目的
- 顔や絵画を生成するAI(GAN)について理解を深める。
- AIでバレーボールの柄を学習し、次世代っぽい柄を生成して楽しむ。
今回はGANの派生系であるDCGANを利用します。
選定理由は情報が手元にあったためです。
背景
私は絵を描くのが下手である。
何度も絵を描く勉強をしたが続かず、結局投げ出してしまった過去がある。
最近、顔や絵画を生成するAIが紹介されていたことを思い出し、絵を描く勉強を自分ではなくAIにやらせ、自分はそのAIを作る勉強をする方が適正としては合っているのではないかと考えた。
そこで、画像(に関わらず様々なデータ)を生成することができるGANの理解を深めようと、手っ取り早く何かを生成してみようと思った矢先、手元にあったバレーボールが目に入った。
GANとは
Generative Adversarial Networksの頭文字を取った言葉です。
GANは、生成ネットワーク(Generator)と識別ネットワーク(Discriminator)の2つのネットワークから構成され、お互いが競い合う仕組みとなっており、このことから敵対的生成ネットワークとも言われています。
Generatorの役目は、Discriminatorを欺く贋作を生成することです。
Discriminatorの役目は、Generatorが生成した作品の真贋を見極めることです。
職業に例えるとこんな感じです。FF感がありますね。
Generator=贋作師
Discriminator=鑑定士
GANというのは贋作の贋(GAN)説も捨てきれませんね。
DCGANとは
Deep Convolutional GANの頭文字を取った言葉です。
今回使うのはこのDCGANです。
大きな特徴としては、名前の通り、GeneratorとDiscriminatorの2つのネットワークに畳み込みニューラルネットワーク(CNN)を用いています。
これにより、通常のGANよりも鮮明な画像の生成が可能となりました。
DCGANにて生成した画像の参考を掲載します。
Pytorch公式のDCGANチュートリアルから拝借してます。
遠目にはわからないぐらいの精度が出てますね。近くで見たり、拡大すると怪しいですが。。。
この辺は学習を重ねると良くなるものなのでしょうね。あくまでチュートリアルの結果です。

実行環境
Google Colab
内容
本投稿にて紹介しているソースコードはGithubに置いてあります。
リンクはページの下部にありますので、そこから辿ってください。
1.事前準備
- インポート
import random
import time
import numpy as np
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
%matplotlib inline
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.utils as vutils
import torchvision.transforms as transforms
- 各種設定
学習に必要な設定値を定義しています。
潜在変数の領域z_dimは後述のGeneratorに入力する領域幅です。
# シード値設定
torch.manual_seed(1234)
np.random.seed(1234)
random.seed(1234)
# 潜在変数の領域
z_dim = 100
# バッチ数
batch_size = 64
# 画像サイズ
img_size = 64
# エポック数
num_epochs = 500
- 使用デバイスの確認
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("使用デバイス:", device)
- リポジトリクローン、訓練データ展開
リポジトリから訓練データを取得し展開します。
リポジトリの中には学習済みモデルも含まれており、学習なしで画像生成のみ実行する場合に必要となります。
!git clone https://github.com/MamedenQ/VolleyballDesign
!unzip VolleyballDesign/data.zip
2.Generatorの作成
- 定義
Generatorを定義します。
モデルについてはPytorch公式を参考にしましたのでこちらを見ていただいた方が良いです。
絵だけ載せると、下記のようなモデル構造をしています。
簡単に言うと、ランダムな値を受け取り、それが色んな層を経て64pxの画像に変わっていく感じです。
DCGANの特徴である畳み込みも入ってます。
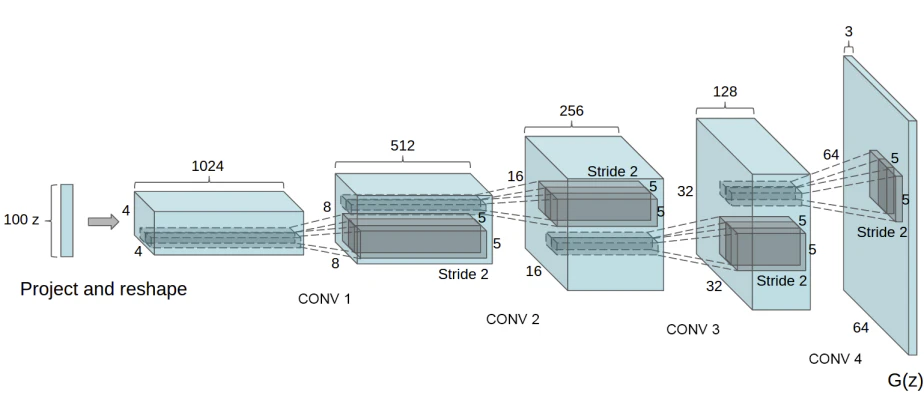
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.layer1 = nn.Sequential(
nn.ConvTranspose2d(z_dim, img_size * 8,
kernel_size=4, stride=1, bias=False),
nn.BatchNorm2d(img_size * 8),
nn.ReLU(inplace=True))
self.layer2 = nn.Sequential(
nn.ConvTranspose2d(img_size * 8, img_size * 4,
kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(img_size * 4),
nn.ReLU(inplace=True))
self.layer3 = nn.Sequential(
nn.ConvTranspose2d(img_size * 4, img_size * 2,
kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(img_size * 2),
nn.ReLU(inplace=True))
self.layer4 = nn.Sequential(
nn.ConvTranspose2d(img_size * 2, img_size,
kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(img_size),
nn.ReLU(inplace=True))
self.last = nn.Sequential(
nn.ConvTranspose2d(img_size, 3, kernel_size=4,
stride=2, padding=1, bias=False),
nn.Tanh())
def forward(self, z):
out = self.layer1(z)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.last(out)
return out
- 生成、動作確認
Generatorの生成と、動作確認として、乱数を入力し偽画像の出力を試します。
generator = Generator()
# randnは標準正規分布(平均0, 分散1の正規分布)に従う乱数を取り出す
input_z = torch.randn(1, z_dim, 1, 1)
# 偽画像を出力
fake_imgs = generator(input_z)
# 偽画像表示
plt.imshow(np.transpose(fake_imgs[0].detach().numpy(), (1, 2, 0)))
plt.show()
細かな理由はわかってませんが、シンプルな乱数ではなく、標準正規分布に従った乱数であることが大事らしいです。
torch.randn(1, z_dim, 1, 1)
偽画像を表示するとこのような画像が表示されます。
学習前なのでバレーボール感は全くありませんね。

3.Discriminatorの作成
- 定義
Discriminatorを定義します。
Generator同様、モデルについてはPytorch公式を参考にしましたのでこちらを見ていただいた方が良いです。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, img_size, kernel_size=4,
stride=2, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True))
self.layer2 = nn.Sequential(
nn.Conv2d(img_size, img_size*2, kernel_size=4,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(img_size * 2),
nn.LeakyReLU(0.2, inplace=True))
self.layer3 = nn.Sequential(
nn.Conv2d(img_size*2, img_size*4, kernel_size=4,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(img_size * 4),
nn.LeakyReLU(0.2, inplace=True))
self.layer4 = nn.Sequential(
nn.Conv2d(img_size*4, img_size*8, kernel_size=4,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(img_size * 8),
nn.LeakyReLU(0.2, inplace=True))
self.last = nn.Sequential(
nn.Conv2d(img_size*8, 1, kernel_size=4, stride=1,
padding=0, bias=False),
nn.Sigmoid())
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.last(out)
return out
- 生成、動作確認
Discriminatorの生成と、動作確認として、Generatorで出力した偽画像を入力し判定結果の出力を試します。
discriminator = Discriminator()
# 偽画像を生成
input_z = torch.randn(1, z_dim, 1, 1)
fake_imgs = generator(input_z)
# 偽画像をDiscriminatorに入力
d_out = discriminator(fake_imgs)
# 判定結果発表
print(d_out)
判定結果が出力されます。
tensor([[[[0.5361]]]], grad_fn=<SigmoidBackward0>)
この0.5361がDiscriminatorに入力した偽画像に対する判定結果となります。
(1に近いほど本物判定)
学習前のため、中間の0.5あたりの値となるはずです。
4.DataLoaderの作成
データローダを作成と、データローダから取り出した画像の確認をします。
水増しについては、上下反転、左右反転、色調整を入れています。
少し暗めの画像も含まれていたため、brightnessで多少明るくする等の調整入れました。
train_dataset = datasets.ImageFolder(root="data",
transform=transforms.Compose([
transforms.Resize((img_size, img_size)),
transforms.RandomHorizontalFlip(p=0.3),
transforms.RandomVerticalFlip(p=0.3),
transforms.ColorJitter(brightness=(1, 1.3), contrast=(1, 1.2), saturation=(0.8, 1.2)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True)
real_batch = next(iter(dataloader))
plt.figure(figsize=(8, 8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(
np.transpose(
vutils.make_grid(real_batch[0].to(device)[:batch_size], padding=2, normalize=True).cpu(),
(1, 2, 0)))
動作確認として、データローダから取り出した画像が表示されます。

5.学習
- ネットワーク初期化
重みの初期化をします。
平均と標準偏差を指定しますが、指定している値がどういった影響を及ぼすのか理解できていないので、参考としたPytorch公式のままです。
def weights_init(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm") != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
generator.apply(weights_init)
discriminator.apply(weights_init)
- 学習
いよいよ学習します。
時間がかかるので、このセルを飛ばして、次のセルで学習済みのモデルを読み込み、画像生成を試すでもいいです。
t_start = time.time()
# 最適化手法の設定
g_lr, d_lr = 0.0002, 0.0002
beta1, beta2 = 0.5, 0.999
g_optimizer = torch.optim.Adam(generator.parameters(), g_lr, [beta1, beta2])
d_optimizer = torch.optim.Adam(discriminator.parameters(), d_lr, [beta1, beta2])
# 誤差関数を定義
criterion = nn.BCELoss()
# ネットワークをGPUへ
generator.to(device)
discriminator.to(device)
# 訓練モード設定
generator.train()
discriminator.train()
# ネットワークがある程度固定であれば、高速化させる
torch.backends.cudnn.benchmark = True
# 損失のリスト初期化
g_loss_all = []
d_loss_all = []
for epoch in tqdm(range(num_epochs)):
t_epoch_start = time.time()
# epoch内の損失を溜め込むリスト
epoch_g_loss = []
epoch_d_loss = []
for imgs in dataloader:
##################
# Discriminator学習
##################
# GPUが使えるならGPUにデータを送る
imgs = imgs[0].to(device)
# 正解ラベルと偽ラベルを作成
# epochの最後のイテレーションはミニバッチの数が少なくなる
cur_batch_size = imgs.size(0)
label_real = torch.full((cur_batch_size,), 1).to(device)
label_fake = torch.full((cur_batch_size,), 0).to(device)
# 真の画像を判定
d_out_real = discriminator(imgs)
# 偽の画像を生成して判定
input_z = torch.randn(cur_batch_size, z_dim).to(device)
input_z = input_z.view(input_z.size(0), input_z.size(1), 1, 1)
fake_imgs = generator(input_z)
d_out_fake = discriminator(fake_imgs)
# 誤差を計算
label_real = label_real.type_as(d_out_real.view(-1))
d_loss_real = criterion(d_out_real.view(-1), label_real)
label_fake = label_fake.type_as(d_out_fake.view(-1))
d_loss_fake = criterion(d_out_fake.view(-1), label_fake)
d_loss = d_loss_real + d_loss_fake
# バックプロパゲーション
g_optimizer.zero_grad()
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
##################
# Generator学習
##################
# 偽の画像を生成して判定
input_z = torch.randn(cur_batch_size, z_dim).to(device)
input_z = input_z.view(input_z.size(0), input_z.size(1), 1, 1)
fake_imgs = generator(input_z)
d_out_fake = discriminator(fake_imgs)
last_d_out_fake = d_out_fake
# 誤差を計算
g_loss = criterion(d_out_fake.view(-1), label_real)
# バックプロパゲーション
g_optimizer.zero_grad()
d_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
epoch_d_loss.append(d_loss.item())
epoch_g_loss.append(g_loss.item())
g_losses_mean = np.mean(epoch_g_loss)
d_losses_mean = np.mean(epoch_d_loss)
g_loss_all.append(g_losses_mean)
d_loss_all.append(d_losses_mean)
tqdm.write("epoch {} || d_loss:{:.4f} g_loss:{:.4f} timer: {:.4f} sec.".format(
epoch + 1,
d_losses_mean,
g_losses_mean,
time.time() - t_epoch_start))
# 損失をグラフ化
fig, ax = plt.subplots(1, 1)
ax.plot(g_loss_all, label="g loss", marker="o")
ax.plot(d_loss_all, label="d loss", marker="*")
ax.legend()
print("finish time:{:.4f} sec.".format(time.time() - t_start))
学習後にGeneratorとDiscriminatorの損失がグラフで出力されます。
学習回数を変更し、1000回学習した際の損失グラフとなります。

上がり下がりを繰り返していて、学習がうまくいっているのかが正直よくわかりません。
この辺はもう少し理解、対処できるようにしていきたいです。
6.画像生成
- モデル読み込み
学習直後であれば実行不要ですが、学習済みモデルを読み込み画像生成を行いたい場合は、コメントアウトを解除し実行が必要となります。
ただし、事前設定やモデルの定義が必要となるため、本セル以前のセル(5.学習は不要)の実行が必要です。
# generator.load_state_dict(torch.load("VolleyballDesign/model/generate.pt"))
- 画像生成
学習したモデルを利用し画像を生成します。
plt.figure(figsize=(8, 8))
plt.axis("off")
plt.title("Gen Images")
fixed_z = torch.randn(64, z_dim)
fixed_z = fixed_z.view(fixed_z.size(0), fixed_z.size(1), 1, 1)
generator.eval()
fake_img = generator(fixed_z.to(device))
plt.imshow(
np.transpose(
vutils.make_grid(fake_img, padding=2, normalize=True).cpu(),
(1, 2, 0)))
8x8枚の画像がグリッドで表示されます。
下に掲載してあるイメージは2回分の生成画像を左右に並べたものになっています。
学習回数を変更し、1000回実施した際のモデルから出力された画像となります。
当たり前ですが、生成画像は毎回変わります。

思ったより綺麗に出力されていますね。もっとヒドイかと思っていました。
さて、ここまで長かったので忘れてしまったかもしれませんが、もう1つの目的はAIでバレーボールの柄を学習し、次世代っぽい柄を生成して楽しむです。
さて、楽しみましょう![]()
上の画像に赤丸をつけていますが、ハート型の模様が見えます。ちょっと無理があるかもしれませんが。。。回転したり、目を細めたりして見てください。あなたにも見えるはずです。
ボールにハート型とか、バレーボールでは今までなかったので、いいかもしれませんね。女性に人気が出そうです。ボールの柄1つでスポーツへの入りやすさも変わるのではないかなと思いました。
毎回ランダムで生成されるので、もし実行された方は、面白い柄が出てくるかぜひ試してみてください。
作成したコードのGitHub
Colabノートブックへの直接リンクはこちら。
![]()
最後に
今回はGANへの理解を深めるため、バレーボール画像を生成してみました。
これを機に他のGANへの理解も深め、いつか目標である絵画を生成するAIを作成しIT画家になりたいです。