TL;DR
Shift_JISにしただけでコンパイラが通らなくなる恐ろしい事件とその回避法について。
- \ (¥)のASCIIコードは0x5c
- 表、能は良くない
- UTF-8は神
2023/12/06追記
誤りがあったので訂正します。こんな読まれると思ってなかったので正直ちょっとびっくりしていますが、いろいろコメントありがとうございました。(ツイート等全て拝見しました。)
- Shift_JISが悪いわけではない(デフォルトのエンコーディング設定の問題)→追記しました
- UTF-8にはUTF-FSSという仕様でこの問題が回避されている→マジでタメになる知識ありがとうございます
- OSによってデフォルトのエンコーディング設定が異なるせいで、デフォルト環境での動作がOSにより異なる→なるほど?(調査中)
- CRLFとLF問題では→なるほど?(調査中)
- そんな問題何を今更→UTF-8が出てから生まれたからです。
\を改行とみなすかどうか
C言語のコンパイラは\が行末に来ると改行を無視します。
int main(void) {
//この行はコメントだよー \
この行もコメント
この行はコメントではない
return 0;
}
例えば、このプログラムはエラーになるのでダメです。
int main(void) {
//うわー \
if (1) {
}
return 0;
}
これはif(1) {がコメントと解釈されると、それに対応する中括弧が対応しなくなるためです。
本題 Shift_JISのトラップ
ここからが本題です。
int main(void) {
//あいうえお
if (1) {
}
return 0;
}
このプログラムは問題なくコンパイルできます。(そりゃぁそう)
int main(void) {
//プログラムの才能
if (1) {
}
return 0;
}
しかしこちら、Shift_JISで保存してコンパイルすると、エラーが起こることがあります。は?
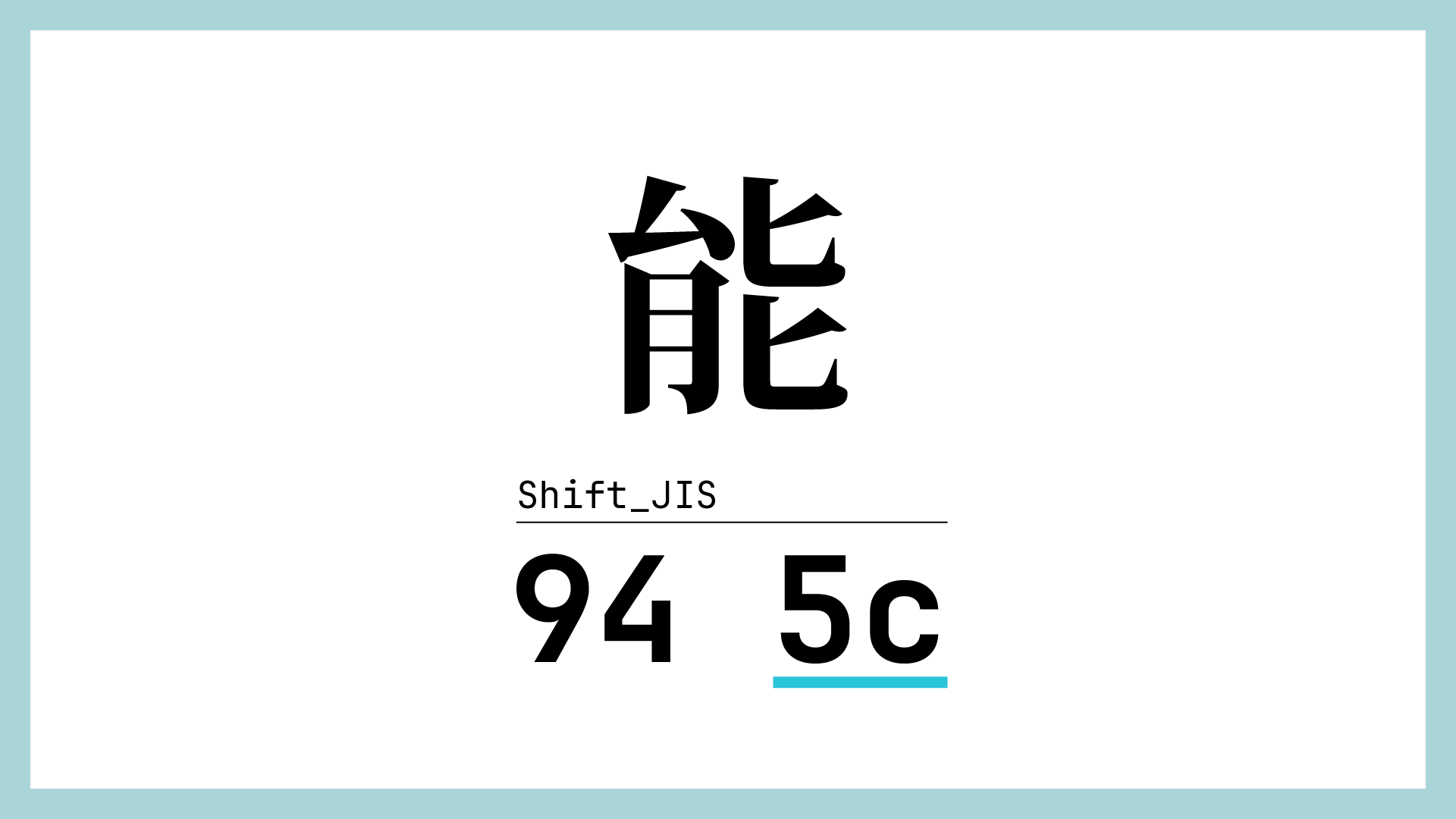
\ (¥)のASCIIコードは0x5cなので、エンコーディングの設定が間違っているとコンパイラが能の2バイト目を\と解釈してしまいます。そうするとif(1) {が無視されてエラーとなります。
他にもこのような文字は存在していて、全部書くと書ききれないのですがよく使いそうなものだと
- ソ
- 噂
- 欺
- 圭
- 構
- 十
- 申
- 貼
- 能
- 表
- 暴
- 予
です。表・能・欺とかは割と文末に来ることが多いので注意です。
これらは下位バイトが5cなのでShift_JISでプログラミングするときに行末にあってはいけません。ダメ文字1と一部界隈はよばれているそうです。
結局あのコメントはなんだったのか
int main(void) {
//プログラムの才能
//このコメントを消したらなぜか動かない
if (1) {
}
return 0;
}
先ほどの説明を踏まえるとこのコメントを説明できます。能の次の行がコメント(又は空白行)だと\と解釈されても次の行がプログラム的に意味を持たないため問題なくコンパイルできます。
対策
- ダメ文字を使わない
- Shift_JISを使わない
- 正しくエンコーディング設定をする
ちなみに先ほどの能が文末にくるプログラムは、UTF-8ではUTF-FSSにより下位バイトが5cになることはない2ので(流石!!)問題なくコンパイルできます。
コンパイル時にエンコーディングを正しく設定するとこの問題は発生しませんが、特別な理由でもない限りUTF-8で保存するのが無難だと思います。
Shift_JISの名誉のために
Shift_JISさん悪く言ってごめんなさい。確かにバイト数が少なく済むのはいいと思うのでがんばってね。俺は使わないけど。
まとめ
Shift_JISやめましょう
参考文献
- 文字コード表 シフトJIS(Shift_JIS) http://charset.7jp.net/sjis.html