目的
- 現状の限られたプレーデータを分析し、チームに効果的なフィードバックをしたい。
- pythonの
seabornライブラリを使ってみたい。
背景
社会人サークルのため、実業団のように専門のアナリストがいるわけではない。そのため、限られた時間と少ないデータから、効果的なフィードバックをしたいと思った。
条件
- 過去23セット分のブレイク率とサイドアウト率を元に分析する。
(もっと他にも取得しているデータや優先的に見るべきデータはある気はするが、データの整形も含め手軽に利用できる状態だったためこれを採用。) - 試合経過情報やセット終了時の成績は意識せず、シンプルにブレイク率、サイドアウト率のみで分析をする。
ブレイク率とサイドアウト率とは
- ブレイク率
自チームがサーブの時のラリーで得点することをブレイクと言います。
ブレイク率とはその割合のことです。
自チームブレイク率 = 自チームサーブ時の自チーム得点 / 自チームサーブ数
- サイドアウト率
相手チームがサーブの時のラリーで得点することをサイドアウトと言います。
サイドアウト率とはその割合のことです。
自チームサイドアウト率 = 相手チームサーブ時の自チーム得点 / 相手チームサーブ数
計算上、セットを取っている場合、自チームのブレイク率とサイドアウト率を足すと100%を超えます。
尚、自チームのブレイク率、サイドアウト率が分かれば、相手チームのブレイク率、サイドアウト率は下記となります。
相手チームブレイク率 = 100% - 自チームサイドアウト率
相手チームサイドアウト率 = 100% - 自チームブレイク率
例えば、自チームのブレイク率が高く、サイドアウト率が低い場合、相手チームのブレイク率も高く、サイドアウト率も低くなります。
seabornとは
pythonで利用できるデータの可視化ライブラリ。matplotlibという似たようなライブラリがあリますが、seabornはこれをラップしたライブラリです。
matplotlibと比べ、より簡単に、より美しくデータを可視化することができるらしいです。
実行環境
Google Colab
内容
1.分析用データを取得
!git clone -q --depth 1 "https://github.com/MamedenQ/AnalyzeBreakSideoutRate.git"
2.必要ライブラリインポート
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import seaborn as sns
今回使いたいライブラリseabornのインポート文です。
公式でも別名snsとしているようなのですが、何の略なのか分かってません。
知ってる方いたらコメントください。
3.データ読み込み確認
csv_path = "AnalyzeBreakSideoutRate/data.csv"
df = pd.read_csv(csv_path)
df.head()
1.分析用データを取得でクローンしたリポジトリ内のCSVファイルを読み込みます。
出力結果はこのような感じになるはずです。
| index | sideout | break | win_or_lose |
|---|---|---|---|
| 0 | 0.41 | 0.55 | lose |
| 1 | 0.3 | 0.3 | lose |
| 2 | 0.67 | 0.75 | win |
| 3 | 0.29 | 0.33 | lose |
| 4 | 0.5 | 0.44 | lose |
- index
インデックスです。pandasが勝手につけてくれます。 - sideout
サイドアウト率です。 - break
ブレイク率です。 - win_or_lose
勝敗です。
win:勝ちセット
lose:負けセット
4.散布図描画
sns.scatterplot(data=df,
x="break",
y="sideout",
hue="win_or_lose",
palette="deep")
# 軸の設定
gca = plt.gca()
gca.set(xlim=(0, 1), ylim=(0, 1))
plt.show()
4.1.散布図の描画関数呼び出し
今回分析するにあたり描画する図は散布図となります。
seabornで散布図を描画するためのにはscatterplot関数を使います。
scatterplotのAPIは下記にあるため深く知りたい方は閲覧してみてください。
https://seaborn.pydata.org/generated/seaborn.scatterplot.html#seaborn.scatterplot
ひとまず、使っている引数に絞って説明します。
-
data
散布図にプロットするデータを指定します。
3.データ読み込み確認でCSVから読み込んだデータフィールドをそのまま指定します。 -
x
散布図のX軸(横軸)を指定します。
今回は横軸はブレイク率を指定したため、break列を指定しました。 -
y
散布図のY軸(縦軸)を指定します。
今回は縦軸はサイドアウト率を指定したため、sideout列を指定しました。 -
hue
色相を指定します。
プロットされる点の色合いを変えることができます。色は指定した列の値ごとに割り付けられます。
今回は勝敗によってプロットされる色を変え、視覚的にわかりやすくしたかったため、win_or_lose列を指定しました。 -
palette
hue引数で指定した色相のカラーパレットを指定します。
色が変われば何でもよかったためとりあえずdeepを指定しました。この辺りのパレットが使えるようです。

色については下記に掲載されています。
https://seaborn.pydata.org/tutorial/color_palettes.html?highlight=color%20palette%20deep#qualitative-color-palettes
4.2.縦軸・横軸の目盛設定
グラフの軸を取得し、そこに対してx軸y軸の範囲を指定します。
gca = plt.gca()
gca.set(xlim=(0, 1), ylim=(0, 1))
4.3.散布図の描画結果
こんな感じです。美しいですね。
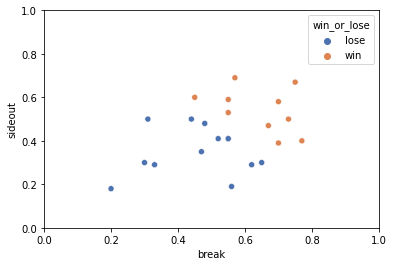
考察
この散布図から、あと10%(5%でもいい)サイドアウト率が高ければ勝てそうなセット(下の図の赤丸プロット)が見受けられた。
あくまで主観ではあるが、これらの惜しいセットを取るためには、全体としてサイドアウト率を高めていくような修正が必要と感じた。もちろんブレイク率を高めるという選択肢もあるが、一般的にはブレイクよりもサイドアウトの方が取りやすいとされることと、全体的にはサイドアウト率が低いため、底上げしやすいという理由でサイドアウト率の底上げを選択している。
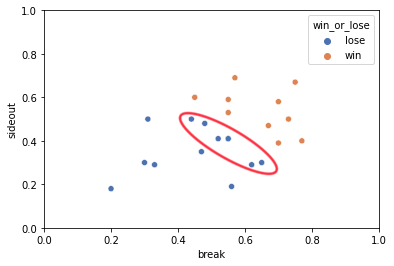
ただし、表面上の数値でしか見ていないため、どういった背景でプロットされた結果に至ったのか、今後詳細を分析し具体的な策を立てていく必要がある。
尚、ブレイク率が少々高く感じるかもしれないが、参加しているリーグは、選手、チーム同士のレベルの差が激しく、サーブや自責点だけで崩れていくパターンも少なくない。ここまでリーグ等の詳細は記載してこなかったが、当リーグは9人制バレーボールのリーグであり、1stサーブに失敗しても2ndサーブを打てるという保険もあるため、リーグレベルと相まって散布図のブレイク率につながっていると考えている。
作成したコードのGitHub
最後に
限られたデータを分析した結果、効果的なフィードバックまでとはいかなかったが、効果的なフィードバックに繋げるための第一段階としては十分な分析結果だと思った。
分析の経験や知識を持っていない素人の場合、少ないデータから様々な仮説を立てられるほどのボキャブラリーがないため、上澄みのデータを切り口に徐々に分析し広げていくことが効果的だと感じた。
尚、当方、データ分析については素人のため、諸先輩方からのご指摘や、別な切り口でのアドバイスあればコメントにてお待ちいたしております。
今後ともよろしくお願いします。m(_ _*)m