はじめに
この記事は、AMBL株式会社 Advent Calendar 2022の9日目の記事になります。是非、他の記事も読んで見て下さい〜![]()
2022年11月末に話題になった「chatGPT」についての記事を、カレンダーの8日目に記載しましたが、その中で特に計算問題なんかの思考過程の出力に筆者は感動ております![]()
こういった思考の過程も生成できるように学習する手法として、「Chain of Thought Prompting」が有名です。chatGPTのロジックにも組み込まれています・
この記事では、2022年1月に発表された「Chain of Thought Promptin」という学習手法についてまとめています。
忙しい方向けの3行要約
- 何らかしらの問いに対する答えを出す際の 「思考過程」 を学習させることができたよ
- 特に、「数学の文章問題を解く」ようなタスクの際に品質の向上が確認できたよ
- ただ、ある程度の大規模言語モデル(60Bくらいのパラメータ数)でないと、Chain of Thoughtの効果はあまり実感できなさそう
本編
この記事では、論文の流れに沿って個人的に重要だと思った部分のみ抜粋してまとめていきます。
まとめ方としては、
- 先行研究の課題、問題提起
- 提案手法の概要
- 実験結果 (ここ今執筆中です!!)
- まとめ、今後の展望
の順に論文の内容をまとめていこうと思います。理解しきれなかった部分に関しては、論文の本文抜粋だけしつつ、内容の説明は随時追記していきます。
基本的には、自分の理解のメモ書き、という認識なので読みやすさはあまり考慮しておりません。
先行研究の課題
この研究において解決したい課題は、実際の論文内で以下のように記載されています。
Scaling up the size of language models has been shown to confer a range of benefits, such as improved performance and sample efficiency (Kaplan et al., 2020; Brown et al., 2020, inter alia).
However, scaling up model size alone has not proved sufficient for achieving high performance on challenging tasks such as arithmetic, commonsense, and symbolic reasoning (Raeet al., 2021).
言語モデルのサイズとその性能には比例関係があることが有名です。モデルのパラメータ数を増やし、サイズを大きくすることでモデルの表現能力が向上する、ということは Kaplanら、Brownらの研究で明らかになっています。
しかし、計算問題や常識問題など、単語の意味理解とは別に「推論」という思考過程が必要なタスクを解くためには、モデルサイズを大きくするだけでは不十分である、ということがRaeetらの論文で述べられています。
なので、この論文では、「現状の言語モデルでは計算問題のような 思考過程 を学習させることができていない」という課題に取り組んでいます。
提案手法の概要
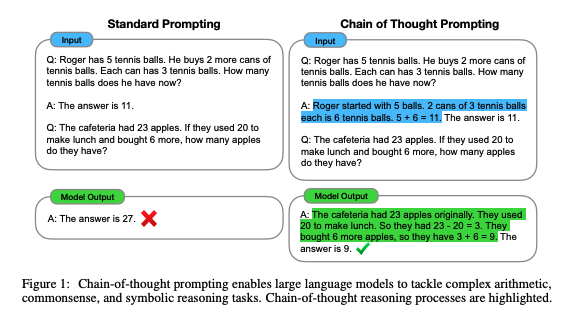
まず初めに、この論文の目標は「与えられた問いに対する最終的な答えの思考過程」も言語モデルが生成できるようにすることです。以下、論文抜粋。
The goal of this paper is to endow language models with the ability to generate a similar chain of thought—a coherent series of intermediate reasoning steps that lead to the final answer for a problem.
この「思考」を具体的に説明すると下記のようになります。
Question:
ジェーンはお花12個持っていました。母親に2つあげたあと、父親にも3つあげました。現在ジェーンはお花をいくつ持っているでしょう??
Answer(Chain of Thought):
ジェーンがお母さんに花を2つあげた後、彼女は10個持っています。それからお父さんに3つあげた後、彼女は7個持っているでしょう。だから答えは7です。
この 「ジェーンがお母さんに花を2つあげた後、彼女は10個持っています。それからお父さんに3つあげた後、彼女は7個持っているでしょう。」に相当する部分が Chain of Thought = 思考過程です。
このように、学習データのAnswer側のテキストに上記のような思考過程の情報を加わえることで、思考過程も一緒に学習させましょう、という手法ですね。
この学習方法の利点として、以下の4つの点が論文内で挙げられています。
-
モデルが段階的な推論を必要とする問題に対して、途中の推論を追加で学習することができる
-
推論ステップを分割することで、答えを間違えた際にどの推論で間違えたのかが分かるようになる
-
Chain of Thoughtによって、数学の文章問題、常識問題などの人間が言語を介して解くことができるあらゆるタスクに (少なくとも原理的には) 適用できる可能性がある
-
Chain of Thoughtは、大規模言語モデル(GPT-3やPaLMなど)において、少量のプロンプトに思考過程を追記するだけでも、効果が確認できる。
- First, chain of thought, in principle, allows models to decompose multi-step problems into intermediate steps, which means that additional computation can be allocated to problems that require more reasoning steps.
- Second, a chain of thought provides an interpretable window into the behavior of the model, suggesting how it might have arrived at a particular answer and providing opportunities to debug where the reasoning path went wrong (although fully characterizing a model’s computations that support an answer remains an open question).
- Third, chain-of-thought reasoning can be used for tasks such as math word problems, commonsense reasoning, and symbolic manipulation, and is potentially applicable (at least in principle) to any task that humans can solve via language.
- Finally, chain-of-thought reasoning can be readily elicited in sufficiently large off-the-shelf language models simply by including examples of chain of thought sequences into the exemplars of few-shot prompting.
実験は下記の3パターンに分けて、Chain of Thought Promptingを導入した結果の差を確認している。
- 算術的推論
- 常識的推論
- 記号的推論(← ここがイマイチ理解できずまとめ切れていない)
実験結果
1. 算術的推論


(追記します...)
2. 常識的推論
(追記します...)
3. 記号的推論
(追記します...)
まとめ
In all experiments, chain-of-thought reasoning is elicited simply by prompting an off-the-shelf language model.
実験の結果、全ての検証結果においてChain of Thought Promptingによる精度の向上を確認できています。普通にすごいですよね。しかし、論文内では、下記の点がまだ課題として残っていると述べています。
As for limitations, we first qualify that although chain of thought emulates the thought processes of human reasoners, this does not answer whether the neural network is actually “reasoning,” which we leave as an open question.
限界としては、まず、chain of thoughtは人間の推論者の思考過程をエミュレートしているが、ニューラルネットワークが実際に「推論」しているかどうかには答えていないことを挙げ、これは未解決問題として残しておく。
Second, although the cost of manually augmenting exemplars with chains of thought is minimal in the few-shot setting, such annotation costs could be prohibitive for finetuning (though this could potentially be surmounted with synthetic data generation, or zero-shot generalization).
第二に、手作業で模範的なデータを思考の鎖で補強するコストは、数ショットの設定では最小であるが、そのようなアノテーションコストは、微調整のために禁止されるかもしれない(ただし、これは合成データ生成、またはゼロショット汎化によって克服される可能性がある)。
Third, there is no guarantee of correct reasoning paths, which can lead to both correct and incorrect answers; improving factual generations of language models is an open direction for future work (Rashkin et al., 2021; Ye and Durrett, 2022; Wiegreffe et al., 2022, inter alia).
第三に、正しい推論経路の保証はなく、正しい答えと間違った答えの両方を導くことができる。言語モデルの事実上の世代を改善することは、将来の研究のためのオープンな方向である(Rashkinら、2021;YeとDurrett、2022;Wiegreffeら、2022、特に)。
Finally, the emergence of chain-of-thought reasoning only at large model scales makes it costly to serve in real-world applications; further research could explore how to induce reasoning in smaller models.
最後に、大きなモデルスケールでのみ思考連鎖推論が出現するため、実世界のアプリケーションで提供するにはコストがかかる;さらなる研究により、より小さなモデルで推論を誘導する方法を探ることができる。
論文のまとめ内容は以上になります。
終わりに
いかがでしたでしょうか?
「Chain of Thought Prompting」の内容は、かなりシンプルでわかりやすい話だったかなと思います。
しかし、直近の話題になる言語モデルのほとんどに採用されているぐらいには、有名な手法になっています。こういった知見は、しっかりとメリット・デメリットは把握しつつ、知見をまとめていきたいですね。