Qiitaの初投稿です![]()
最近、業務で人物再認識AI(Presin Re-Identification)を使用した研究開発をする機会があり、この分野について研究サーベイをしています。
その一環として、CVPR2022に採択されたPerson Re-Identificationに関する論文をまとめてみよう! と思い立ったが吉日、まとめています。
(CVPR2022から"Re-Identification"で検索してhitした論文の一覧から引っ張ってきています。)
基本的な目的はサラッとしたサーベイなので、一旦は各論文のgithubとabstract(DeepL先生に活躍してもらいました)、モデルの概要図くらいまでをひたすら並べていきます。
※諸事情により、3Dモデリングベースの手法は割愛しました。また、Person以外のreidも今回はスコープ外にしています。
※自分の余力があるかぎり、加筆修正していくつも りです。優しい目で見てもらえると助かります。
※タイトルに![]() がついている論文は、僕が特に気になっている論文です。優先して、加筆していきます。
がついている論文は、僕が特に気になっている論文です。優先して、加筆していきます。
※別途、要望あれば論文詳細の加筆をしていきます。
論文のリスト(20本)
Unleashing Potential of Unsupervised Pre-Training With Intra-Identity Regularization for Person Re-Identification
キーワード: Unsupervised Learning Image-based Reid
概要
- 既存のreid手法は、初期化のために事前に学習したImageNetの重みを直接読み込むのが一般的
- しかし、reidのようなクラス間の分散が少ない分類タスクでは、ImageNetが想定した分類との間にギャップがある
- そこで対照学習に基づくreidのための教師無し事前学習フレームワークを設計し、UP-ReIDと名付ける
- 事前学習において、reidの特徴を学習するための2つの重要な問題に対処することを試みる。
- (1)CLパイプラインの拡張は人物画像における識別の手がかりを歪めてしまう可能性がある
- (2)人物画像の局所的な特徴量は十分に探索されていない
- 上記の課題に対し、UP-ReIDにL2正則化を導入
- グローバルな画像アスペクトとローカルなパッチアスペクトから来る2つの制約としてインスタンス化され、増強に対する頑健性を高めるために増強画像とオリジナル人物画像の間にグローバルな一貫性が保てる
- 一方でローカルな識別の手がかりを十分に探るために各画像のローカルパッチ間の固有のコントラスト制約が採用されている
- 事前学習において、reidの特徴を学習するための2つの重要な問題に対処することを試みる。
- PersonX、Market1501、CUHK03、MSMT17などの一般的なreidデータセットに対する広範な実験により、UP-ReIDを用いたpre-trainモデルをtuningすることで、最先端の性能を達成
手法のアーキテクチャ

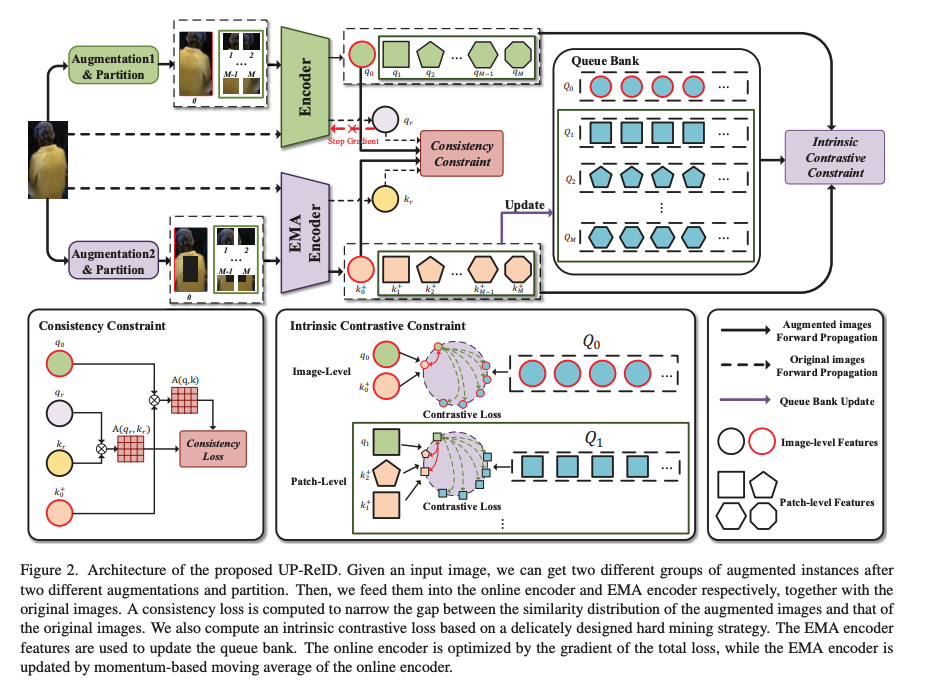
- 論文 リンク
- github リンク *no code
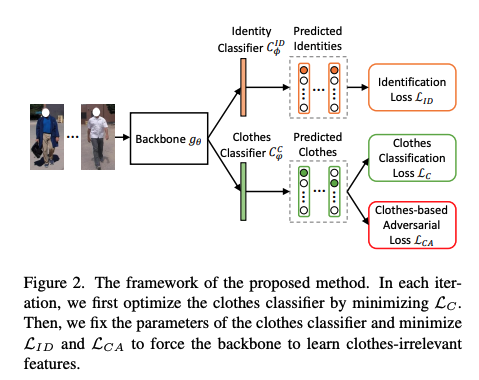
Clothes-Changing Person Re-identification with RGB Modality Only
キーワード: Supervised Learning Clothes-Changing Reid Video-based Reid
概要
- 衣服の着替えた場合のreidを行うためには、顔、髪型、体型、歩行など、衣服とは無関係な特徴を抽出すつ必要がある
- 先行研究では、主にマルチモダリティ情報(例えば、シルエットやスケッチ)から体型をモデル化することに焦点を当てていますが、元のRGB画像に含まれる服に無関係な情報を十分に利用できていない
- 本論文では,服装を考慮したCAL(逆行列損失)を提案し、服装を考慮したreidモデルの予測力にペナルティを与えることにより、元のRGB画像から服装に無関係な特徴をマイニング
- CALはRGB画像のみを用いたreidベンチマークにおいて、SOTAを達成
- また、動画は画像と比較して、より豊かな外観と付加的な時間情報を含んでおり、衣替えの再認証を支援するための適切な時空間パターンをモデル化するために利用することができる
- 一般に公開されている動画像のreidデータセットがないため、新しくCCVIDというデータセットを提供
- 時空間情報のモデル化には多くの改善の余地がある
手法のアーキテクチャ
Part-based Pseudo Label Refinement for Unsupervised Person Re-identification
キーワード: Unsupervised Learning Image-based Reid
概要
- Unsupervised reidモデルの一つ
- 近年の技術は擬似ラベル(= ??)を用いてこのタスクを達成しているが、擬似ラベルは本質的にノイズが多く、精度が低下する。この問題を解決するために、いくつかの擬似ラベルの精密化手法が提案されているが、これらはreidに不可欠な局所部分の特徴を無視するものである
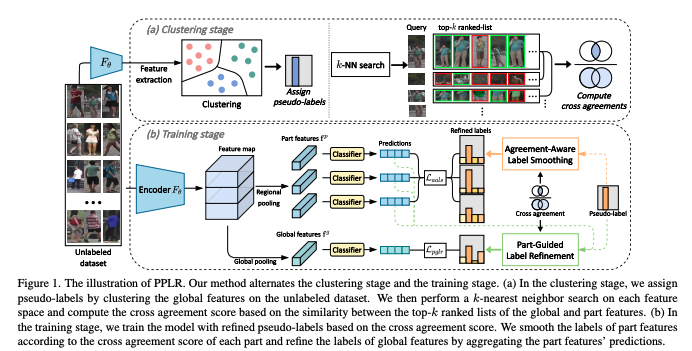
- この論文では、大局的特徴と部分的特徴の相補的関係を利用することで、ラベルノイズを低減する新しい部分ベース疑似ラベル洗練(PPLR)フレームワークを提案する
- 具特徴空間間のk近傍の類似度として相互一致スコアを設計し、信頼できる相互補完関係を利用する
- この相互一致度に基づいて、一部の特徴の予測値をアンサンブルすることで全体特徴の擬似ラベルを精緻化し、全体特徴のクラスタリングにおけるノイズを軽減する
- 与えられたラベルの一部の特徴に対する適合性に応じて、ラベルスムージングを適用することで、一部の特徴の擬似ラベルを洗練させる
- このように、相互一致スコアが提供する信頼性の高い補完情報により、我々のPPLRはノイズの多いラベルの影響を効果的に軽減し、局所文脈に富む識別表現を学習することができる
- Market-1501とMSMT17を用いた広範な実験により、提案手法の有効性が最先端の性能を上回ることを実証する
手法のアーキテクチャ
Learning with Twin Noisy Labels for Visible-Infrared Person Re-Identification
キーワード: Supervised Learning Visible-Infrared Reid
概要
- Visible-Infrared Person Re-Identification(VI-ReID)における未解決の問題、すなわち、ノイズの多いアノテーションと対応付けを指すTwin Noise Labels(TNL)についての研究
- TNLは、ノイズの多いアノテーションと対応付けを意味し、可視・赤外領域における認識性能の低さなど、データ収集とアノテーションの複雑さにより、誤った人物情報をアノテーションすることが避けられない
- 単一のモダリティで誤ったアノテーションを行ったデータは、最終的にクロスモーダルデータの対応付け(可視画像と赤外線画像の対応付)にノイズを与えてしまう
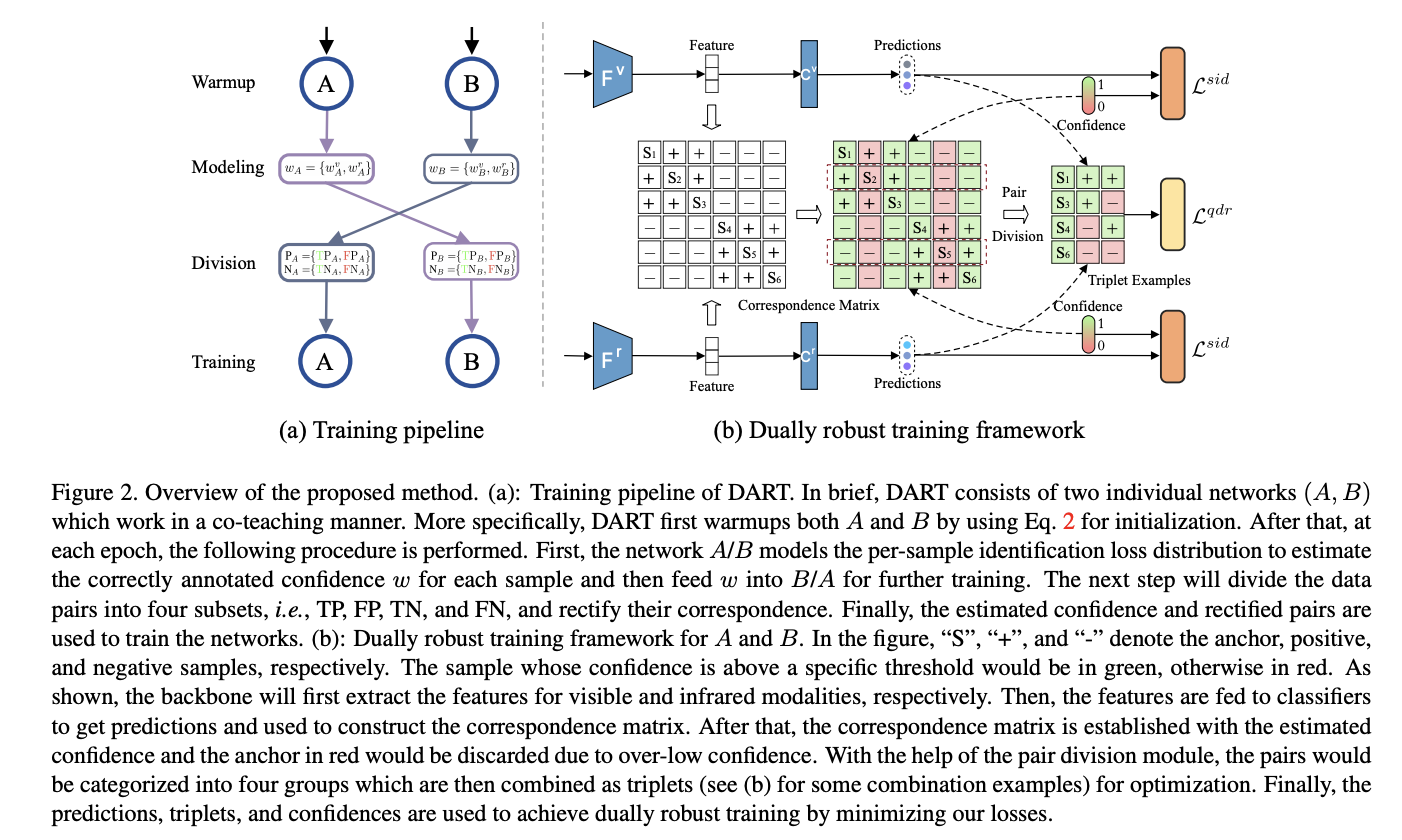
- この問題を解決するために、我々はDuAlly Robust Training (DART)と呼ばれるロバストなVI-ReIDのための新しい手法を提案する
- DARTは、まずディープニューラルネットワークの記憶効果を利用して、アノテーションの信頼度を計算
- 次に、推定された信頼度とノイズの多い対応関係を修正し、さらにデータを4つのグループに分割して利用
- 最後に、DARTはノイズの多いアノテーションとノイズの多い対応関係に対してロバスト性を実現するために、ソフト同定損失と適応的四重極損失からなる新しい二重ロバスト損失を採用
- SYSU-MM01およびRegDBデータセットを用いた広範な実験により、提案手法がノイズの多い双子のラベルに対して有効であることを、5つの最先端手法と比較して検証している
手法のアーキテクチャ
FMCNet: Feature-Level Modality Compensation for Visible-Infrared Person Re-Identification
キーワード: Supervised Learning Visible-Infrared Reid
概要
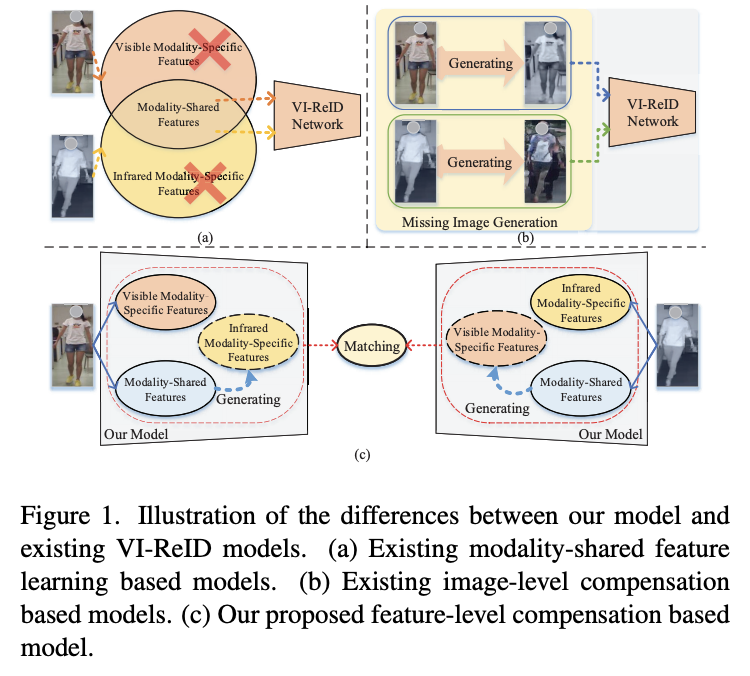
- VI-ReIDにおいて、既存のモダリティ( = 入力画像から得られる特徴のこと)別の情報補正モデルでは、モダリティ間の不一致を低減するために、既存の画像から欠損したモダリティの画像を生成する
- しかし、可視画像と赤外線画像ではモダリティの不一致が大きいため、生成された画像は通常、品質が低く、干渉情報(色の不一致など)が多く含まれています。このため、VI-ReIDの性能は大きく低下します
- この論文ではFeaturelevel Modality Compensation Network (FMCNet)を提案
- 一方のモダリティの共有特徴量から、他方のモダリティ固有の欠落特徴量を直接生成することを目指す
- これにより、VI-ReIDのために、識別性の高い人物関連モダリティ特有特徴を主に生成し、識別性の低いものを捨てることができるようになります
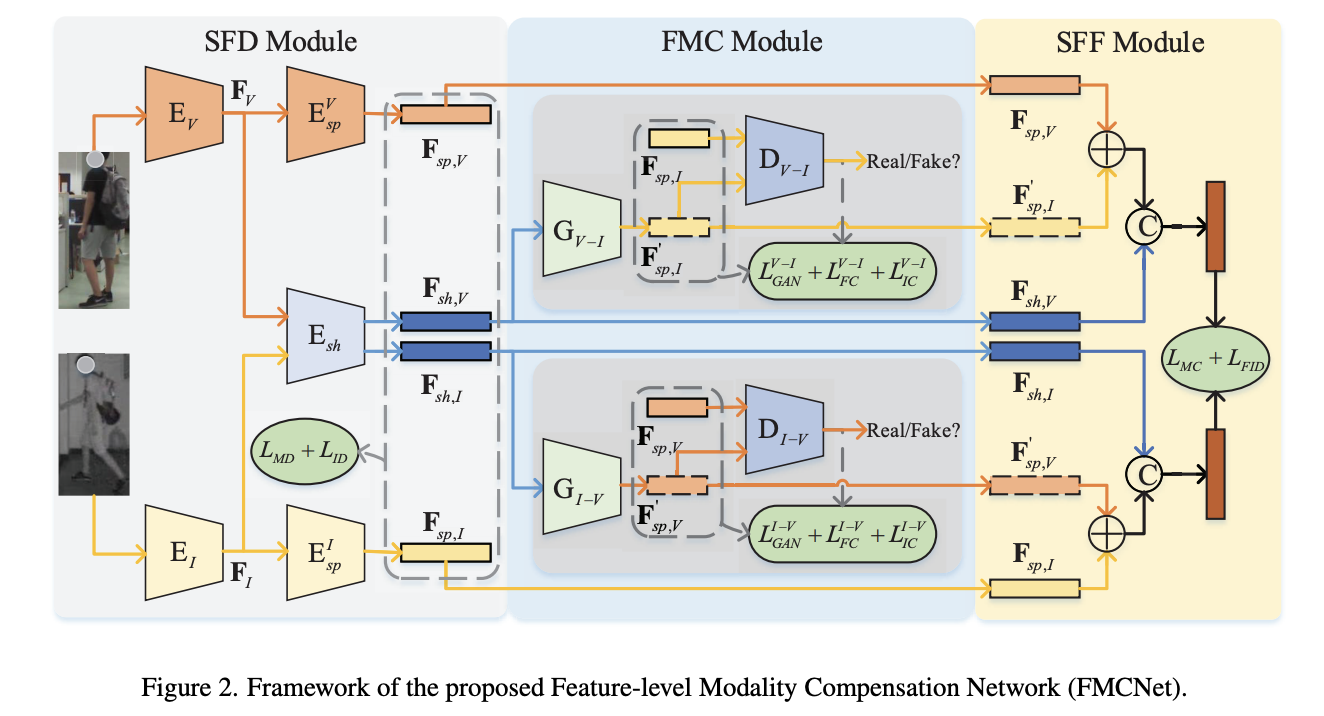
- そのために、まずシングルモダリティ特徴分解モジュールを設計し、シングルモダリティ特徴をモダリティ固有の特徴とモダリティ共有の特徴に分解
- 次に、既存のモダリティ共有特徴から不足するモダリティ固有特徴を生成するために、特徴レベルのモダリティ補正モジュールが存在する
- 最後に、既存の特徴と生成された特徴を組み合わせてVI-ReIDを実現するために、共有特徴融合モジュールを提案する
- 提案モデルの有効性は2つのベンチマークデータセットで検証される.
手法のアーキテクチャ
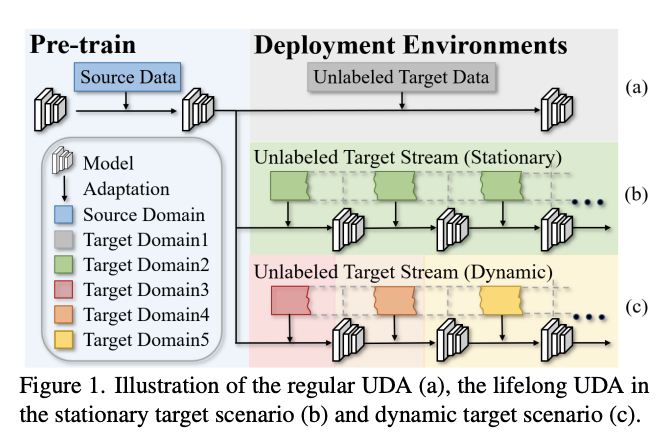
Lifelong Unsupervised Domain Adaptive Person Re-identification with Coordinated Anti-forgetting and Adaptation
キーワード: Supervised Learning Visible-Infrared Reid Video-based Reid
概要
-
VI-reIDタスクに取り組んだ論文
-
一般的なデータセットでは、可視画像と赤外線画像のデータが一度にアクセス可能であることを前提とされているが、実世界のストリーミングデータでは、このことがデータの統計量の変化へのタイムリーな適応や、増加するサンプルの十分な活用の妨げとなる場合が多々ある
-
この論文では、より実用的なシナリオに対応するために、永続的に教師なしでreidを行う Lifelong Unsupervised Domain Adaptive (LUDA) という新しいタスクを提案
- reidのようなクラスタ間の分散が少ない人物検索タスクに対して、壊滅的な忘却を緩和しつつ、ターゲット環境における未知データに対して継続的に適応するモデルを必要とするため、挑戦的なタスクになる
-
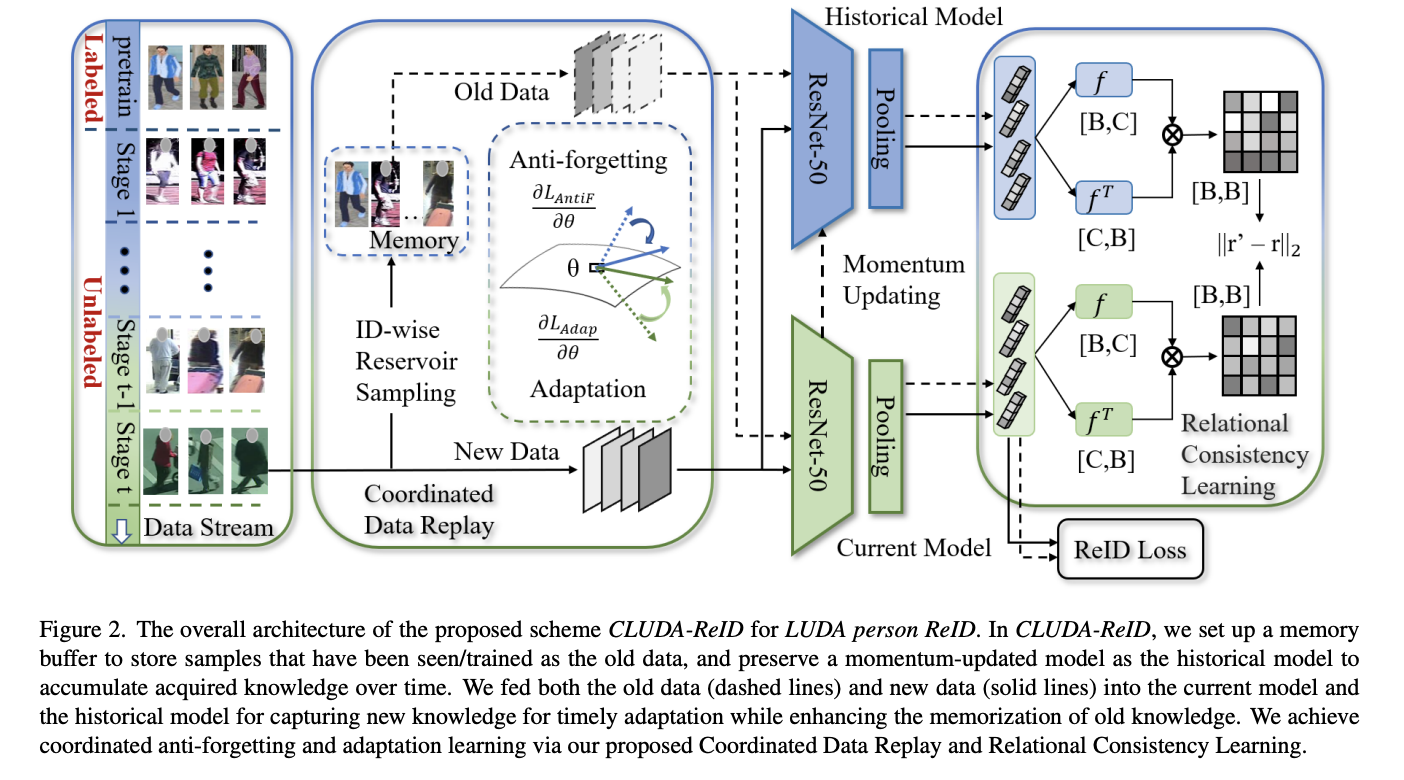
LUDAに効果的なスキームを設計し、忘却防止と適応をいい塩梅にバランシングしてくれるCLUDA-ReIDという手法を提案
- meta情報を用いた 「Coordinated Data Replay strategy」というを手法を用いることで、古いデータを再生し、適応と記憶の両方に対して協調的な最適化の方向性を持つネットワークを更新
- その後、過去に獲得した特徴データを蒸留・継承するための「Relational Consistency Learning」という手法を用いる
-
実用的な応用シナリオを模擬するために2つの評価設定を行った
- CLUDA-ReIDは、静的な検索対象ストリームを扱うシナリオと動的な検索対象ストリームを扱うシナリオの両方において、有効な効果を実証した
手法のアーキテクチャ
 Large-Scale Pre-Training for Person Re-Identification With Noisy Labels
Large-Scale Pre-Training for Person Re-Identification With Noisy Labels
キーワード: Semi-Supervised Learning Image-based Reid
概要
- この論文では、ノイズの多いラベルを用いたreidの事前学習の問題を扱うことを目的としている
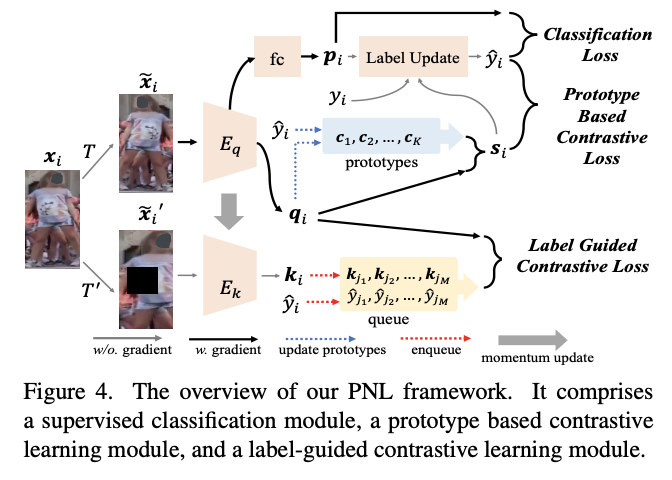
- 事前学習課題を設定するために既存の教師なしデータセット "LUPerson "のに簡単なビデオに、Online Multi Object Trackingを行い、"LUPerson-NL "と呼ばれるノイズラベル付きのバリエーションを構築
- trackletから自動生成されるIDラベルにはノイズ(= 付与したTrackerIDの揺れ)が含まれるため、ノイズラベルを利用した大規模な事前学習フレームワーク(PNL)を開発した
- このフレームワークは、Classification、Unsupervised Contrastive Learning、Supervised Contrastive Learningの3つの学習モジュールで構成される
- 原理的には、これら3つのモジュールの共同学習により、類似する例を1つのプロトタイプにクラスタリングするだけでなく、プロトタイプの割り当てに基づきノイズの多いラベルを修正
- 人物の特徴表現空間をゼロから学習するスケーラブルな手法であるため、ResNetやOmni-Scaleのようなbackboneとなるモデルは不要
- 提案手法は、「LUPerson-NL」上でSOTAを達成
- PNLを用いたpre-trainモデルを、同じ教師ありreidモデルであるMGNに適用した場合、教師なし事前学習と比較してCUHK03、DukeMTMC、MSMT17でそれぞれ5.7%、2.2%、2.3%のMAP向上を確認
手法のアーキテクチャ
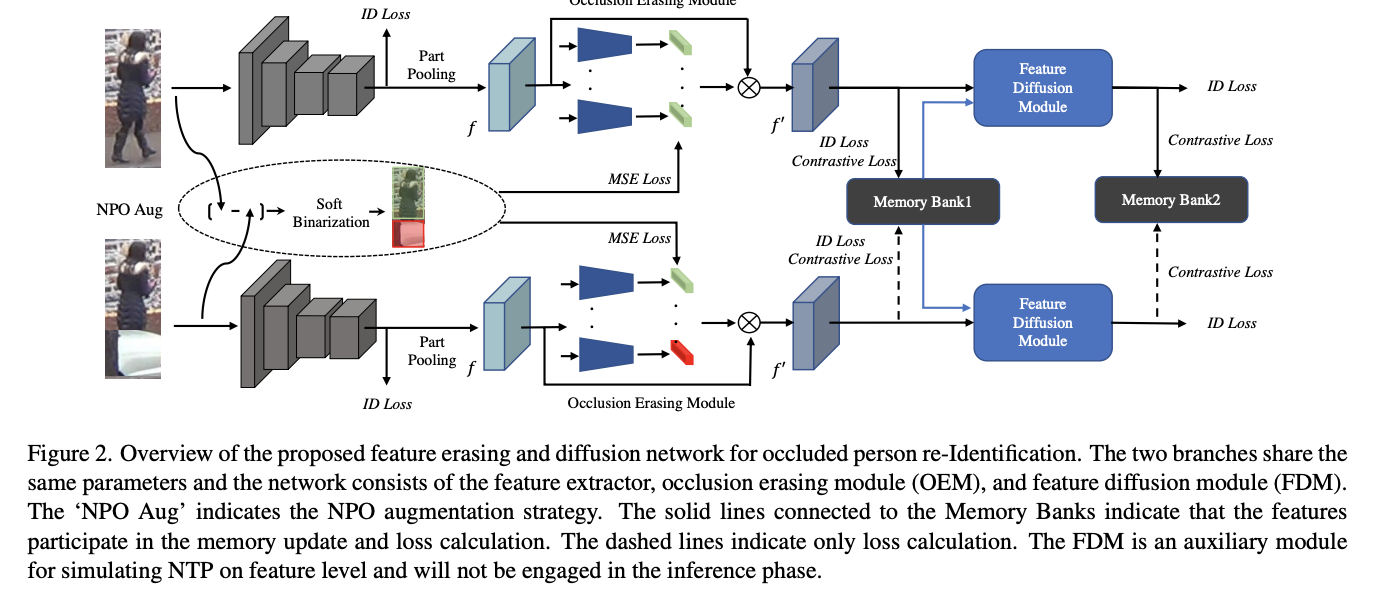
Feature Erasing and Diffusion Network for Occluded Person Re-Identification
キーワード: Supervised Learning Image-based Reid
概要
- Occluded Person ReIDは、異なるカメラビューにおいて、重なりが発生した人物画像を全体的な画像にマッチングさせることを目的としている
- 対象歩行者は通常、歩行者以外とのオクルージョン(Non-Pedestrian Occlusions: NPO)や他歩行者(Non-Target Pedestrians: NTP)とのオクルージョン(= 物体間の重なり)が発生する
- 従来の手法では、NTPによる特徴量の損失を無視し、NPOに対するモデルの頑健性を高めることに主に焦点が当てられている
- この論文では、NPOとNTPを同時に扱う手法、Feature Erasing and Diffusion Network (FED) を提案
- 歩行者画像上でNPOをシミュレートし、正確なオクルージョンマスクを生成するNPO補強戦略を用いて、提案するOcclusion Erasing Module(OEM)によりNPO特徴を除去
- 次に、学習可能な交差注意メカニズムを通して、新しい特徴拡散モジュール(FDM)により、歩行者表現を他の記憶された特徴と拡散し、特徴空間にNTP特徴を合成
- OEMによるオクルージョンスコアのガイダンスにより、特徴拡散処理は主に可視の身体部分に対して行われ、合成されるNTP特性の品質が保証
- 提案するFEDネットワークにおいて、OEMとFDMを共同で最適化することで、モデルのTPに対する知覚能力を大幅に向上させ、NPOやNTPの影響を緩和することができます
- さらに、提案するFDMは学習のための補助モジュールとしてのみ機能し、推論段階では破棄されるため、推論計算のオーバーヘッドがほとんど発生しません
- occluded and holistic person ReIDベンチマークを用いた実験により、FEDの優位性が示される
- Occluded REIDにおいてFEDは86.3%のランク1精度を達成し、少なくとも4.7%の差をつけて他を圧倒している。
手法のアーキテクチャ
-
下記画像は、occlusionが発生した画像例↓
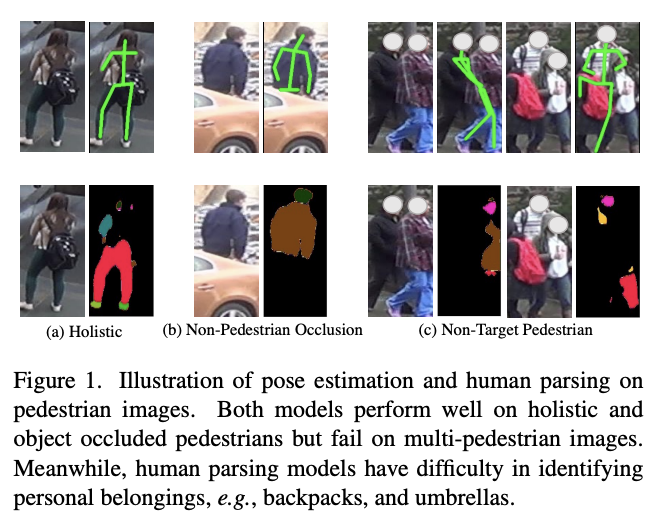
-
提案手法の概要図
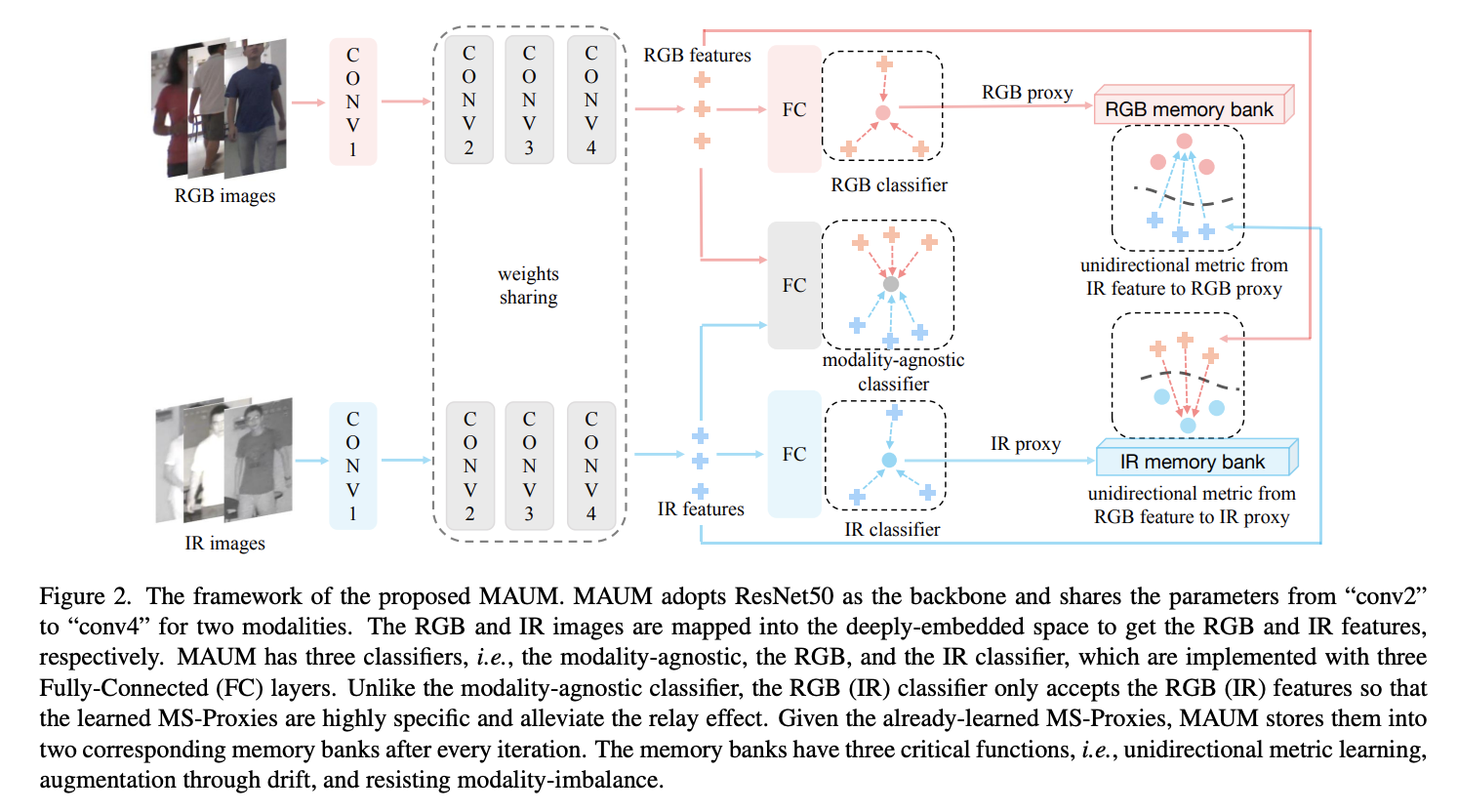
Learning Memory-Augmented Unidirectional Metrics for Cross-Modality Person Re-Identification
キーワード: Supervised Learning Visible-Infrared Reid
概要
- この論文では,モダリティの不一致を抑制ることで、VI-ReIDに取り組む
- クロスモダリティ再識別では、クエリ画像とギャラリー画像は異なるモダリティである
- 訓練用IDが与えられると、一般的な深層分類ベースラインは2つのモダリティに対して、最終Layer(分類層)の重みが共有される
- 共有された最終Layerが2つのモダリティ間の中間リレーとして機能するため、モダリティギャップに対してかなりの耐性がある
- この論文では、"unidirectional metrics" と "memory-based augmentation" という2つの新しいアルゴリズムからなる Memory-Augmented Unidirectional Metric(MAUM) learning methodを提案
- MAUMはまず、モダリティに特化したプロキシ(MS-Proxies)を各モダリティの下で独立して学習
- その後、MAUMは既に学習したMS-Proxiesを静的参照として、対象のモダリティの特徴量を引き出すために使用
- これら2つのunidirectional metrics(IR画像→RGBプロキシ、RGB画像→IRプロキシ)により、リレー効果を緩和し、クロスモダリティの関連付けを実現
- さらに、MS-Proxyをメモリバンクに格納し、参照の多様性を高めることで、クロスモダリティの関連付けを強化
- 重要なことは、MAUMがモダリティバランスのとれた設定において、クロスモダリティreidを改善し、モダリティ不均衡問題に対する堅牢性を獲得できる
- SYSU-MM01とRegDBデータセットでの広範な実験により、MAUMがSOATを達成
- コードは別途公開予定
手法のアーキテクチャ
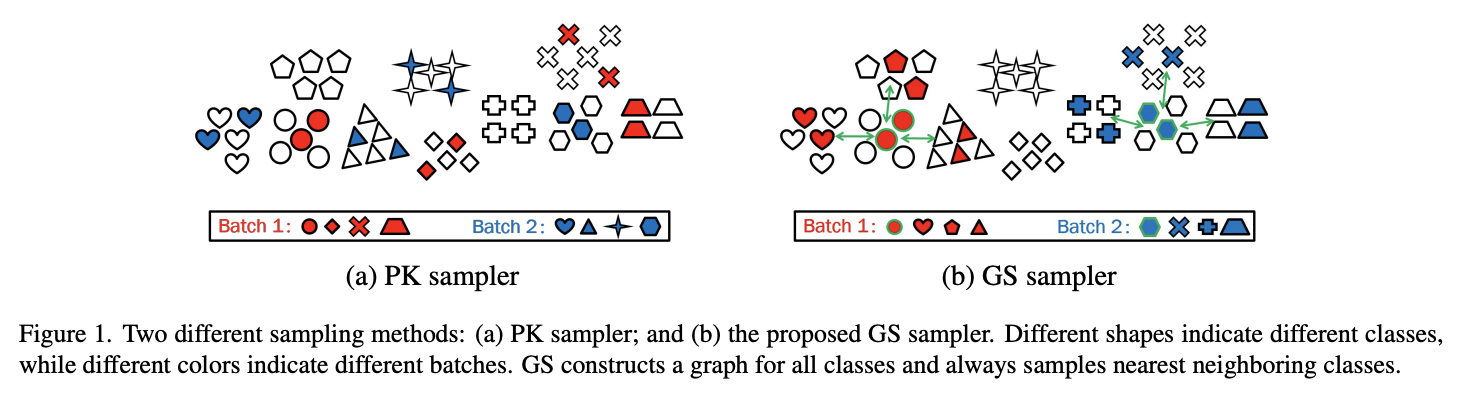
Graph Sampling Based Deep Metric Learning for Generalizable Person Re-Identification
キーワード: Data Sampling
概要
- 近年の研究により、明示的な深層特徴量照合と大規模かつ多様な学習データの両方が、reidの汎化性能を大幅に向上させることがわかっている
- しかし、大規模データにおけるdeep matcherの学習効率については、まだ十分に研究されていない
- 分類パラメータやクラスメモリを用いた学習は一般的な方法であるものの、大きなメモリコストと計算コストが発生する
- これに対して、ミニバッチ内でのpairwise deep metric learning学習がより良い選択となると仮定
- 最も一般的なランダムサンプリング法であるよく知られたPK samplerは、Deep metric learningにとって情報量が少なく効率的とは言えない
- オンライン硬質例マイニングにより学習効率はある程度改善されたが、ランダムサンプリング後のミニバッチでのマイニングはまだ限定的である
- このことから、より早い段階 = データサンプリング段階でのマイニングを検討
- この論文では、大規模なdeep metric学習のために、Graph Sampling(GS)と呼ばれる効率的なミニバッチサンプリング手法を提案する
- 基本的な考え方は、各エポックの最初に全てのクラスについて最近傍関係グラフを構築することである
- そして、各ミニバッチはランダムに選択されたクラスとその最近傍クラスで構成され、学習のための有益かつ挑戦的な事例を提供
- RandPersonで学習した場合、MSMT17のRank-1で25.1%という大幅な改善を達成
- MSMT17で学習した場合、CUHK03-NPのRank-1で6.8%上回るなど、競合ベースラインを上回る性能を確認
- また、8,000 IDのRandPersonで学習させた場合、学習時間は25.4時間から2時間へと大幅に短縮されることが確認
手法のアーキテクチャ
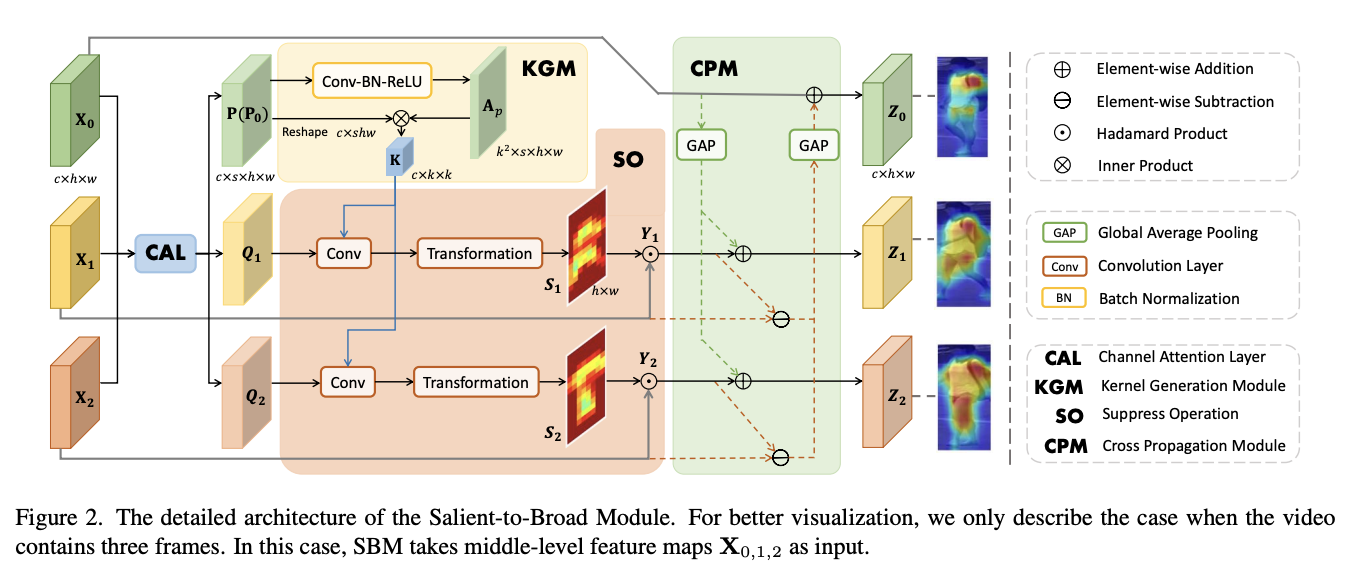
Salient-to-Broad Transition for Video Person Re-identification
キーワード: Supervised Learning Video-based Reid
概要
- 映像の時間的関係の利用が限定的であるため、主流の手法のフレームレベルの注目領域は部分的であり、類似性が高い
- この問題を解決するために、我々はAttention領域を徐々に拡大するSalient-to-Broad Module (SBM)を提案する
- SBMでは、前のフレームが最も顕著な領域に注目していたのに対して、後のフレームはより広い領域に注目する傾向がある
- このように、広い領域の追加情報が顕著な領域を補完することで、より強力な映像レベルの表現が可能となる。SBMをさらに改善するために、フレームレベルの表現を強化する統合・分散モジュール(IDM)が導入されている
- IDMは、まず特徴空間全体から特徴を統合し、統合された特徴を各空間位置に分配する
- SBMとIDMは、それぞれビデオレベル、フレームレベルの表現を強化するため、相互に有益である
- 4つの一般的なベンチマークを用いた広範な実験により、本手法の有効性と優位性を実証する
手法のアーキテクチャ
NFormer: Robust Person Re-identification with Neighbor Transformer
キーワード: Supervised Learning Image-based Reid
概要
- reidは、様々なカメラやシナリオで非常に多様な環境において人物を検索することを目的としており、そのためにはロバストで識別性の高い表現学習が重要である
- ほとんどの研究では、画像間の潜在的な相互作用を無視し、単一の画像から表現を学習することを検討している
- しかし、同一人物内のばらつきが大きいため、そのような相互作用を無視すると、典型的には異常値特徴量になる
- この問題に取り組むため、我々はNeighbor Transformer Network(NFormer)を提案する
- NFormerは全ての入力画像間の相互作用を明示的にモデル化し、外れ値の特徴を抑制し、全体としてより頑健な表現に導く
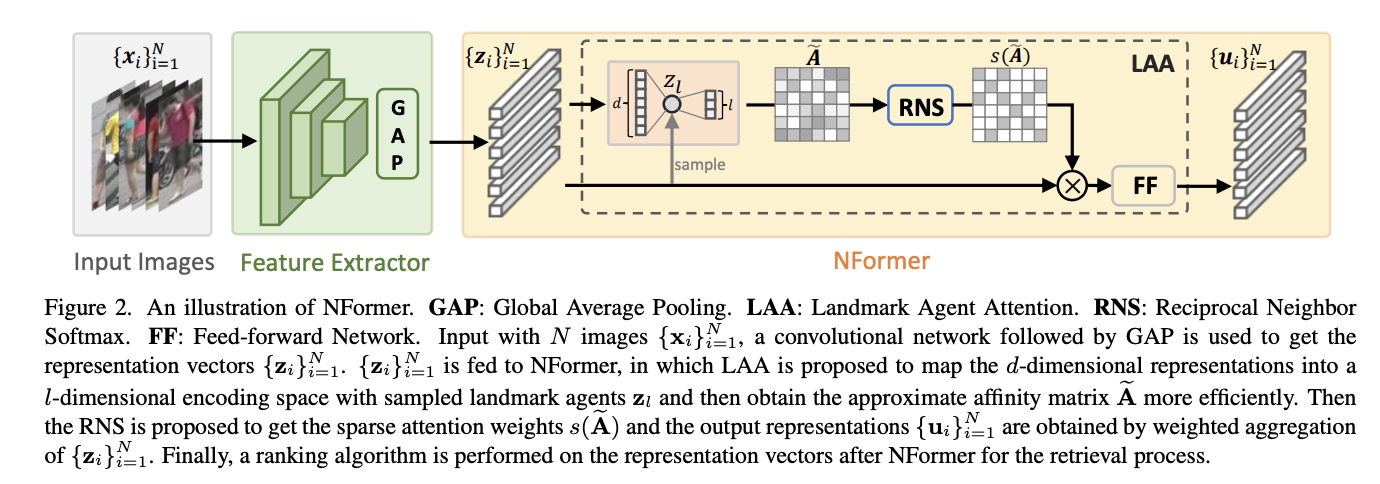
- NFormerは、膨大な量の画像間の相互作用をモデル化することは、多くのディストラクタを伴う大規模なタスクであるため、2つの新しいモジュール、Landmark Agent Attention と Reciprocal Neighbor Softmax を導入しています
- 具体的には、Landmark Agent Attentionは、特徴空間における少数のランドマークを用いた低ランク因子分解によって、画像間の関係写像を効率的にモデル化する
- また、Reciprocal Neighbor Softmaxは、関連性の高い(むしろ全てではない)近傍領域のみへの疎な注意を実現し、無関係な表現の干渉を緩和し、計算負荷をさらに軽減させる
- 4つの大規模データセットを用いた実験では、NFormerはSOTAを達成した。
手法のアーキテクチャ
Implicit Sample Extension for Unsupervised Person Re-Identification
キーワード: Unsupervised Learning Image-based Reid
概要
- 既存の教師なしreid手法のほとんどは、モデル学習のために擬似ラベルを生成するためにクラスタリングを使用
- クラスタリングは別のIDを同じクラスタに分類したり、同じIDを2つ以上のサブクラスタに分割したりすることが多々ある => classificationに比べてどうしても精度が低い
- 各IDのサンプル数が限られているため、正確なクラスタを明らかにするための情報が不足している可能性があります
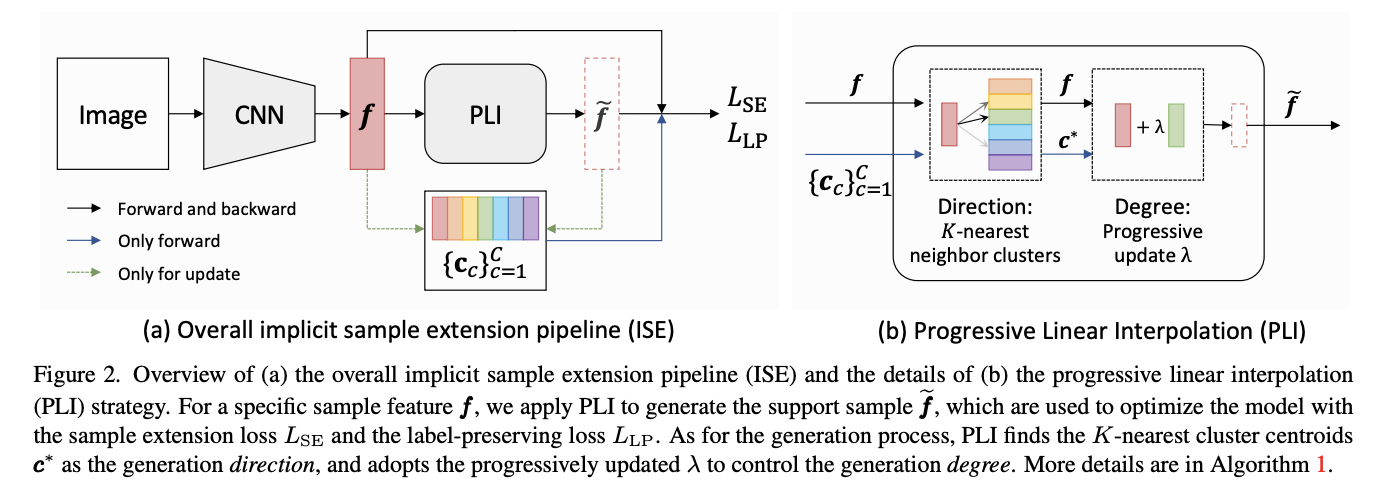
- そこで、クラスタ境界の周辺にサポートサンプルと呼ばれる情報を生成する暗黙的サンプル拡張法(Implicit Sample Extension, \OurWholeMethod)を提案
- 具体的には、埋め込み空間における実際のサンプルとその近傍のクラスタから、PLI(Progressive Linear Interpolation)戦略によってサポートサンプルを生成
- PLIは、1)実際のサンプルからK個の近傍クラスタに向かう方向、2)K個の近傍クラスタからの文脈情報の混合度、の2つの重要な要素で生成を制御
- 一方、サポートサンプルが与えられると、ISEはさらにラベル保存損失を用いて、対応する実際のサンプルに引き寄せ、各クラスタをコンパクトにする
- その結果、ISEは "sub and mixed "クラスタリングエラーを減らし、Re-IDの性能を向上させる
- 提案手法は教師なしreidにおいて有効であり、SOTAを達成
手法のアーキテクチャ

Cloth-Changing Person Re-identification from A Single Image with Gait Prediction and Regularization
キーワード: Supervised Learning Clothes-Changing Reid
概要
- Cloth-Changing person Reid(CC-ReID)は、数日間に渡って異なる場所で同一人物を照合することを目的としているため、必然的に衣服交換の問題に直面する
- この論文では、より困難な設定、すなわち1枚の画像からCC-ReID問題をうまく処理することに焦点を当て、リアルタイム監視アプリケーションにおいて高効率で遅延のない歩行者識別を可能にします
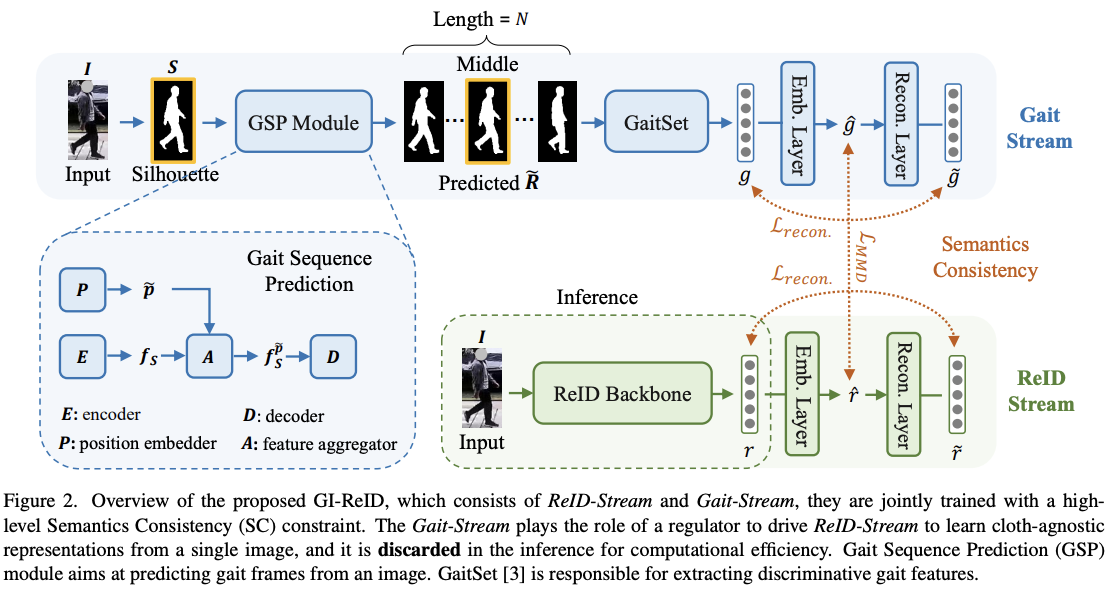
- 具体的には、歩行認識を補助タスクとして導入し、画像ReIDモデルを駆動して、個人固有の歩行情報を活用することで、布に依存しない表現を学習します
- GI-ReIDは、画像ReIDストリームと補助的な歩行認識ストリーム(Gait-Stream)の2つのストリームから構成されるアーキテクチャを採用しています
- Gait-Streamは計算効率を上げるために推論時に破棄され、学習時にReID-Streamが衣服に依存しない生体運動特徴を捉えるように促す調整役として機能
- また、1枚の画像から時間的に連続した運動情報を得るために、Gait-StreamのためのGait Sequence Prediction (GSP) モジュールを設計し、歩行情報を充実させる
- 最後に、知識の正則化を効果的に行うために、2つのストリームに対する高レベルのセマンティクスの一貫性を強制する
- GI-ReIDは、LTCC、PRCC、Real28、VC-Clothesなどの複数の画像ベースのClothes-Changing Reidベンチマークで実験し、現状にSOTAに近い性能を示した
手法のアーキテクチャ
Learning Modal-Invariant and Temporal-Memory for Video-Based Visible-Infrared Person Re-Identification
キーワード: Supervised Learning Visible-Infrared Reid Video-based Reid
概要
- cross-modal person Re-idの検索技術により、可視-赤外(RGB-IR)環境の人物を共通の空間に投影することでreidを実現し、24時間監視システムにおけるreidを可能にしている
- しかし、既存のRGB-IRベースのクロスモーダルreid手法のほとんどは、画像間のマッチングに焦点を当てており、より豊富な空間・時間情報を含むビデオ間のマッチングは未解決のままである
- 本論文では、映像に基づくクロスモーダル人物再認識法について主に研究する。このデータセットには、12台のRGB/IRカメラで撮影された463,259フレームと21,863トラックレットを含む927個の有効なIDが格納されている
- 構築したデータセットに基づき、トラックレット内のフレーム数が増加するにつれて、性能が向上することを証明し、RGB-IR reid における映像間マッチングの重要性を示す
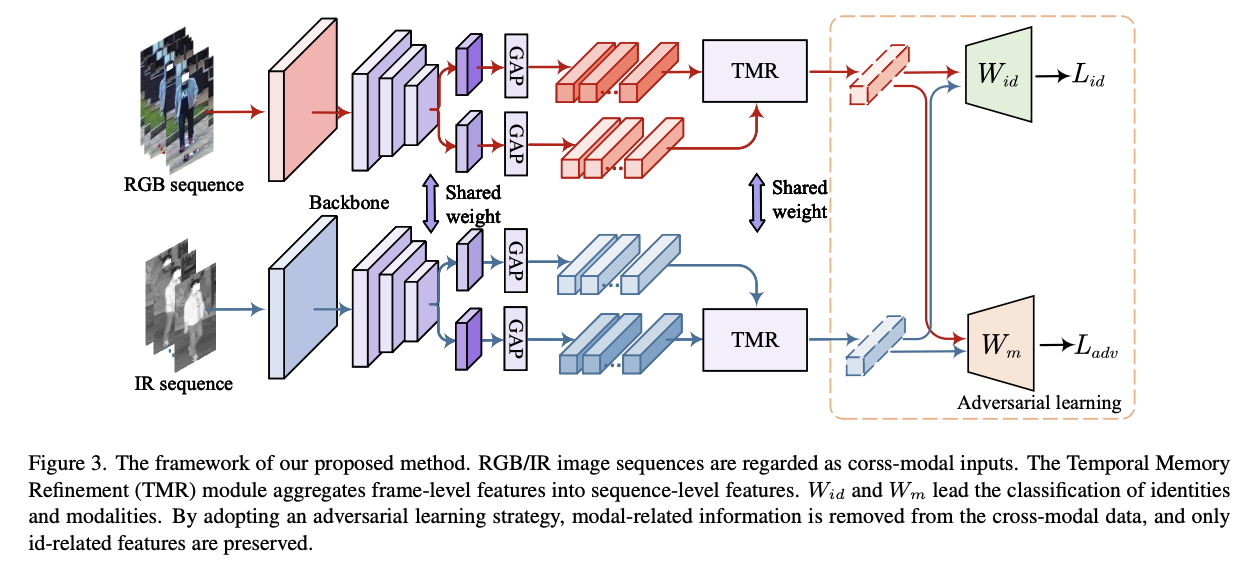
- さらに、2つのモダリティをモード不変部分空間に射影するだけでなく、運動不変の時間記憶を抽出する新しい方法を提案する
- この2つの手法により、動画像に基づくクロスモーダルな人物再認識において、より優れた結果を得ることができる
手法のアーキテクチャ
-
TMRの中の構造↓
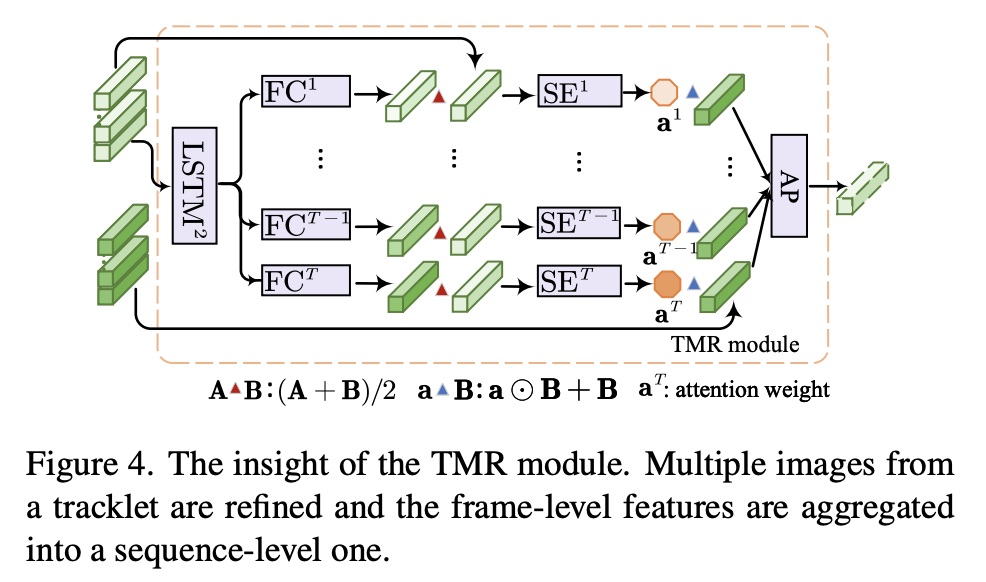
-
adversarial learningの構造(3パターン)↓
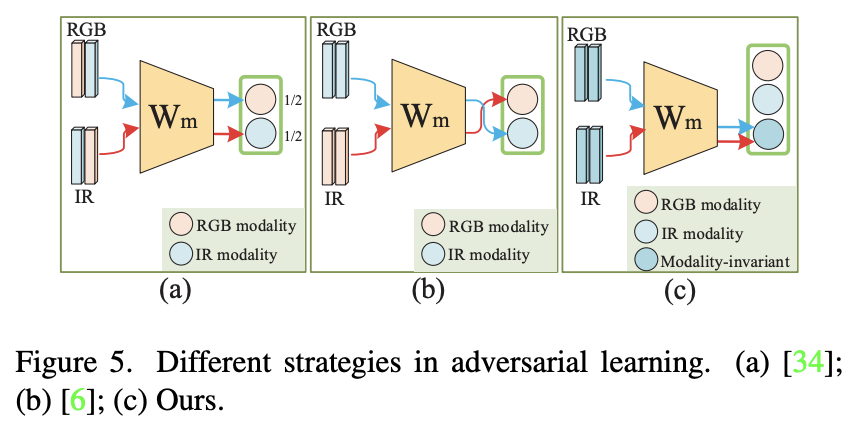
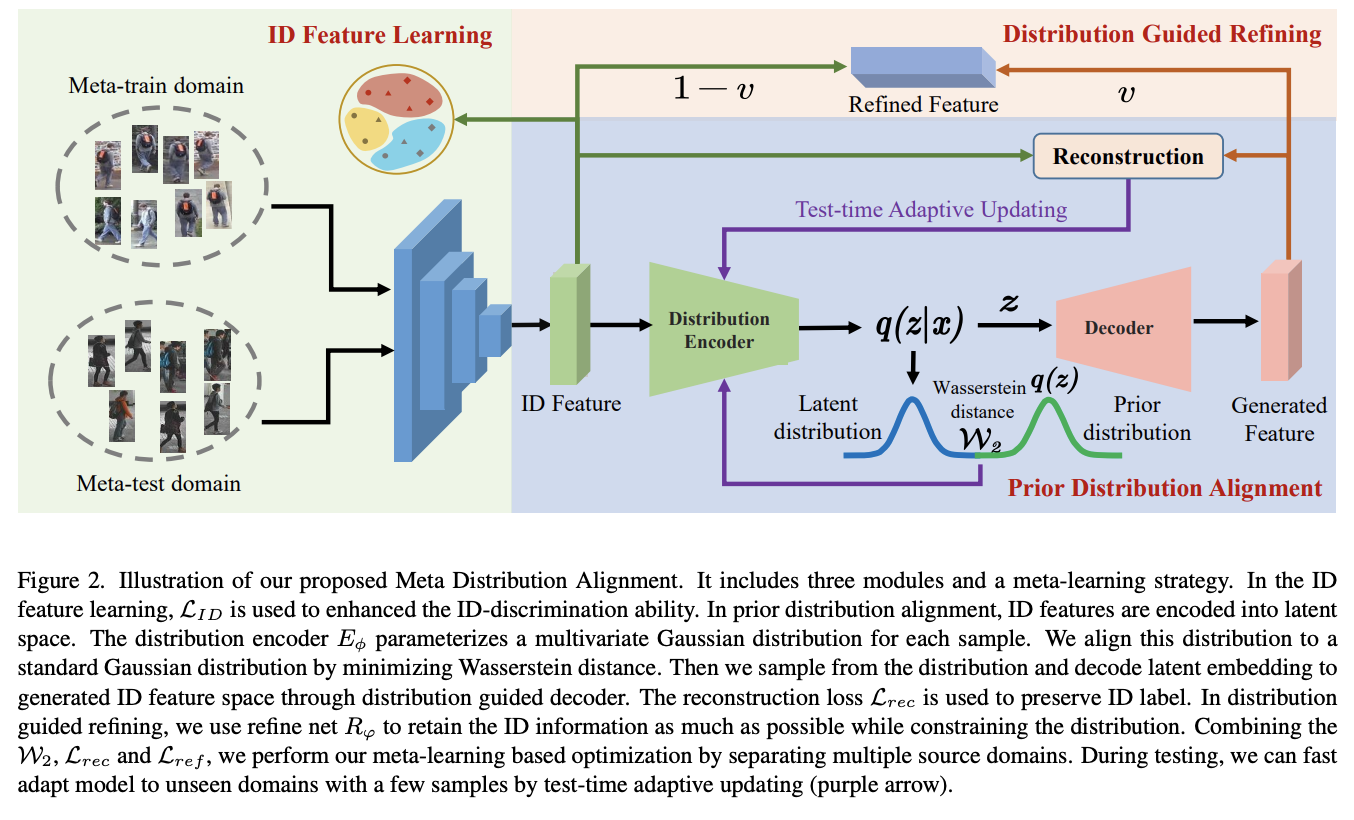
Meta Distribution Alignment for Generalizable Person Re-Identification
キーワード: Supervised Learning Image-based Reid
概要
- Domain Generalizable Person ReID(DG)は、ソースドメインでモデルを学習しつつ、ターゲットドメインでうまく汎化する難しいタスクである
- 既存の手法は、ソースドメインを用いてドメイン不変な特徴を学習し、その特徴がターゲットドメインとも無関係であると仮定している
- しかし、DGの学習フレーズでは利用できないターゲットドメインの情報は考慮されていない
- この問題を解決するために、我々は、テスト時間-学習時間において、類似した分布を共有することを可能にする新しいメタ分布アライメント(MDA)手法を提案する
- 具体的には、高次元特徴は既知の単純な分布で制約することが困難であるため、まず既知の事前分布で制約された中間的な潜在的空間を導入する
- 汎化を促進し、高速な適応をサポートするために、メタ学習戦略を導入する
- さらに、両者の矛盾を減らすために、潜在空間に基づくテスト時適応更新戦略を提案し、少数のサンプルで未知のドメインにモデルを効率的に適応させる。
- 我々のモデルは大規模ドメイン汎化ベンチマークReIDにおいて平均5.1%R-1、単一ソースドメイン汎化ベンチマークにおいて平均4.7%R-1と、最先端手法を凌駕することが示された。
手法のアーキテクチャ

Camera-Conditioned Stable Feature Generation for Isolated Camera Supervised Person Re-IDentification
キーワード: Supervised Learning Image-based Reid ISolated Camera Supervised
概要
- Re-IDのためのカメラビューが不変な特徴を学習するためには、各人物のカメラ間画像ペアが重要な役割を果たす
- しかし、遠隔地に設置された監視システムのようなISolated Camera Supervised (ISCS) 設定では、このようなクロスビューの学習サンプルが利用できない可能性がある
- この論文では、モデル学習のための特徴空間におけるクロスカメラサンプルを合成する新しいパイプライン、Camera-Conditioned Stable Feature Generation (CCSFG)を提案
- EncoderとGeneratorをend2endで最適化
- CCSFGでは、EncoderとGeneratorを組み合わせて学習させるため、生成モデル学習の安定性が懸念
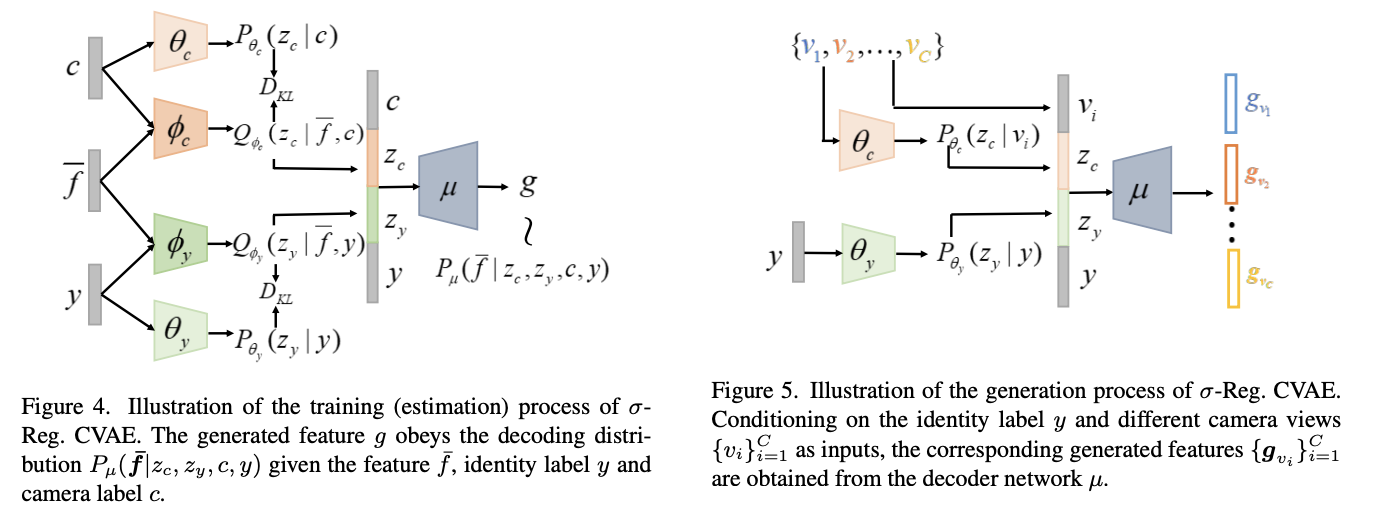
- そこで、Generatorとしてσ-Regularized Conditional Variational Autoencoder (σ-Reg.~CVAE)を提案
- 2つのISCS person Re-IDデータセットに対する広範な実験により、我々のCCSFGが競合他社より優れていることを実証する。
手法のアーキテクチャ
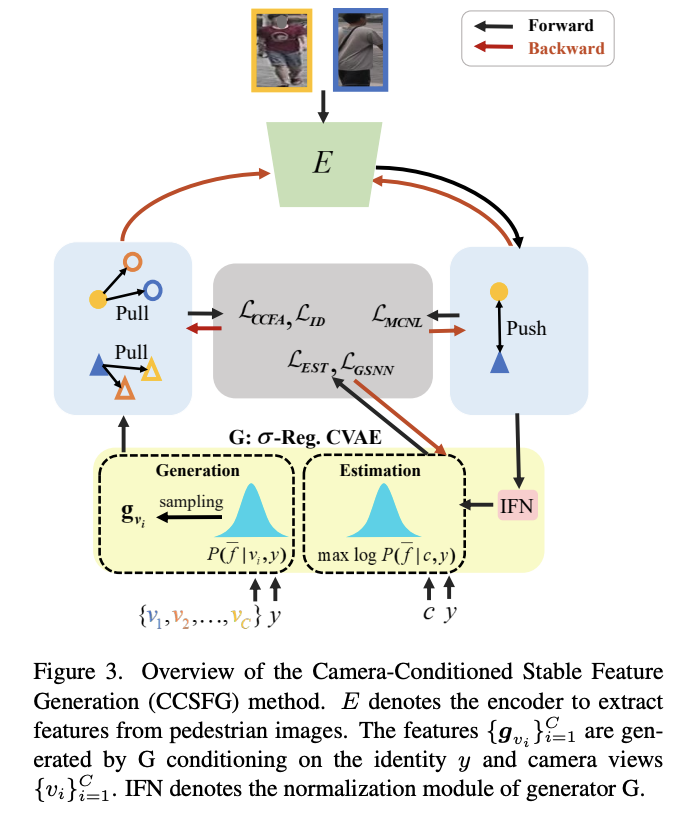
-
上図のGeneration(左)、Estimation(右)の中身↓
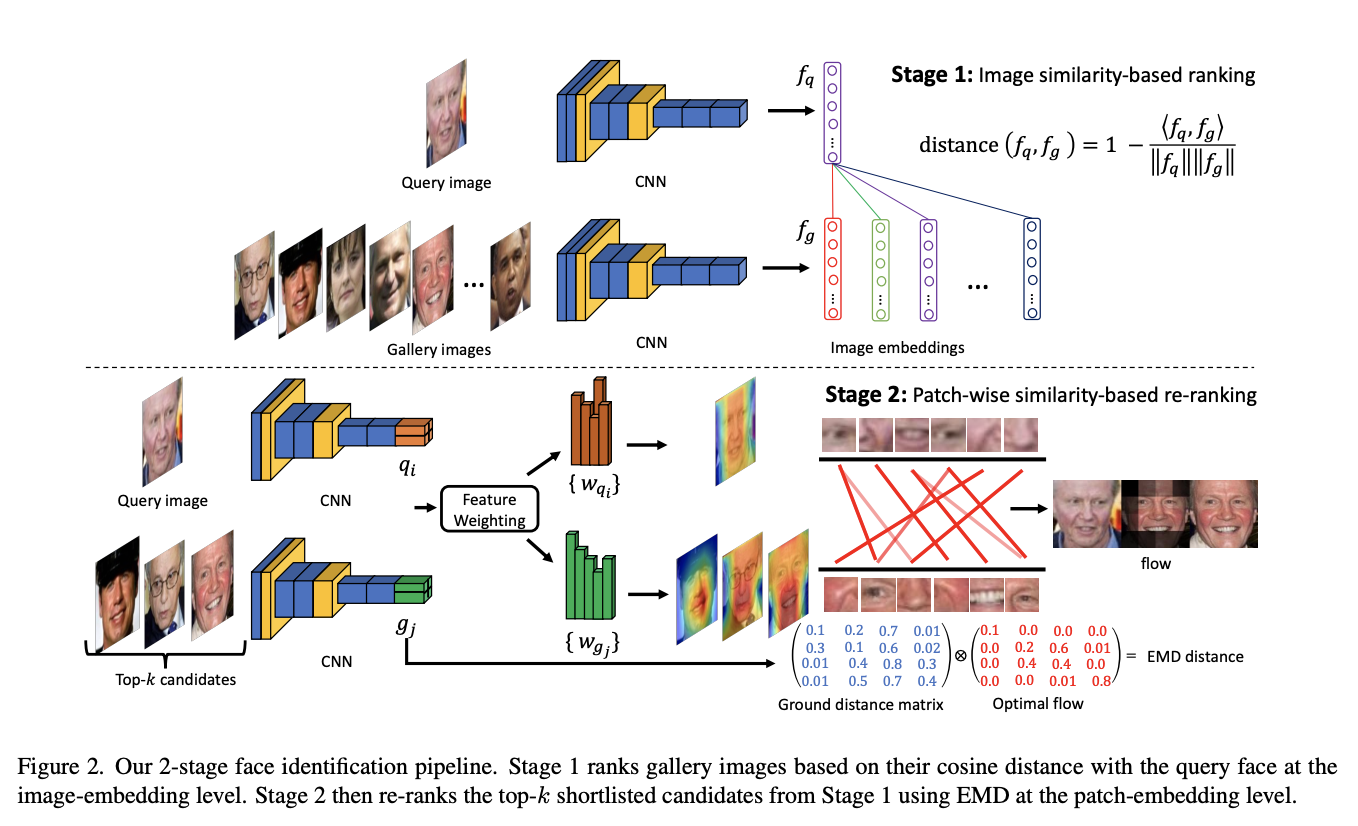
DeepFace-EMD: Re-ranking Using Patch-wise Earth Mover’s Distance Improves Out-Of-Distribution Face Identification
キーワード: Supervised Learning Face Recognition
概要
- Arcfaceなどでは、2つの画像の画像埋め込み間のコサイン類似度を取ることによって2つの画像を比較する
- しかし、このようなアプローチは、学習セットやギャラリーに含まれていない新しいタイプの画像(例えば、クエリの顔がマスクされたり、切り取られたり、回転されたりした場合)に対する分布外(OOD)一般化の低さに悩まされている
- ここでは、画像パッチの深い空間的特徴に関するEarth Mover's Distanceを用いて2つの顔を比較する再順位付けのアプローチを提案
- 画像の類似性を顔の細かいパーツ(例えば、目と目の間)毎に比較し、従来のFace-reidよりも新規の顔画像やocclusionsに対してより頑健になる
- 興味深いことに、特徴抽出器を微調整することなく、我々の手法は、テストした全ての新規の顔画像クエリ(マスクされた画像、切り取られた画像、回転した画像、敵対的な画像)で一貫して精度を向上させ、配布中の画像では同様の結果を得ることができた。
手法のアーキテクチャ
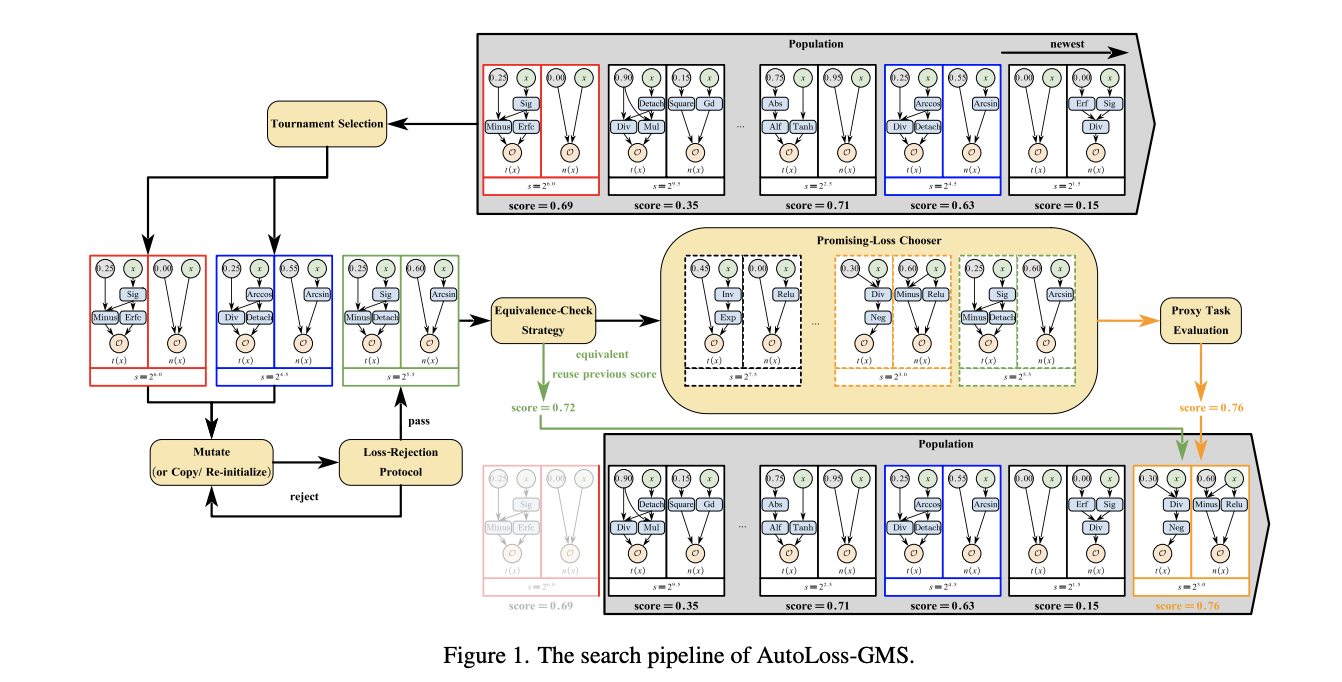
AutoLoss-GMS: Searching Generalized Margin-Based Softmax Loss Function for Person Re-Identification
キーワード: Loss Function Image-based Reid
概要
- 既存のreidモデルの多くは、手作業で作成された損失関数を利用しており、通常、最適とは言えず、設計も困難
- この論文では、reidのための一般化マージンベースのSoftMax関数の空間において、より良い損失関数を自動的に探索する新しい手法、AutoLoss-GMSを提案
- 具体的には、まず、一般化マージンベースのSoftMax関数を2つの計算グラフと定数に分解
- そして、損失関数を効率的に探索するために、進化的アルゴリズムに基づく一般的な探索フレームワークを提案
- 計算グラフはfeedforwardで構築され、既存の研究で用いられているbackwardよりもはるかに豊富な損失関数形式を構築す
- 基本的なグラフ内に対するノイズに加え、グラフ間に対するノイズを考案し、tree構造の多様性をさらに向上
- また、探索効率を向上させるために、損失拒絶プロトコル、等価性チェック戦略、予測器ベースの有用な損失関数の推論モデルを開発
- 実験結果により、探索された損失関数がSOTAを達成し、reidにおける異なるモデルやデータセット間で移植可能であることを検証
手法のアーキテクチャ
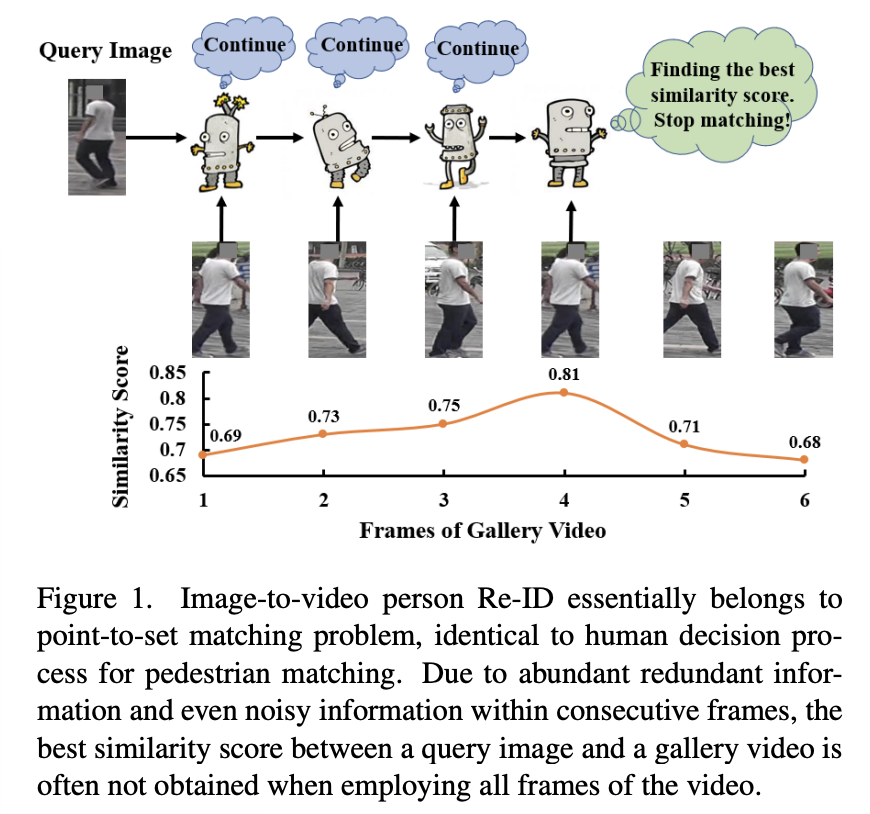
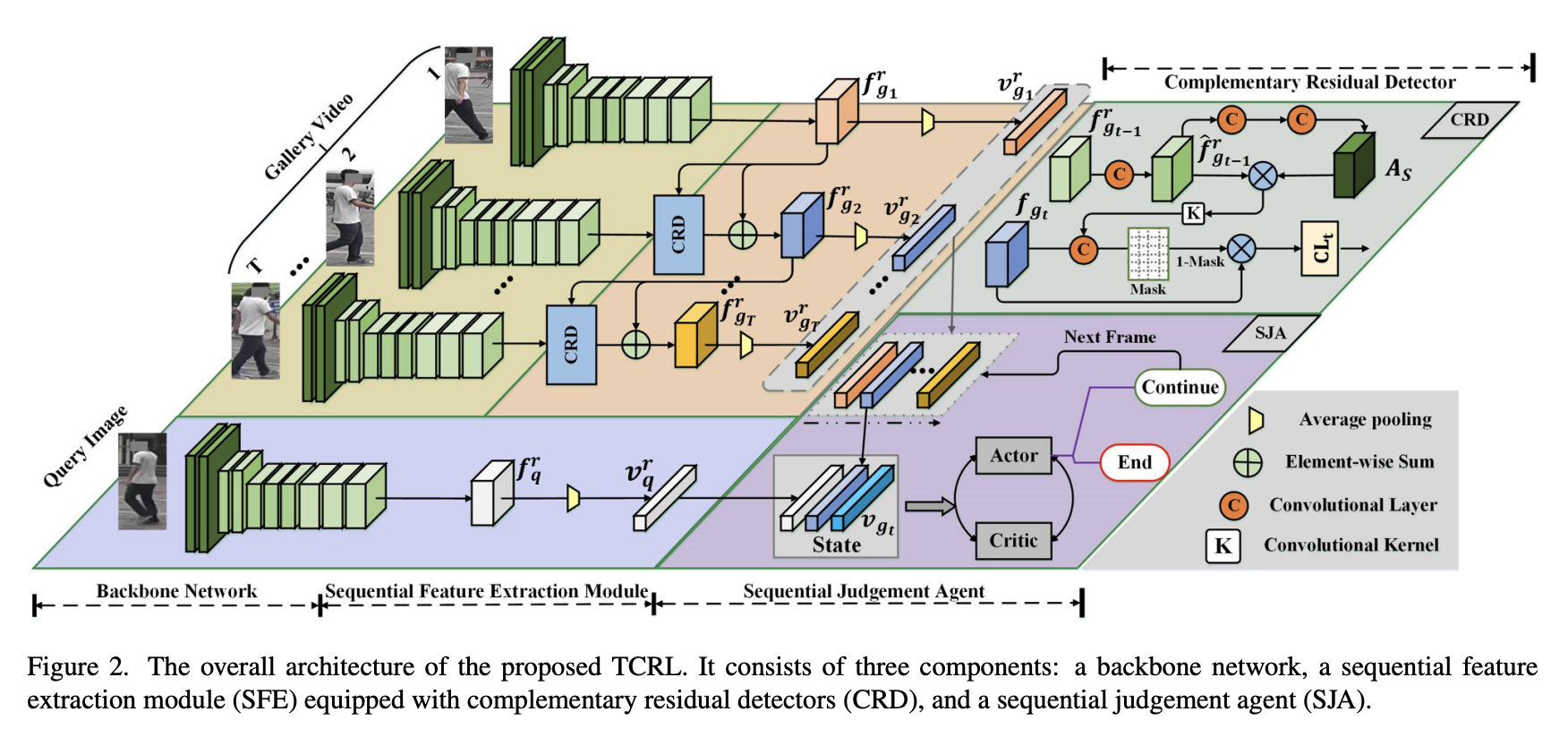
Temporal Complementarity-Guided Reinforcement Learning for Image-to-Video Person Re-Identification
キーワード: Supervised Learning Video-based Reid Image-based Reid
概要
- 画像から動画へのreidは、動画ベースのギャラリー集合から画像ベースのクエリと同じ歩行者を検索することを目的としている。既存の手法は、このタスクをクロスモダリティ検索タスクとして扱い、画像とビデオのモダリティから共通の潜在的埋め込みを学習するが、モダリティギャップが大きく、全てのビデオフレームを利用することによる冗長な特徴学習により、効果・効率ともに低い
- 本研究では、まず、このタスクを人間の意思決定プロセスと同じ点と点のマッチング問題とみなし、画像から動画へのreidのための新しい時間的相補性ガイド強化学習(TCRL)アプローチを提案
- TCRLは、効率と精度を両立させるために、深層強化学習を用い、ギャラリー映像から適切な量のフレームを動的に選択して逐次判定を行い、クエリ画像の誘導によってこれらのフレーム間の時間的補完情報を適切に蓄積
- 具体的には、TCRLはポイント・トゥ・セットのマッチング手順をマルコフ決定過程として定式化し、逐次判定エージェントが各時間ステップでクエリ画像と全ての履歴フレームの間の不確実性を測定
- 判定に十分な補完的手がかりが蓄積されているか(同一または異なる)、判定支援のためにさらに1フレーム要求することを確認
- さらに、TCRLは補完残差検出器を備えた逐次特徴抽出モジュールを保持し、冗長な顕著領域を動的に抑制し、選択されたフレーム間の多様な補完手がかりを徹底的にマイニングしてフレームレベル表現を強化
- 本手法が優れていることは、広範な実験により実証されている。
手法のアーキテクチャ