この記事
インフラエンジニアをやっています。
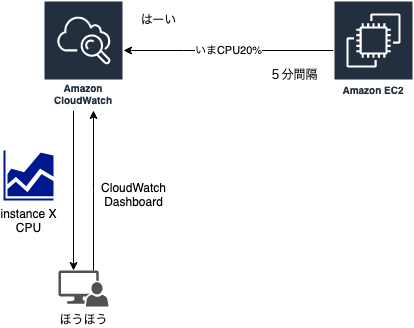
AWSを業務で使い始めて始めにやったことを思い出すと、EC2とCloudWatchでした。
監視ソフトウェアを使わずとも、それこそ最低限の監視であればスッと始められるし料金も知れてるので、今回はその内容を少し書きます。
設計ではなく手法の話になります。
対象読者はAWSを使って監視というものを試したことがない方、あるいはSAA試験対策の一貫になったりするかと思います。
監視の種類
あくまでサーバーの監視ってどんなのだっけ?というお話。
死活監視
サーバー息してる?といういわゆるping応答の監視

リソース監視
リソースという言葉は広い意味で取れるが、例えばCPUやストレージ容量といった基本的なもの
ずっとCPUが90%以上だったら、サーバーが超人気なのか、サーバー内の処理でなにか問題が起きているのか。
ログ監視
Webサーバーに誰かが侵入しようとしていないか?secureログに、大量のSSHアタックの形跡があるかもしれない。
または、アプリケーションのログで実はエラーが流れていて、気づけないかもしれない。特定のログを通知する場合はログの監視が必要
サービス/URL監視
いわゆる外形監視。
Webサーバーのような、Webページを表示するものであれば、そのページが外から開けるのか定期的に確認
サーバーが息していても、サービスは落ちてて503レスポンスで見れていない、なんてケースもある
クラウドならではの監視
コスト監視
AWS料金をサービスごと、リージョンごとに監視し、予算を超えそうならば通知させることで未然に対策を気づいて対策を打つこともできる。
AWS API監視、リソース監視
AWSサービスへのアクセスがいつ、どのユーザによってされたのかをログ証跡として保存、また特定の変更などを監視できる
マネジメントコンソールへのログインも同様
AWS側の障害
AWS側で起きている障害状況は公開されているので、そちらもチェック(監視)する必要があります。
AWSで監視に活用できる身近なサービス
CloudWatch
AWSでサーバーを立てたり、データベースを立てたりするとデフォルトで「メトリクス」が取得できる。
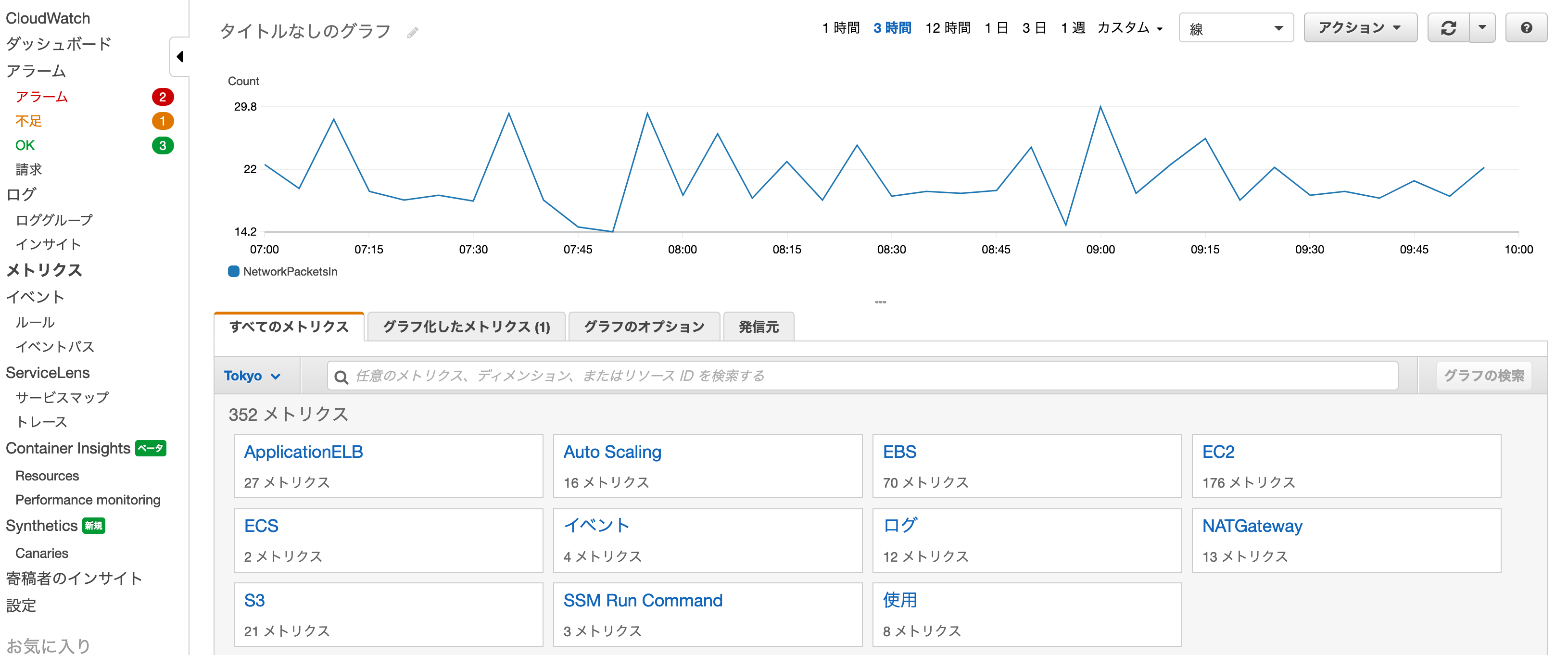 CloudWatch「メトリクス」コンソール画面↑
CloudWatch「メトリクス」コンソール画面↑
メトリクスとは、事前にAWS上のリソースがCloudWatchに発行する各リソース状況の時系列データポイントのこと。
基本間隔は1分または5分で、詳細メトリクスに変更すると秒単位にまで変えられる。
つまり、このメトリクスに対して閾値さえ設定してしまえば最低限アラートを設定することはできる。
また、サーバー内に設定を追加すれば、ログ監視(CloudWatch Logs)をしたり、
標準メトリクスにはない項目をカスタムメトリクスとして作成することもできる。
Config
指定したAWSリソースの設定変更などを監視できる。
例えば、ALBやEC2の開けてはいけないポートを誰かが間違って開けてしまった際に、SNSを使って通知させることや、Lambdaで修正することも可能。
SNS
各アラートを通知するために使用。
アラート用のトピックを作成して、EmailやSlackなど、通知させるエンドポイントをサブスクライブさせる。
CloudTrail
AWSユーザーの使用したAPI履歴を証跡として残してくれる。
例えば、インスタンスを終了したユーザのイベント記録や発信元IPアドレス等を記録している。
認証エラーが起きたら通知することなども可能。
GuardDuty
AWSリソース全体の脅威検知を行う。
各AWSリソースのログを収集して、機械学習を用いて検知してくれるサービスで、有効化するだけで使用可能。
全体といっているのは、我々が使用するクレデンシャル情報等も対象となるため。
※AWS Macieも機械学習を使用したセキュリティサービスだが、主な違いとして
MacieはS3の保護に特化しており、マルチアカウントでの運用でも役立てられるサービス。
やってみる
定番のEC2の監視設定をやってみます。
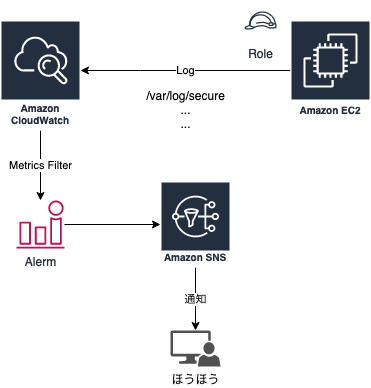
SSHアクセス検知のために、CloudWatch Logsも使って入れ込んでみます。
・CPU使用率が80%を超えたら通知
→リソース監視
・SSHアクセス不可だった場合の通知
→ログ監視
EC2のメトリクスを見てみると
EC2の標準メトリクスはどんな物があるのか見てみる。
AWSコンソールでCloudWatchの画面へ
メトリクス > 検索で、該当のインスタンスidを入れる
おそらくデフォルトだと、14種類くらいのEC2メトリクスが表示される
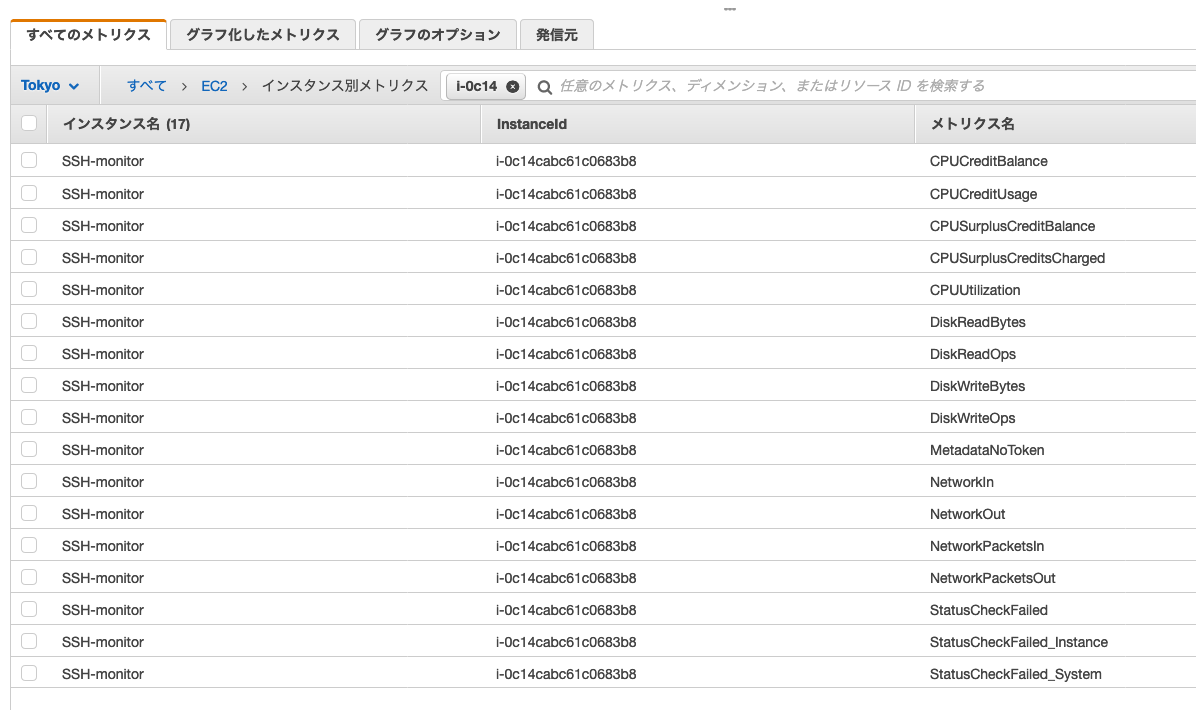
例えばこんなメトリクスが存在します
・CPU使用率;CPUUtilization
・ディスクパフォーマンス;DiskWriteBytes
・インスタンスで受信したネットワークトラフィックバイト数;NetworkIn
Amazon EC2 のモニタリング
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/monitoring_ec2.html
EC2に対するアラームの設定
今回はCPU使用率である CPUUtilizationに対して一定のしきい値を超えたらアラームを設定したいので
アラーム > アラームの作成 > メトリクスの選択で、該当のインスタンスidを入れてCPUUtilizationを選択
デフォルトで5分間平均の値を対象とするのでそのまま。
条件を、「80%よりも大きい」に設定して次へ
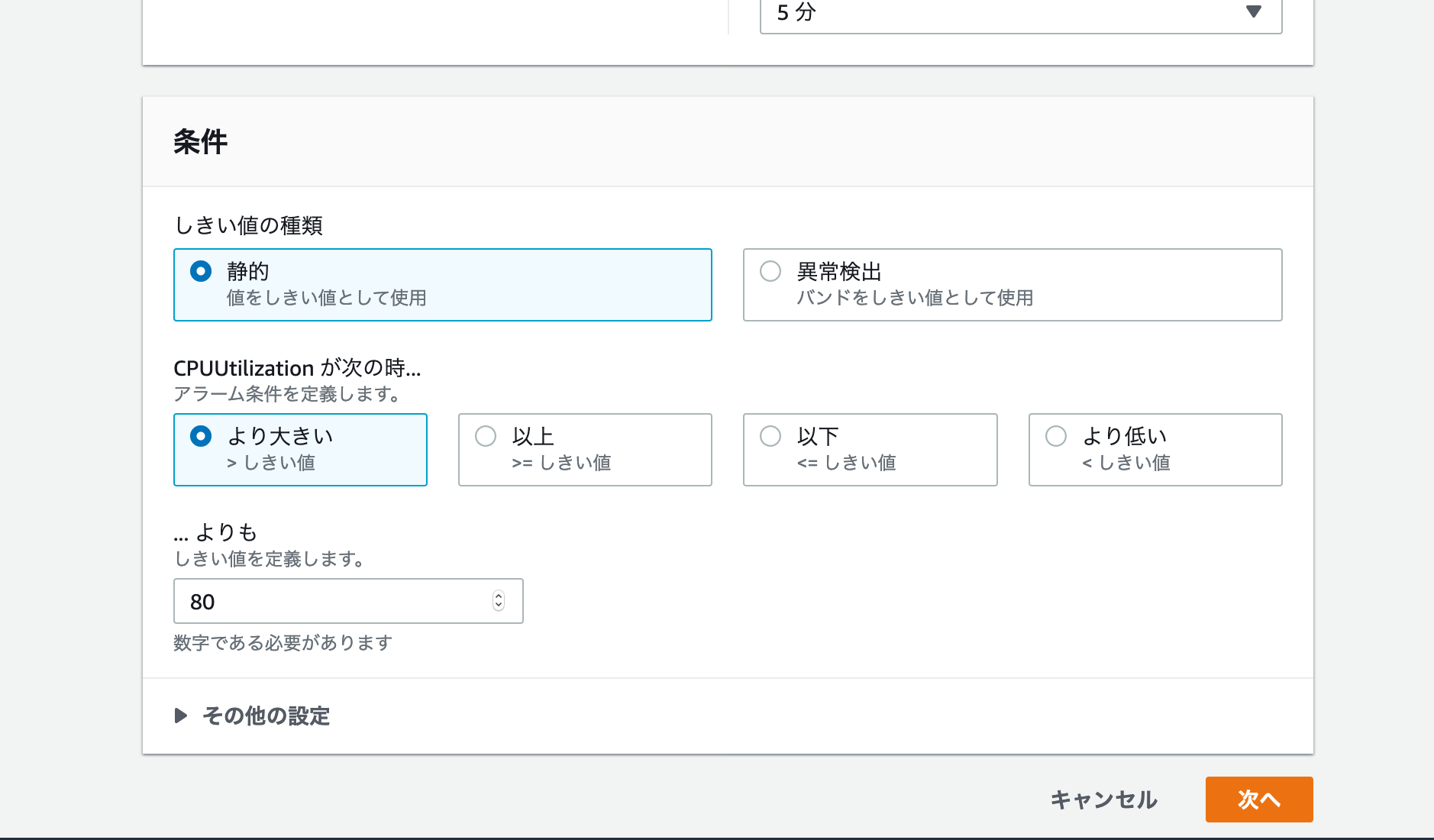
通知に設定するSNSトピックをこの画面から作成できるため、今回用のトピックを作成する
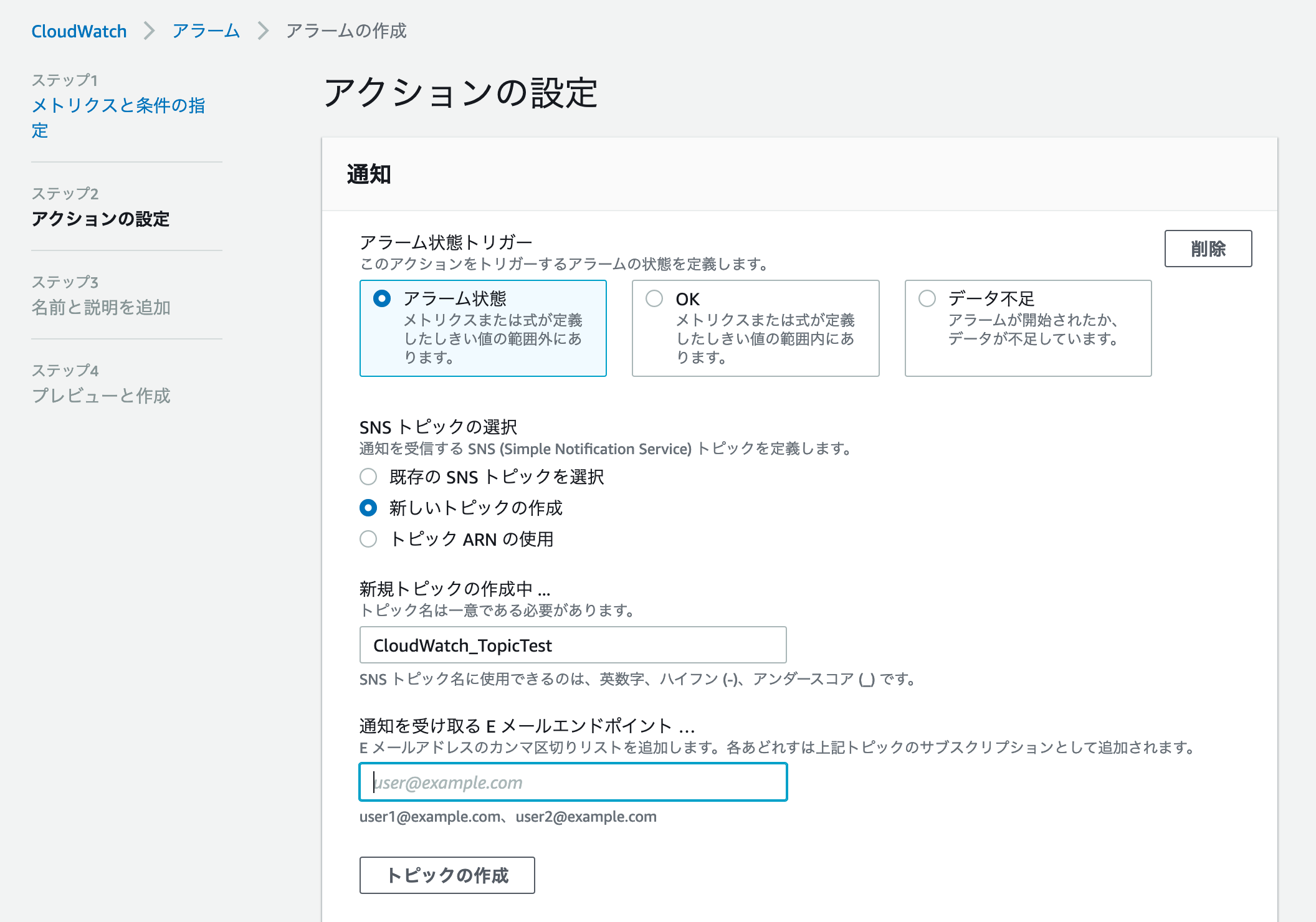
最後にアラーム名をわかりやすい名前に決めて、作成完了。
尚、トピックをサブスクライブしたEmail等で設定確認をする必要があるので、届いたmailを確認しておく

これでCPU監視設定は終わり
SSHの監視
SSHのログは、EC2内の
/var/log/secure
にログが残る。(今回はAmazonLinux2を使用)
CloudWatch Logsに対してこのファイルを配信するように設定して、特定ワードで引っ掛ければ実現できる。
もちろん他の使い方も可能
まず、EC2に対してCloudWatch Logsへの権限を与える必要がある。
AWSのドキュメントでRoleが記載されているためそちらを拝借する
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/QuickStartEC2Instance.html
AWSコンソールでIAM > ポリシーの作成 > JSON
にてJSONを貼り付けて、ポリシーの確認。
名前をつけ、ポリシー作成完了
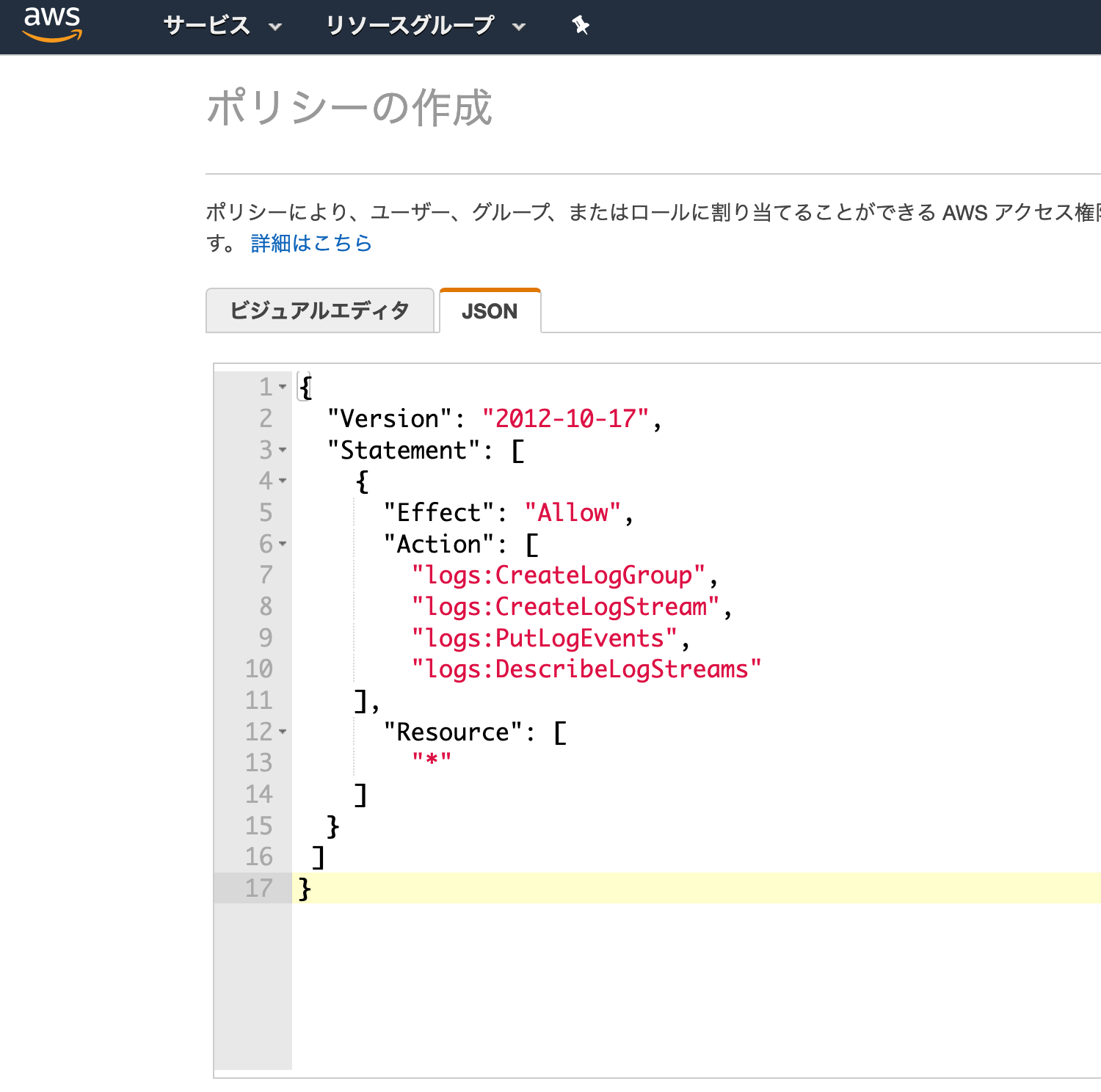
次に、このポリシーのみを使用したRoleを作成する。
IAM > ロール > ロールの作成でEC2を選択
次のステップで、先ほど作成したポリシーを選択
Role名を決めて、作成完了
あとはEC2にRoleを適用
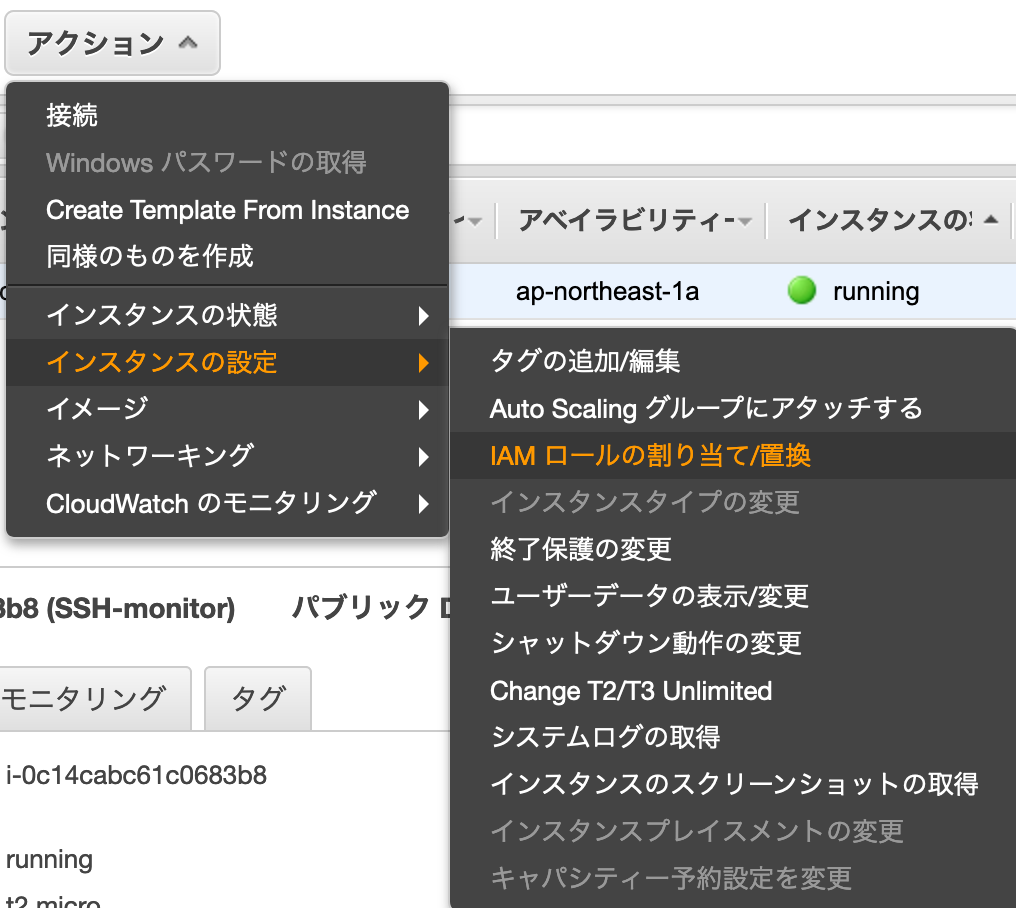
コンソールのEC2インスタンス一覧にて、該当のEC2に対してアクションからRole適用を選択
これでEC2からCloudWatchにログを送る権限はOK
適用したら、実際にEC2にCloudWatchLogsへの仕掛けをいれていく
EC2に入り、awslogs パッケージをインストール
[ec2-user@ip-192-168-2-173 ~]$ sudo yum update -y
[ec2-user@ip-192-168-2-173 ~]$ sudo yum install -y awslogs
設定ファイル/etc/awslogs/awscli.confにて対象のリージョンを指定
[plugins]
cwlogs = cwlogs
[default]
region = ap-northeast-1
/etc/awslogs/awslogs.confにて対象ファイル情報等を設定(追記)
# SSH logs
[/var/log/secure]
file = /var/log/secure
log_group_name = ssh_logs
log_stream_name = {instance_id}/var/log/secure
datetime_format = %b %d %H:%M:%S
ファイルを保存したら、いよいよawslogsを起動して、配信開始!
[ec2-user@ip-10-0-0-229 ~]$ sudo systemctl start awslogsd.service
[ec2-user@ip-10-0-0-229 ~]$ sudo systemctl enable awslogsd.service
Created symlink from /etc/systemd/system/multi-user.target.wants/awslogsd.service to /usr/lib/systemd/system/awslogsd.service.
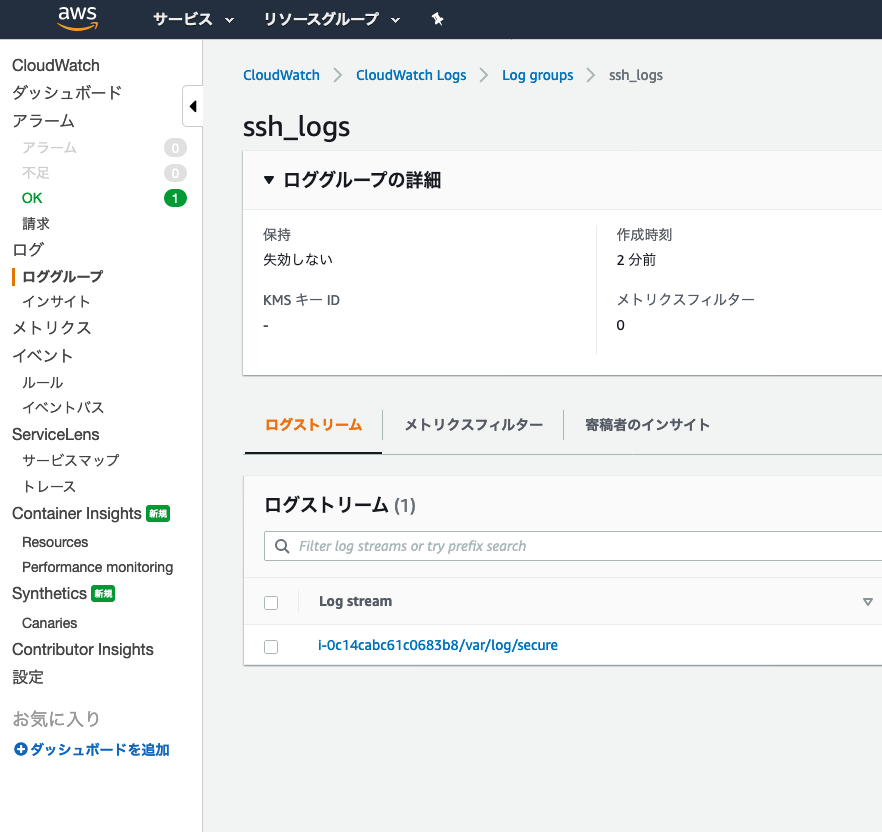
その後、時間が立つとログが確認できるので
CloudWatch > ロググループ > log_group_nameで設定した名前(↑だとssh_logs)
にて、ログが確認
SSH失敗すると、/secureログに
sshd[xxxxx]: Connection closed by xxx.xxx.xx.xx port xxxxx [preauth]
のようなログが出力されますが、今回はそのログに対して
"[preauth]"というワードでフィルタする
先程のロググループの画面にメトリクスフィルタがあるので「メトリクスフィルターを作成」
今回の引っ掛けたい文字列 preauth を設定
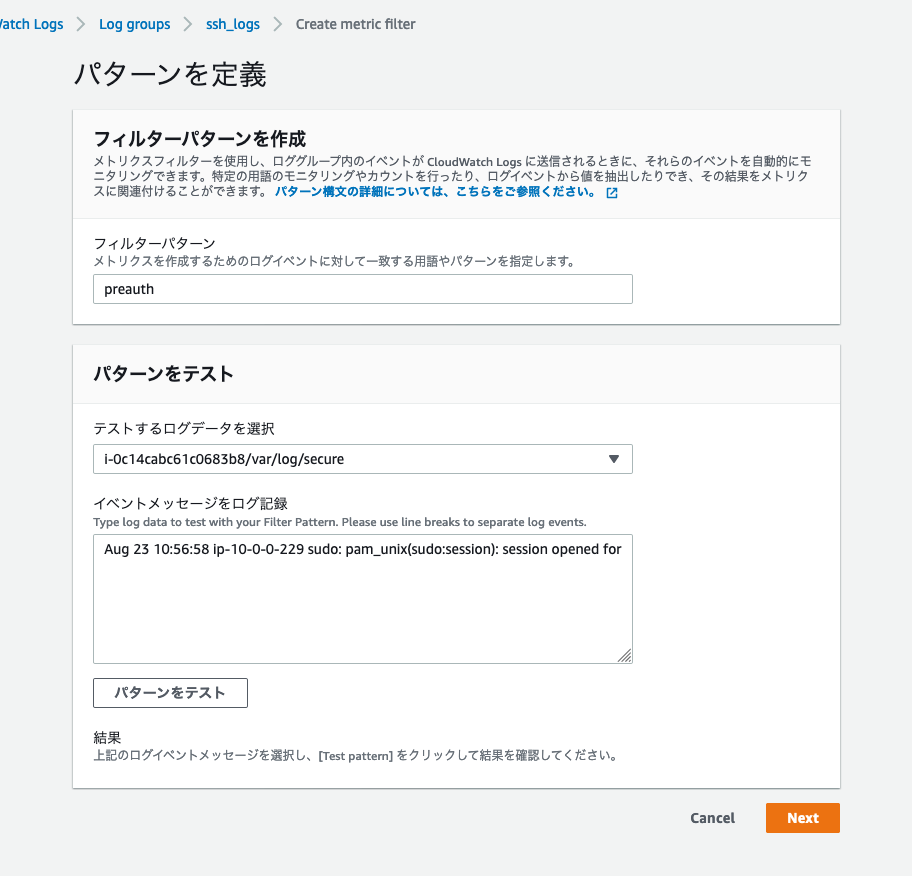
その後フィルタ名などを設定して、完了
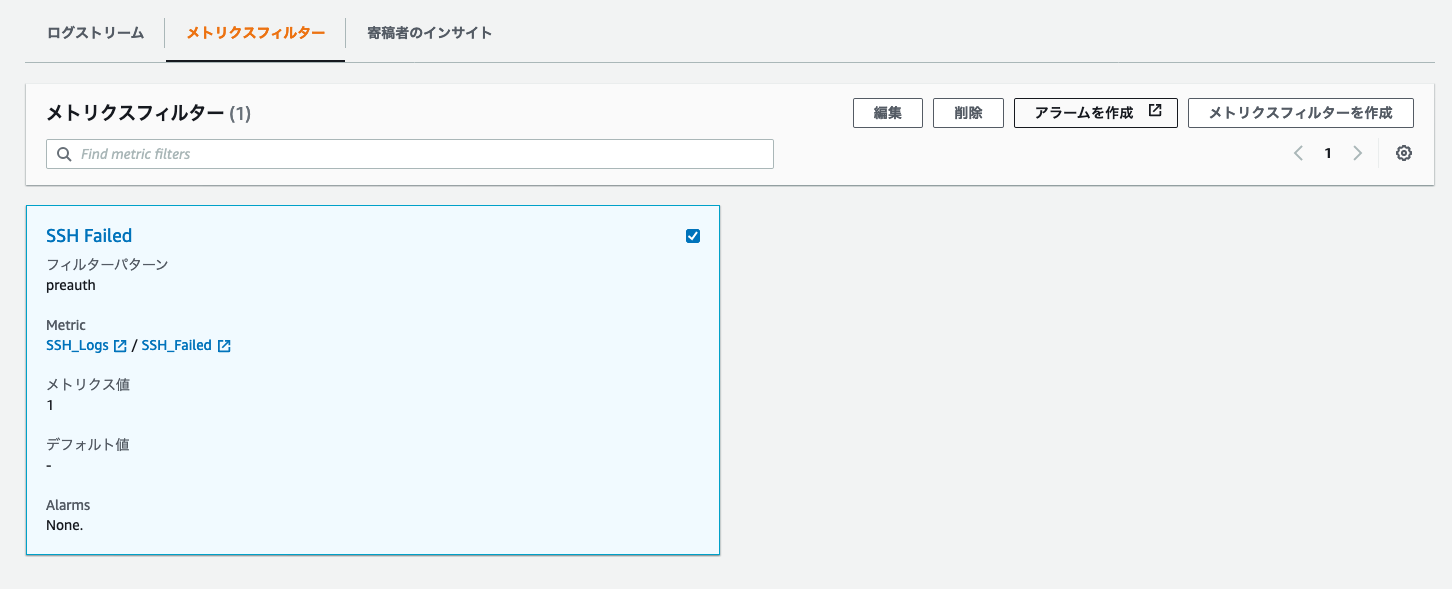
最後に「アラームを作成」から先程と同じSNSトピックに対してのアラームを作成してOK!
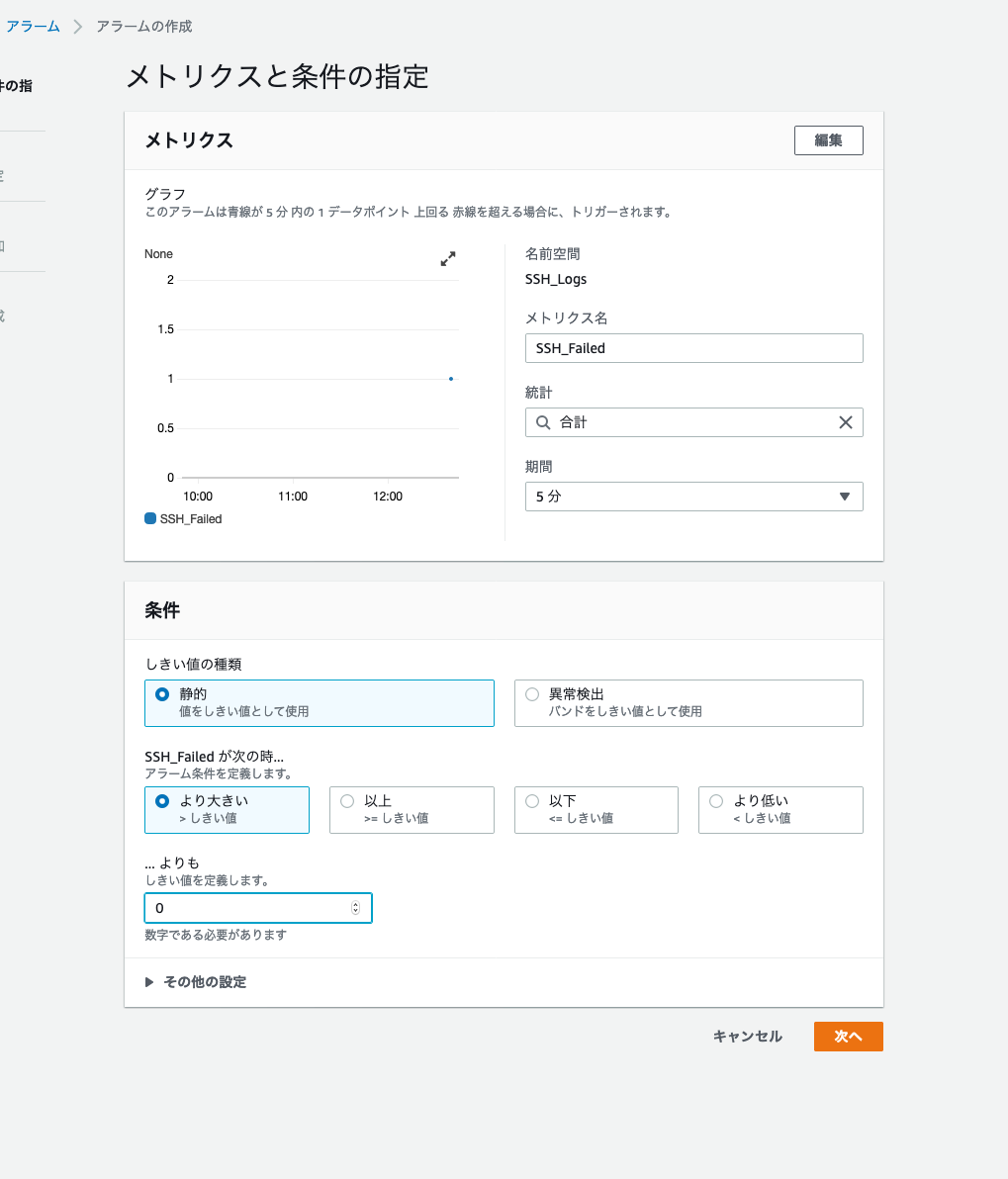
SSHでキーペアなしでテストしたら、
ALARM: "SSH Failed" in Asia Pacific (Tokyo)
みたいなアラートがメール等で届けば確認完了。
まとめ
設定自体はシンプルで、予め用意されているものが多いので、その範疇だと設定はかんたんです。
ただ前提として、監視はこんなもので終わりではなく
・障害となる前に、問題になる傾向を事前検出できるパラメータはどれか
・アラートの閾値は、サーバーの傾向からどの値にするべきか
・企業/プロジェクトの予算に合わせた最大限の監視手法はどの組み合わせか
…
など様々な目線で設計する必要があります。
監視すべきシステム全体を見ると、EC2やECS以外にも、LoadBalancer, RDSなど見るべきリソースはたくさんあります。
前提として
CloudWatchメトリクスは監視する項目すべてを既存のメトリクスでカバーしているわけではなく、
メモリ使用率やプロセスの監視など、より詳細なOSのパラメータを検出する必要がある場合は
カスタムメトリクスを入れ込む必要があります。
今回の例のようなシンプルな監視だったらいいですが、場合によってはコストを考え
MackerelやZabbixといったソフトウェアを導入するほうがコスパが高い場合も大いにあり得ますね。
以上、今回はAWSサービスのみを使って行う監視の、ごく一例でした。
最後に、この記事は後々追記・変更していくと思います。
読んでいただきありがとうございました。