はじめに
この記事はリンクアンドモチベーション アドベントカレンダー2021のカレンダー2の23日目の記事です。
機械学習とか詳しくないけどサクッと使ってみたい、そんなあなたに
昨今AI, 機械学習が身近になって久しいですがまだまだ実際に使ってみることに関しては敷居が高く感じている方が多いのではないでしょうか。
ただ最近ではAutoML(Automated Machine Learning)という機械学習モデルの設計や構築を自動化、勝手におすすめのモデルを作成してくれるものが徐々に増え、確実に敷居は下がりつつあります。
そこで今回はAutoMLのパッケージの中でも昨年リリースされ比較的新しいローコードのAutoML、「Pycaret」をgoogle colaboratoryで実際に使って「賃貸物件の家賃予測」を行いたいと思います。
現在絶賛引越し先を探している最中なのでお得な物件を探します。
※こちらの記事を参考にさせていただきました。
準備
google colaboratoryにて以下のように自身のgoogle driveをマウント、必要なパッケージ類をインストール、インポートしてきます
from google.colab import drive
drive.mount('/content/drive')
!pip install scikit-learn==0.23.2
!pip show scikit-learn
!pip install pycaret==2.0.0
!pip install japanize-matplotlib
import pandas as pd
import re
import numpy as np
import japanize_matplotlib #日本語化matplotlib
import seaborn as sns
sns.set(font="IPAexGothic") #日本語フォント設定
データはsuumoの物件データ(東京23区)をスクレイピングし、マイドライブ配下の「Colab Notebooks」にcsvファイルとして配置します(ここが一番の山場かもしれません)
簡単のためにデータの整形は割愛します。
df = pd.read_csv("suumo.csv")
df
前処理
データと必要なパッケージ類が揃ったのでいよいよモデルを作る、、その前にまずはpycaret用にデータの前処理、前準備を行います。
同じことをpycaretを使わずに書こうとすると何行も書かなければいけませんが、pycaretなら数行で書けます。
# 今回は回帰(連続値の予測)なのでregressionを指定
from pycaret.regression import *
# データとしてdf, target(予測したい変数)として「家賃」を指定します
reg1 = setup(data=df, target="家賃", folds_shuffle=True)
そうすると下記画像のようにそれぞれの列のデータ型の確認を行います
数字型ならNumeric, いくつかの分類に分かれる場合はCategoricalと表示されます。
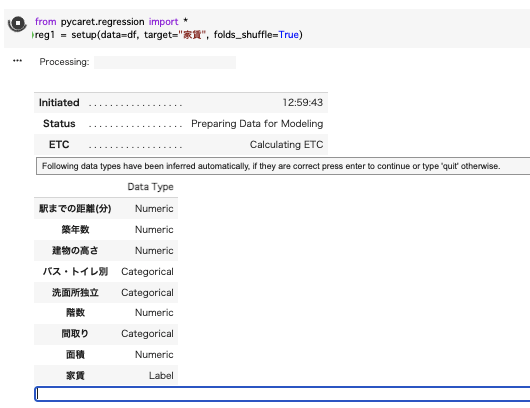
Enterを押して次に進みます。モデリング開始です。
モデリング
モデリングも一行で終わります。
複数の手法で一気にモデリングし、一番良い手法・モデルをおすすめしてくれます。
best = compare_models()
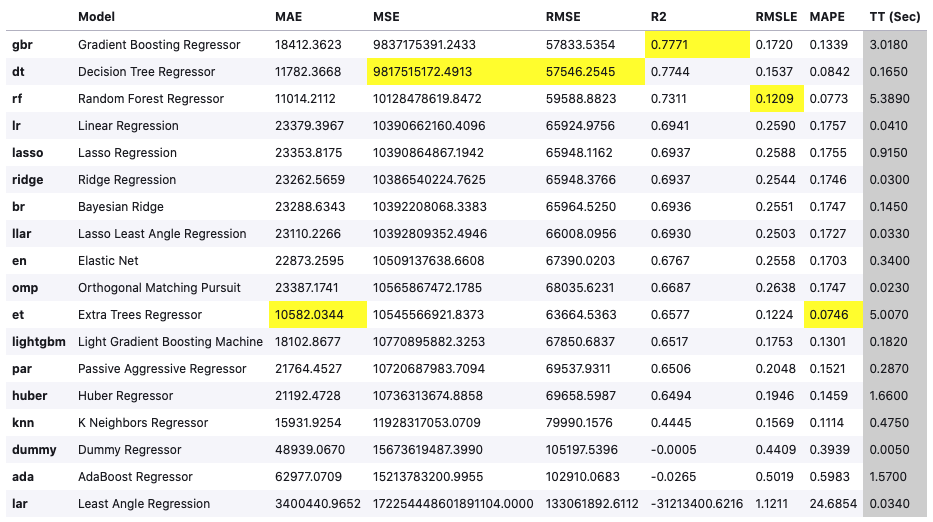
今回はGradient Boosting Regressorが決定係数R2(予測値と実測値の誤差)で評価すると一番良いモデルだったようです。
次に出来上がったモデルがどんなモデルなのか見ていきます。
可視化
予測する上でどの変数が重要だったかを可視化してみます。
plot_model(best, plot="feature")
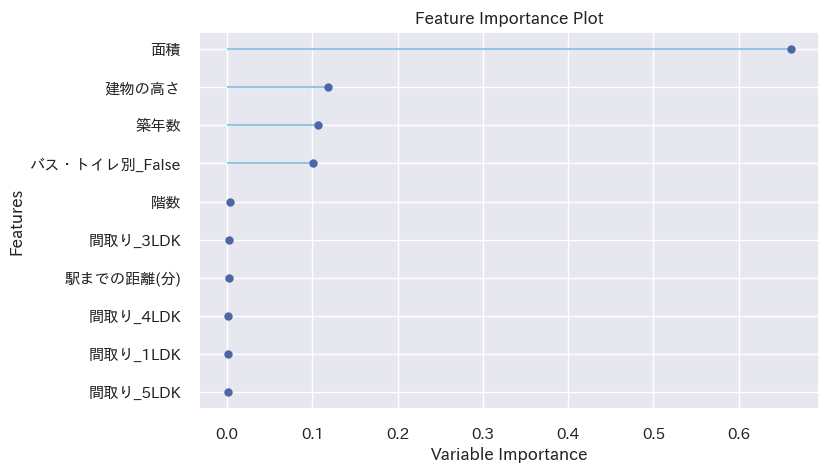
面積が圧倒的、次いで建物の高さ、築年数、バス・トイレ別かどうかと続きます。
間取りももっと上位に来るのかなと思ってましたが、間取りが大きくなれば面積も大きくなるはずなのでそこに吸収されてしまった可能性がありそうです。
個人的にはバス・トイレ別は外せない条件なので家賃が少し上がることも覚悟しなくてはならないようです。
また、予測精度を確認してみます。
plot_model(best, plot="error")
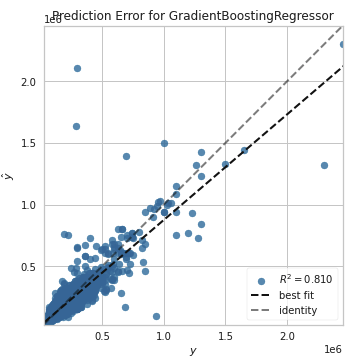
_best fit_の傾きが_identity_よりも小さくなっていることがわかります。
どうやら実際の家賃よりも少し安く見積もるようなモデルになっているようです。
結果を受けて
この結果をもとに、パートナーと物件の相談をしてみました。
予測値よりも実際の家賃が安い物件をいくつかピックアップして見せてみました。
結果は**「全然良くない」**と一蹴されました。。。
原因は駅までの距離に対する非常に強いこだわりが主でした。やはり駅近い方が楽ですしね。
また全体的に二人で住むには全くそぐわないとても広い物件も多く学習に用いていたのでここらへんを省いて学習してみたほうが良かったかもしれません。
おわりに
いかがだったでしょうか。
AutoMLにより機械学習やAIはより身近になり、誰もが気軽に機械学習等を利用出来る環境が揃いつつあります。
今回はローコードで数行のコーディングが必要でしたが、GUI上でモデリングが完結するようなサービスも数多く出てきています。
まだまだ意思決定においてそのまま機械学習モデルの結果を鵜呑みにするのは難しいようですが、
だからこそ機械学習やAIの結果を上手く解釈し、わかりやすく伝え、意思決定をサポートする人間の役割が非常に重要になってくると考えられます。
今回のツールも意思決定にそのままは難しかったですが、サクッと深く考えずにコーヒーを飲みながらでも重要な変数に当たりをつけたりするのには使えそうです。
これからも機械学習の使い所を吟味しながら、課題解決の1ツールとしてうまく活用し倒して行きましょう!