MacにオールインワンなSpark開発環境を構築する手順のまとめ
Mac上でHadoopを動かすため実用的ではないですが、ミニマムな開発環境としては価値があるのではないかと思います。
環境
- OS X 10.11.1
- Java 1.7.0_45
- Scala 2.11.7
- Homebrew 0.9.9
- Hadoop 2.7.2
- Spark 1.6.1
Hadoopのインストール
今回はHomebrewを使用します。
$ brew install hadoop
Hadoopのインストールが終わったら、native-hadoop libraryを作成します。
※ これが無いと以下のエラーが出てHadoopが起動しません
util.NativeCodeLoader: Unable to load native-hadoop library for your platform...
- インストールしたHadoopのバージョン確認
$ hadoop version
Hadoop 2.7.2
...
Compiled with protoc 2.5.0
- 同バージョンのSourceをダウンロード
$ curl -O http://ftp.jaist.ac.jp/pub/apache/hadoop/common/hadoop-2.7.2/hadoop-2.7.2-src.tar.gz
- Protocol Buffersが入っていなければインストール
※ バージョンはそろえること
$ brew install protobuf250
- Mavenが入っていなければインストール
$ brew install maven
- native-hadoop libraryの作成
$ cd hadoop-2.7.2-src/hadoop-common-project/hadoop-common/
$ sudo mvn -P native compile
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building Apache Hadoop Common 2.7.2
[INFO] ------------------------------------------------------------------------
[INFO]
...
[INFO] Executed tasks
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: xx:xx min
[INFO] Finished at: xxxx-xx-xxTxx:xx:xx+09:00
[INFO] Final Memory: 32M/254M
[INFO] ------------------------------------------------------------------------
$ ls target/native/target/usr/local/lib/
libhadoop.1.0.0.dylib libhadoop.a libhadoop.dylib
作成したライブラリを/Library/Java/Extensionsに配置してください。
Hadoopの設定
こちらの記事を参考にしました。
Macでhadoopをちょっとだけ動かしてみる
バージョンが違うので$HADOOP_HOMEが下記になります
/usr/local/Cellar/hadoop/2.7.2
Hadoopの起動
$ cd /usr/local/Cellar/hadoop/2.7.2/sbin/
$ ./start-all.sh
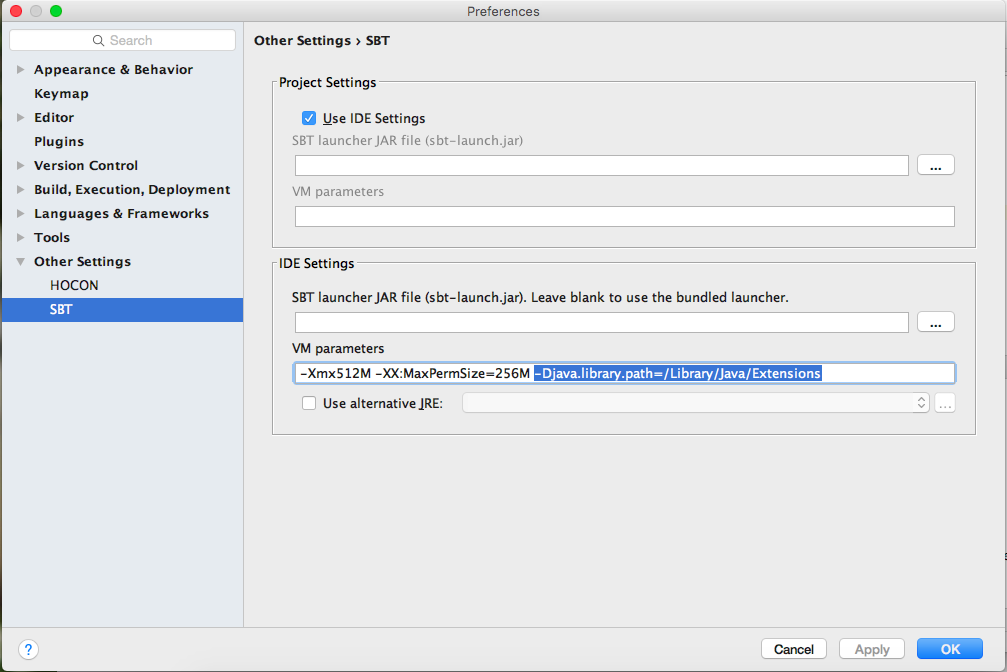
Unable to load native-hadoop library〜が出る場合はjava.library.pathに/Library/Java/Extensionsが設定されているか確認してください。
※ 起動時に以下のエラーが出ますが、Java1.7での解決方法が見つけられなかった事と、動作はするのでスルーしました。
Unable to load realm info from SCDynamicStore
Sparkサンプルのプロジェクト作成
- Activatorのインストール
こちらからダウンロードします。
http://www.lightbend.com/activator/download
$ curl -O https://downloads.typesafe.com/typesafe-activator/1.3.10/typesafe-activator-1.3.10-minimal.zip
解凍・配置したらPATHに登録しておくと便利です。
export ACTIVATOR_HOME=/usr/local/Cellar/activator-1.3.10-minimal
export PATH=$ACTIVATOR_HOME/bin:$PATH
$ source ~/.bash_profile
- サンプルデータの設置
今回はMovieLens 1Mを使用します。
$ curl -O http://files.grouplens.org/datasets/movielens/ml-1m.zip
$ unzip ml-1m.zip
$ cd ml-1m
$ hadoop fs -mkdir /input/
$ hadoop fs -put ratings.dat /input/
$ hadoop fs -ls -R /
drwxr-xr-x - root supergroup 0 2016-xx-xx xx:xx /input
-rw-r--r-- 1 root supergroup 24594131 2016-xx-xx xx:xx /input/ratings.dat
- プロジェクトの作成
Activatorでプロジェクトを作成します。
$ activator new SparkSample
Fetching the latest list of templates...
Browse the list of templates: http://lightbend.com/activator/templates
Choose from these featured templates or enter a template name:
1) minimal-akka-java-seed
2) minimal-akka-scala-seed
3) minimal-java
4) minimal-scala
5) play-java
6) play-scala
(hit tab to see a list of all templates)
> 4
OK, application "SparkSample" is being created using the "minimal-scala" template.
...
- ライブラリ・プラグインの設定
Sparkライブラリと、コマンドライン実行用のプラグインを設定します。
minimal-scalaのプロジェクトだとproject/plugins.sbtが無いと思うので作成してください。
addSbtPlugin("com.typesafe.sbt" % "sbt-native-packager" % "1.0.6")
scalaVersion := "2.11.7"
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core_2.11" % "1.6.1",
"org.scalatest" %% "scalatest" % "2.2.4" % "test"
)
enablePlugins(JavaAppPackaging)
サンプルコード
今回はデータを取得できるかを疎通確認するだけのコードを作成します。
別途、今回の環境で簡単なレコメンドロジックの実装を行う予定です。
package com.example
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Hello {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("SparkSample")
.setMaster("local")
val sc = new SparkContext(conf)
val textFile = sc.textFile("hdfs://localhost:9000/input/ratings.dat")
println(s"###file line count=${textFile.count}")
sc.stop
}
}
実行
上記のソースをコンパイルし、ratings.datの行数を出力させます。
$ cd SparkSample
$ activator compile
...
[info] Done updating.
[info] Compiling 1 Scala source to /xxx/SparkSample/target/scala-2.11/classes...
[success] Total time: 36 s, completed 2016/xx/xx xx:xx:xx
$ activator stage
...
[info] Done packaging.
[success] Total time: 11 s, completed 2016/xx/xx xx:xx:xx
$ cd target/universal/stage/bin/
$ ./sparksample
16/xx/xx xx:xx:xx INFO SparkContext: Running Spark version 1.6.1
...
### file line count=1000209
結果(1,000,209行)が出力されました。
実ファイルの行数と一致しています。
$ cat ratings.dat | wc -l
1000209
おまけ
IntelliJのSBT ConsoleでUnable to load native-hadoop library〜エラーが出る場合は、Preferences...からjava.library.pathを設定するとよさそうです。