以下の内容は、arXiv ( https://arxiv.org/abs/2404.11584 ) に掲載されている論文
「THE LANDSCAPE OF EMERGING AI AGENT ARCHITECTURES FOR REASONING, PLANNING, AND TOOL CALLING: A SURVEY」を読んだあとにまとめた読書メモ・要約となります。
なお、より詳しい内容にご興味のある方は、ぜひ原論文と、論文内で言及されている文献も合わせてご覧ください。
概要(Overview)
本稿は、人工知能(AI)エージェントの最新の進展を総合的に紹介し、特に複雑な目標を達成する際に必要とされる推論(Reasoning)、計画(Planning)、および ツール呼び出し(Tool Calling) などの能力に焦点を当てています。主な目的は、以下の3点にまとめられます。
- 現在の AI エージェント実装が持つ能力と限界を紹介する
- それらのシステムを実際に使用した際の観察結果や知見を共有する
- 将来の AI エージェント設計における重要な考慮事項を提示する
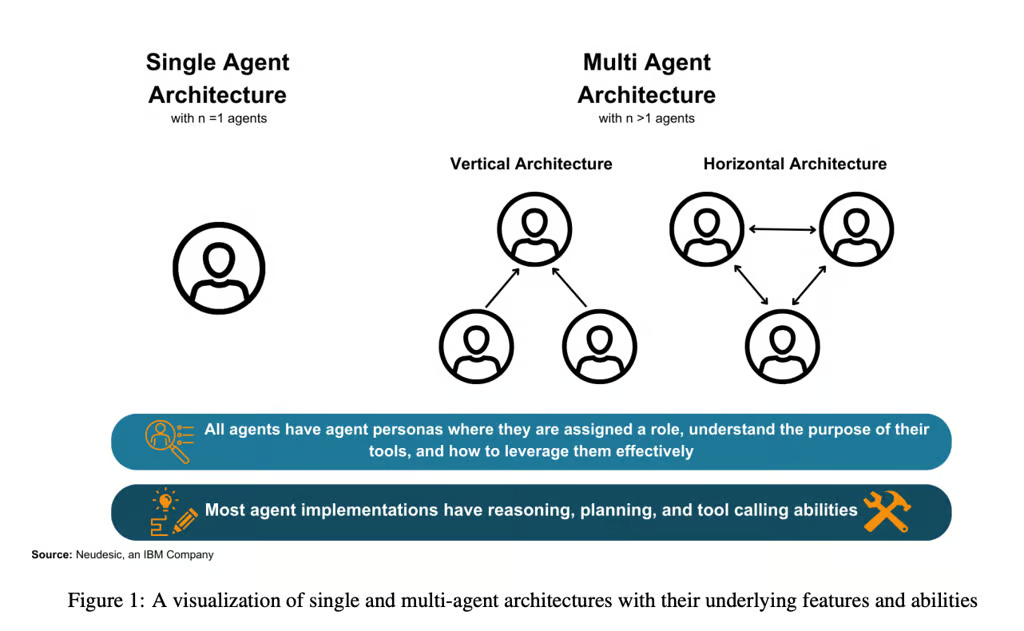
まず、単エージェント(Single-Agent) と 多エージェント(Multi-Agent) の2種類のアーキテクチャを概観し、それぞれの設計上の特徴と差異を整理します。その後、これらがタスク遂行に与える影響を評価し、最終的に、エージェント選択時に考慮すべき主要トピックをまとめます。それには、リーダーシップ(Leadership)の役割、エージェント間のコミュニケーション方法、そして堅牢な AI エージェントシステムを構築するために不可欠な計画・実行・反省といった主要フェーズが含まれます。
AI エージェントの発展とトレンド
ChatGPT の登場以降、AI エージェント技術は急速に注目を集めています。従来の「Retrieval Augmented Generation (RAG)」のような単純な検索+生成モデルと比べ、現在の AI エージェントは、より強力な推論・計画・タスク実行能力を併せ持ちます。これにより、エージェントは従来よりも高度な決定やアクションを自律的に行うことが可能となり、さらに複雑なインタラクションが要求されるシナリオで大きな効果を発揮します。
とはいえ、AI エージェントの最新動向はどのようなものなのでしょうか? 私たちはどのように最適なアーキテクチャを選び、そして将来どのように進化していくのでしょうか? 本稿の後半では、AI エージェントの現状、コアとなる特徴、そしてこれからの展望をより深く考察し、読者の皆様にこの先端技術への理解を深めていただきます。
AI エージェントの分類(Taxonomy)
AI エージェントは、その機能、アーキテクチャ、そして対話形態などによって複数の分類が可能です。以下に主なポイントを紹介します。
-
エージェント(Agents)
- 大規模言語モデル(LLM)をベースにした“知的主体”で、タスクを受け取り、推論・計画を行い、一連の行動を実行できる。
- 単一のエージェントだけで構成される場合もあれば、複数のエージェントが協調して動作する場合もある。
-
エージェント・ロール(Agent Persona)
- エージェントが担う役割や目的、およびツール権限を定義する。
- 例えば「契約書作成エージェント」なら、ドキュメントの編集・査読・メール送信などに関連するツール権限を持つ。
-
ツール(Tools)
- エージェントが呼び出し可能な外部機能を指す。
- REST API でリアルタイムデータを取得する、プラグインを使って文書を編集するなど、多岐にわたる。
-
単エージェント・アーキテクチャ(Single Agent Architectures)
- 1つのエージェントのみで構成されるため、推論・計画・ツール呼び出しのすべてを担当。
- 外部のフィードバックは人間ユーザに限られ、他の AI エージェントからの支援はない。
-
多エージェント・アーキテクチャ(Multi-Agent Architectures)
- 複数のエージェントが同時に存在し、タスクを分担して進める構成。
- 同じ LLM を使う場合もあれば、異なる LLM やツールを使うエージェントを混在させることもある。
-
垂直型アーキテクチャ(Vertical Architectures)
- 複数エージェントの中に「リーダー」的存在を置き、他のエージェントはリーダーにレポートを送る形式。
- リーダーが意思決定やリソース配分の中心を担い、作業を割り振る。
-
水平型アーキテクチャ(Horizontal Architectures)
- すべてのエージェントが同格の立場で、共有環境の下にリアルタイムで議論や情報交換を行う。
- リーダーがいないため、エージェント間で自主的にタスクを取得し合うような形をとる。
このような分類を理解することで、目的や要件に応じた適切なエージェント・アーキテクチャの選定が容易になります。
エージェントを有効にするための重要なポイント
AI エージェントは、大規模言語モデル(LLM)を拡張する形で実装されることが多く、複雑な現実タスクに対応するためには以下の3つの能力が極めて重要です。
1. 推論(Reasoning)
推論は人間の認知において最も基盤的な要素とされ、AI エージェントにとっても同様に重要です。
- 決定・インタラクション:複雑なタスクを多段階で実行する際、適切な推論がなければ整合性が維持できません。
- 動的適応:新しい情報やフィードバックに応じて柔軟にタスク遂行を修正する能力も、推論が担う大事な役割です。
2. 計画(Planning)
推論の成果を具体化するステップが「計画」です。代表的なアプローチは以下の通りです。
- タスク分解(Task Decomposition):大きなタスクを小さなサブタスクに分割。
- 複数プラン選択(Multi-Plan Selection):複数の実行パターンを生成し、最適なものを選ぶ。
- 外部モジュール支援(External Module-Aided Planning):既存のプランナーやツールを活用して効率化する。
- 反省と調整(Reflection and Refinement):実行のフィードバックを受けてプランを修正・強化する。
- 記憶強化型(Memory-Augmented Planning):外部データベースなどを利用して文脈や知識を保持し、長期的な計画に反映する。
3. ツール呼び出しの有効活用(Effective Tool Calling)
多くの研究では、エージェントが「推論→ツール呼び出し→結果検証」を何度も繰り返すことで複雑なタスクを正確に遂行できると示されています([16, 23, 32] など)。
- 単エージェントの課題:タスクのステップ数が多い場合、論理の整合性を保つのが難しくなりやすい。
- 多エージェントの潜在力:各エージェントがサブタスクを並行して処理できるため、効率と堅牢性を高めやすい([22, 6] など)。
単エージェント・アーキテクチャ
主な特徴
単エージェント・アーキテクチャは、一つの言語モデルエージェントがあらゆる処理を担います。
-
利点
- 実装の単純化:管理すべきエージェントが1つだけなので構成が分かりやすい。
- 外部からの干渉が少ない:他のエージェントの誤りなどに引きずられない。
-
課題
- 無限ループ:反省や終了条件が不十分だと、同じ処理を繰り返しタスクを完了できないケースがある。
- 協調不足:多角的なフィードバックや並列作業がほしいタスクには不向き。
そのため、比較的明確な目標や手順があるようなタスク(API 呼び出し、書類自動生成など)には単エージェントが適していますが、長い推論や多人数的な視点が必要な場面では不向きになる可能性があります。
代表的手法
1. ReAct (Reason + Act)
- 概要:エージェントが「思考→行動→結果観察」をループしてタスクを進める。
- 利点:Zero-Shot Prompting よりも正確性が高く、推論過程を記録するため可観測性も向上。
-
弱点:計画や終了条件が不十分な場合、同じ思考や行動を繰り返して抜け出せなくなる。

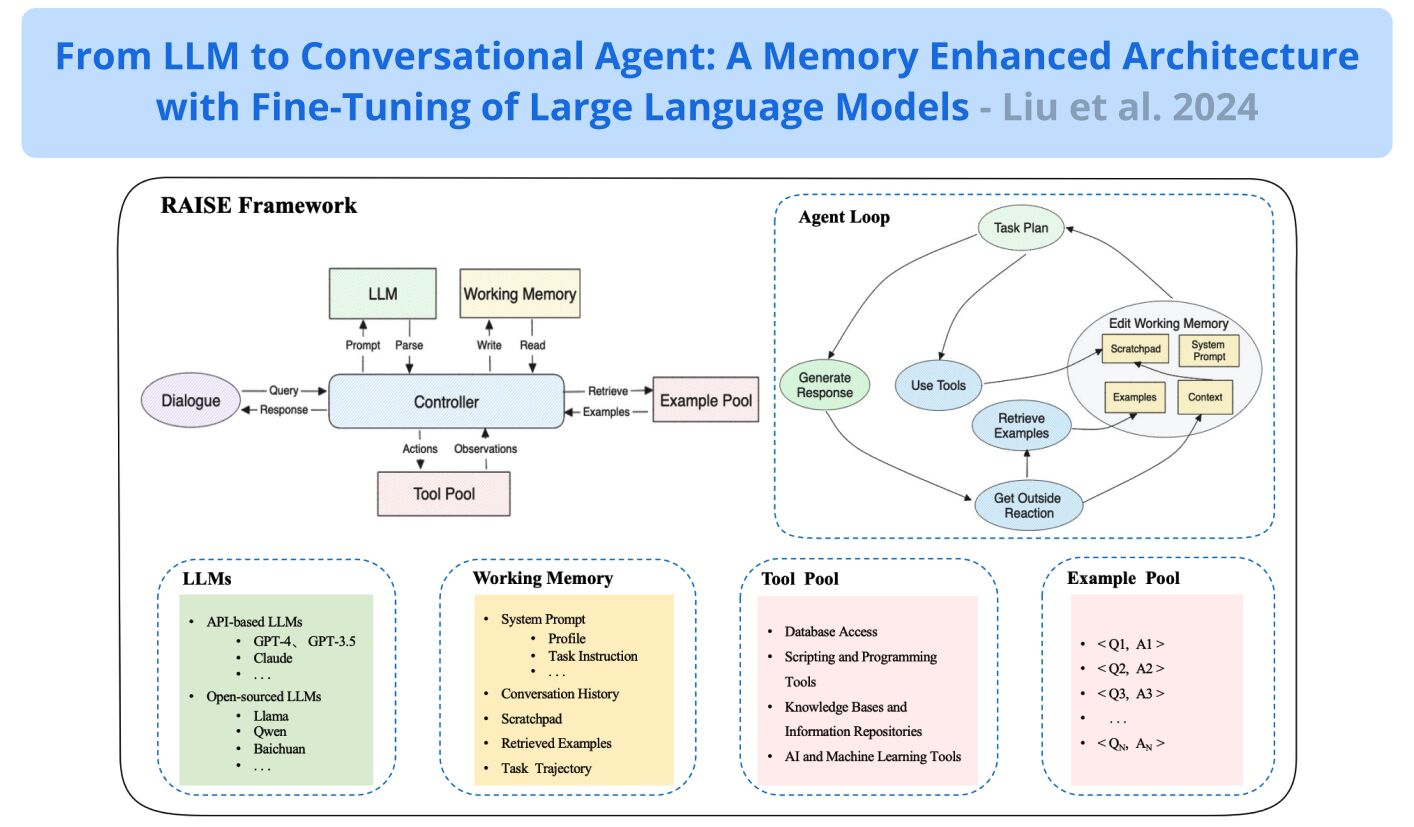
2. RAISE(Memory-Enhanced ReAct)
- 改良点:ReAct に加え、短期・長期記憶を導入してコンテキスト維持能力を高めた。
-
メリット:実行効率と出力品質が向上。ただし、複雑な論理や厳密なロール制限において幻覚が残存する可能性がある。
3. Reflexion(自省ベースのシングルエージェント)
- 特徴:言語ベースのフィードバック(LLM Evaluator)を用い、各ステップで自省(Reflection)を行う [23]。
- 比較:Chain-of-Thought や ReAct よりも成功率が高く、誤り率は低い。しかし、長期メモリの制約など依然として改良の余地あり。
4. AutoGPT+P(プランニング重視の自動エージェント)
- 仕組み:LLM と従来型プランナー(PDDL など)を併用し、部分的な計画失敗時には代替プランを試みる・ユーザに助けを求めるといった柔軟性を持つ。
-
対象:環境探索を伴うロボティクスなど、動的シナリオでのタスク遂行に強み。

5. LATS(Language Agent Tree Search)
- 手法:モンテカルロ木探索を参考に、「状態」を木構造で管理し、言語モデルで推論した手がかりを基に最適なアクションを選択。
- 強み:強力な探索アルゴリズム+自省ステップの相乗効果で多様なタスクで好成績。
- 制限:計算コストやツール呼び出し対応などの面で検証すべき余地が残る。
多エージェント・アーキテクチャ
主な特徴
多エージェントでは複数のエージェントが同時に動作し、役割分担(Role Assignment) や 並行実行(Parallel Execution) を通じて、単エージェントより複雑なタスクにも対処しやすくなります。
- 並行性:複数のタスクを同時に進められるため、速度・堅牢性が向上。
- ロール分化:リーダー、調整役、実行役などを明確にするとチームの効率が上がる。
- 情報共有:適切な通信戦略を用いなければ、雑多な情報に埋もれるリスクがある。
代表的手法
1. 具身型 LLM エージェントのチーム協調
- 知見:リーダー・エージェントがいるチームではタスク処理が約10%短縮されると報告 [9]。
- 構成:リーダーを頂点とする垂直型と、他エージェント同士の自由対話という水平型の両方の要素を組み合わせる。
-
重要性:批判・反省ステップを交えることで、動的にチーム体制を再編し、高いパフォーマンスを発揮。

2. DyLAN(Dynamic LLM-Agent Network)
- 特徴:タスク遂行における各エージェントの“貢献度”を定量化し、成績の良いエージェントを次のラウンドに引き継ぐ。
- 効果:数値推論やコード生成などで性能向上を確認。
3. AgentVerse
- 4フェーズモデル:招集(Recruitment)、共同意思決定(Collaborative Decision-Making)、独立実行(Independent Action Execution)、評価(Evaluation)の繰り返し [2]。
- 利点:各ステージが明確化されており、タスクの進行度に応じてエージェントを追加・削除できる。
-
応用:水平(コラボ向き)・垂直(明確な権限分離向き)いずれも実装可能。

4. MetaGPT
- 課題への対処:複数エージェントの自由対話はノイズが多いため、文書や図などの「構造化された情報」でやり取りする方針を採用 [11]。
- Publish-Subscribe 機構:すべての情報が集約される場所に“公開”し、各エージェントは必要な情報のみ“購読”することで、無駄な会話を削減。
- 成果:HumanEval や MBPP などのベンチマークで、単エージェントを上回る結果を示す。
議論と考察
主な発見
-
単エージェント vs. 多エージェント
- 単エージェント:ゴールや手順が明確で、他のフィードバックをあまり必要としない場面に最適。実装が簡単だが、タスクが長大になるほど限界を迎えやすい。
- 多エージェント:複数視点・並行作業が必要な場面に効果的だが、通信管理・リーダーシップ設定などが難しい。
-
エージェントと非同期タスク
- 単エージェントでも非同期呼び出しはできるが、実質的には逐次計画と実行を繰り返すため真の並行性は得にくい。
- 多エージェントなら本当に別々のスレッドや領域でタスクを走らせられる。
-
フィードバックと人間の監督
- 複雑タスクほど、外部フィードバックによる軌道修正やエラー補正が成否を分ける。
- 現状、多くのシステムで人間が介入できる仕組みを残した方が堅牢性が高いとされる。
-
チーム対話と情報共有
- 多エージェントはチーム内の雑談や無意味なやり取りに陥りがち。
- 資格(Subscribe/Filtering)などの仕組みで必要な情報だけを流通させると効率が上がる。
-
ロール定義と動的チーム
- 単エージェントでもロールの明確化は重要で、エージェントが越権・誤用しないようにする。
- 多エージェントの場合は、リーダー役やタスクの割り当てをはっきりさせることで大幅な効率アップが期待できる。
まとめ
- 単エージェント:明確な役割・ツール設定、人間からのフィードバックを受けながらタスクを段階的に完了する設計が成功の鍵。
- 多エージェント:リーダー役や計画フェーズの設定、動的なメンバー入れ替え、効果的なメッセージフィルタリングなどを用いると、より大規模で複雑なタスクにも対応可能。
- 共通要素:いずれのアーキテクチャでも「明確なシステムプロンプト」「ロール分担」「計画―実行―評価ループ」「外部(人間または他エージェント)からのフィードバック」「ノイズを抑える情報管理」などが性能向上の鍵となる。
研究の制限事項と今後の展望
1. エージェント評価の課題
- 統一基準の欠如:多くの研究が独自の評価データセットやベンチマークを使用しており、横比較が難しい。
- 人工評価の限界:手動スコアリングは品質が高い一方、大規模化しにくく主観的バイアスも入りやすい。
2. データ汚染と静的ベンチマークの影響
- データ汚染:モデルの訓練データに評価セットの内容が含まれている場合、スコアが実際より高めに出る可能性。
- 静的ベンチマークの不足:LLM の進化が速く、既存の固定的なテストセットではモデルの真の能力を測りきれないという問題が指摘されている。
3. ベンチマークの範囲と移植性
- 1ステップ課題中心:多くの NLP ベンチマークが単一ステップの問題を想定しており、ツール呼び出しを含む複数ステップの評価が少ない。
- 領域の制限:プログラミング能力評価ベンチマークなど、特定分野に特化したものが多く、一般的な性能評価は不十分。
4. 実アプリケーションとのギャップ
- 雑多な現実データ:実環境ではデータがノイズを含み、多領域にまたがる。
- 既存テストの集中領域:ゲームや論理パズルを対象とした評価結果が、実際の企業や社会課題に直結するかは不透明。
5. エージェントシステムにおけるバイアス(Bias)と公平性
- 言語モデルのバイアス:LLM は社会的・文化的バイアスを内包し得るため、エージェントとして動作するときにさらに増幅する恐れがある。
- 大規模ベンチマークの欠如:バイアス検出には実際の人間による詳細評価が必要な場合も多く、未だ確立した基準が少ない。
結論と今後の方向性
まとめると、現行の AI エージェント技術は大規模言語モデル(LLM)の上に推論・計画・ツール呼び出しの能力を追加することで、多段階の複雑タスクにも対応できるようになりました。単エージェントと多エージェントのどちらを選ぶかはユースケースによって変わりますが、もっとも性能が高い例では以下のような要素が必ず取り入れられています。
- 明確なシステムプロンプト
- リーダーシップやタスク分担の明確化
- 「計画 → 実行 → 評価(反省)」といった段階的プロセス
- チーム構成の動的制御(必要に応じたエージェントの追加・削除)
- 人間もしくは外部のインテリジェンスによるフィードバック
- 情報フィルタリングや雑音制御の仕組み
一方で、包括的なベンチマークや実環境への適用性、言語モデルが元来内包するバイアスの抑制など、依然として解決されていない課題も存在します。これらの問題を克服し、より信頼性が高く柔軟なエージェントを実現するための研究・開発は、今後ますます重要になるでしょう。本稿で紹介したステップを踏まえつつ、実環境に耐えうるアーキテクチャの模索と評価基準の確立が今後の最前線と言えます。