背景
AWSのMLS(Machine Learning Speciality)の勉強をしている中で、今まで聞いたことない単語が良く出てきました。
機械学習関連で忘れかけてた用語含めて、説明しながらまとめます。
AWS Certified Machine Learning - Specialty
なお、さほど有名でないと思われる単語を重点的にピックアップしてます。
MLS対策として網羅的というではありませんので、ご注意ください。
これから受けられる方のご参考になれば嬉しいです。
機械学習関連用語
アルゴリズム、データの前処理、モデル学習方法の順番にまとめます。
機械学習アルゴリズム
テキスト系
Object2Vec
単語ベクトルを生成する手法であるWord2Vecをより汎用化したもの。
長文に活用したり、高次元のベクトルを次元削減して、データ内の関係性を表現したりすることができる。
活用事例としてはレコメンデーションや長文からの特徴量抽出等がある。(参考記事)
BlazingText
Word2Vecを実装したアルゴリズムで、短い文章のベクトル化(Word2Vec)や、テキスト分類の教師あり学習も可能。
Object2Vecの簡易版。
潜在的ディリクレ配分 (LDA) アルゴリズム
文章のトピックを抽出する教師なし学習向けアルゴリズムで、トピックモデルの代表例。
トピックモデルとは、クラスタリング手法の1つであり、各データが複数のクラスに所属できるもの。
(k-means等は1データ1クラスの割り当て)
タグ付けのイメージに近い。
ニューラルトピック
文章のトピックを抽出する教師なし学習向けアルゴリズム。
LDAと同様のトピックモデルだが、計算にNNを活用しており、CPUとGPUでトレーニングが可能。
CPUでしか使えないLDAtお比較して、ニューラルトピックは並列化できるので、LDAよりも柔軟性があり、拡張性に優れている。
(AWS公式:潜在的ディリクレ配分 (LDA) とニューラルトピックモデル (NTM) のいずれかを選択する)
Seq2Seq
連続した入力データを受け取り、変換して出力するアルゴリズム。
時系列データを取り扱えるのが特徴で、例えば、機械翻訳やチャットボット、文章の要約などに用いられる。
Sockeyeモデル
PyTorchで使える、機械翻訳用に構築されているオープンソース。
Amazon SageMaker seq2seqのベースになっているそう。(AWSブログより)
ちなみに、Sockeyeとは 紅鮭 のことらしい(なぜ)

構造化データ(表形式)
AutoGluon-Tabular
最適なアルゴリズムを選ぶAutoMLライブラリの一つで、AutoGluon-Tabluarは構造化データを対象にしたもの。
候補となるアルゴリズムはRandom Forest、LightGBM、NN等。
なお、SageMakerの組み込みアルゴリズムには、AutoGluon-Tabluarしかないが、
一般向けのライブラリの中には、構造化データ以外にもテキストや画像に対応したマルチモーダル予測、時系列予測モデルがある。
AutoGluon公式サイト
ちなみに、Gluonとはクォーク同士を結合する働きがあるとされる基本粒子のこと(なんですかそれ。。。)
因数分解機
特徴量の内積を用いて計算する、分類と回帰の双方に使える教師あり学習モデル。
値が所々入っていないスパースなデータにも有効で、レコメンデーションやクリック率の予測などに用いられる。
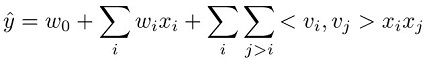
AWS:因数分解機の仕組みより
勾配ブースティング決定木(GBDT)
Kaggleでおなじみの、弱学習器を順番に組み合わせながら学習していく勾配ブースティング手法。
SageMakerでは以下の3つが組み込まれている。
- XGBoost:勾配ブースティングの先駆け
- LightGBM:計算をより軽く、早く
- CatBoost:カテゴリカル変数に対する処理を改良
時系列
時系列はSageMakerでデータの前処理からパラメータチューニングまで丁寧にやっていくパターンと、ForecastでAutoMLを使っていい感じに結果を出してもらう2パターンが存在する。
Forecastについては後述。
SageMakerに含まれるアルゴリズム
- DeepAR:RNNを利用した時系列予測。大規模なデータセットに有効。(DeepAR+とほぼ同じ?)
Amazon Forecastに含まれるアルゴリズム
2023年3月時点で6つのアルゴリズムがあるが、AutoMLを使えばデータセットに最適なアルゴリズムを自動で選択してくれる。
- DeepAR+:RNNを活用した時系列予測。大規模なデータセットに有効
- CNN-QR:CNNを活用した時系列予測。大規模なデータセットに有効
- ARIMA:自己回帰和分移動平均法(ARIMA)。小規模なデータセットに有効
- ETS:指数平滑法(ETS)。ARIMAと同様に小規模なデータセットに有効で、季節性やトレンドに対応
- NPTS:ノンパラメトリック時系列。時系列が断続的(多くの0を含む)なケースに有効
- Prophet:季節性やトレンドに対応
データ前処理
次元削減
t-SNE
高次元データを2次元又は3次元に変換して可視化するための次元削減アルゴリズム。
数値変換処理
- StandardScaler:
標準化。平均を0、分散を1となるように変換する。最大値及び最小値が決まっていない場合に活用。 - Normalizer(Min-Max normalization):
正規化。値の範囲が[0,1]の範囲となるように変換する。画像処理などの最大値が決まっている場合に活用 - MaxAbsScaler:
最大値が1となるように変換する
欠損値補完
- レコード/列の削除:欠損データが多い場合は、偏りが生じてしまうため非推奨。
- 代入法:数値なら平均値・中央値・最頻値・予測値による代入、カテゴリ値なら比率代入・予測値等。欠損値としてフラグを立てるのも可
モデル学習方法
オプティマイザ(最適化手法)
- Xavier
- Adagrad
- Adam
- RMSProp
- 勾配降下法
- ミニバッチ勾配降下法
- 確率的勾配降下法
SMOTE
k近傍法をもとに、データをオーバーサンプリング(数が少ないデータを増やす)する方法。
scikit-learnのimbalanced-learnにて実装可能
AWS関連用語
ここからはAWSサービスに関連する用語です。
SageMaker
-
Amazon SageMaker Elastic Inference(EI)
デプロイモデルからのスループットを高速化し、リアルタイムの推論を得るためのレイテンシーを短縮できる。
ただし、2023年4月15日以降は新規作成不可能となる。
AWSInferentiaなどの新しいハードウェアアクセラレータオプションを推奨とのこと。(AWSデベロッパーガイドより) -
Amazon SageMaker Ground Truth
データのラベリングサービスのこと。フルマネージド型のため、担当者との共有や収集が容易。
なお、Ground Truthは英語で、遠隔測定した地上の対象物について、実際に現地調査から得た真実のデータを言うそう。

Amazon Forecast
時系列予測を実現するサービスで、分野問わず活用可能。
モデル作成時にドメインを選択することが可能で、「小売り」「在庫管理」「ウェブトラフィック」「収益やキャッシュフロー」「労働力の需要」「EC2容量」に加えて、「その他すべて」がある。(AWS公式ドキュメント)
(EC2に特化して使えるというのは面白いですね。)
データ処理系サービス
AWS IoT Greengrass
AWS IoTの機能をエッジデバイスで実行できる。
Kinesis四兄弟
- Kinesis Data Streams:
リアルタイムに、センサ等のコンピュータから送られてくるデータを別のサービスまで届けるためのサービス - Kinesis Firehose:
Streamsと同じくデータ転送サービスだが、より管理の必要がないフルマネージドサービス - Kinesis Data Analytics:
ストリーミングデータに対して、SQLやJavaを使ってリアルタイムの分析ができるマネージドサービス - Kinesis Video Streams:
ビデオのライブストリーミングに使用したり、リアルタイムのビデオ処理やバッチ指向のビデオ分析のためのアプリケーションを構築できるマネージドサービス - 補足
- このうち、parquet形式のデータを取り込めるのはFirehoseのみ
- Firehoseなら、入力データをJSONからParquet、Apache ORC等に変換可能
- FirehoseとData Streamsの詳しい違いはこちら
-
Firehoseは消防ホースのこと

音声/テキスト/画像/動画を取り扱うサービス
この辺は取り扱うデータを起点に図でまとめました。
AWSの音声・テキスト系サービスの関連性を初心者向けに図解
* Amazon Textract
* Amazon Polly
* Amazon Transcribe
* Amazon Translate
* Amazon Comprehend
参考文献
かなりのボリュームでまとめられてますので、これからMLS受ける方はおすすめです。
AWS認定機械学習 - 専門知識を受験した時の話