はじめに🏠💰
今回もオープンデータで遊んでみる企画です😋
Airbnbは利用したことないので細かいことはわからないですが
ホテルの部屋のダイナミックプライシングや、ユーザーが価格を決めるときのサポートとして、機械学習による価格予測が利用されてきていますね!
👇OYOでは機械学習を利用し部屋の価格を1日4,300万回も変動させ、利益を最大化しているみたいですね。
OYO、インターコンチネンタルが「ダイナミックプライシング」を推進する一方で、真逆の戦略を採るホテルも | https://airstair.jp/oyo-dynamic-pricing/
データ📊
Signateのデータを利用します。
【練習問題】民泊サービスの宿泊価格予測 | https://signate.jp/competitions/266

構成は以下のようになってます。
| カラム | ヘッダ名称 | データ型 | 説明 |
|---|---|---|---|
| 0 | id | int | インデックスとして使用 |
| 1 | accommodates | int | 収容可能人数 |
| 2 | amenities | char | アメニティ |
| 3 | bathrooms | float | 風呂数 |
| 4 | bed_type | char | ベッドの種類 |
| 5 | bedrooms | float | ベッドルーム数 |
| 6 | beds | float | ベッド数 |
| 7 | cancellation_policy | char | キャンセルポリシー |
| 8 | city | char | 都市 |
| 9 | cleaning_fee | int | クリーニング料金を含むか |
| 10 | description | char | 説明 |
| 11 | first_review | char | 最初のレビュー日 |
| 12 | host_has_profile_pic | int | ホストの写真があるかどうか |
| 13 | host_identity_verified | int | ホストの身元確認が取れているか |
| 14 | host_response_rate | char | ホストの返信率 |
| 15 | host_since | char | ホストの登録日 |
| 16 | instant_bookable | char | 即時予約可能か |
| 17 | last_review | char | 最後のレビュー日 |
| 18 | latitudes | float | 緯度 |
| 19 | longitude | float | 経度 |
| 20 | name | char | 物件名 |
| 21 | neighbourhood | char | 近隣情報 |
| 22 | number_of_reviews | int | レビュー数 |
| 23 | property_type | char | 物件の種類 |
| 24 | review_scores_rating | float | レビュースコア |
| 25 | room_type | char | 部屋の種類 |
| 26 | thumbnail_url | char | サムネイル画像リンク |
| 27 | zipcode | int | 郵便番号 |
| 28 | y | float | 宿泊価格 |
AutoMLツール「VARISTA」
プログラミング知識ゼロの初心者でも安心なAutoMLツールを利用します!
varista.aiはAutoMLツールと言われる、機械学習のパイプラインを自動化してくれるサービスです。
ノンコーディングで、データの可視化、学習、予測などが行える優れものです。
普段Python/Rで機械学習をしている方も、実装前のデータ調査などで役立つ機能が利用できるツールでもあります。
EmailかSNSアカウントがあれば無料で開始できるのでおすすめです。
👉VARISTA | https://www.varista.ai/

プロジェクトのセットアップ✌️

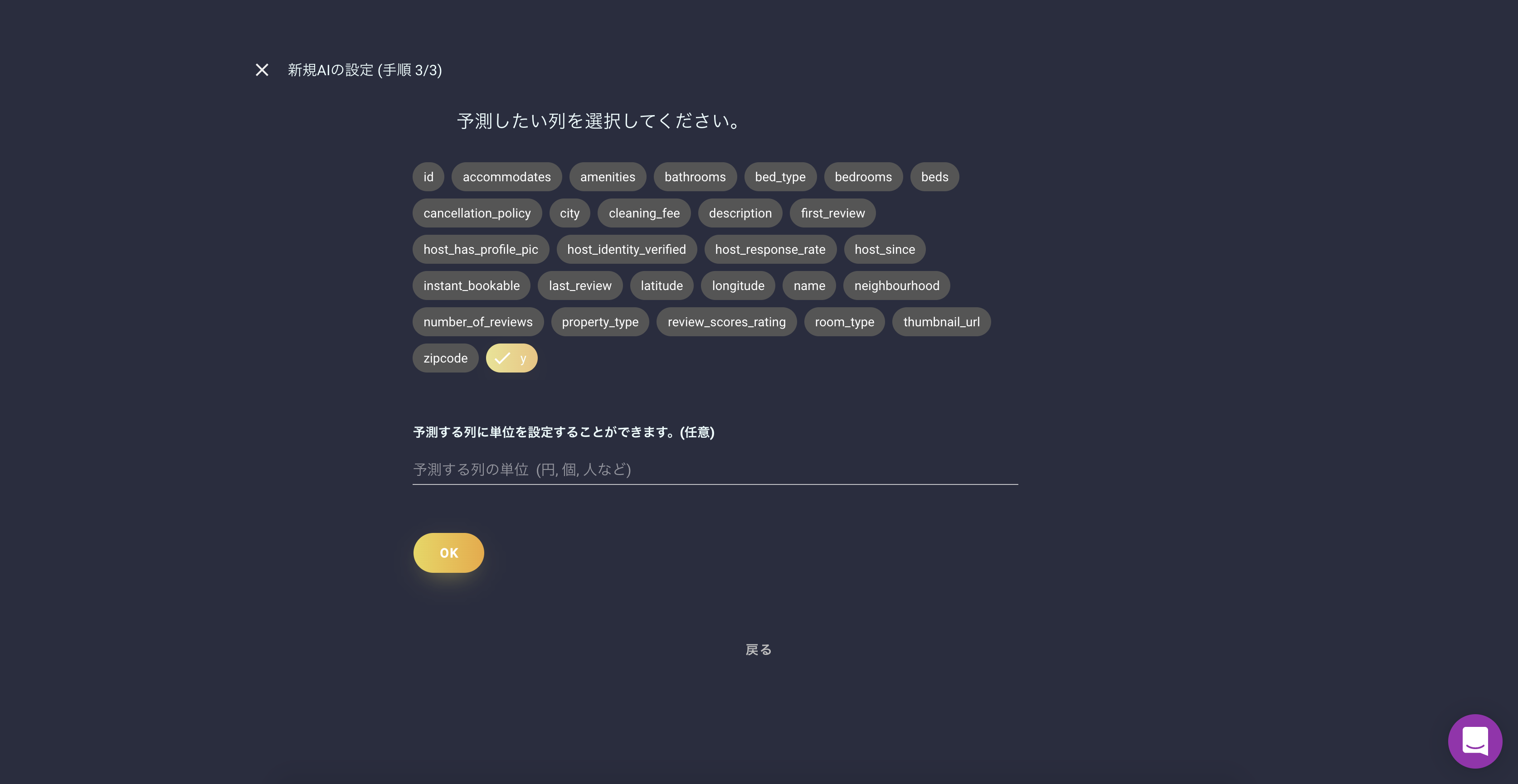 プロジェクト名を入力し、予測する列を設定します。
今回は「y」が予測する価格になります。
プロジェクト名を入力し、予測する列を設定します。
今回は「y」が予測する価格になります。
データセットアップ🍔
不要な列の削除
上の列のうち学習に利用しない方がいい不要な列を指定します。
「id」列
無規則なユニークな列は学習に影響がないので削除します。

「amenities」列
内容が構造体になっているため、利用するとしたら別途パースが必要なため、今回は削除

「description」列
自然言語列のため、利用するとしたら別途作業が必要なため、今回は削除

「name」列
自然言語列のため、利用するとしたら別途作業が必要なため、今回は削除

「thumbnail_url」列
画像分析を行う場合は、ここからダウンロードしたデータを利用しますが、テーブルデータのみで学習を行うため、今回は不要

以上5列を削除します。
相関関係の確認
varistaのビジュアライズ機能を利用して、相関関係の高い特徴を確認してみましょう。
第1位**「accoummodates」列**
相関度:52.2
部屋の収容可能人数です。確かに部屋が広く、収容人数が上がれば上がるほど、部屋の価格は高いのがあってそうですね🤔

第2位**「bedrooms」列**
相関度:49.6
ベッドの数です。部屋の収容可能人数と同じく、ベッド数も増えれば増えるほど、価格が高くなるのも理解できます🤔

第3位**「bathrooms」列**
相関度:45.6
風呂の数です。うん🤔

学習させた際にこれらの特徴がどう影響してくるのか、見てみましょう。
学習🔥
まずはとりあえず、何も設定せずに学習を行ってみます。

学習結果1
約6分で学習完了しました。

各結果の詳細をみていきます。
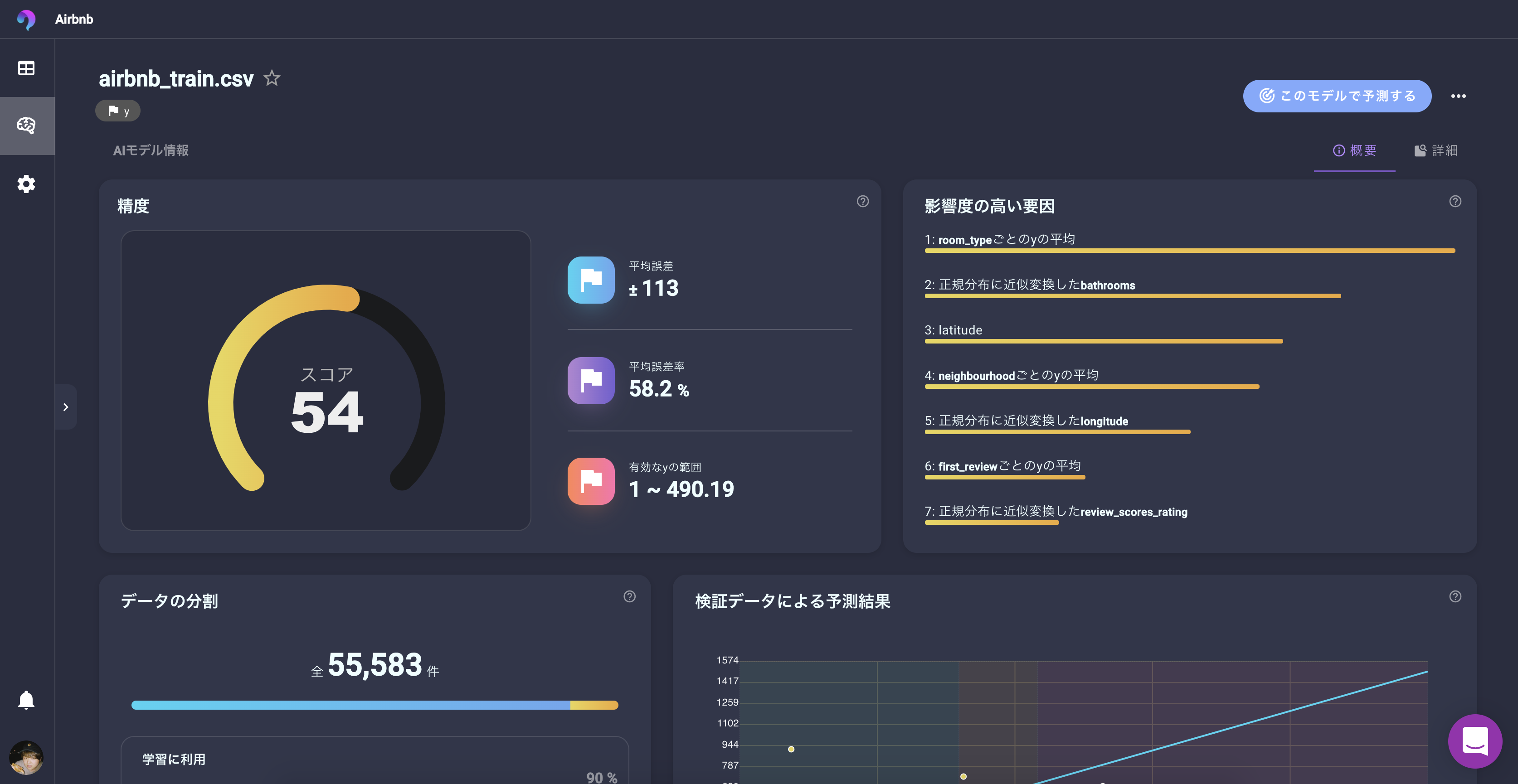
精度
全体のスコアは51となっています。
VARISTAではモデルの評価を1〜100のスコアで表示してくれます。
細かな精度は横に表示されている、精度を確認することでわかります。
平均誤差
RMSEと呼ばれる誤差の表示です。
単位が目的変数と同じため、感覚的に誤差の大きさを把握することができます。
今回の場合「平均で約±113.9ドルくらいの誤差が出るモデルですよ」っていうのがわかります。
SignateでのAirbnbコンペでも、この評価指標が使われています。

参考(https://funatsu-lab.github.io/open-course-ware/basic-theory/accuracy-index/#rmse)
平均誤差率
RMSPEと呼ばれる指標です。

参考(https://qiita.com/23tk/items/2dbb930242eddcbb75fb)
影響度の高い要因
 予測結果におおきく影響を与える要因が確認できます。
予測結果におおきく影響を与える要因が確認できます。
1位は「room_typeごとのyの平均」
一軒家の平均価格、プライベートルームの平均価格、シェアルームの平均価格が大きく影響しているようです。
これはvaristaの自動特徴量エンジニアリングの機能によって作られた特徴です。
通常では人の手でこう言った特徴をひとつづつ追加するのですが、知識がなくても自動で価値のある列を生成してくれるのもAutoMLの強みだと思います。

2位、3位...は「accommodates」、「bedrooms」...
これらの列は相関関係で確認した通り、元から相関度の高い列でしたね。
しっかりと価格予測時に参考にされているのがわかります。
zipcodeごとのyの平均
要するに地区毎の平均価格も影響を与えているようです。
日本で言うと千代田区での平均価格、世田谷区での平均価格といったようなものなので、確かに価格設定時には参考になりそうです。

モデルの改善⚡️
機械学習において精度を改善するためにとる手段は大きく分けて以下の4つがあります。
- データの改善
- アルゴリズムの変更
- パラメータの調整
- 学習パイプラインの改善
まずは4の学習パイプラインの改善を行います。
varistaでは学習時の設定で、学習レベル、検証データの割合、交差検証の分割数を変更することができます。

学習レベルを変更することで、探索するアルゴリズム数、探索時のイテレーション数などを増やすことができます。
また検証データの割合を減らすことで、簡単に精度の改善が見込めます。
しかし、あまりにデータセット数が少ない場合だと、スコア算出時のデータに偏りが生じてしまい、精度の信憑性が下がってしまう可能性があるので要注意です。
さらに、交差検証の分割数を増やすことで、パラメータチューニングや特徴選択の精度をあげることができますが、デメリットとして学習時間が長くなることが挙げられます。
以下の変更をして再学習します。
学習レベル:1 -> 3
検証データの割合:20 -> 5%
交差検証の分割数:3(そのまま)
学習結果2
 ### 改善結果
スコアが3上昇しました🔥
平均誤差もわずかですがよくなりました。
### 改善結果
スコアが3上昇しました🔥
平均誤差もわずかですがよくなりました。
このように学習データを少し増やすだけでも、精度が改善されるのがわかります。
もっと大きく改善したい場合は通してもデータそのものをいじる必要が出てくるので、それはまたの機会に。
おわり🍕
ノンコーディングでもデータサイエンスを行うのに便利なツールがたくさんで始めています。
さまざまな技術を駆使して、データから得られる有益な情報を活用してみましょう!
これから機械学習を学ぼうと思っている方も、AutoMLを利用して、基礎概念を体系的に身に付けておくのもありだと思います。