この記事
もやっとしたインフラ知識をスッキリさせていく方針で
Linuxの学習をしており、その記録をしていきます。
今回はLinuxのキャパシティプランニング分野です。
学習ベースは現在LinuCレベル2としてます。
学習に際して詰めが甘い部分もありますが、
Linuxお兄さん目指して精進します。
About キャパシティプランニング
コンピュータリソースは、無限にあるわけではなく
節約してうまく運用していかねばならない
必要なハードウェアやクラウド上のリソースを見積もることが、一般的なキャパシティプランニングを指す
何をするのか
リソースを知る、見積もる
リソースを予想するのは難しく、ピーク時に急激にリソース不足になることもある。
しかし、システム上の各プログラムがどれだけリソースを削るかのデータを収集すれば、将来の負荷をある程度まで見積もることはできる。
リソースの種類
主にCPU、メモリ、ディスクI/Oなどが挙げられる。
他にもネットワークI/O、スワップ利用率など。
Linuxにはこれらを知るためのツールやユーティリティが存在するので、手段を知ることが大事。
リソースを調整する
システム上のリソースを設定調整することで、性能の最適化を目指す。
パフォーマンスチューニングといい、キャパシティプランニングとともに重要なこと。
どうやるのか
システムリソースを知るために、Linuxではいくつかのコマンドが用意されている。
今回は代表的なtopコマンドを見てみる
現時点でのシステムリソースを知る
topコマンド
リアルタイムで実行中のプロセスを表示できる。
※これらはmanコマンドだったり、ググったりすればわかるので、覚える必要はないのだが
一度しっかり見ておくことで「ほー、こんなものなのか」と頭に入れておく
1行目
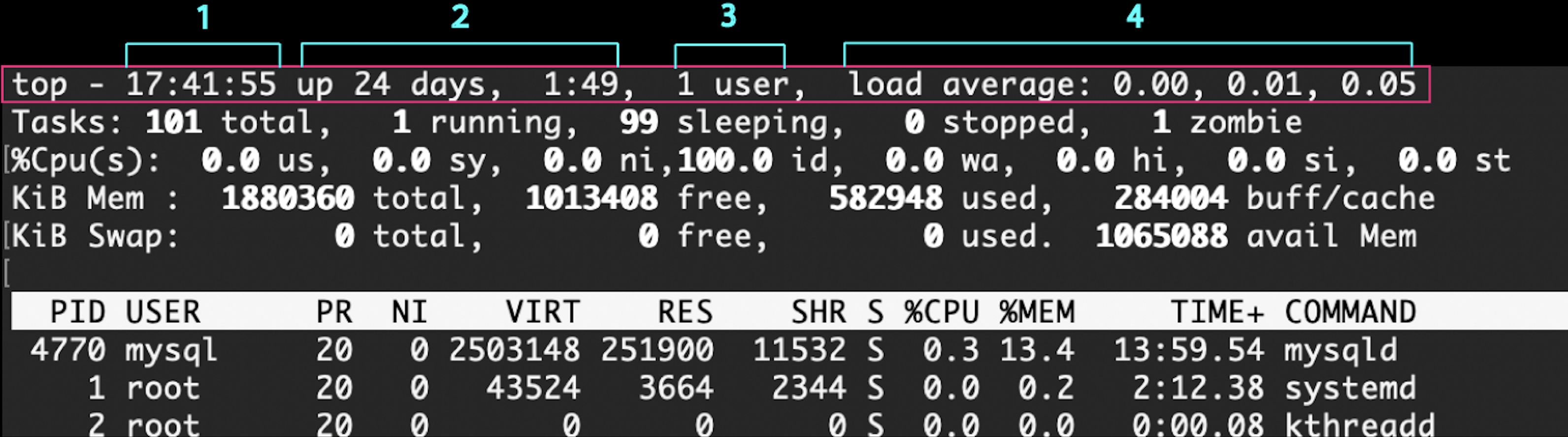
1:現在日時(Linux上)
2:システム起動してからの経過時間
3:ログイン中のユーザー数
4:ロードアベレージ
ロードアベレージは、システム全体の負荷状況。
直近1/5/15(分)の値であり、1CPUにおける(単位時間あたりの)実行待ちとディスクI/Oプロセス数。
つまり、現在動いてるプロセスと待ち状態のプロセスを足し合わせたシステムの負荷数値という感じ
1より高いと処理待ち中のプロセスがいる、のような判断材料。
※値はもちろんCPUのコア数によって違う。
16コアであれば、16.0 = CPU100%が続いた、ということ
ロードアベレージが高いときは、CPU使用率やディスクI/O(Input/Output)を見たりしていく。
勘で動くのではなく、数値計測をして原因を探るためのもの
2行目
プロセスの状態
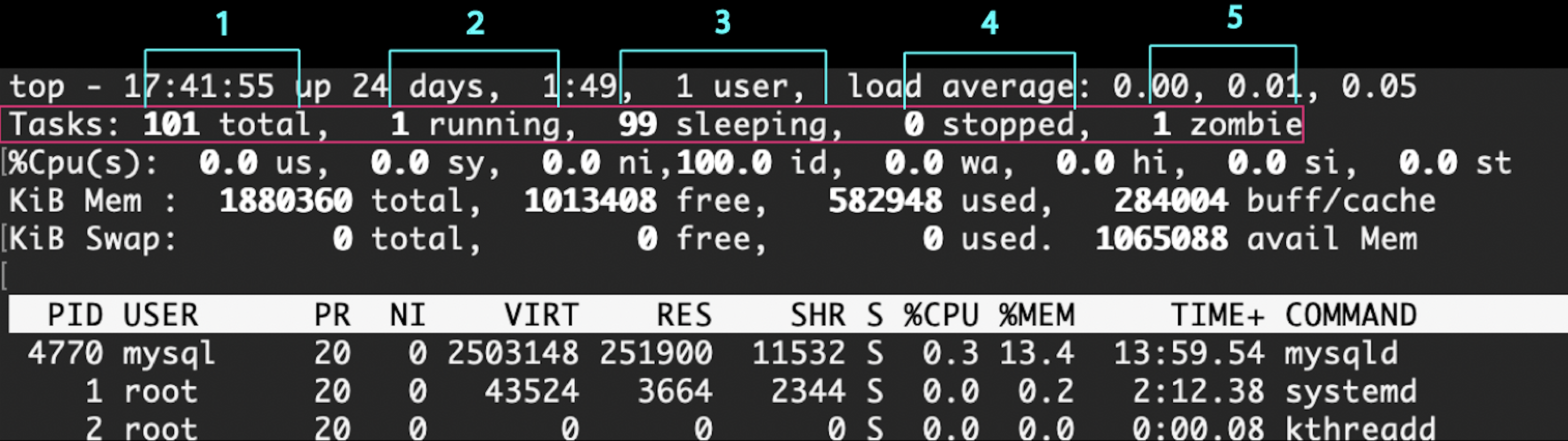
1:総プロセス数
2:実行状態
3:スリープ状態
4:停止状態
5:ゾンビ状態
ゾンビ気になる。
プロセスは、PIDという番号を持っていて、プロセステーブルにエントリがあるが
プロセステーブルに残っているのにその実態が存在しない場合にゾンビプロセスと言われる
ゾンビプロセスのエントリを消すにはkillコマンドでPIDを指定すれば可能
3行目
CPUの状態
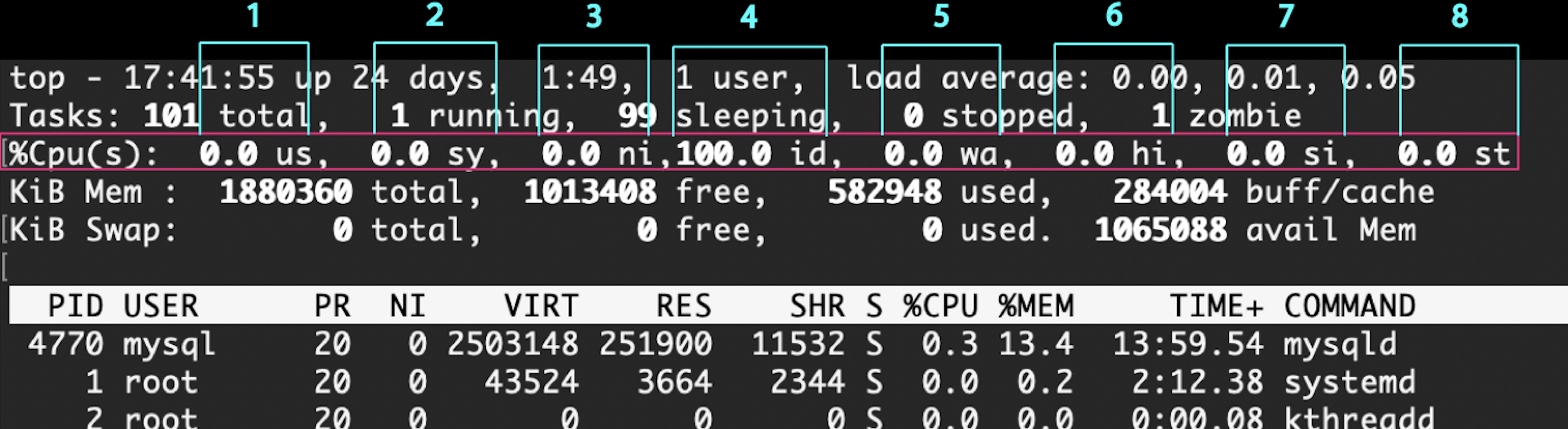
1:ユーザプロセスが、CPUを使用している時間割合
us: user
2:カーネルが、CPUを使用している時間割合
sy: system
3:優先度が変更されたプロセスが、CPUを使用している時間割合
ni: nice
→プログラムを実行する優先度をnice値といい、rootユーザのみが変更できる
4:CPUがアイドル状態の時間割合
id: idle
5:ディスクI/O待ちの時間の割合
wa: io-wait
6:ハードウェア割込み要求時間の割合
hi: hardwareirq
7:ソフトウェア割込み要求時間の割合
si: softwareirq
8:ゲストOSがCPUを割り当てられなかった時間の割合
st: steal
→AWS EC2など、仮想環境でゲストOSが要求しても割り当ててもらえなかったので待機した時間割合
以前、EC2で何故か重くて原因がこいつだったことがあった(T2インスタンス)
T系インスタンスはCPUクレジットが関連することもあり。
4,5行目
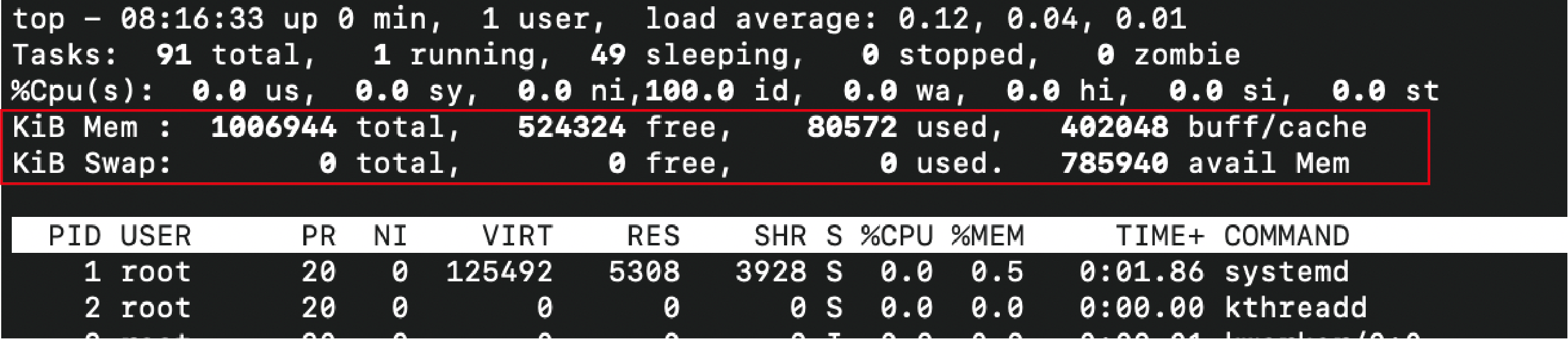
メモリとスワップの状態
4行目は、
全物理メモリ量、空きメモリ量、使用中メモリ量、バッファ/キャッシュサイズ。
5行目は、
スワップ領域サイズ、空き、使用中、メモリ不足時に利用可能な物理メモリ量。
Linuxメモリは、以下のようなものとなる
使用中のメモリ:カーネルが通常利用するメモリ
キャッシュ:ストレージとの高速なI/Oのために使用する
空きメモリ:残っている限り、キャッシュが使用していく容量
スワップ:使用メモリが実メモリ数を上回った際に使用される、ストレージ側の容量。ストレージで使用しているのでもちろんI/Oは遅い
タスクエリア
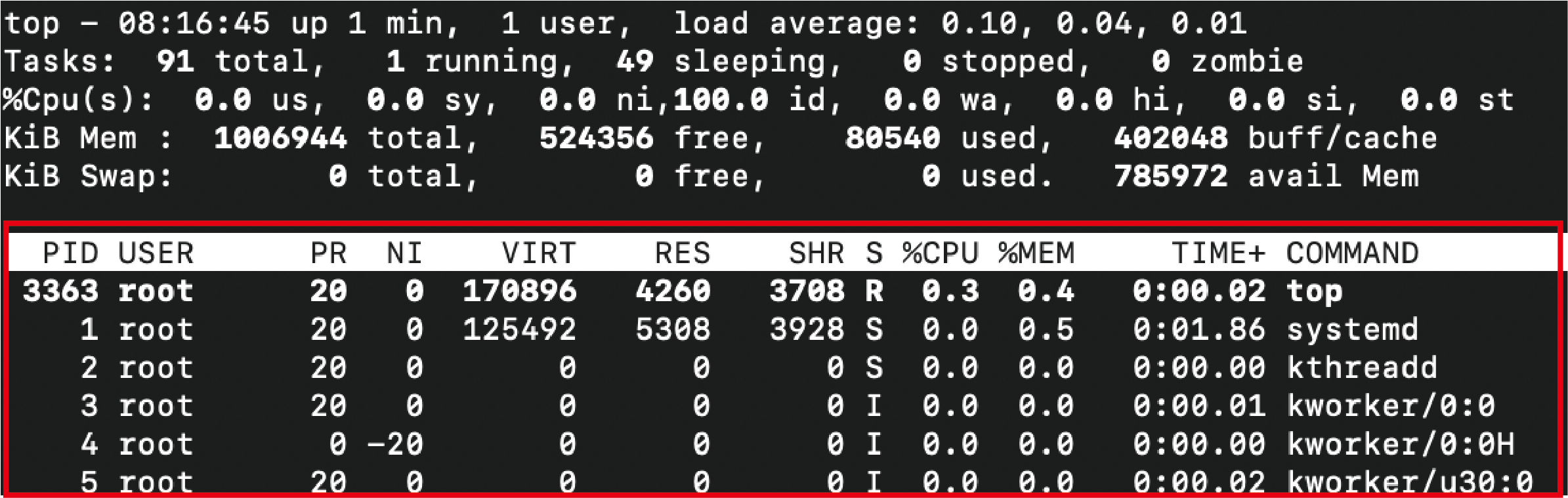
PID: プロセスID
USER: ユーザー名
PR: 実行静的優先度
NI: nice値(相対優先度)
VIRT: 使用中仮想メモリ値(KB)、ただしスワップ含む
RES: 使用中実メモリ(KB)、スワップなし
SHR: 共有メモリ(KB)
共有というのは、他のプロセスとの共有しているメモリを指す
S: プロセスの状態
割り込み不能、実行中、ゾンビなどの状態を文字で表す
%CPU: CPU使用率
%MEM: 物理メモリの使用率
TIME+: プロセス開始からのCPU時間合計
COMMAND: 実行コマンド
このあたりは特に、例えばMac上のアクティビティモニタでも戦闘に表示される内容
(よくブラウザのスレッド数やCPU時間を見て反省する)
topコマンドの表示は、表示やソートを切り替えることが出来る。
メモリ使用率を確認する際に'm'を2度押して、グラフ表示に変えたりしている
デフォルト時
メモリのグラフ表示
'f'を押すと、表示する項目を選択可能になる
他にチェックしたいコマンドとして、vmstat, sar, w等が挙げられる。
リソースを分析する
システムリソースの分析、予測をするためには、これらコマンドの結果を比較したり、よりわかりやすく可視化するために
監視ツールを使用することが一般的である
監視ツールを導入すると、継続的にデータを取得することが出来るため、
キャパシティの限界値に達する前に予測をする事ができるようになる
CPU
平均負荷のみを眺めるのではなく、システム使用率、ユーザーごとの使用率から、
システムのどの部分にCPU負荷がかかっているのかを分析する。
メモリ
稼働時間が長くなるほど空きメモリ自体はなくなるのが一般的であるため、
空きメモリではなくスワップ使用状況なども確認する。
スワップは使用メモリが実メモリ数を上回った際に使用されるため、恒常的に使用されているならば増設が必要。
スワップ領域の確認にはvmstat, freeコマンドを活用できる。
ディスク
I/Oは、パーテイション別に見て特定の部分に負荷がかかっていないか等、ボトルネックを探す。
ディスク容量自体の増加は、アラートを設定しておき、必要なストレージ容量を予測する。
ログファイルがたまり続けていないかなども確認する。
まとめ
今回はキャパシティプランニングについて少しまとめました。
まだあまり使ったことないコマンドもあるので、この記事あるいは別記事に増やしていきます。
次はカーネルについての内容をまとめます。