はじめに
この記事は、AMBL株式会社 Advent Calendar 2022の22日目の記事になります。是非、他の記事も読んで見て下さい〜![]()
今年の頭に、SimCSEという対照学習(Contrastive Learning)を用いた教師なし学習によるText Embeddingの手法が少し話題になっていました。
今回まとめる論文は、対照学習を用いたSentence Embeddin ModelであるDiffCSEという言語モデルです。
個人的には結構面白かった論文なので、振り返りも含めてまとめ記事書いていこうかなと思います。
論文情報
- タイトル:DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings
- 学会:NAACL
- 発表年:2022
- URL:https://arxiv.org/abs/2204.10298
一言説明
- SimCSEの派生モデル。原文と編集後の文の差分に敏感になるように、教師なし対照学習モデルを作成
- STS(Semantic Textual Similarity)タスクにて、教師なし学習modelの中でSOTA(2022年4月時点)を達成
先行研究との比較
最近は、下記のような対照学習を用いたSentence embeddingsが多く研究されています。
対照学習では、入力データにどのようなaugmentationをするかが重要であり、
下記のような先行研究が挙げられている。
-
CV領域の先行研究
-
SimCLR
- 入力画像と意味的に近い画像を作成し、そのデータを正例、それ以外を負例
-
SimCLR
-
CVのaugmentation
- RandomResizedCrop(画像内の一部分ランダムで抜粋し、元のサイズにリサイズ)
- ColoJitter(色相、明度などの変換)
- Rotate (画像の回転)
-
NLP領域の先行研究
加えて、先行研究の中で、対照学習にとっては「有害」なaugmentationも挙げられている
- SimCLR
- Rotateによるaugmentationを用いた場合、ImageNetの線形探索精度が低下
- SimCSE
- 単語の15%を置換するMLMを用いた場合、STSタスクの性能が低下
対照学習における学習目的は、入力に対して意味が不変な表現を作るaugmentationを行うことであるが、入力に対する直接的な変換(例えば、削除、置換)は文の意味を変えてしまうため、精度悪化の要因になってしまう。
先行研究の多くは、上記のような「有害」なaugmentationは、学習過程から省かれている。しかし、DiffCSEでは、この「有害」なaugmentation(= MLMを用いた単語置換による文生成)も学習に利用するべきである、と主張。
実際に、E-SSLの研究では、有害なaugmentationを、下記図のような形式で利用することで、精度向上を確認されています。
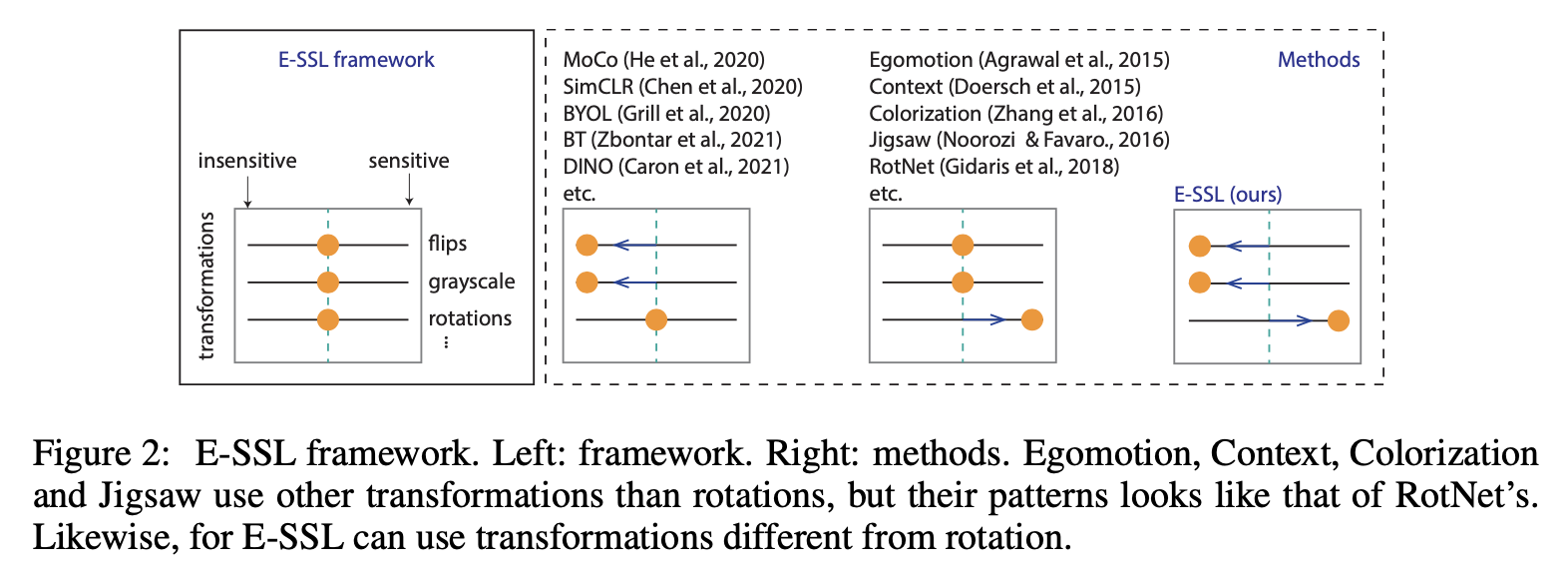
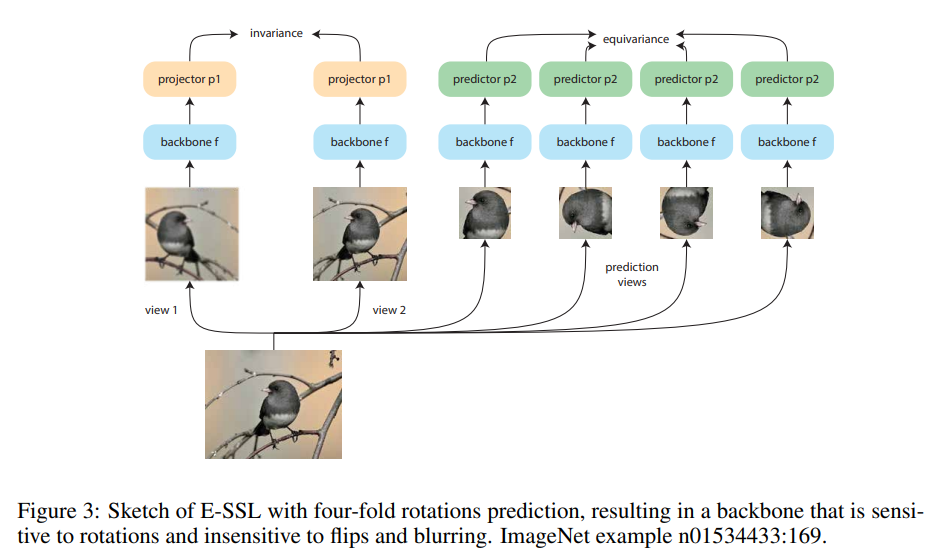
- sensitive ... augmentationによる意味に変化に敏感な場合
- insensitive... augmentationによる意味に変化に鈍感な場合
上記の手法をNLPドメインにも拡張したモデルが、今回の「DiffCSE」になります。
*教師なしSimCSEは上記の図で言うところ、入力文の文埋め込みベクトルをよりinsensitiveになるように学習する
技術や手法のキモ
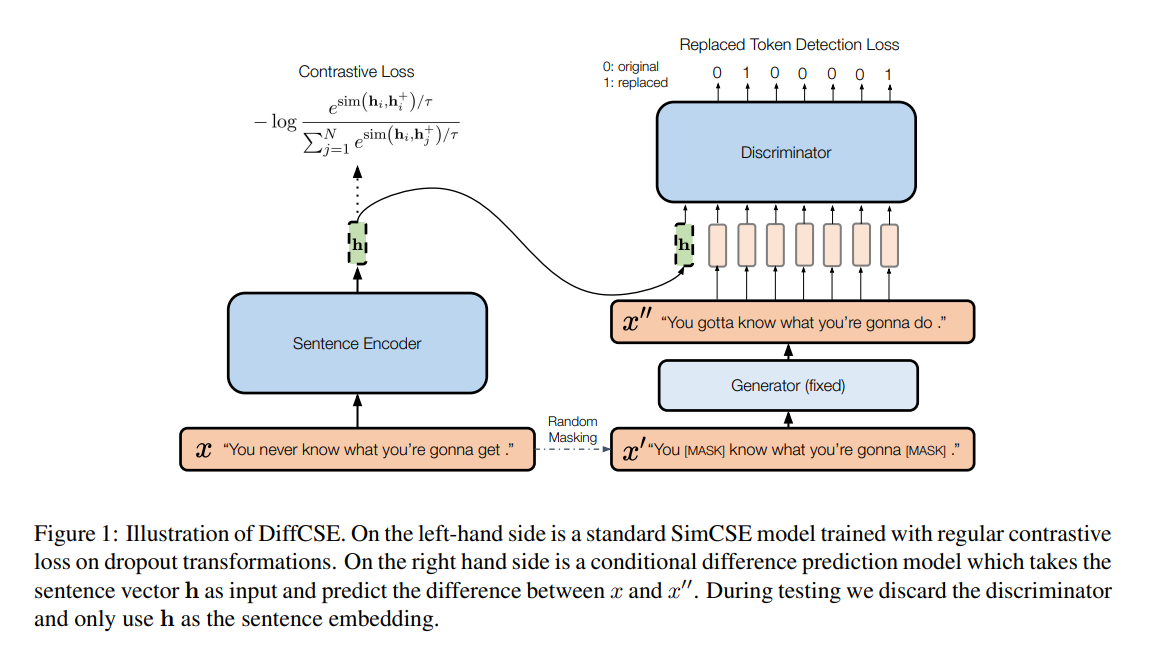
下記図は、DiffCSEの概要になります。
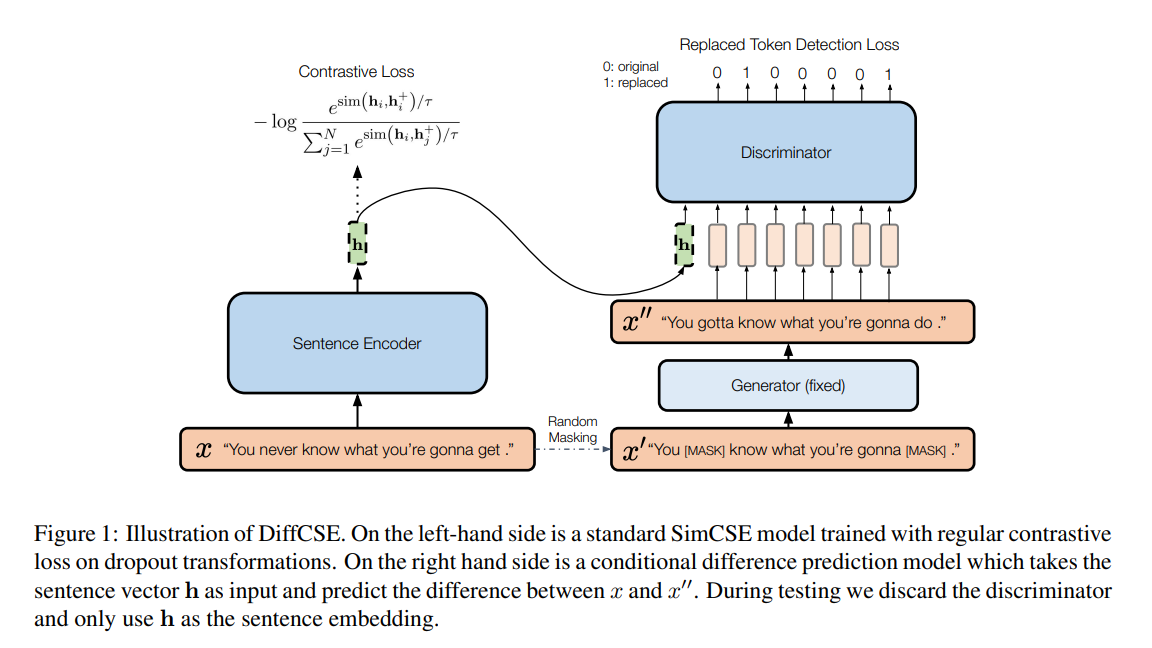
図の左側は先行研究となるSimCSEの構成になります。
ラベル無しの入力分xに対して、dropout maskを用いた意味類似度の高い文を生成し、対照学習を行います。
そして図の右側が、MLMを用いたaugmentationによって得られた文(= 編集文)が入力文(= 原文)の差分を学習する機構です。
構造としては、ELECTRAで使われている学習構造の条件付きバージョンになります。
ELECTRAとの違いとしては、識別器側の入力に原文の埋め込みベクトルが入力されていることです。
これにより識別器の学習勾配をencoder側に逆伝搬させる事ができ、識別器側で原文と編集文の埋め込みベクトルの差分を学習する事ができます。
上記の構成によって、DiffCSEの目的関数は以下のようになります。

実験
-
学習データ
- 事前学習にはSimCSEで提供されているWikipediaデータからランダムに取得した106文のデータ
-
DiffCSEで使用するモデル
- Sentence Encoder: Bert, RoBerta
- Generator: DistilBERT, DistilRoBERTa
- Discriminator: Bert, RoBerta
- (学習時には、Generatorは固定)
-
対象となる評価タスク
- SentEvalで設定された7個のSTSタスク(=> 全て教師なし学習で実験)
- SentEvalから選定した7つ下流タスク(=> EncoderはSTSタスクで学習したモデルで固定)
- テキスト分類問題を埋め込みベクトルを入力としたロジスティック回帰を使用して評価
-
STSタスクの結果
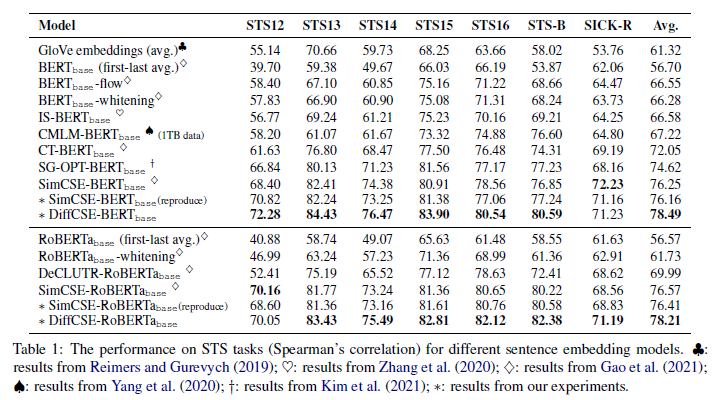
- BERTベース、RoBERTaベース共に、DiffCSEが平均スコアにて最高精度を達成
- SimCSEに比べて、BERTベースで+2.2%、RoBERTaベースで+1.2%の向上
-
Down streamタスクの結果
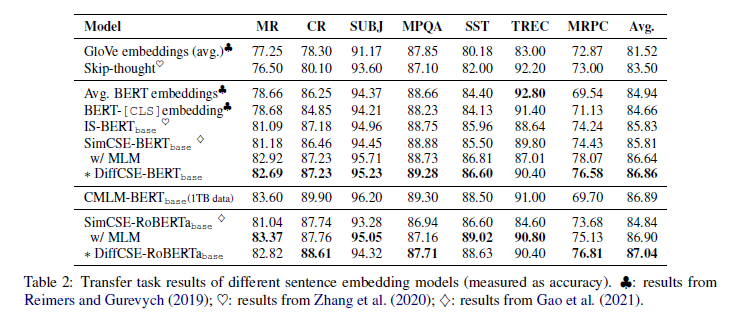
- BERTベースでは、SimCSEと比べて平均スコアを+1.3%向上
- RoBERTaベースでは、平均スコアを+2.2%向上
- CMLM-BERTbaseがDiffCSEよりも高い性能を示している。しかし、CMLM-BERTbaseでは1TBの学習データを使用しているのに対し、我々のモデルは115MBの学習データで上記の精度を達成
- SimCSEでは、下流タスクのfinetuningを行う際にMLMを使用することで精度が向上する。その場合のSimCSEの精度と比較すると+0.2%とあまり差はない
-
類似文検索の検証

- SimCSEでは単語の出現位置など、表現が近い文のスコアが高くなりがちなのに比べ、DiffCSEでは表現が似ていない文でも、意味類似度を高い文を検索できている
- 二重否定はまだ難しい
読んだ所感
- CV領域とNLP領域での対照学習の研究を比較して、アイデアを得る過程が詳細に述べられていて、研究背景が理解しやすい
- DiffCSEも学習構造自体がとてもシンプル。これまでは使用できなかったaugumentationも使えるようになったなったていうのは嬉しい
- 論文内の類似文検索の結果を見る限り、確かにより正確に文の意味を把握できている用に見える(他のパターンを色々みたいところではあるが、、)