はじめに
データ活用について日々勉強するなか、色々な情報がある割には実際にどのようなデータをどのように加工・集計・分析し、その結果どのような示唆が得られたのかという事については具体的な事例が少ないように感じました。
そこで、無いならば自分で発信しようということで、自身の勉強がてら定期的に情報を発信していきたいと思います。
私自身は非エンジニアの人間ですので、きれいなコードを書くことより、分析の結果どのような示唆が得られたのか、何の役に立つのかという点を重視していきたいと思います。
分析対象データ
本記事では「ID-POSデータ」を分析対象のデータとします。
「ID-POSデータ」の分析を通じて、小売・流通業界の役に立つことを目標とします。
使用するデータについて
データは、ソシム社から出版されている「データサイエンス100本ノック 構造化データ加工編ガイドブック(森谷和弘・鈴木雅也 著)」で用意されているサンプルデータを使用します。
(MITライセンスで自由に利用して良いとの事です。ありがとうございます。)
ID-POSデータとは
コンビニやスーパーで買い物をするとき、バーコードを読み込んで代金を計算しますが、この時に集められるデータが「POSデータ」です。
「POSデータ」からは、「いつ」「どこで」「どの商品が」「いくつ」「いくらで」売れたかという販売時点情報が得られます。この「POSデータ」に「誰が」という情報が加わったものが「ID-POSデータ」です。
分析の3つの視点
分析の視点として、
① 店舗視点の分析
② 商品視点の分析
③ 顧客視点の分析
の3つの視点で分析をしていきます。
(各回1テーマを取り扱う予定です)
今回のテーマ
早速、今回のテーマですが、「店舗視点の分析」をしていきます。
複数店舗を運営している小売業を想定し「客単価」と「来店頻度」の2軸で店舗間の比較をします。
「客単価」と「来店頻度」の2軸での比較を通し、店舗ごとに取り組むべき課題を抽出していきます。
分析の流れ
分析の大まかな流れは以下の通りとします。
① 上記出典元の『レシートデータ』より、2017年1月のデータを抽出
② 店舗ごとの客単価と来店頻度を算出
③ 散布図を使い可視化
④ 可視化により、各店舗の取り組むべき課題を抽出
Rによる実装
まずは、Tidyverseを読み込みます。
library(tidyverse)
次に、データを読み込みます
id_pos <- read_csv("receipt.csv")
ちなみにデータはこんな感じです
"id_pos"テーブルを表示
先頭20行のみ表示しました
データ自体は104,681行 9列のデータです
このデータの中から2017年1月のデータのみ抽出していきます
まずはsales_ymd列のデータ型を調べます。
class(id_pos$sales_ymd)
[1] "numeric"
"numeric"型(数値型)なので、日時型へ変換します
id_pos$sales_ymd <- parse_data_time(id_pos$sales_ymd, order = "ymd")
念のため、変換されたかの確認をします
class(id_pos$sales_ymd)
[1] "POSIXct" "POSIXt"
無事、日時型に変換されましたので、2017年1月のデータのみ抽出し、昇順で並び替えます
id_pos_2017_1 <- id_pos %>%
filter(year(sales_ymd) == 2017,
month(sales_ymd) == 1) %>%
arrange(sales_ymd)
上位20行だけだとわかりづらいですが、2017年1月のデータのみ抽出しました
"id_pos_2017_1"テーブルを表示
次に、集計に必要な列のみ抽出したのち、"quantity(数量)列"と"amount(金額)列"から売上金額を計算し、"sales_amount(売上金額)"列を新たに追加
id_pos_2017_1_sales_amount <- id_pos_2017_1 %>%
select(sales_ymd, store_cd, customer_id, product_cd, quantity, amount) %>%
mutate(sales_amount = quantity*amount)
"id_pos_2017_1_sales_amount"テーブルを表示
次に"store_cd(店舗コード)"でグループ化した後、2017年1月の店舗ごとの合計売上金額を計算し、"sales_store_amount"列を新たに追加
id_pos_2017_1_sales_store_amount <- id_pos_2017_1_sales_amount %>% group_by(store_cd) %>%
summarise(sales_store_amount = sum(sales_amount))
店舗ごとの2017年1月の合計売上金額が計算できました
"id_pos_2017_1_sales_store_amount"テーブルを表示
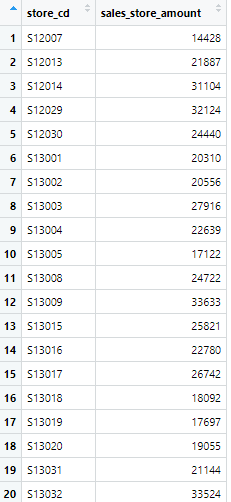
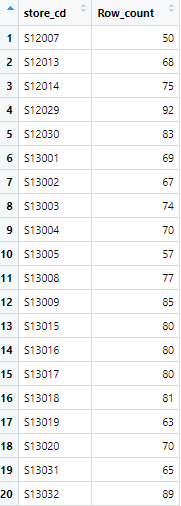
次に、2017年1月の店舗ごとの、「のべ購入回数」を計算し、"Row_count"列を新たに追加
id_pos_2017_1_store_count <- id_pos_2017_1 %>%
group_by(store_cd) %>%
summarise(Row_count = n())
店舗ごとの「のべ購入回数」が計算できました
"id_pos_2017_1_store_count" テーブルを表示
次に、上で計算した「店舗ごとの2017年1月の合計売上金額」と「のべ購入回数」から「客単価」を計算していきます
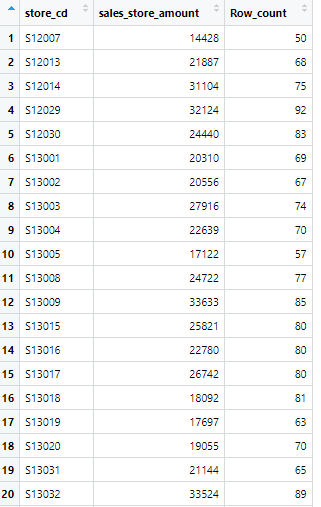
まず、店舗ごとの売上合計金額のテーブルとのべ購入回数のテーブルを結合します
id_pos_2017_1_join <- left_join(id_pos_2017_1_sales_store_amount, id_pos_2017_1_store_count,
by = "store_cd")
"id_pos_2017_1_join"テーブルを表示
"sales_store_amount(店舗ごとの売上合計金額)"と"Row_count(のべ購入回数)"から客単価を計算していきます
id_pos_2017_1_sales_per_customer <- id_pos_2017_1_join %>%
mutate(sales_per_customer = sales_store_amount / Row_count)
"id_pos_2017_1_sales_per_customer"テーブルを表示
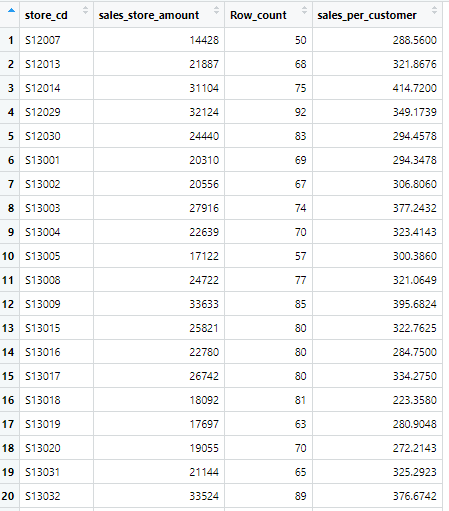
"sale_per_customer(客単価)"が計算できました
つぎに店舗ごとの来店頻度を計算していきます
そのために、まず、店舗ごとのユニーク顧客数を計算します
id_pos_2017_1_unique <- id_pos_2017_1 %>%
group_by(store_cd) %>%
summarise(unique_customer = n_distinct(customer_id))
"id_pos_2017_1_unique"テーブルを表示します
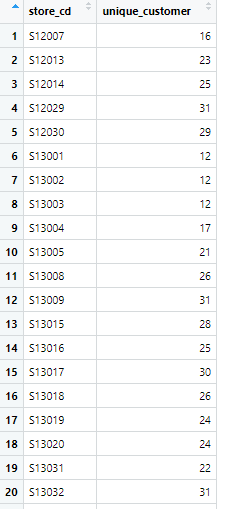
店舗ごとの"unique_customer(ユニーク顧客数)"が計算できました
このユニーク顧客数とのべ購入回数から、店舗ごとの来店頻度を計算していきます
まずは、のべ購入回数のテーブルと、上で計算したユニーク顧客数のテーブルを結合します
id_pos_2017_1_join_2 <- left_join(id_pos_2017_1_store_count, id_pos_2017_1_unique,
by = "store_cd")
"id_pos_2017_1_join_2"テーブルを表示します
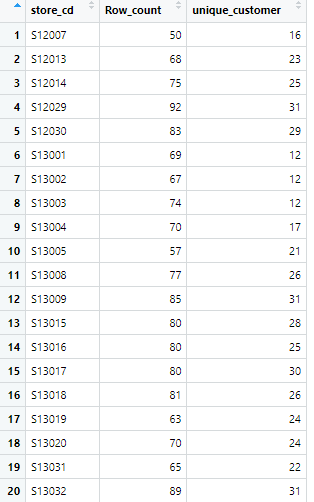
店舗ごとの「のべ購入回数」と「ユニーク顧客数」から店舗ごとの「来店頻度」を求めます
id_pos_2017_1_freq <- id_pos_2017_1_join_2 %>%
mutate(customer_freq = Row_count / unique_customer)
"id_pos_2017_1_freq"テーブルを表示します
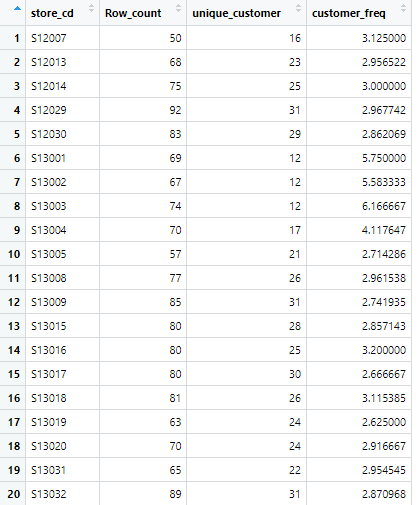
店舗ごとの「来店頻度」"customer_freq"が計算できました
これで店舗ごとの客単価と来店頻度が計算できましたので一つのテーブルにまとめます
id_pos_2017_1_for_plot <- left_join(id_pos_2017_1_sales_per_customer,id_pos_2017_1_freq,
by = "store_cd" )
"id_pos_2017_1_for_plot"テーブルを表示します
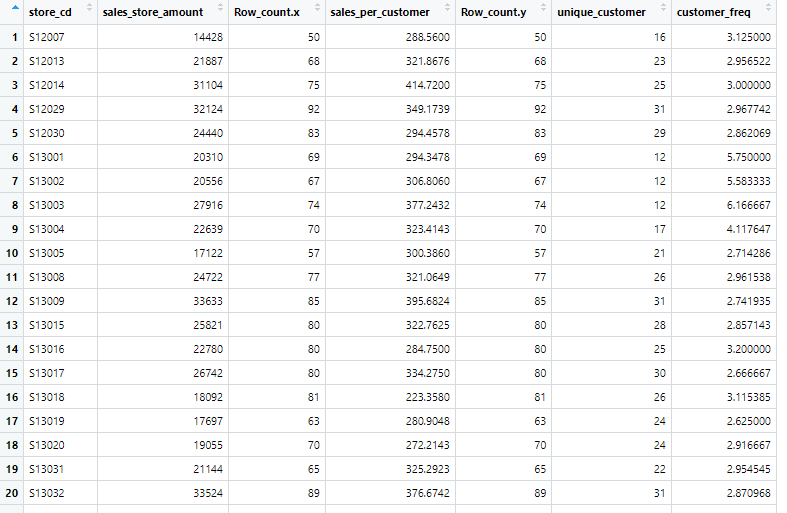
上テーブルの"sales_per_customer"列が「客単価」、"customer_freq"列が「来店頻度」です
このテーブルから、散布図を作っていきます
ggplot(data = id_pos_2017_1_for_plot) +
geom_point(aes(x = customer_freq, y = sales_per_customer,
colour =store_cd)) +
theme_classic() +
scale_x_continuous(limits = c(0,10))
散布図を表示します
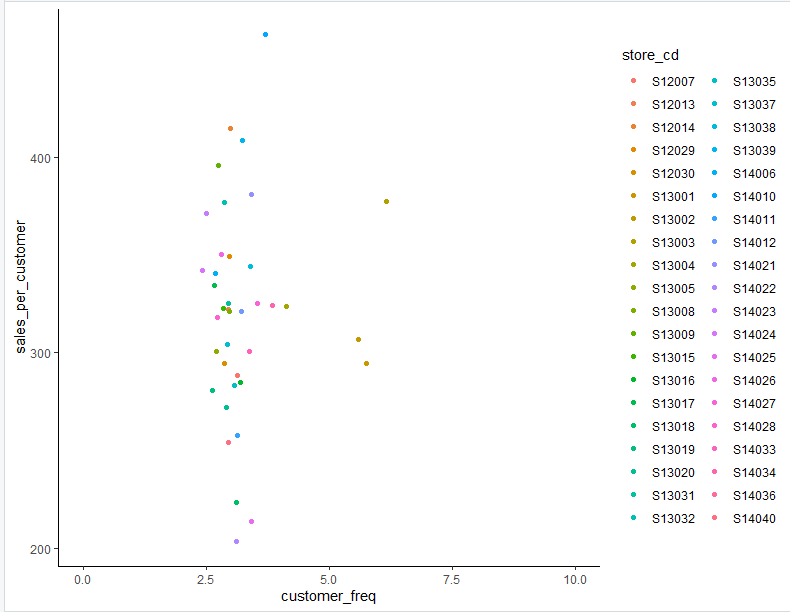
店舗によって来店頻度よりも客単価のばらつきが大きいことが分かりました
この散布図に、客単価、来店頻度それぞれの平均値を加えてみます
#客単価、来店頻度の平均値を計算する
x_mean <- mean(id_pos_2017_1_for_plot$customer_freq)
y_mean <- mean(id_pos_2017_1_for_plot$sales_per_customer)
#平均値を散布図に加える
ggplot(data = id_pos_2017_1_for_plot) +
geom_point(aes(x = customer_freq, y = sales_per_customer,
colour =store_cd)) +
theme_classic() +
scale_x_continuous(limits = c(0,10)) +
geom_vline(xintercept = x_mean, linetype = "dashed", color = "red") +
geom_hline(yintercept = y_mean, linetype = "dashed", color = "red")
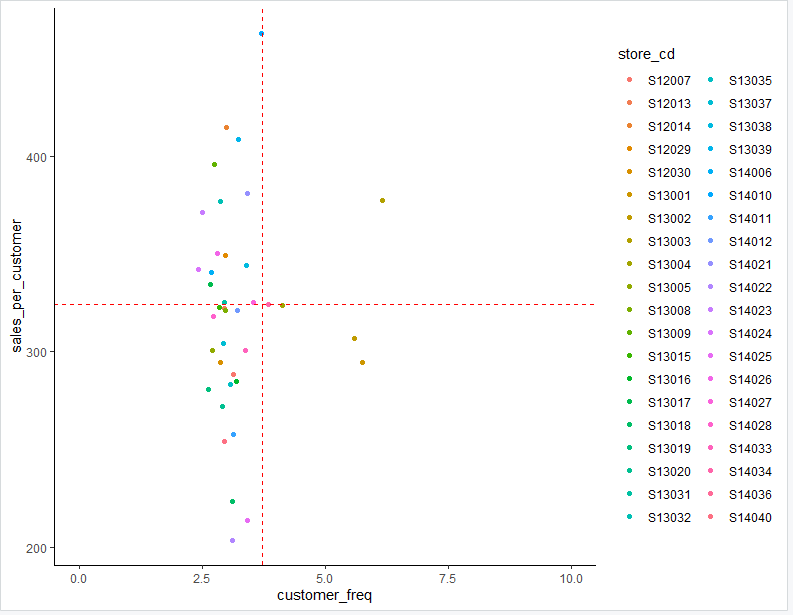
客単価と来店頻度の平均値を加えることで、4象限に分けられました
これをもとに、各店舗が客単価向上に取り組むべきか、それとも来店頻度向上に取り組むべきか等、現状を踏まえた改善施策が可能になりそうです
まとめ
今回は長くなってしまったので、ひとまず散布図で可視化したところまでとしました。
次回以降、ここからさらに、客単価がばらつく要因を調べたり、客単価が高い店舗と低い店舗では売れている商品にどのような違いがあるかなど深堀していきたいと思います。