Athena
Amazon Athenaは、標準SQLを使用してAmazon S3に保存されたデータを分析することができる、強力でサーバーレス、インタラクティブなクエリサービスです。複雑なETLパイプラインやデータウェアハウスを設定して管理する必要がなく、大量のデータを処理する組織にとって魅力的なオプションです。ただし、Athenaの価格設定は、予算が厳しい場合など、すべてのユーザーに適しているわけではありません。このブログ投稿では、Athenaの代替となる、低コストで同等の機能を提供できるアルティメットを紹介します。
利点:
Athenaの主な利点の1つは、Amazon S3のデータを、複雑なETLプロセスや専用のデータウェアハウスなしに、標準SQLクエリを使用して分析できることです。 Athenaはサーバーレスでもあり、データ量やクエリの複雑さに基づいて自動的にスケールされるため、事前のインフラストラクチャ投資が必要なく、柔軟で費用効果の高いデータ分析ソリューションを提供します。
短所:
多くの利点があるにもかかわらず、Athenaの価格設定は、大量のデータを処理する必要があるユーザーにとっては不利な場合があります。 Athenaは、クエリによってスキャンされたデータの量に基づいてユーザーに料金を請求するため、クエリが最適化されていない場合やS3バケットに不必要なデータが多い場合、高いコストにつながる可能性があります。また、Athenaのクエリパフォーマンスは、クエリに複雑なジョインや集計が含まれる場合を含め、大規模なデータ分析に特化した他のツールよりも速くない場合があります。
全体として、Athenaは多くのユーザーにとってデータ分析を簡素化する強力なツールです。ただし、その価格設定はすべての組織に適しているわけではなく、より費用効果の高い代替方法が存在する場合があります。次のセクションでは、Athenaの代替手段を紹介し、それらがどのように異なるデータ分析ニーズを満たすことができるかを探求します。
DuckDB
DuckDBは、高速な解析クエリのパフォーマンスを提供するために設計された現代的な埋め込み型SQLデータベースです。オープンソースであり、SQLiteの代替として使用できますが、より高いパフォーマンスとより高度なSQL機能のサポートが可能です。DuckDBはまた、軽量で使いやすく、多くのユースケースに適しています。Athenaの代替ソリューションでは、DuckDBを使用してデータをストアおよびクエリするためのサーバーレス環境を構築し、Athenaの価格設定構造に比べて費用効果が高い代替手段となります。
DuckDBの詳細については、公式サイトをご覧ください。
Lambda
AWS Lambdaは、サーバーのプロビジョニングや管理の必要なく、イベントに応じてコードを実行できるサーバーレスのコンピュートサービスです。Python、Node.js、Javaなど、さまざまなプログラミング言語でコードを書くことができ、Lambdaは受信したイベントの数に応じてコードを自動的にスケーリングします。これにより、イベント駆動型アプリケーションやサービスの構築に理想的であり、短時間の計算タスクや定期的な計算タスクの実行にも適しています。Athenaの代替ソリューションでは、Lambdaを使用してDuckDBクエリを実行し、サーバーレスコンピューティングのスケーラビリティと柔軟性を活用しながら、コストを低く抑えることができます。
前述の通り、Amazon Athenaの価格設定は、大規模なデータ分析には高額になる可能性があります。この課題に対応して、DuckDBのパワーとAWS Lambdaの柔軟性を活用した、費用対効果の高い代替ソリューションを開発しました。SQLエンジンとしてDuckDBを使用し、サーバーレスコンピュートサービスとしてAWS Lambdaを使用することで、Athenaと同様の機能を実現しながら、コストを大幅に削減することができます。以下のセクションでは、このソリューションがどのように動作し、自分自身のデータ分析ニーズに実装する方法について詳しく説明します。
仕組み
私のソリューションの手順は以下の通りです:
- Amazon S3に構造化または半構造化データを保存します。このデータは、CSV、JSON、Parquetなどのさまざまな形式で保存できます。
- AWS Lambdaを使用して、DuckDBクエリを実行します。AWS Lambdaがサポートする多数のプログラミング言語(Python、Node.js、Javaなど)でクエリを書くことができます。
- Lambda関数で、DuckDBを使用してAmazon S3からデータを読み込みます。DuckDBは、CSV、JSON、Parquetなどの多様なファイル形式からデータを読み込むことができます。
- DuckDBを使用して、Lambda関数内でSQLクエリを実行し、データ分析タスクを完了します。
このソリューションでは、サーバーレスコンピューティングのスケーラビリティと柔軟性を活用しながら、コストを抑えることができます。次のセクションでは、このソリューションの各ステップを詳しく説明し、自分自身のデータ分析ニーズにこのソリューションを実装する際の例やヒントを提供します。
ビリングモデル
私のAthenaの代替ソリューションの請求モデルは、予算内で大規模なデータ分析タスクを実行する必要があるユーザーにとって費用対効果が高いように設計されています。
Amazon S3バケットに保存されたデータがLambda関数と同じリージョンにある場合、データ転送やスキャンに追加の料金はかからず、Lambda関数の実行時間のみが請求されます。これにより、データスキャンに料金を課金するAmazon Athenaを使用する場合に比べて、大幅なコスト削減が可能になります。
ただし、Amazon Athenaは、データ転送、スキャン、クエリの実行にそれぞれ別々に料金を請求します。本文執筆時点では、Amazon S3でのデータスキャンの費用は1テラバイト(TB)あたり5ドルです。大規模なデータ分析タスクを実行する必要があるユーザーにとって、これはすぐに高額になる可能性があることに注意してください。
Lambda関数の最適化に経験があるユーザーにとっては、AWS Lambda Power Tuningなどのツールを使用してLambda関数のメモリ使用量を調整することで、費用対効果を大幅に改善できる機会があります。
最後に、ネットワークデータ転送はLambda関数の実行時間に影響を与える可能性がありますが、Amazon Elastic File System(EFS)にデータをプリロードしたり、他の最適化技術を使用するなど、これを軽減するための多数の戦略があります。
インプリメント
Athenaの代替ソリューションをTypeScriptとDuckDBを使用してAWS Lambdaに実装するために、最初にDuckDB Node.jsモジュールをインストールして、Lambda関数で使用できるようにする必要がありました。
さらに、Lambda関数にDuckDBレイヤーを構成する必要があります。これにより、gLibcなどの必要な依存関係やhttpfs、parquetなどの一般的な拡張機能が提供され、Lambda環境でDuckDBを使用してAmazon S3の様々な形式のデータを簡単に読み取り、SQLクエリを実行できます。
TypeScriptを使用することで、Lambda関数を強力に型付けされたオブジェクト指向の方法で書くことができ、保守やデバッグが容易になります。以下のセクションでは、必要なコンポーネントの設定方法を説明し、TypeScriptを使用してAWS LambdaでDuckDBクエリを実行するためのサンプルコードを提供します。
IaC
import * as cdk from 'aws-cdk-lib';
import { NodejsFunction } from 'aws-cdk-lib/aws-lambda-nodejs';
import { Construct } from 'constructs';
import { Architecture, Runtime } from "aws-cdk-lib/aws-lambda";
import { aws_lambda } from "aws-cdk-lib";
import { Bucket } from "aws-cdk-lib/aws-s3";
import { BucketDeployment, Source } from "aws-cdk-lib/aws-s3-deployment";
import * as path from "path";
import { PolicyStatement } from "aws-cdk-lib/aws-iam";
export class DuckdbSampleStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const URSA_LABS_TAXI_DATA_BUCKET_NAME = 'ursa-labs-taxi-data';
const duckdbLambda = new NodejsFunction(this, 'DuckdbSampleLambda', {
functionName: 'DuckdbSampleLambda',
entry: 'src/duckdb-sample.ts',
handler: 'handler',
runtime: Runtime.NODEJS_18_X,
architecture: Architecture.X86_64,
memorySize: 128,
timeout: cdk.Duration.minutes(15),
bundling: {
minify: false,
sourceMap: false,
target: 'es2018',
externalModules: ['duckdb']
},
environment: {
URSA_LABS_TAXI_DATA_BUCKET_NAME
}
});
// if region is ap-northeast-1, you can use this layer
if (this.region === 'ap-northeast-1') {
duckdbLambda.addLayers(aws_lambda.LayerVersion.fromLayerVersionArn(this, 'DuckdbLayer', 'arn:aws:lambda:ap-northeast-1:041475135427:layer:duckdb-nodejs-x86:1'));
} else if (this.region === 'us-east-2') {
duckdbLambda.addLayers(aws_lambda.LayerVersion.fromLayerVersionArn(this, 'DuckdbLayer', 'arn:aws:lambda:us-east-2:041475135427:layer:duckdb-nodejs-x86:1'));
}
bucket.grantRead(duckdbLambda);
// can read s3;
duckdbLambda.addToRolePolicy(new PolicyStatement({
actions: ['s3:*'],
resources: [`arn:aws:s3:::${URSA_LABS_TAXI_DATA_BUCKET_NAME}/*`],
}));
}
}
Lambda Code
import * as duckdb from 'duckdb';
import * as util from "util";
import { Handler } from 'aws-lambda';
const db = new duckdb.Database(':memory:');
export const handler: Handler = async (event) => {
const sql = event.sql;
async function executeQuery(query: string) {
console.time(query);
const result = await dbAllPromise(query);
console.timeEnd(query);
return result;
}
const dbAllPromise = util.promisify(db.all.bind(db));
const results = await Promise.all([sql].map(executeQuery));
return 1;
}
実験
私たちは、DuckDBとAWS Lambdaを使用したAthenaの代替ソリューションの効果を実証するため、ニューヨーク市タクシーデータを使用した実験を行いました。ニューヨーク市タクシー・リムジン委員会(TLC)のデータセットを使用し、ライセンスを持つタクシーやフォー・ハイヤー車がニューヨーク市で行った旅行に関する情報を含んでいます。このデータセットはParquet形式で複数年にわたりあり、各レコードにはピックアップやドロップオフの時間、場所、料金などの情報が含まれています。私たちはこのデータセットをAmazon S3に保存し、DuckDBを使用したLambda関数を使ってSQLクエリを使用してデータを分析しました。同じデータセットとクエリを使用して、Athenaと私のソリューションのパフォーマンスとコストを比較し、公平な比較を提供しました。
私たちは、大規模なデータセットに対して効率的な圧縮とクエリのパフォーマンスを提供するために設計された列指向ストレージフォーマットであるParquet形式でニューヨーク市タクシーデータセットを保存しました。Parquetは分析的なワークロードとOLAPワークロードの両方に最適化されており、データ分析タスクに最適な形式です。Amazon AthenaとDuckDBの両方が、Parquet形式で保存されたデータを読み取ることができるため、どちらのソリューションを使用しても効率的にデータを分析することができました。私たちは実験で、Parquet形式で提供される効率的なストレージとクエリパフォーマンスを活用しながら、DuckDBとAWS LambdaをAthenaの代替として使用した場合のパフォーマンスとコストを評価しました。
テスト用に4種類のSQLを実行する:
SELECT vendor_id, count(*)
FROM read_parquet('s3://ursa-labs-taxi-data/2019/*/data.parquet')
GROUP BY 1;
SELECT passenger_count, avg(total_amount)
FROM read_parquet('s3://ursa-labs-taxi-data/2019/*/data.parquet')
GROUP BY 1;
SELECT passenger_count, extract(year from pickup_at), count(*)
FROM read_parquet('s3://ursa-labs-taxi-data/2019/*/data.parquet')
GROUP BY 1, 2;
SELECT passenger_count, extract(year from pickup_at), round(trip_distance), count(*)
FROM read_parquet('s3://ursa-labs-taxi-data/2019/*/data.parquet')
GROUP BY 1, 2, 3
ORDER BY 2, 4 desc;
これに対応して、Athenaでも同じSQLを実行し、Athenaでは年、月のパーティションを設定しています。
SELECT vendor_id, count(*)
FROM "ursa-labs-taxi-data"
WHERE year = 2019
GROUP BY 1
ニューヨーク市タクシーデータセットを使用した実験で、私たちは、DuckDBとAWS Lambdaのソリューションは、Amazon Athenaを使用する場合に比べて、最大75%のコスト削減を提供することが分かりました。私たちはLambda関数の実行時間を最適化していないにもかかわらず、より低いコストが実現できる可能性があります。追加の最適化なしで、私たちのソリューションとAthenaのクエリの実行時間とコストを比較することに重点を置きました。
私たちの実験では、私たちのソリューションはAthenaに比べて似たようなクエリパフォーマンスを提供し、クエリの実行時間は数秒から数分に範囲があり、LambdaとS3間のデータ転送に大きく依存します。一部の種類のクエリに対してAthenaはより高速な実行時間を提供できるが、私たちのソリューションの低コストと柔軟性は多くのユーザーにとって実現可能な代替案であると考えられます。
私たちはLambdaを128M/512M/832M/3008Mのメモリで使用しました。
実験結果
Duration vs Cost for SQL1
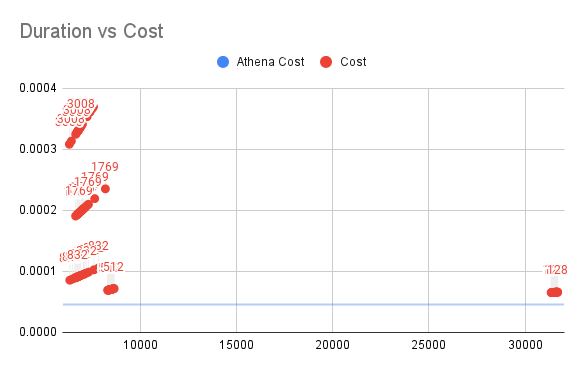
垂直軸がLambdaのコスト、水平軸が実行時間を表しています。
SQL1については、Lambdaは常にAthenaよりも多くのコストがかかります(図の青線)し、メモリが不十分な場合は実行時間が30秒以上になるなど、異常な長時間の実行が観測され、128Mのメモリがすべて消費されることがわかります。
Duration vs Cost for SQL2
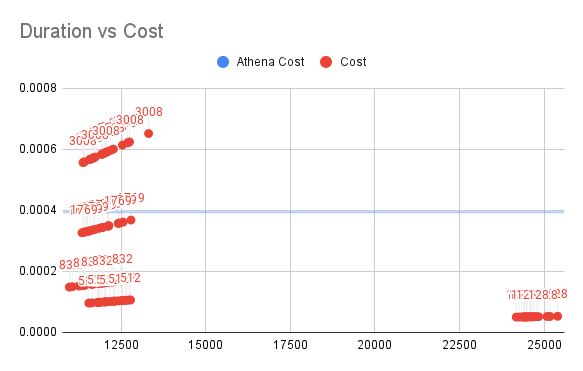
垂直軸がLambdaのコスト、水平軸が実行時間を表しています。
SQL2については、計算に余分な列が含まれているため、データ量が増加するにつれて(メモリを無駄にしない場合の512M / 832M)Athenaの価格は0.0004程度であり、Athenaの価格の50%未満、または25%未満になることが観測されました。
Duration vs Cost for SQL3
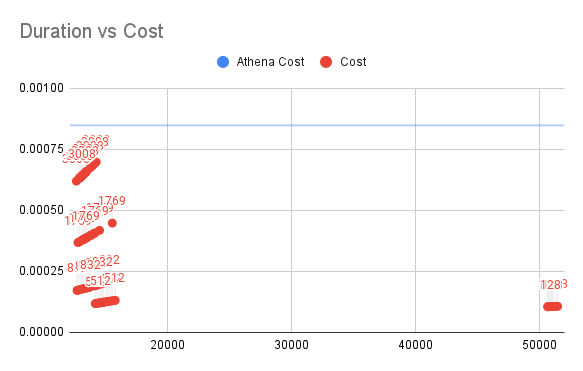
垂直軸がLambdaのコスト、水平軸が実行時間を表しています。
SQL3については、データ量がさらに増加するにつれて、512M環境では私たちのソリューションのコストがAthenaの価格の15%未満であることがわかりました。
Duration vs Cost for SQL4
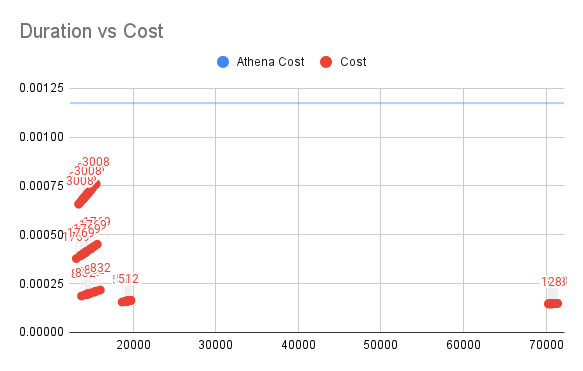
垂直軸がLambdaのコスト、水平軸が実行時間を表しています。
結果によれば、SQL4の場合、Athenaの価格はさらに高くなっていますが、私たちのソリューションはあまり変わっていません。512Mのメモリを使用したLambda関数を使用する場合、Athenaの価格の14%以下のコストで同じ処理を実行することができました
Data Scanned vs Cost
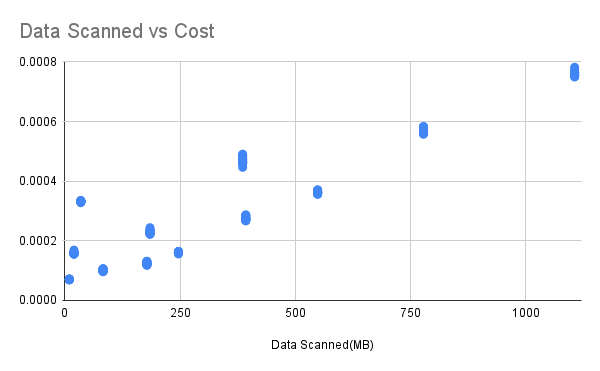
水平軸がスキャンされたデータ量、垂直軸が消費額を表しています。この結果は、512Mのメモリ環境で行われました。
データ量が増加するにつれて、Lambdaの実行時間が増加するため、消費額も増加することが分かります。Lambdaの実行時間の増加は、主にS3からのデータ読み取りから来ると考えられます。
Data Scanned vs Ratio of My Solution spending to Athena spending
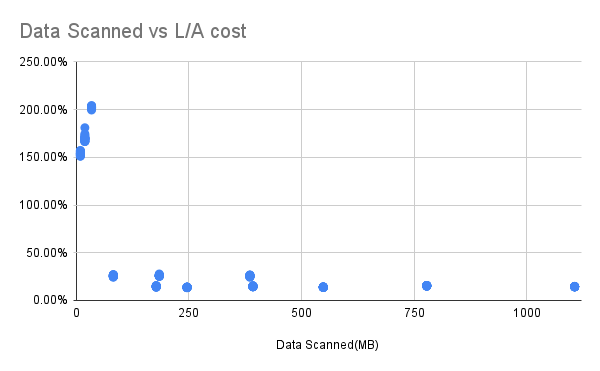
水平軸がスキャンされたデータ量、垂直軸が私たちのプログラムの支出とAthenaの支出の比率を表しています。
このデータは、それぞれ6か月、1年、2年のデータをLambda 512MBの環境で実行したSQL1/2/3および4の結果です。左端には3つのスタックがあります。これはSQL1の場合で、コストが100%以上になるため、私たちのソリューションの方がAthenaよりも高価であることを意味します。可能な理由は、DuckDBがS3とデータの転送を行う際に、総データ量は小さいが転送に必要なリクエスト数が変わらないためです。しかし、SQL1をよく見てみると、1つの列のみを対象とするこのような単純なクエリは、稀であるとも言えます。
SQL1以外のケースでは、データが6か月または1年または2年であっても、Athenaが費やす費用の25%未満、または15%未満であることが分かります。
実験結果の生データはこちらから取得できます。
実験コードの全体はこちらで入手できます。
結論
利点
- Amazon Athenaに比べてデータ分析タスクのコストを抑えられる。
- Glueを使用してメタデータを生成および管理する必要はありません。
短所(改善可能点)
- 計算中の最大メモリ使用量は10GBに制限される。ただし、私たちの実験では、数年にわたるデータセットでもメモリ使用量は126MB未満でクエリを実行できた。
- 各Lambda関数の最大実行時間は15分に制限される。ただし、よく設計されたクエリはこの時間制限を超えることはない。より長い実行時間が必要な場合は、AWS Fargateを検討してください。
- パフォーマンスはLambdaとAmazon S3の間の転送速度、およびhttpfsのパフォーマンスに影響を受ける可能性がある。パフォーマンスを改善するには、httpfsの使用を避け、代わりにデータをAmazon Elastic File System(EFS)に事前にロードすることを検討してください。
使用シナリオ
- 単一のクエリのデータ量はおそらくテラバイトレベル以内である。
- コストに敏感である。
- データがすでに半構造化または構造化データであり、parquetやjsonデータなどである。
- クエリ実行時間に厳しいわけではなく、数秒または数十秒であれば問題ない。