Athena
Amazon Athena is a powerful, serverless, interactive query service that enables users to analyze data stored in Amazon S3 using standard SQL. It eliminates the need to set up and manage complex ETL pipelines or data warehouses, making it an attractive option for organizations with large amounts of data to process. However, Athena's pricing structure may not be suitable for everyone, especially those on a tight budget. In this blog post, we will introduce some affordable alternatives to Athena that can deliver similar functionality with lower costs.
Advantages:
One of the major advantages of Athena is its ability to analyze data in Amazon S3 using standard SQL queries without the need for complex ETL processes or a dedicated data warehouse. Athena is also serverless, which means that it automatically scales based on the amount of data and the complexity of the query. This eliminates the need for upfront infrastructure investment and provides users with a flexible and cost-effective solution for their data analysis needs.
Disadvantages:
Despite its many advantages, Athena's pricing structure can be a disadvantage for users who have large amounts of data to process. Athena charges users based on the amount of data scanned by their queries, which can lead to high costs if queries are not optimized or if there is a lot of unnecessary data in the S3 bucket. Additionally, Athena's query performance may not be as fast as other more specialized tools that are designed for large-scale data analysis, especially if the queries involve complex joins or aggregations.
Overall, Athena is a powerful tool that can simplify data analysis for many users. However, its pricing structure may not be suitable for all organizations, and there may be more cost-effective alternatives available. In the following sections, we will introduce an alternatives and explore how they can be used to meet different data analysis needs.
DuckDB
DuckDB is a modern, embedded SQL database that is designed to deliver high performance for analytical queries. It is open-source and can be used as a drop-in replacement for SQLite, but with better performance and support for more advanced SQL features. DuckDB is also lightweight and easy to use, making it a good fit for many use cases. In my Athena alternative solution, we will be using DuckDB to store and query data in a serverless environment, making it a cost-effective alternative to Athena's pricing structure.
For more information about DuckDB, please refer its official site.
Lambda
AWS Lambda is a serverless compute service that allows you to run code in response to events, without the need to provision or manage servers. You can write your code in a variety of programming languages, including Python, Node.js, and Java, and Lambda will automatically scale your code in response to the number of events that you receive. This makes it an ideal choice for building event-driven applications and services, as well as for running short-lived or periodic compute tasks. In my Athena alternative solution, we will be using Lambda to run our DuckDB queries, allowing us to benefit from the scalability and flexibility of serverless computing while keeping our costs low.
As we discussed earlier, the pricing structure of Amazon Athena can make it expensive to use for large-scale data analysis. In response to this challenge, I have developed a cost-effective alternative solution that utilizes the power of DuckDB and the flexibility of AWS Lambda. By using DuckDB as our SQL engine and AWS Lambda as our serverless compute service, we can achieve similar functionality to Athena while significantly reducing our costs. In the following sections, we will explain in detail how this solution works and how it can be implemented for your own data analysis needs.
How it work
Here are the steps to my solution:
- Store your structured or semi-structured data in Amazon S3. This data could be in a variety of formats, such as CSV, JSON, or Parquet.
- Use AWS Lambda to run your DuckDB queries. You can write your queries in a variety of programming languages supported by AWS Lambda, such as Python, Node.js, or Java.
- In your Lambda function, use DuckDB to read your data from Amazon S3. DuckDB supports reading data from a variety of file formats, including CSV, JSON, and Parquet.
- Use DuckDB to execute your SQL queries in the Lambda function, completing your data analysis tasks.
With this solution, you can benefit from the scalability and flexibility of serverless computing while keeping your costs low. In the following sections, we will explain each step of my solution in detail, providing examples and tips to help you implement this solution for your own data analysis needs.
Billing Model
The billing model for my Athena alternative solution is designed to be cost-effective for users who need to perform large-scale data analysis tasks on a budget.
When your data is stored in an Amazon S3 bucket in the same region as your Lambda function, you will only be charged for the execution time of your Lambda function, with no additional fees for data transfer or scanning. This can provide significant cost savings compared to using Amazon Athena, which charges for data scanning.
It's important to note that Amazon Athena charges separately for data transfer, scanning, and query execution. As of this writing, the cost for scanning data in Amazon S3 is $5 per terabyte (TB). This can add up quickly for users who need to perform large-scale data analysis tasks.
For users who have experience optimizing Lambda functions, there is also a significant opportunity to improve cost-effectiveness by tuning the memory usage of your Lambda function using tools such as AWS Lambda Power Tuning.
Finally, network data transfer can impact the execution time of your Lambda function, but there are many strategies for mitigating this, such as pre-loading data into Amazon Elastic File System (EFS) or using other optimization techniques.
Implement
To implement our Athena alternative solution using TypeScript and DuckDB in AWS Lambda, we needed to first install the DuckDB Node.js module to be able to use it in our Lambda function.
Additionally, we needed to configure a DuckDB layer for our Lambda function, which provides the necessary dependencies, such as gLibc, and common extensions, such as httpfs and parquet. This allows us to easily read data from Amazon S3 in a variety of formats and execute SQL queries using DuckDB in a Lambda environment.
By using TypeScript, we were able to write our Lambda function in a strongly-typed, object-oriented manner, making it easier to maintain and debug. In the following sections, we will explain how to set up the necessary components for my solution and provide sample code for executing DuckDB queries in AWS Lambda using TypeScript.
IaC
import * as cdk from 'aws-cdk-lib';
import { NodejsFunction } from 'aws-cdk-lib/aws-lambda-nodejs';
import { Construct } from 'constructs';
import { Architecture, Runtime } from "aws-cdk-lib/aws-lambda";
import { aws_lambda } from "aws-cdk-lib";
import { Bucket } from "aws-cdk-lib/aws-s3";
import { BucketDeployment, Source } from "aws-cdk-lib/aws-s3-deployment";
import * as path from "path";
import { PolicyStatement } from "aws-cdk-lib/aws-iam";
export class DuckdbSampleStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const URSA_LABS_TAXI_DATA_BUCKET_NAME = 'ursa-labs-taxi-data';
const duckdbLambda = new NodejsFunction(this, 'DuckdbSampleLambda', {
functionName: 'DuckdbSampleLambda',
entry: 'src/duckdb-sample.ts',
handler: 'handler',
runtime: Runtime.NODEJS_18_X,
architecture: Architecture.X86_64,
memorySize: 128,
timeout: cdk.Duration.minutes(15),
bundling: {
minify: false,
sourceMap: false,
target: 'es2018',
externalModules: ['duckdb']
},
environment: {
URSA_LABS_TAXI_DATA_BUCKET_NAME
}
});
// if region is ap-northeast-1, you can use this layer
if (this.region === 'ap-northeast-1') {
duckdbLambda.addLayers(aws_lambda.LayerVersion.fromLayerVersionArn(this, 'DuckdbLayer', 'arn:aws:lambda:ap-northeast-1:041475135427:layer:duckdb-nodejs-x86:1'));
} else if (this.region === 'us-east-2') {
duckdbLambda.addLayers(aws_lambda.LayerVersion.fromLayerVersionArn(this, 'DuckdbLayer', 'arn:aws:lambda:us-east-2:041475135427:layer:duckdb-nodejs-x86:1'));
}
bucket.grantRead(duckdbLambda);
// can read s3;
duckdbLambda.addToRolePolicy(new PolicyStatement({
actions: ['s3:*'],
resources: [`arn:aws:s3:::${URSA_LABS_TAXI_DATA_BUCKET_NAME}/*`],
}));
}
}
Lambda Code
import * as duckdb from 'duckdb';
import * as util from "util";
import { Handler } from 'aws-lambda';
const db = new duckdb.Database(':memory:');
export const handler: Handler = async (event) => {
const sql = event.sql;
async function executeQuery(query: string) {
console.time(query);
const result = await dbAllPromise(query);
console.timeEnd(query);
return result;
}
const dbAllPromise = util.promisify(db.all.bind(db));
const results = await Promise.all([sql].map(executeQuery));
return 1;
}
Experiment
To demonstrate the effectiveness of our Athena alternative solution using DuckDB and AWS Lambda, we conducted experiments using New York City taxi data. We used the publicly available New York City Taxi & Limousine Commission (TLC) dataset, which contains information about trips made by licensed taxis and for-hire vehicles in New York City. The dataset is available in Parquet format and spans multiple years, with each record containing information such as pickup and drop-off times, locations, and fares. We stored this dataset in Amazon S3 and used our Lambda function, powered by DuckDB, to analyze the data using SQL queries. We compared the performance and cost of my solution with Amazon Athena using the same dataset and queries, to provide a fair comparison.
We stored our New York City taxi dataset in Parquet format, which is a columnar storage format that is designed to provide efficient compression and query performance for large datasets. Parquet is optimized for both analytical and OLAP workloads, making it an ideal format for data analysis tasks. Both Amazon Athena and DuckDB are capable of reading data stored in Parquet format, which allowed us to efficiently analyze the data using either solution. In our experiments, we evaluated the performance and cost of using DuckDB and AWS Lambda as an alternative to Athena, while still being able to take advantage of the efficient storage and query performance provided by the Parquet format.
We will run four different SQL for testing:
SELECT vendor_id, count(*)
FROM read_parquet('s3://ursa-labs-taxi-data/2019/*/data.parquet')
GROUP BY 1;
SELECT passenger_count, avg(total_amount)
FROM read_parquet('s3://ursa-labs-taxi-data/2019/*/data.parquet')
GROUP BY 1;
SELECT passenger_count, extract(year from pickup_at), count(*)
FROM read_parquet('s3://ursa-labs-taxi-data/2019/*/data.parquet')
GROUP BY 1, 2;
SELECT passenger_count, extract(year from pickup_at), round(trip_distance), count(*)
FROM read_parquet('s3://ursa-labs-taxi-data/2019/*/data.parquet')
GROUP BY 1, 2, 3
ORDER BY 2, 4 desc;
Correspondingly, the same SQL is run in Athena, and we have configured year and month partitions in Athena.
SELECT vendor_id, count(*)
FROM "ursa-labs-taxi-data"
WHERE year = 2019
GROUP BY 1
In my experiments using the New York City taxi dataset, we found that my DuckDB and AWS Lambda solution provided cost savings of up to 75% compared to using Amazon Athena. This is despite not optimizing the execution time of our Lambda function, which could potentially result in even lower costs. We focused on comparing the time and cost of executing SQL queries in my solution versus Athena, without any additional optimizations.
My experiments showed that my solution can provide similar query performance to Athena, with query execution times ranging from a few seconds to a few minutes, mostly depending on the data transfer between Lambda and S3. While Athena can provide faster query execution times for certain types of queries, we believe that my solution's lower cost and flexibility make it a viable alternative for many users.
We used Lambda with 128M/512M/832M/3008M memory.
Experiment Result
Duration vs Cost for SQL1
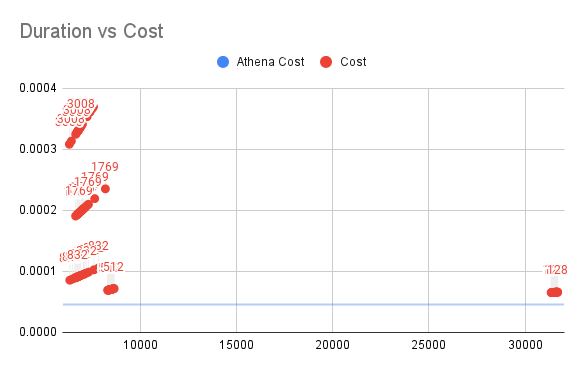
The vertical axis is the cost of Lambda and the horizontal axis is the time of execution.
For SQL1, Lambda always spends more than Athena (blue line in the figure) and takes an exceptionally long execution time of more than 30s in the case of insufficient memory, and it is observed that all 128M of memory is exhausted.
Duration vs Cost for SQL2
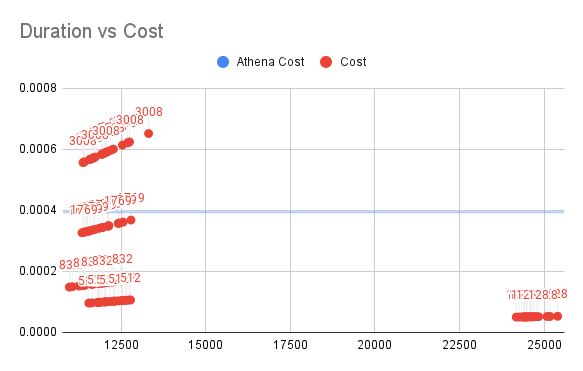
The vertical axis is the cost of Lambda and the horizontal axis is the time of execution.
For SQL2, as the amount of data increases (because there is an extra column involved in the calculation), the price of Athena is around 0.0004, which is less than 50% or even 25% of the price of Athena when we don't waste memory (512M/832M).
Duration vs Cost for SQL3
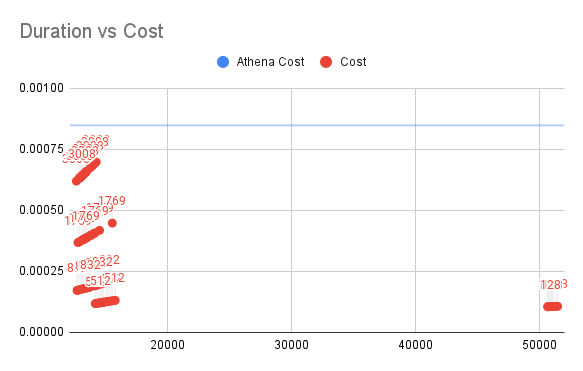
The vertical axis is the cost of Lambda and the horizontal axis is the time of execution.
For SQL3, with the further increase in data volume, my solution costs less than 15% of Athena's in a 512M environment.
Duration vs Cost for SQL4
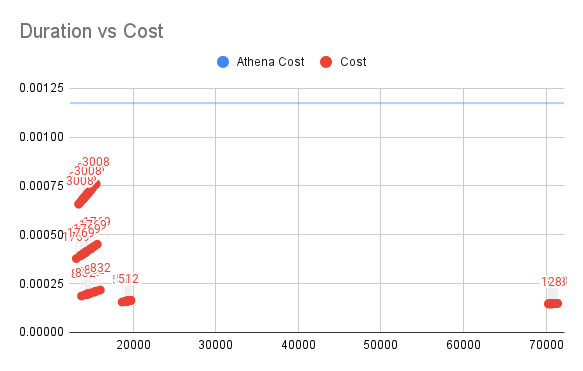
The vertical axis is the cost of Lambda and the horizontal axis is the time of execution.
For SQL4, Athena's price has increased further, but my solution has not changed much. 512M memory Lambda solution costs less than 14% of Athena's
Data Scanned vs Cost
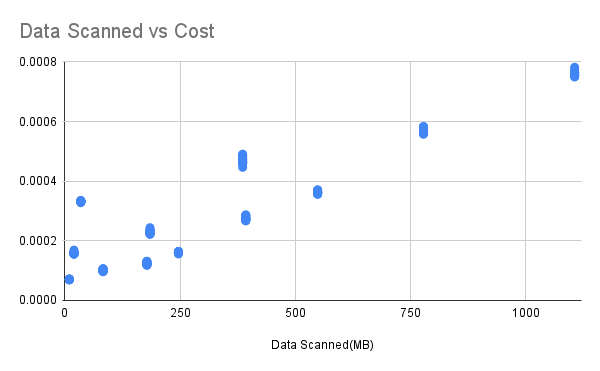
The horizontal axis is the amount of data scanned and the vertical axis is the spend. This is done in a 512M memory environment.
We can know that as the amount of data increases, the spending also increases because the Lambda execution time grows, and the growth of Lamda execution time mainly comes from reading data from S3.
Data Scanned vs Ratio of My Solution spending to Athena spending
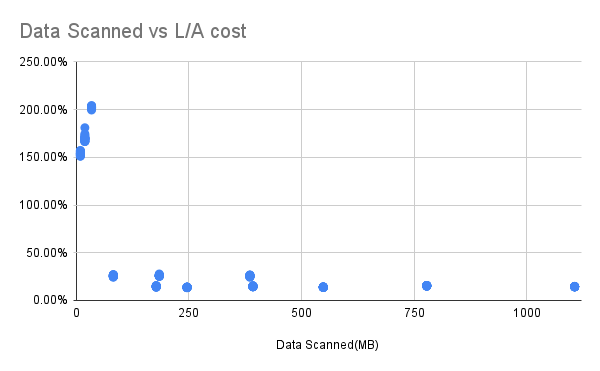
The horizontal axis is the amount of data scanned, and the vertical axis is the ratio of my program's spend to Athena's spend.
This data comes from running SQL1/2/3 and 4 on six months, one year and two years of data, respectively, in an environment that is still Lambda with 512MB of memory.
We can see that there are three stacks on the far left, that is the case of SQL1 running, in this case, the cost is more than 100%, which means that our solution is more expensive than Athena, the possible reason is that when DuckDB in the process of transferring data with S3, although the total data volume is small, but the number of requests needed to transfer does not change. But let's look at SQL1 carefully, this kind of query which is so simple and involves only one column should also be rare.
In cases outside of out SQL1, whether the data is for six months or one year or two years, it is less than 25% or even less than 15% of what Athena spends.
The raw data can be obtained from here.
Conclusion
Pros:
- Cost-effective alternative to Amazon Athena for data analysis tasks.
Cons (possible improvements):
- Limited to a maximum of 10GB of memory usage during computation. However, in our experiments, we were able to execute queries on datasets spanning several years with a memory usage of less than 126MB.
- Limited to a maximum execution time of 15 minutes for each Lambda function. However, well-designed queries should not exceed this time limit. If longer execution times are required, consider using AWS Fargate.
- Performance may be impacted by the transfer speed between Lambda and Amazon S3, as well as the performance of httpfs. To improve performance, consider avoiding the use of httpfs and instead pre-loading data into Amazon Elastic File System (EFS).
Usage scenarios
- single query data volume is probably within the terabyte level
- sensitive to cost
- the data is already semi-structured or structured data: like parquet or json data.
- not demanding on query execution time: a few seconds or tens of seconds makes no difference.