学習データ
データはkaggleのこちらのもの👇
https://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset
特徴は全部で35列
年齢、性別などの基本情報から、残業してたか、給料、勤めてからどのくらいたつかなどもあります。
ターゲットは「Attrition」離職したかどうかです。
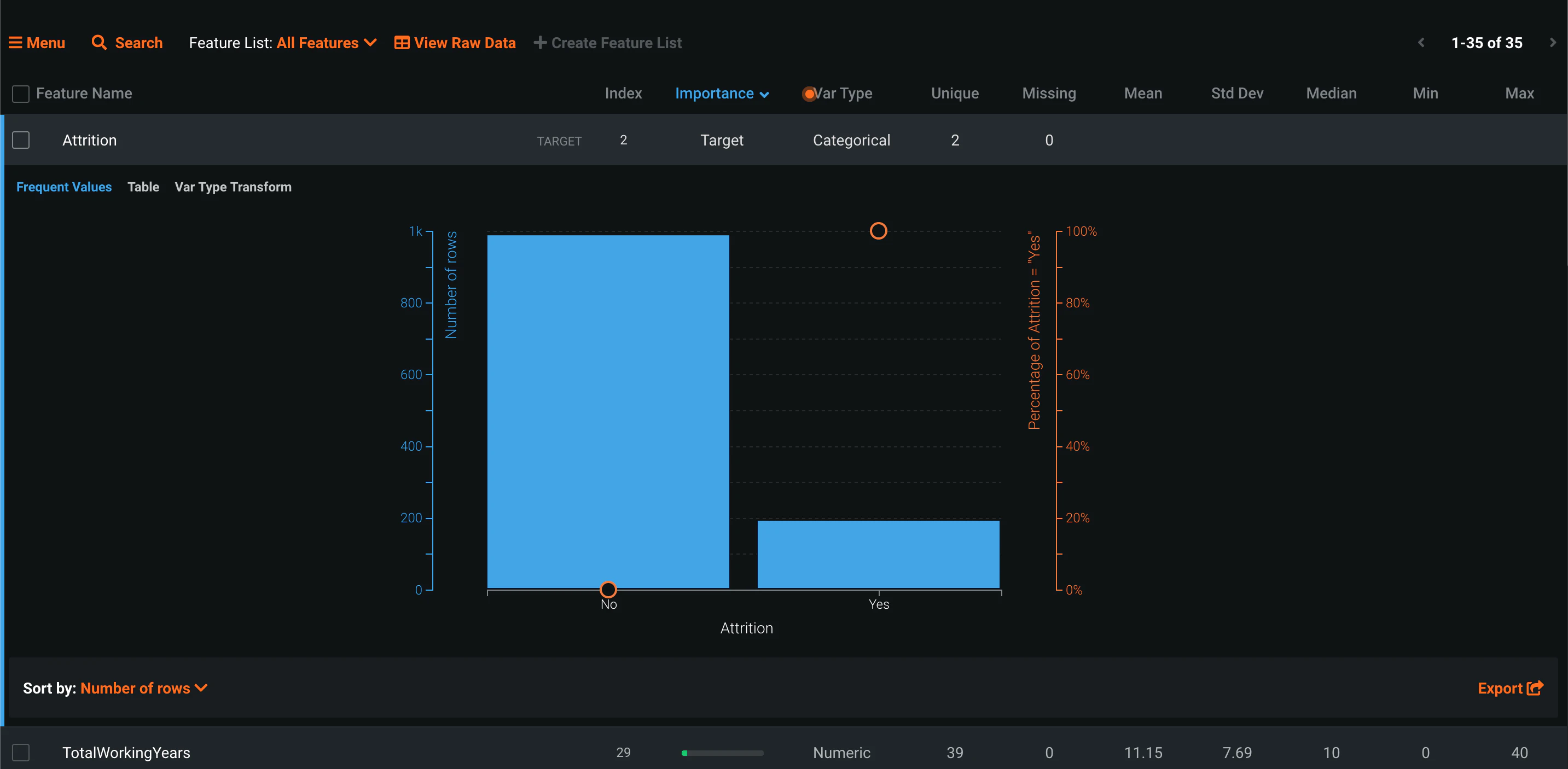
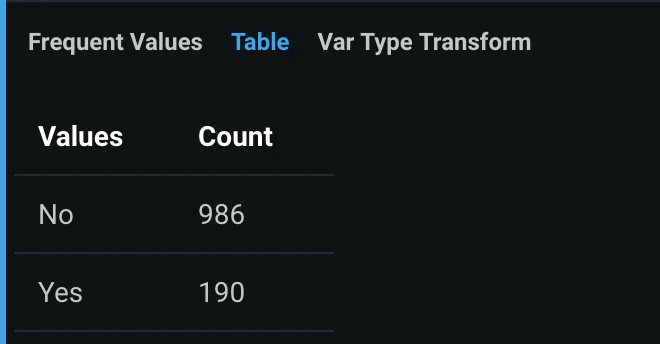
見るからに不均衡なデータです。
学習
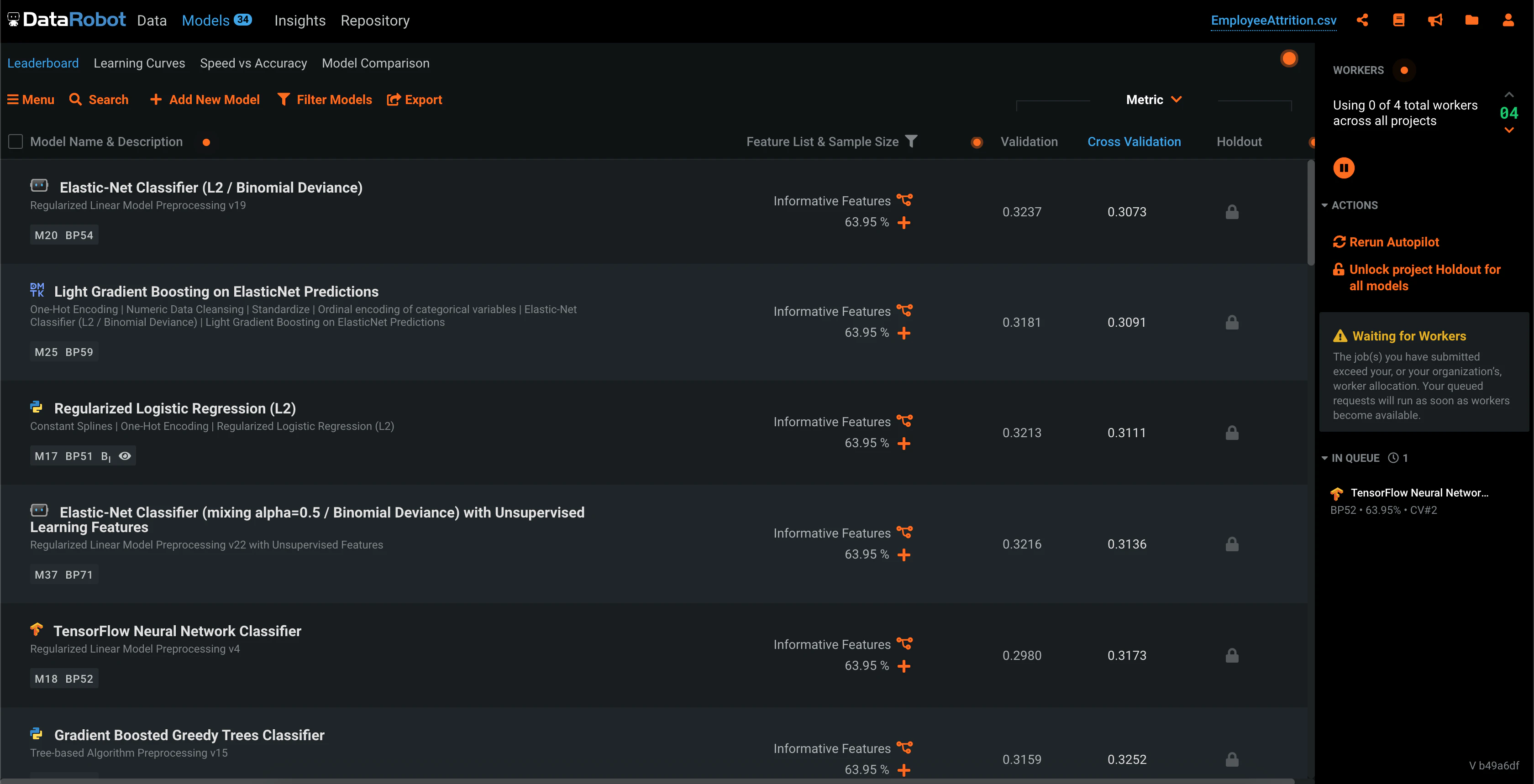
続々とモデルが作成されていきます。
結果
合計41個のモデルが生成されました。
いちばん精度が高かったのはElastic-Net Classifierでした。
ここまでわずか数分

ブループリント
2番目に精度の高かった、おなじみのLightGBMモデルをみてみましょう。
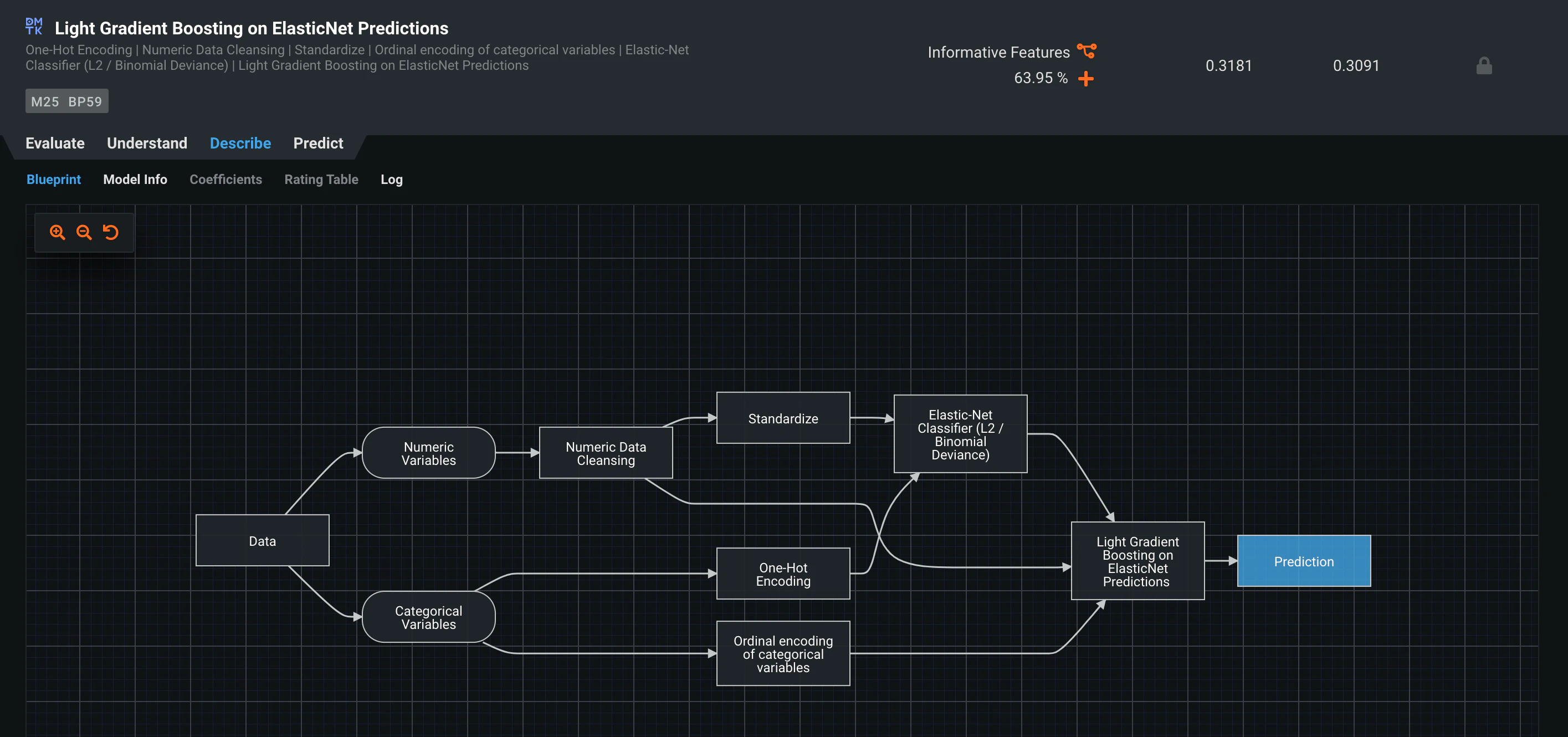
ブループリントから各特徴に施された処理が確認できます。
この自動特徴量エンジニアリングがAutoMLツールの強みですね。
精度
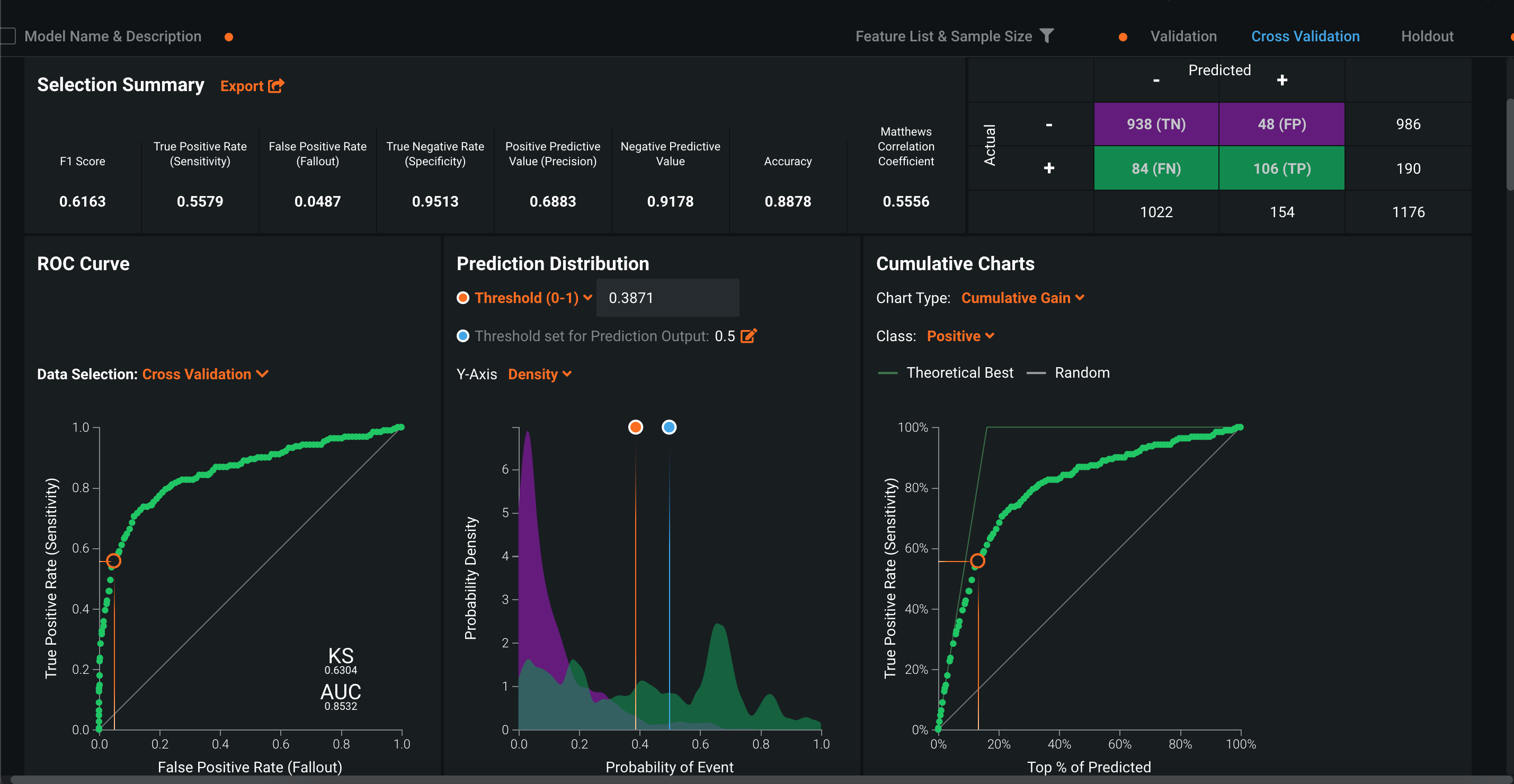 混同行列やROCカーブが自動生成されるのはいいですねー
ただ、190件の離職者のうちちゃんと的中できてるのは106件なので、もう少し精度が欲しいところ
このあとさらに精度をあげたいってなった場合は「Advancet Tuning」のところからハイパーパラメータなどの調整ができるっぽいですね
混同行列やROCカーブが自動生成されるのはいいですねー
ただ、190件の離職者のうちちゃんと的中できてるのは106件なので、もう少し精度が欲しいところ
このあとさらに精度をあげたいってなった場合は「Advancet Tuning」のところからハイパーパラメータなどの調整ができるっぽいですね
インサイト
Feature Importance
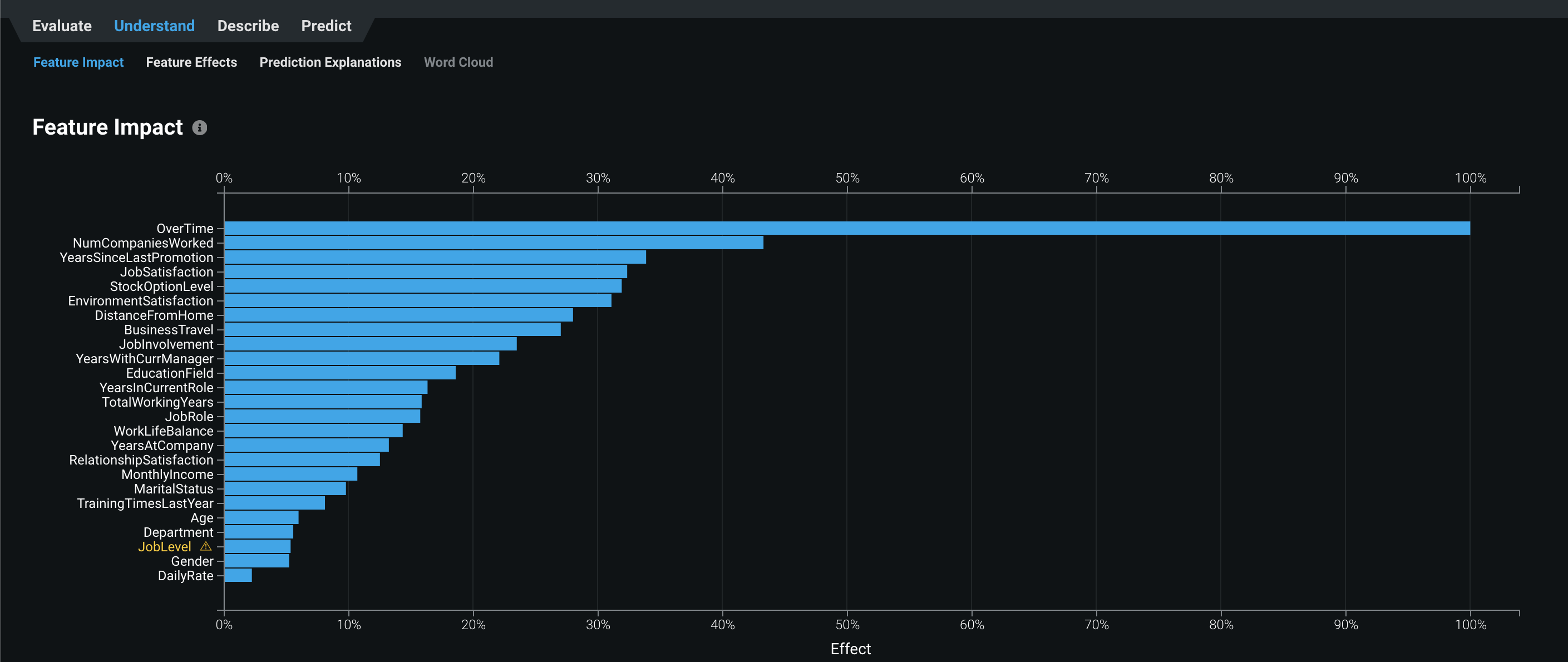 予測結果に与える影響度を可視化してくれてる機能
「OverTime」残業してるかどうかがいちばん影響してるとはなんともリアルですね。
こういうデータがあるとモデルの出力する予測結果に説得力がでてきます。
予測結果に与える影響度を可視化してくれてる機能
「OverTime」残業してるかどうかがいちばん影響してるとはなんともリアルですね。
こういうデータがあるとモデルの出力する予測結果に説得力がでてきます。
Prediction Explanations
 予測結果を何件かとってきて、なんで予測結果がそのような値になったのかを説明してくれてます。
いちばん上のID457の予測結果では「残業あり」、「出張が頻繁」、「勤めてまだ1年目」ということで離職する確率が**95.5%**であると予測しています。
予測結果を何件かとってきて、なんで予測結果がそのような値になったのかを説明してくれてます。
いちばん上のID457の予測結果では「残業あり」、「出張が頻繁」、「勤めてまだ1年目」ということで離職する確率が**95.5%**であると予測しています。
推論
 今回はこのデータセットが学習データのみだったため推論は省きますが、
学習したモデルを選択して「Prediction」の項目から推論が簡単に実行することができます。
今回はこのデータセットが学習データのみだったため推論は省きますが、
学習したモデルを選択して「Prediction」の項目から推論が簡単に実行することができます。
おわり
たった数分で学習から分析まで自動でやってくれるDataRobotさすがです。
他にもいろいろとデータの可視化やモデル比較など使える機能があるのでそれはまた別の記事で書こうかと思います。