目的
-
YOLOv5について、入門までとはいかないが、門の前に立てる程度の知識を身につける。 -
YOLOv5を利用して学習から物体検出(今回はサングラス)を行い、最低限の使い方を身につける。
背景
チュートリアルでもよくある、自前でモデルの作成、学習、分類を行ったりしたことはあったが、YOLO等の物体検出アルゴリズムを利用したことがなかったため、試しに利用し、知識を得たかった。
YOLOv5とは
YOLOv5とは物体検出アルゴリズムで、You Only Look Onceの頭文字をとっています。
処理速度が非常に速いのが特徴で、リアルタイムに物体検出を行うことも可能です。
YOLOv5はPytorchをベースに作られています。
自身でpythonコードを書かずに(もちろん書くこともできます)、YOLOv5が用意している処理を実行するだけで、学習や物体検出を簡単に行うことができます。
- YOLOv5のGitHub
- YOLOv5の公式ドキュメント
実行環境
Google Colab
内容
ここからはYOLOv5を使った学習と物体検出の流れを説明します。
ソースコードについてはGitHubにアップしてあります。GitHubへのリンクは本投稿後半にあるソースコードの章を参照願います。
1.事前準備
学習、物体検出を行うための事前準備を行います。
- YOLOv5のインストール
!git clone https://github.com/ultralytics/yolov5
%cd yolov5
!pip install -r requirements.txt
- データセットの準備
YOLOv5で読み込むことが可能なデータセットを準備願います。
準備できた方は任意のディレクトリ配置してください。
2024/1/1 追記-----
下記にて、YOLOにて読み込み可能なデータセットを作成するGoogleColabを用意しました。
GoogleOpenImageDatasetにあるデータ限定となりますが、お試しする分には十分と思います。
出来上がったtrain_data.zipをyolov5フォルダ直下に解凍し利用してください。
2.学習
学習を行います。
今回は手持ちのデータ数が少なかったため、転移学習を行います。
転移学習とは
1から学習する通常学習と異なり、学習済みのモデルを元に、少ないデータでモデルを素早く再学習する方法です。
学習済みモデルのパラメータを再利用するため、いくつかの層のパラメータを固定する場合がほとんどです。
人に例えると、経験を活かすと同じ感じです。野球のバットを振るのがゴルフのスイングに活かされるように。
!python train.py --batch 16 --epochs 50 --data train_data/data.yaml --weights yolov5s.pt --optimizer AdamW --cache --freeze 10
学習が完了すると、yolov5/runs/train/expの下に学習結果が格納されます。
学習時に--nameを指定しない場合、exp,exp2・・・と自動的にフォルダ名が割り振られます。複数回学習を行った場合、間違えないよう注意願います。
学習済みモデルはweightフォルダに格納され、best.ptが一番よかったモデルとなります。
他、精度や損失についての結果等が格納されていますが、今回はそこには触れず、別の投稿で解説したいと思います。(私もまだちゃんと理解できていないため)
今回指定したオプションについての説明です。
あまり細かなことまで調べきれていないため、概要程度の説明となります。
別な投稿にて詳しい解説を予定しています。
こちらにて解説を投稿しましたので参照願います。(2022/8/2 追記)
| オプション | 指定値 | 説明 |
|---|---|---|
| --batch | 16 | バッチ数です。お使いの環境に合わせ調整してください。 |
| --epochs | 50 | 学習回数です。気の済むまで学ばせてやってください。 |
| --data | train_data/data.yaml | 読み込みたいデータセットのdata.yamlへのパスです。train.pyを実行する際のディレクトリからの相対パスとなります。データセットの場所に合わせ変えてください。 |
| --weights | yolov5s.pt | 転移学習する元の学習済みモデルです。モデルによって、学習性能や精度が異なるため、ベストなモデルを選択してください。 |
| --optimizer | AdamW | オプティマイザの指定です。この辺はあまりわかってないので、名前だけでカッコ良さそうなものをチョイスしました。ちゃんと理解した上でベストなオプティマイザを選択してください。 |
| --cache | 訓練、検証用の画像をキャッシュするどうかの指定です。指定なしの場合、キャッシュされず、学習時間が長くかかる可能性があります。指定ありの場合、画像がメモリ上にキャッシュされ、学習時間が短縮されます。お使いの環境に合わせ選択してください。 | |
| --freeze | 10 | モデルのパラメータを固定する層の指定です。固定したい層分指定してください。今回はbackboneを固定するため10を指定しました。 |
YOLOv5にて転移学習をする場合、学習時に下記オプションの指定が必要となります。
--weights
--freeze
公式GitHubのIssuesに転移学習の解説があります。
解説によると、出力層を除く、モデル全体のパラメータを固定することもできるようですが、精度が下がる結果が出ているようです。backboneのみの固定も多少精度が下がるようです。
全てが良い方向に向くわけではありませんが、手持ちのデータが少ない場合、1から始めるよりは効果があると思われます。
詳しく知りたい方は、ぜひ公式GitHubのIssuesを覗いてみてください。
物体検出
物体検出を行います。
学習同様、YOLOv5が用意した処理を呼び出すだけでも可能ですが、システムに組み込んだりする場合も想定し、コマンドから物体検出処理を呼び出す方法と、ソースコードから呼び出す方法の2種類やってみました。
- コマンドから
コマンドから物体検出処理を呼び出します。
!python detect.py --source input.jpg --conf 0.5 --weights runs/train/exp/weights/best.pt
今回指定したオプションについての説明です。
あまり細かなことまで調べきれていないため、概要程度の説明となります。
学習同様、別な投稿にて詳しい解説を予定しています。
| オプション | 指定値 | 説明 |
|---|---|---|
| --source | input.jpg | 物体検出に入力する画像、または、画像が格納されているフォルダの指定です。 |
| --conf | 0.5 | 物体を検出した際のクラス分類(今回はサングラスのみ)の判定値に対する閾値です。指定した値を下回る判定をされた物体については検出されません。 |
| --weights | runs/train/exp/weights/best.pt | 物体検出を行う際のモデルです。 |
物体検出が完了すると、yolov5/runs/detect/expの下に検出結果画像が格納されます。
画像を開くとこんな感じです。
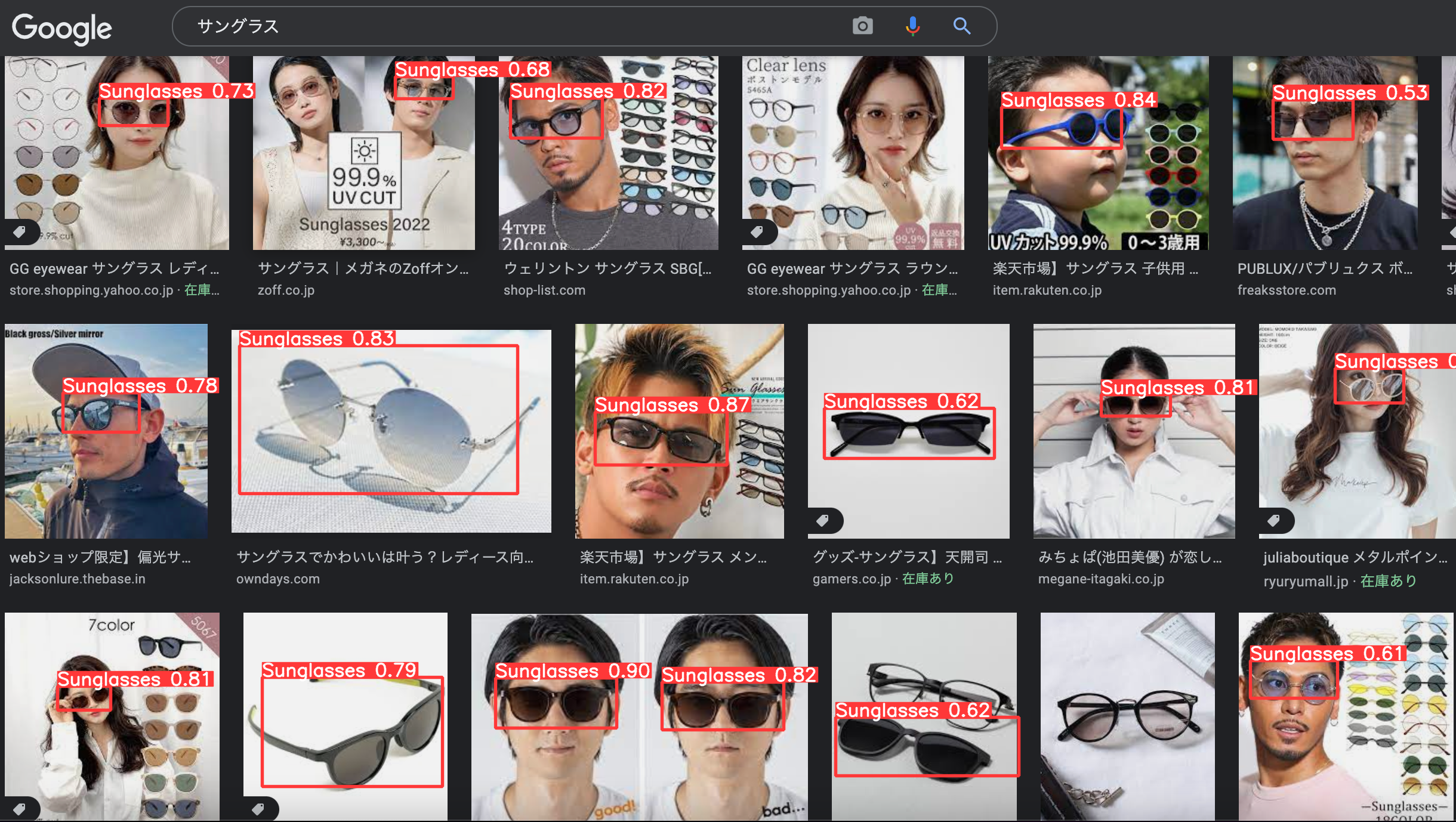
検出できていないところ、バウンディングボックスがイマイチなところありますが、比較的ちゃんとサングラスを検出できてますね!!
- ソースコードから
今度は物体検出処理をpythonのソースコード上から行います。
検出した物体のバウンディングボックスを取得し画像を切り抜き保存してみます。
import math
import torch
import cv2
# モデルの読み込み
model = torch.hub.load(".", "custom", path="runs/train/exp/weights/best.pt", source="local")
# 入力画像の読み込み
img = cv2.imread("input.jpg")
# 検出の閾値設定
model.conf = 0.5
# 物体検出
result = model(img)
# バウンディングボックスを取得し画像をクリップ
for idx, row in enumerate(result.pandas().xyxyn[0].itertuples()):
height, width = img.shape[:2]
xmin = math.floor(width * row.xmin)
xmax = math.floor(width * row.xmax)
ymin = math.floor(height * row.ymin)
ymax = math.floor(height * row.ymax)
cripped_img = img[ymin:ymax, xmin:xmax]
cv2.imwrite(f"crip_{idx}.jpg", cripped_img)
切り抜いた画像

物体検出後、結果オブジェクトからバウンディングボックスの座標(xyxyn)を取得し、画像を切り抜いてますが、結果オブジェクトが持っているバウンディングボックス座標はいくつか種類があります。
| 変数名 | 説明 |
|---|---|
| xyxy | 左上xy座標、右下xy座標がピクセルで格納されている。 |
| xywh | 中心xy座標、幅、高さがピクセルで格納されている。 |
| xyxyn | 画像の幅、高さを元に標準化(x座標を幅で割った値 yの場合は高さ)された左上xy座標、右下xy座標が格納されている。 例えば、幅1,000pxの画像で、左上x座標が400pxの場合、標準化された値は0.4となる。 |
| xywhn | 画像の幅、高さを元に標準化された中心xy座標、幅、高さが格納されている。 |
変数の命名パターンは、xyxyは左上右下xy座標、xywhは中心xy座標幅高さ、後ろにnがついてる場合、値が標準化されています。
尚、結果オブジェクトはmodels.common.Detectionsです。
print(type(result))
# 出力結果
# <class 'models.common.Detections'>
参考としてソースコードを掲載しておきます。
今後処理が変わると厄介なので、現時点の断面を指定しておきます。
以上で学習〜物体検出までの操作が完了です。
ソースコード
今回のソースコードは下記に入ってます。
ノートブックしかないので、下記リンクを叩くでも良いです。
![]()
最後に
YOLOv5を利用して、簡単に学習や物体検出を行うことができました。
まだまだ知らないことが多いため、本文中で積み残した不明点を今後調べ、もっと深めていきたいと思います。