンターやクラウドサービス間でサイトを分散するマルチAZ構成。
当然コストはかなり高くなる。
Portを覚えて
SSH……22
HTTP……80
FTP……20
データセンターのバックアップをオンプレミスのサーバーからクラウドに取りたい
A. iSCSIを介してAWS Storage Gatewayを使う。
AWS Storage GatewayはオンプレミスアプリケーションをAWSのクラウドストレージとシームレスに連携させたいときに使える。
対応するストレージプロトコルは
- NFS
- SMB(つまりAmazon FSx for Windowsを利用する)
- iSCSI(ブロックストレージにしたいならこちら。Volume Gatewayの利用になる)
などがあるので要件に従って選択する。
保存先は上記以外にもS3 GatewayやTape Gatewayが利用できる。
例えばiSCSIプロトコルを使う要件であると、Volume Gateway、つまりクラウドベースのストレージボリュームを作ることになる。
これには保管型とキャッシュ型の2種類が存在して、
保管型ボリュームを使用すると、プライマリデータをローカルに保存する一方で、そのデータを非同期に AWS にバックアップする。
なので、オンプレミスのアプリケーションがそのデータセット全体に低レイテンシーでアクセスできるようになり、
同時に、耐久性のあるオフサイトのバックアップが提供されることになる。
今回はバックアップなのでこれを作成し、iSCSI デバイスとしてオンプレミスのアプリケーションサーバーからマウントする
また保管型ボリュームに書き込まれたデータは、オンプレミスのストレージハードウェアに保管され、同時にこのデータは Amazon Elastic Block Store (Amazon EBS) スナップショットとして Amazon S3 に非同期でバックアップされる。
ちなみにキャッシュボリュームはS3にデータを保管し、頻繁にアクセスが求められ、低レイテンシーを実現したいデータサブセットのコピーをローカルに保持させるためのボリューム。
プライマリストレージのコスト削減、及びストレージをオンプレミスで拡張することを抑えたい場合に利用する。
ちなみに
-
保管型……プライマリはオンプレミスでAWSのクラウドストレージはバックアップ
-
キャッシュ型……プライマリはAWSのクラウドストレージでオンプレミスはキャッシュ
という違いがあることを覚えておく。
VPCにホストされているインスタンスに対してトラフィックをインターネットに通過させないでS3にアクセスできるような設定をしたい
A.VPCエンドポイントを設置
Auto Scalingを設定しているが、短期間にスケールイン・アウトを繰り返してしまう
A. クールダウンタイマー値の最適化とCloud Watchのアラーム設定を変更する
この現象が発生する要因は負荷減少に対するスケールインの開始が早すぎるところにあるので、クールダウンタイマーを設定することでスケールインの開始を遅らせ、アラーム設定でスケールインの基準値を変更することでスケールインの発生をコントロールすればいいという話。
AMIから複数同じインスタンスを起動したのに一部のインスタンスがネットワークに繋がらない
A, EC2インスタンスにはたまにパブリックIPアドレスが付与されないケースがあるのでIPアドレスが付与されてるか確認する
Standard-IAとOne Zone-IAを間違える
Standard-IAもOne Zone-IAもInfrequency Access、つまり低頻度アクセスなデータに対するストレージに使う。
では、どう使い分けるかというと
- Standard-IA……必要時にはすぐにアクセス可能かつ重要なデータ
- One Zone-IA……マスターデータ、バックアップのコピー等の長期保存やデータ消失のリスクを考えなくていい場合
という点で使い分ける。
Redshift
講義ではいまいちしっくりこなかったのでBlack Belt他を見てきました。
【AWS Black Belt Online Seminar】Amazon Redshift 運用管理
Redshiftって?
高速、スケーラブルで費用対効果の高いデータウェアハウス及びデータレイク分析を行うためのマネージドサービス。
Redshift自体のスケールアップもS3と連携してデータ増加に伴うS3ストレージの追加も自動でやってくれる。
負荷に合わせてノードのスケールアウト・インも可能(Elastic Resize機能)で、それでもピーク時にクエリのキューに待機が出てしまうくらいに負荷が上がってしまったらクラスター自体を拡張してそこでも並列処理をさせるようなスケーリングも可能(Concurrency Scaling機能)
DWHとデータレイクの違いって?
大雑把に言うと
- RDB(正確には分析特化仕様として列指向であったりする)か分散型DBか
- DWHはBIデータ(ビジネスインテリジェンスデータ)にデータレイクはビックデータやIoTデータに用いられる。
両社ともにいわゆる行指向なDB設計で必要な1行のレコードをすべて読み込み、そこから列ごとに取り出しや更新を行ういう処理を頻繁にやるためのものではなく、大量に溜め込まれたデータに対してのクエリ(数年分のデータから特定の商品の売上を取り出し分析する等)を実行するためのDBである。
Redshiftはこの2つのDBで分析用クエリ実行をすることに特化した管理システムであり、特に柔軟なクラスタ構成(複数のサーバーを立て、処理分散させつつ見立てとしては1台のサーバーになるような構成)によって並列分散処理を行うためのツールになる。
ワークロードの最適化って?
例えば
- テーブルメンテナンス
- 分散、ソートキーの自動設定
- クエリへのリソース割当の最適化
こういうことを指す。
Redshiftはこれらを自動でやってくれる。
もちろん手動で追加のチューニングを行うことも可能。
(圧縮、分散、ソート、マテリアライズドビュー、クエリの優先度設定等)
ソートキーと分散キーって?
ソートキーはクエリで頻繁に絞り込みを行う列のこと。
ソートキーを指定しておくと、データロードやメンテナンス時に自動でデータがソートされる。
分散キーはRedshiftでデータの分散方法の一つであるKEY分散で用いられるもの。
各スライス(ノードに含まれる並列処理の単位。例えば1ノードの処理を2つの処理にすると1ノード2スライスということになる)にJOINするためのキーを配布して分散させるのがKEY分散。
分散スタイルって?
並列分散処理のやりかたみたいなもの。
JOINにはあまり向かないが、もしテーブルをJOIN場合はノード間でネットワークI/Oが多発して処理速度ができるだけ落ちないようにというのが目的。
以下の3種類がある。
- KEY分散……同じキーのデータは同じスライスへ
- ALL分散……小さいDB規模の場合はすべてのノードへデータを入れる
- EVEN……ノードに均等に分散する(ラウンドロビン)
ノードって?
クラスタを構成する要素。
元締めとしてクエリのエンドポイントかつSQL処理コードを生成し、配下のノードに展開するリーダーノードと実際に処理を実行するコンピュートノードとがある。
で、このコンピュートノードを増やすことで処理性能を上げることができる(スケールアップすることができる)
インスタンスファミリーどれ使えばいいの?
A. 基本的にはストレージの違いなのでそれで選ぶ
- RA3……マネージドストレージでSSDキャッシュ
- DC2……SSD
- DS2……HDD
迷ったらRA3だ、少数のノードで大量のデータを格納できてかつ、マネージドストレージだからノードの追加なく急な増加にも対応できて、おまけにRA3でしかできない機能がある。
(クエリ高速化機能であるAQUA、Data Sharing、クロスAZクラスターリカバリー)
検討の結果RA3では身に余るというなら、性能が必要かどうかで選ぶ。
データが多くなく性能が求められるならDC2、データが大量であるが偏りないアクセスを求められるならDS2……という感じらしい。
障害時は?
基本的にはS3に継続的に増分バックアップが行われ、スナップショットも自動で取得される。
また、スナップショットはリージョン間コピーも可能。
AZ自体が止まってしまった場合に対してはRA3を選択していればクロスAZクラスターリカバリーを使う。
自動で別のAZにオンデマンド(利用時間で課金)なクラスターが作成されてそこにフェイルオーバーされる。
Redshiftで用いているデータ利用をVPC内に限定させたい
拡張VPCルーティングを設定する。
またS3のアクセスをVPCエンドポイントを設定することでも可能。
Data Sharing
Redshiftのクラスター間でセキュアかつ簡単にデータを共有することが可能となる機能。
プロデューサークラスター(共有したいデータを書き込むクラスター)が書き込んだデータをRead Onlyで他のクラスターと共有することができる。
データの移動が少なく、かつアクセス権の管理と共有状況のモニタリングだけでセキュアなデータ共有が実現するのが特徴。
EX.DWHでのRedshift
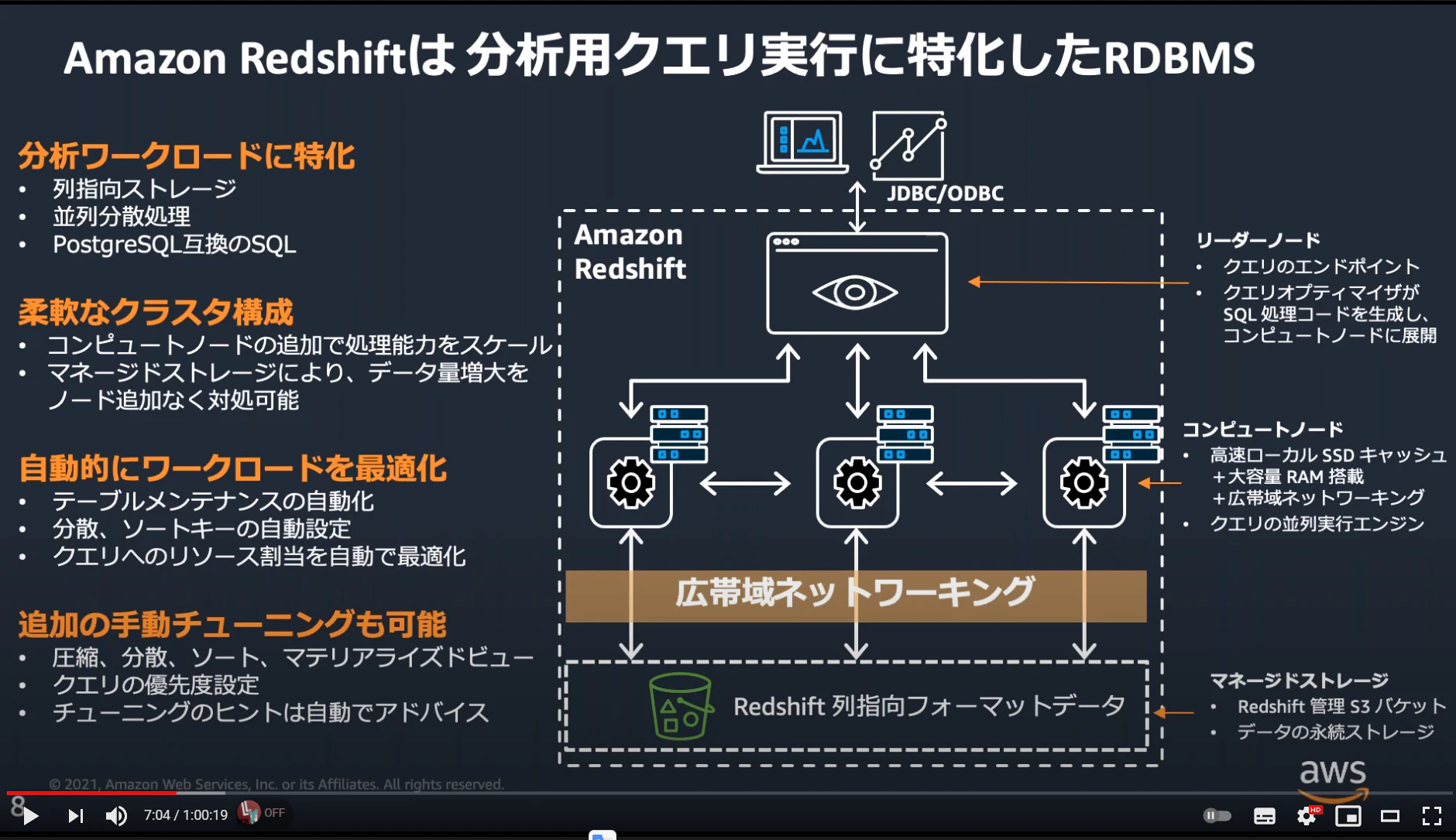
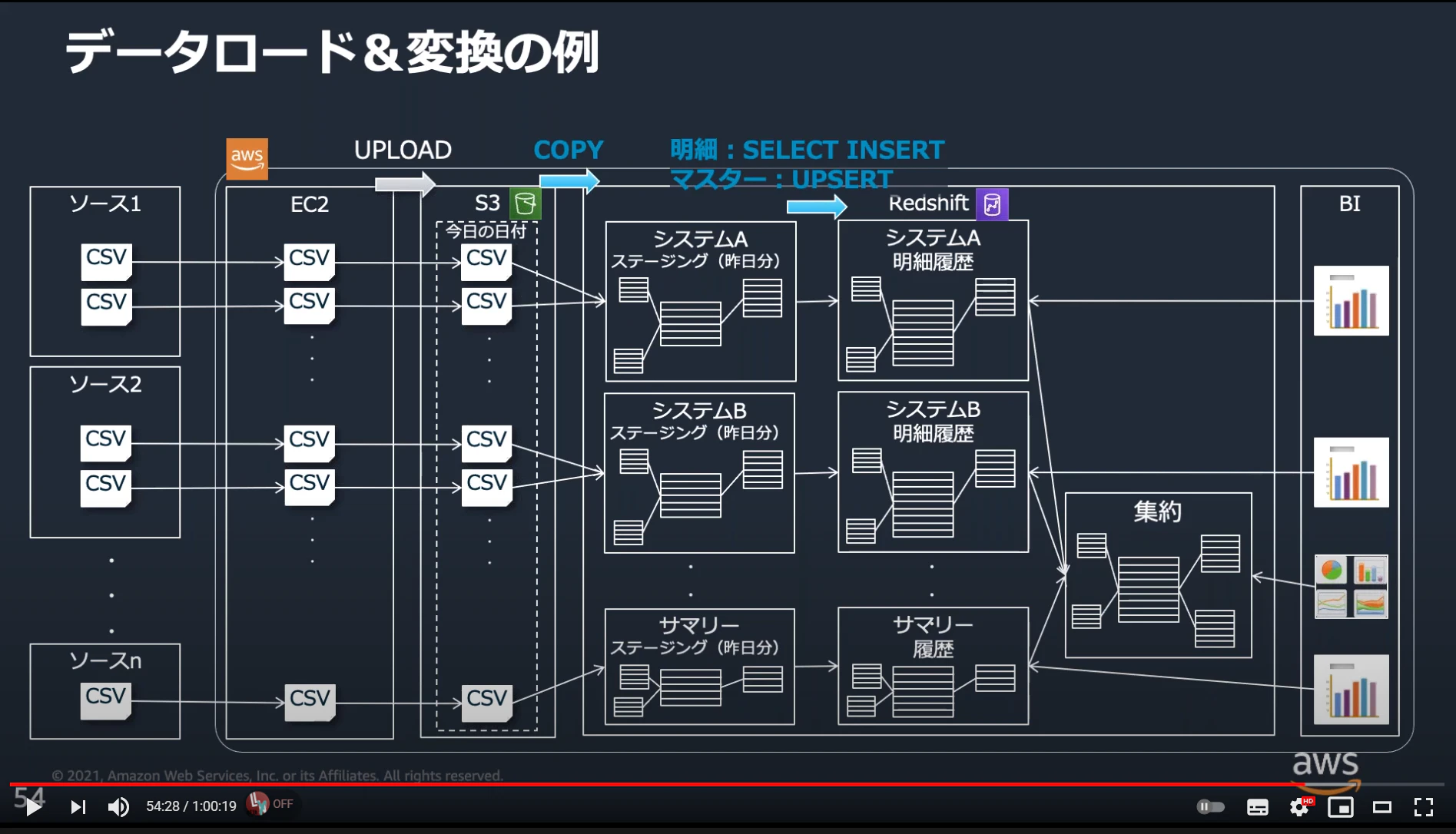
引用: 【AWS Black Belt Online Seminar】Amazon Redshift 運用管理
Ex. データレイクでのRedshift
Redshift SpectrumというS3にデータをおいたまま当該バケットを解析・分析する機能を使う。
