VARISTAって🤔?
クラウド上で機械学習を行えるSaaSサービスです。
https://www.varista.ai/

DataRobotやGCPのAutoML Tableのかっこいい版といった感じです。
しかも基本無料で使えるため、誰でもすぐに利用可能です。
さっそく⭐️
Kaggle、Signateなどのデータサイエンスコンペサイトでは通常、
カーネルやjupyter、自前のpythonコードなどを利用して参加していると思います。
そこで今回はそれらのコンペに参加する上でVARISTAをつかうことで、どんなことができるのかを試してみました。
データは住宅価格予測(回帰)とタイタニック(分類)を利用して確認します。
1. データの確認💡
VARISTAでは、ドラッグアンドドロップでデータをアップロードするだけで
データの自動解析が行われ、ある程度の情報を一瞬で確認することができます。

アップロードが完了すると、データの情報が表示されます。

ここでチェックするのは、各列の欠損数や、列のタイプくらいですかね。
IDなどの学習に利用しない列はトグルでOFFにしておきます。
また、となりのタブにある「集計情報」からは、各列の統計情報を確認することができます。
pandas. describe()の結果をGUIで確認できる感じです。
ちょっとデータを確認したいだけなのに、わざわざ数行のスクリプト用意するのめんどくさいとき結構ありますよね。

2. データの可視化👀
KaggleなどでVARISTAを利用する上で最も重宝するのが、このビジュアライズ機能です!
pythonライブラリでもmatplotlibやseabornなど、データを可視化するライブラリはいろいろあると思います。
それらと比較して、何がいいか。
それは勝手にクールなグラフを生成してくれることです!
これからVARISTAが自動生成してくれる、各グラフをご紹介します。
まずはヒストグラム
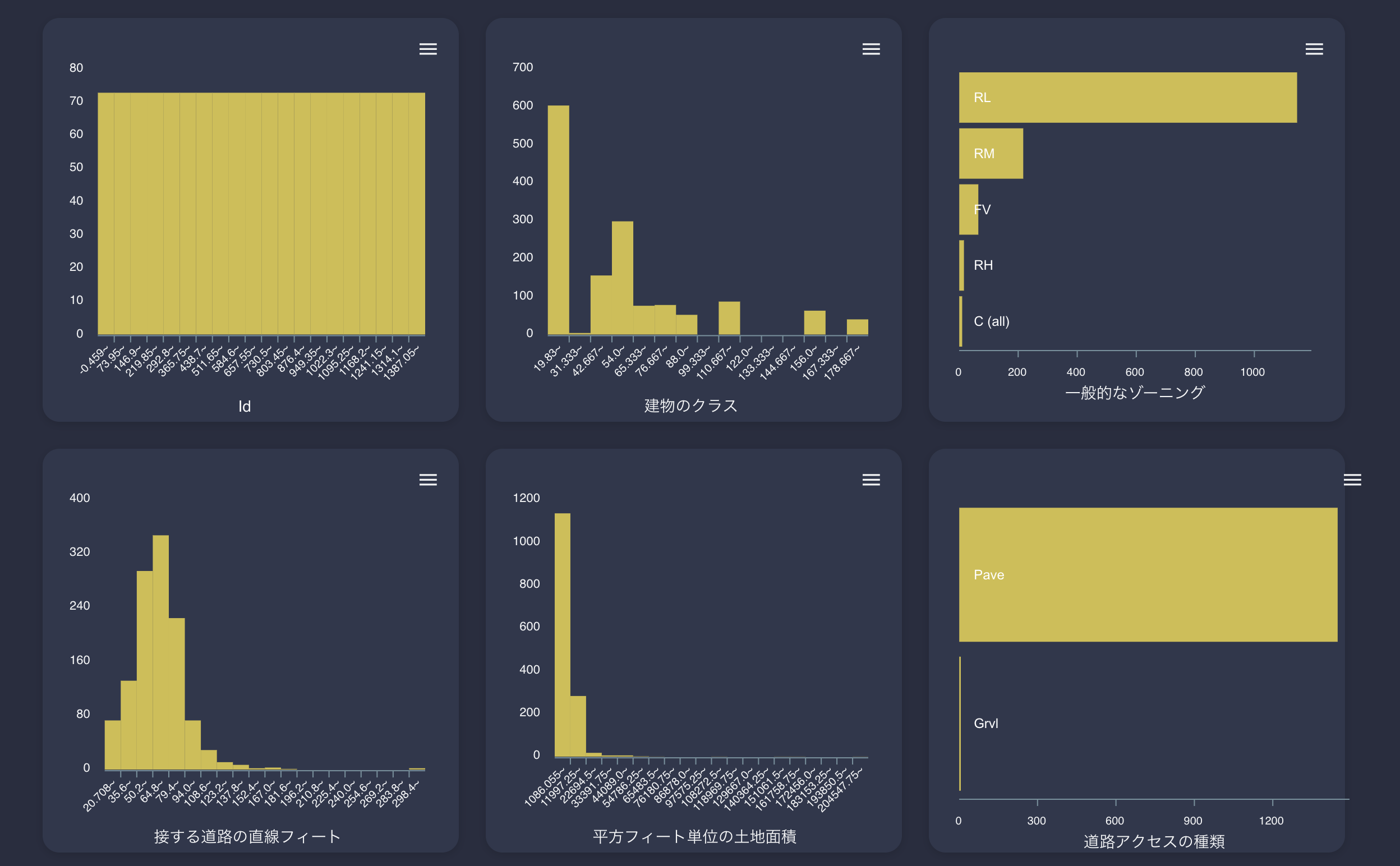 こんな感じで各列ごとのヒストグラムを確認することができます。
もう一度言いますが、全自動です。なにもしてません。
こんな感じで各列ごとのヒストグラムを確認することができます。
もう一度言いますが、全自動です。なにもしてません。
つぎに相関図
 各列と予測する列との相関関係が一眼でわかります。
数値列の場合、近似一時式の直線が表示されていたり、相関度が顔文字で表現されていたりします。
カテゴリ列の場合、最大、最小などのボックスチャートとなり表示されています。
自動でこれらの表示を分けて生成してくれるのがすばらしいですね。
各列と予測する列との相関関係が一眼でわかります。
数値列の場合、近似一時式の直線が表示されていたり、相関度が顔文字で表現されていたりします。
カテゴリ列の場合、最大、最小などのボックスチャートとなり表示されています。
自動でこれらの表示を分けて生成してくれるのがすばらしいですね。
また、これらのグラフは回帰データのもので分類問題だと以下のように表示が変わります。

タイタニックのデータでは、各数値、カテゴリごとの生存率が可視化されています。
これにより、*「年齢が若ければ若いほど生存率が高い」*などが一目瞭然です。
未知のデータに対しても、この機能だけでわかるインサイトは結構あるとおもいます。
ヒートマップ
おなじみのヒートマップです。

正直あまりみないですが、とりあえず可視化しますよね(自分だけか)
3. オート学習機能🚀
VARISTAはAutoMLツールなので、もちろん学習も可能です。
ですが、Kagglerの皆さんはもちろん精度を求めて、自分なりのパイプラインで学習を行うと思います。
だからといってVARISTAの学習は無駄か?というとそういうわけでもありません。
学習結果から得られるインサイトが結構あるのです。
学習が完了すると、このような結果画面が確認できます。
右側にあるFeature Importanceをみれば重要な変数が確認できます。

また、詳細タブを開くとより細かい学習結果が確認可能です。
VARISTAでは欠損値の補完も自動的に探索するのですが、その結果が一覧で表示されています。
データの欠損値補完を悩んでる場合は、ここを参考にしてもいいと思います。

さらにVARISTAではアンサンブル学習に対応しているため、いくつかのアルゴリズムで学習させた結果も残っています。
これを確認することで、どのアルゴリズムで最もスコアが出たのかを確認することができます。

おわり👍
VARISTAではこれらの機能が無料で利用可能です。
スクリプトを書いてもいいけど、とりあえずデータを確認したいってときに使えるツールであることがわかるかと思います。
みなさんも是非お試しください🤪