はじめに🚀
今話題のstreamlit触ってみましたよってだけ。
データ🍕
手元にあったユーザー×アイテムの購入数がマッピングされたデータになってます。
こんな感じ。
| アイテム1 | アイテム2 | アイテム3 | アイテム4 | アイテム5 | |
|---|---|---|---|---|---|
| ユーザー1 | 0個 | 0個 | 0個 | 1個 | 0個 |
| ユーザー2 | 1個 | 0個 | 1個 | 0個 | 0個 |
| ユーザー3 | 0個 | 0個 | 0個 | 3個 | 0個 |
| ユーザー4 | 0個 | 2個 | 0個 | 0個 | 0個 |
| ユーザー5 | 0個 | 0個 | 4個 | 0個 | 6個 |
書いてくよ😋
import numpy as np
import pandas as pd
import streamlit as st
from sklearn import neighbors
データロードの関数
@st.cache
def load_data():
df = pd.read_csv('data/data2.csv')
df = df.set_index('user_id')
df = df.dropna(how='all')
df = df.fillna(0)
return df
@st.cacheがないと、リロードするたびに毎回読み込みみたい
データ読み込んで、表示します!
st.title('Item Recommend Engine 🚀')
df = load_data()
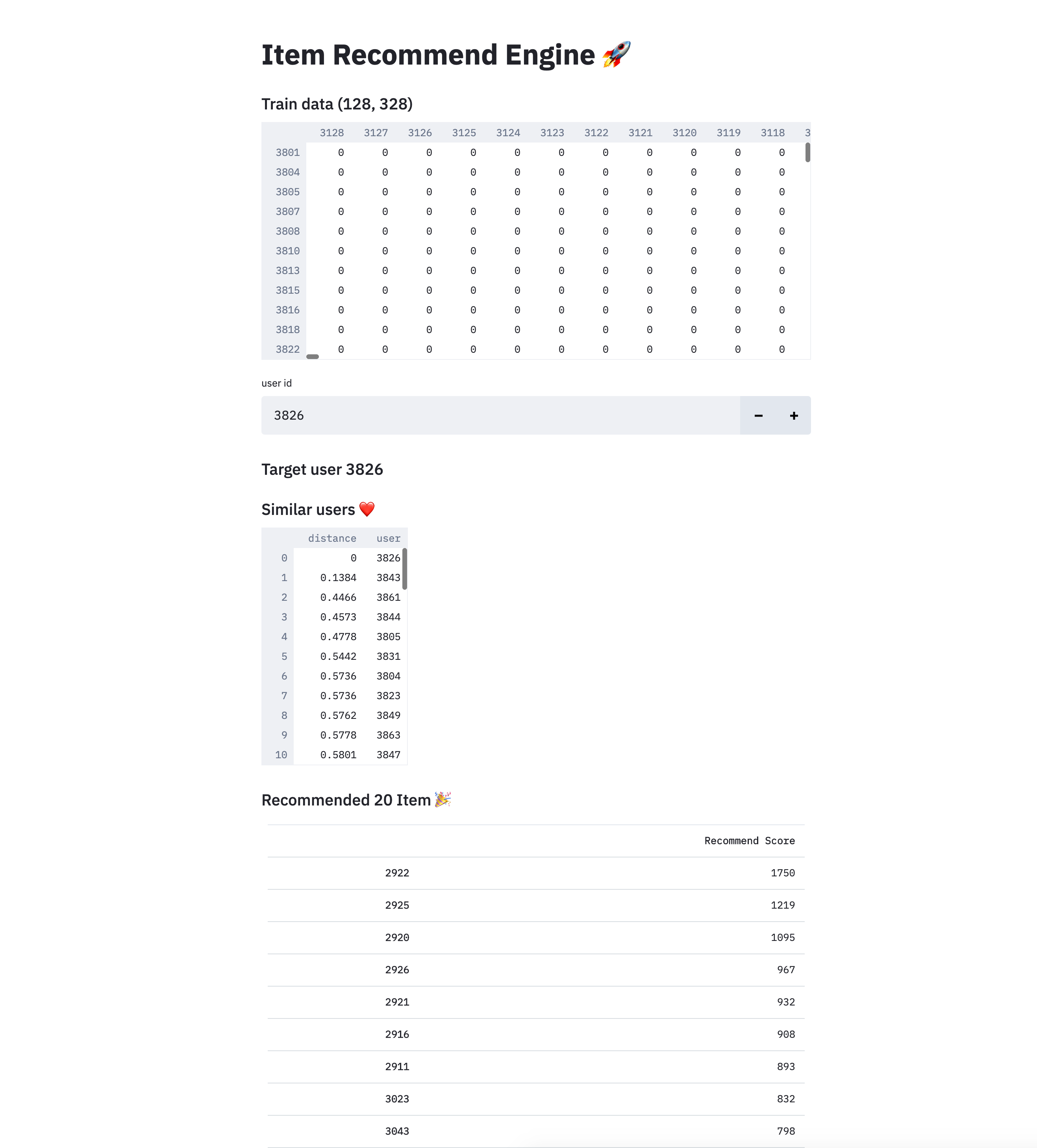
st.subheader('Train data {}'.format(df.shape))
st.write(df.head(100))

モデルを学習
knn = neighbors.NearestNeighbors(
n_neighbors=51, algorithm='brute', metric='cosine')
model_knn = knn.fit(df)
リコメンドするユーザーを指定できるようにする
user = 3826
user = st.number_input('user id', value=user)
if user not in df.index:
st.subheader('User {} is not found 😱'.format(user))
return
st.subheader('Target user {}'.format(user))

リコメンドするユーザーに類似するユーザーを算出
target_row = df[df.index == user].values.reshape(1, -1)
distance, indice = model_knn.kneighbors(target_row, n_neighbors=51)
result_df = pd.DataFrame(data={
'distance': distance[0],
'user': [df.index[indice.flatten()[i]] for i in range(0, len(indice.flatten()))]
})
st.subheader('Similar users ❤️'.format(user))
st.write(result_df)

類似ユーザーが購入したアイテムからリコメンド商品を算出
reshape_df = df.T
counts = pd.Series(
np.repeat(0, df.shape[1]), index=reshape_df.index)
i = 0
for user_id in result_df['user'].values:
s = reshape_df[user_id]
score = s * (50 - i)
counts = counts + score
i = i + 1
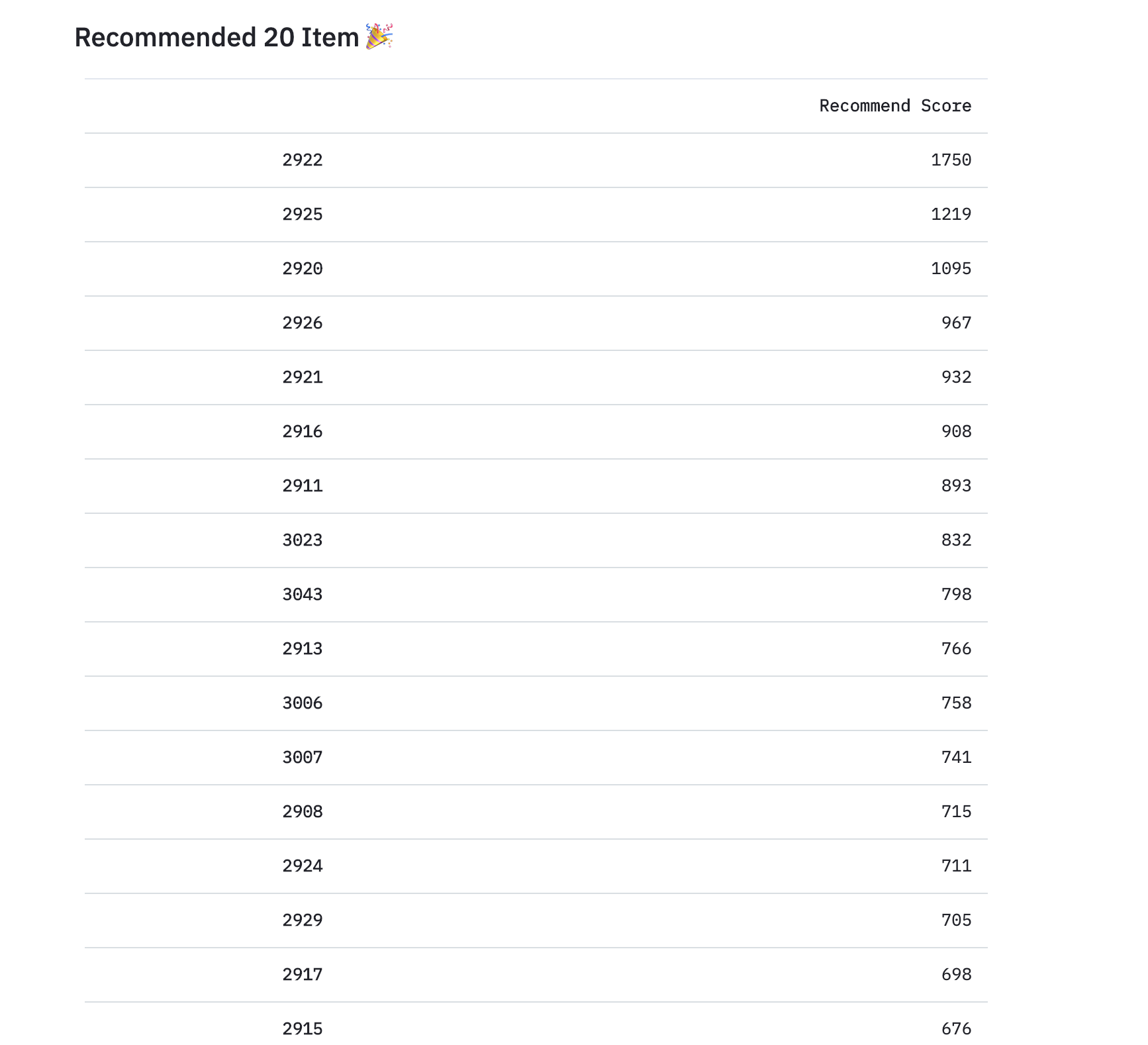
st.subheader('Recommended 20 Item 🎉')
top = counts.sort_values(ascending=False)
top.name = "Recommend Score"
st.table(top[:20])
めでたしめでたし👏
コード全体はこんな感じです。
import numpy as np
import pandas as pd
import streamlit as st
from sklearn import neighbors
@st.cache
def load_data():
df = pd.read_csv('data/data2.csv')
df = df.set_index('user_id')
df = df.dropna(how='all')
df = df.fillna(0)
return df
def main():
st.title('Item Recommend Engine 🚀')
df = load_data()
st.subheader('Train data {}'.format(df.shape))
st.write(df.head(100))
knn = neighbors.NearestNeighbors(
n_neighbors=51, algorithm='brute', metric='cosine')
model_knn = knn.fit(df)
user = 3826
user = st.number_input('user id', value=user)
if user not in df.index:
st.subheader('User {} is not found 😱'.format(user))
return
st.subheader('Target user {}'.format(user))
target_row = df[df.index == user].values.reshape(1, -1)
distance, indice = model_knn.kneighbors(target_row, n_neighbors=51)
result_df = pd.DataFrame(data={
'distance': distance[0],
'user': [df.index[indice.flatten()[i]] for i in range(0, len(indice.flatten()))]
})
st.subheader('Similar users ❤️'.format(user))
st.write(result_df)
reshape_df = df.T
counts = pd.Series(
np.repeat(0, df.shape[1]), index=reshape_df.index)
i = 0
for user_id in result_df['user'].values:
s = reshape_df[user_id]
score = s * (50 - i)
counts = counts + score
i = i + 1
st.subheader('Recommended 20 Item 🎉')
top = counts.sort_values(ascending=False)
top.name = "Recommend Score"
st.table(top[:20])
if __name__ == "__main__":
main()