https://medium.com/aws-activate-startup-blog/scaling-on-aws-part-3-500k-users-3750b227b761#.4c5qe59uq の個人的な翻訳というかメモです。所属する企業や団体における公式見解ならびに公式発表ではございません。
このポストは、ベーシックなアーキテクチャから、どのように何百万人ものユーザー数をもつサービスをサポートできるようなアーキテクチャに継続的に進化させていくかという方法を紹介するブログシリーズのpart 3です。part 1とpart 2では、どのようにスケーリングしてトラフィックを捌くかといったアーキテクチャをAWSのサービスとともに、数万ユーザーに耐えうるレベルまでご紹介しました。このブログポストでは、同じアーキテクチャ上で50万以上のユーザーを捌くアーキテクチャを構築していきたいと思います。
以前のブログで触れた、Auto Scalingのコンセプトがついに動き始めますし、巨大な環境を管理するための自動化やモニタリングサービスもご紹介します。
Auto Scaling
(part 1とpart 2で触れた)コンポーネントを疎結合にし、移行できるものは適切なAWSサービスにワークロードを移した後、Auto Scalingを導入することで、あなたのインフラストラクチャをさらに効率的に管理できるようになります。トラディショナルなインフラストラクチャーの世界では、決まった数のサーバーをプロビジョンする必要がありました。ピークにあわせてキャパシティプランニングをしなければならない、ということです。この方法では、使われていないサーバーに対して無駄なお金をサーバーの調達に使わなければなりません。Eコマースサイトの一般的なトラフィックの推移をみてみましょう。
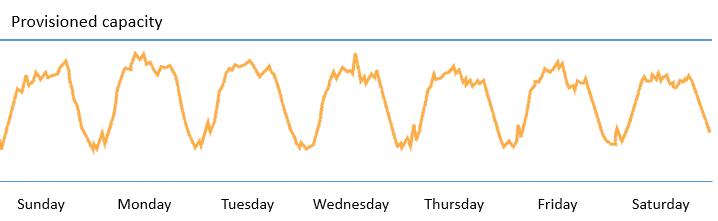
これは一週間におけるよくあるアクセスの推移です。ビジネスオーナーとして、どのように優れたユーザーエクスペリエンスを保証するでしょうか?安全第一でいくのであれば、ピークにあわせてリソースをプロビジョンしてトラフィックがあまりない時間帯においてもアイドルしているサーバーにお金を払い続ける選択をするでしょう。エンジニアを雇って、トラフィックをモニタリングして、負荷にあわせてサーバーを立ち上げたり落としたりすることもできるかもしれませんが効率的ではありません。予想外に午前2時にサーバーが落ちたらどうしますか?エンジニアが問題を対処することを引き換えにどのくらいビジネスに対してネガティブな影響があるでしょうか。AWSプラットフォームでは、Auto Scalingを使えば、自動的にサーバーのメトリクスやtime scheduleそしてunhealthyのホストの置換えを行いながら、サーバーの台数を調整してくれます。この機能はサーバー台数管理の負荷を減らすだけでなく、コスト効率良くサーバーをプロビジョンすることにも繋がります。
どのようにAuto ScalingはEC2インスタンスのグループに対して、自動的なリサイズをアプリケーション層に対して行うのでしょうか?メトリクスもしくはtime scheduleに応じたポリシーを記述することができます。例えば、5分間に渡ってCPUの利用率が60%を超える場合にEC2インスタンスを追加する、といったポリシーです。また、毎朝9時に一定数のサーバーをプロビジョンするような設定も可能です。
これをはじめるにはAuto Scaling groupを作成して、EC2インスタンスをそのグループに入れます。ベースラインとなるパフォーマンス要求とコストコントロールのためにmaximumおよびminimumのインスタンス数をAuto Scaling groupに設定することができます。Auto Scaling group内にローンチするEC2インスタンスのテンプレートを作成するには、インスタンスタイプおよびAmazon Machine Image(AMI)を定義したlaunch configurationを作成します。Auto ScalingにはOn-DemandのインスタンスもしくはSpotインスタンスを利用することができます。On-Demandインスタンスは長期のコミットメント無しで1時間ごとに課金されます。Spotインスタンスは使われていないAmazon ES2キャパシティを活用するために入札制となっていて、多くの場合、非常にコストを抑えた利用をすることができます。
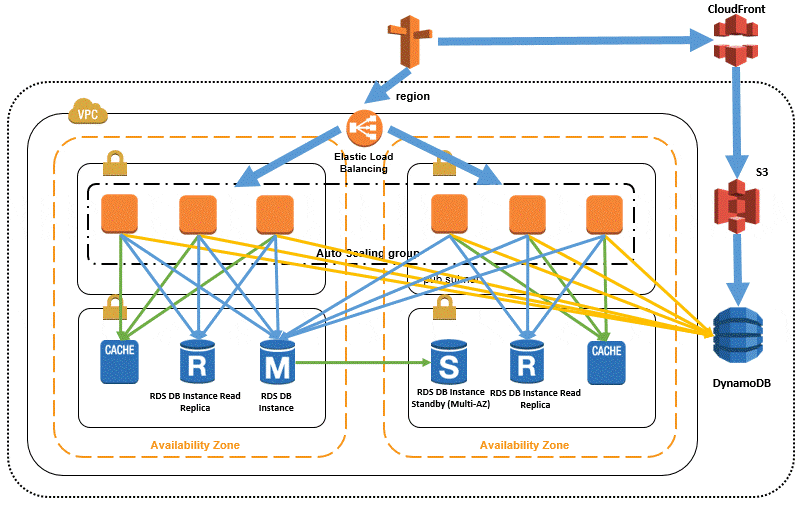
以下の図は、シンプルな単一のアプリケーション層のもので、Auto Scalingを使ってWebサーバーを自動的にスケールさせています。別途Auto Scaling groupを作ってprivate subnetにあるアプリケーション層をそれに適用することもできます。Elastic Load Balancing(ELB)と組み合わせて使う場合、Auto ScalingはEC2インスタンスを付けたり外したりをELBのヘルスチェックを元に行います。トラフィックはhealthyなEC2インスタンスにのみ流れます。
Introduce Automation
あなたの環境がスケールしていくにつれ、手動でそれぞれのコンポーネントを管理するのは非効率になります。手動でデプロイメントする時間だけでなく、ヒューマンエラーをまねくこともあります。アプリケーションのライフサイクルをできるだけ自動するべきです。自動化の利点は以下のようなものが挙げられます。
• 迅速な変化 - Rapid changes
• 生産性の向上 - Improved productivity
• リピータブルなデプロイメント - Repeatable deployment
• 再現可能な環境 - Reproducible environments
• レバレッジの効いた弾力性 - Leveraged elasticity
• 自動テスト - Automated testing
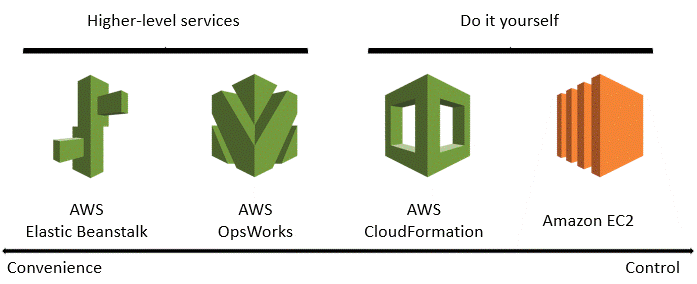
それぞれのお客さまには、それぞれ異なった自動デプロイ手法のニーズがあるため、AWSはサービスを取り揃えていて、最も適したものをお客さまに選択いただけるようになっています。これらのサービスは様々なレベルの便利さや管理を幅広くカバーしています。AWSで自動化を後押しするサービスとしては、AWS Elastic Beanstalk, AWS OpsWorks, AWS CloudFormation, そしてAmazon EC2が挙げられます。
AWS Elastic Beanstalk
AWS Elastic BeanstalkはJava, .NET, PHP, Node.js, Python, Ruby, Goで書かれたコード、そして DockerをApache, Nginx, Passenger, IISといったよく使われているサーバー上に簡単にデプロイできるサービスです。2つのメインなコンセプトとして、environmentsとversionsが挙げられます。Environmentは箱と捉えることができるでしょう。それはあなたのアプリケーションのために自動的にプロビジョニングされたインフラストラクチャーです。Elastic Beantalkでenvironmentを作成すると、load balancingやAuto ScalingもElastic Beanstalkが設定してくれます。
versionはアプリケーションのコードの風味を表します(represents a flavor of って日本語でどういう意味なんだろ…)。コードはS3やGitHubにストアされているものを使うことができます。Elastic Beanstalkをはじめるには、environmentの中にアプリケーションのversionを投入します。シンプルな2-TierなWebアプリケーションでネットワークリソースの設定を行うのでなければ、Elastic Beanstalkは非常に良い選択肢といえるでしょう。
AWS OpsWorks
AWS OpsWorksはイベントドリブンなアプローチでアプリケーションを管理します。Chefのレシピとして環境内の様々な変更をトリガーにした設定を記述できます。ライフサイクルイベントがトリガーされると、ビルトインなレシピもしくはカスタムレシピを実行することができます。それに加えてAWS OpsWorksはあなたのアプリケーションスタックを自動的にヒーリングし、時間やワークロードによるスケーリングを提供し、そしてモニタリングを行うための各種メトリクスを生成します。AWS OpsWorksはAWS Elastic Beanstalkよりも、より詳細に管理を行いたい場合に場合に適していて、より洗練されたアプリケーションのデプロイメントを行う手助けになるでしょう。
AWS CloudFormation
AWS CloudFormationはJSONフォーマットのテンプレートを使ったAWSリソースのプロビジョニングを可能にします。サンプルのテンプレートを使って一般的な構成を構築することもできますし、あなた自身が作ったテンプレートでAWSリソースやアプリケーションに依存のあるものを定義した上で構築することもできます。CloudFormationを使うと、環境を管理そして予測した形で変更することができます。CloudFormationはテキストファイルであり、infrastructure as codeとして日頃使っているバージョン管理システムで扱うことができます。インフラストラクチャーをバージョン管理でき、差分を視覚化でき、既存の継続的インテグレーションや継続的デプロイメントのパイプラインと併せてデプロイを自動化することもできるでしょう。最近、AWSはCloudFormation Designerを発表しました。これによってCloudFormationテンプレートを視覚化でき、drag-and-dropなインターフェースで変更を行うことができるようになりました。
自動的なインフラストラクチャデプロイメントを行う全てのAWSサービスの中で、CloudFormationは最も粒度を細かく管理できるものになります。これは全てのAWSサービスをお客さまに活用しただく後押しとなるものと言えるでしょう。
AWS CodeDeploy
AWS CodeDeployについても言及します。CodeDeployは自動的にコードをAmazon EC2インスタンスおよびオンプレミスで稼働しているサーバーにデプロイするサービスです。AWS CodeDeployは既存のインフラストラクチャにコードを自動的にデプロイするという観点においてAWS Elastic Beanstalk, AWS OpsWorks, そしてAWS CloudFormationを補完するサービスと言えるでしょう。タグを使ってデプロイメントグループを定義でき(例えば、DEV/QA/Staging/Production)、ダウンタイムを最小化するためのローリングデプロイの機能もあります。デプロイメントはAWSマネージメントコンソールおよびAWSコマンドラインインターフェース(CLI), APIそしてSDKを通して、ローンチ、ストップそしてモニタリングさせることができます。
CodeDeployは安全なデプロイメントのコンセプトをサポートします。サービスを正常に保つための最小インスタンス数を明記することができ、もしアップデートに失敗したインスタンスが多すぎる場合はCodeDeployはデプロイを中止します。CodeDeployはデプロイメントの履歴を保持していて、アプリケーションのどのバージョンが現在インストールされているかトラックすることができますし、過去のデプロイの成功率を確認することもできます。デプロイメントのイベントは各インスタンスレベルでトラックすることができます。
CodeDeployはプログラミング言語に依存しないプラットフォームです。設定ファイルを対象のホストにマップします。更に詳細にデプロイメントプロセスをカスタマイズすることができ、例えば“install dependencies”や“stop server”といった具合に各イベントにおけるコマンドを定義することができます。コマンドにはソースコード、スクリプト、カスタムプログラムもしくはマネージメントツールが使えます。
AWS CodePipeline
もう一つのコードデプロイメント自動化ツールとしてAWS CodePipelineが挙げられます。AWS CodePipelineは継続的デリバリー用のサービスで、デプロイメントプロセスをモデリングします。それぞれのステージ - source, build, test, deployment - ごとにカスタマイズ可能で、ソースコードをS3もしくはGitHubから取得します。例えば、sourceステージでは、S3もしくはGitHubからコードを取得します。buildステージではJenkinsやSolanoといったビルドサーバーを使います。testステージでは、BlazeMeter, Ghost Inspector, もしくはもう一度Jenkinsを使ってテストを回します。deploymentステージではElastic BeanstalkやCodeDeployを使います。もちろん全てのステージにおいて自動デプロイメントのプロセスをカスタマイズすることができます。
Using Metrics and Monitoring Tools
計測していないものをより良くしていくことはできません。モニタリングツールを使って内部および外部システムデータを集めることは、システムが想定通りに稼働しているか確認することができます。もし、想定通りでなければ修正しましょう。
内部システムデータは、例えばインスタンスレベルのメトリクスの事を指します。これはインスタンスにおける実際のリソースの消費をアジャストするのに役に立ちます。ロードバランサーから取得できるAggregate-levelのメトリクスはあなたのアプリケーションに対してどれだけアーキテクチャが機能しているかを知る手がかりになるでしょう。外部システムデータはカスタマーエクスペリエンスを理解し、向上させるために活用できます。
以下は取得すべきメトリクスのカテゴリで、いくつかのサービスやツールがそれらを取得するのを可能にします。
• Host-level metrics — Amazon CloudWatchはCPU利用率や、ディスク読込のオペレーション、そしてネットワークトラフィックの出入りのボリュームといったEC2のインスタンスレベルのメトリクスを取得してモニタリングできるサービスです。CloudWatchはまたAmazon Elastic Block Storage(Amazon EBS)ボリュームのメトリクスを取得し、IOPSのアベレージだけでなく、各オペレーションにおけるペイロードサイズのアベレージもとることができます。CloudWatchはカスタムメトリクスを取得し、スタンダートなメトリクスと同じ可視化やアラートの機能を提供します。
• Aggregate-level metrics — Amazon CloudWatchはロードELBロードバランサのメトリクスを取得します。これによってロードバランサに接続された各EC2インスタンスのリソース消費を集計した形でみることができます。例えば、healthy/unhealthyなインスタンスの数、リクエスト数、レイテンシ、レスポンスコード400もしくは500のカウントといったものです。トラフィックがスケールしていくにつれ、ロードバランスをEC2の前に配置する必要が出てきますが、ホストレベルのメトリクスとELBのメトリクスを併せて読むことで、リソースの利用のされ方を把握することができます。
• Log analysis — ログ解析をすることはあなたのワークロードがどのような挙動をしているか深く理解することにとても大切なことです。アクセスを監査し、リソースの利用量をモニタリングし、そしてトラフィックのパターンを理解することができます。例えば、CloudWatch Logsではアプリケーションログの中からエラー数をカウントして、通知することができます。CloudWatchはCloudTrailによってロギングされたAPIのアクティビティをトラックしてアラームを上げることもできます。もし、CloudWatchに機能が足りない場合は、SplunkやSumo Logicといったサードパーティーのサービスを利用することもできるでしょう。
• External site performance — あなたのアプリケーションは最終的にはエンドユーザーに届けるためのものです。もしエンドユーザーがエラーや1つのページを開くのに5分もかかるような事態に遭遇したら、それらの問題をFIXすることにプライオリティを上げるべきです。したがってエンドユーザー目線でシステムのパフォーマンスを理解することは必要不可欠です。例えばPingdomのようなサードパーティーののパフォーマンスマネージメントツールを使えば、uptimeやload timeを捉えることができ、トランザクション、インシデントをモニタリングして通知することができます。
次のポストは最後のポストになるでしょう。継続して何百万人ものエンドユーザーからのトラフィックに耐えるアーキテクチャをご紹介してきます。サービスオリエンテッド(SOA)なアーキテクチャや、巨大なデータセットに適したデータベースのデザインなどの青写真について議論していきたいと思います。
Summary
-
Auto ScalingはAWSインフラストラクチャをスケールさせる最初のステップではありません。しかし、あなたのインフラストラクチャがreadyな状態になれば、Auto Scalingは台数管理のオーバーヘッドを解消し、実際のワークロードの要求に沿った必要十分なサーバーのプロビジョニングを自動的に行ってくれます。
-
AWSはElastic Beanstalk, OpsWorks, CloudFormation, そしてCodeDeployといったサービスを提供することで、ソフトウエアのデプロイメントライフサイクルをあなたのやりたい形で自動化する手助けをします。自動化はデプロイのスピードを上げ、予想可能な結果をもたらし、そして、デプロイメントにおけるエラーを抑制します。これらのサービスは様々な自動化を提供していて、あなたのデプロイメントやスタッフのスキルセットに最も適したものを選択することができます。
-
あなたのアプリケーションにとって、あなたのインフラストラクチャが最適なものになっているか理解するためにメトリクスを活用しましょう。メトリクスはhost-levelそしてaggregate-level(ELBのCloudWatchメトリクスを通して)で取得することができ、全体的な視点でリソースの消費を見ることができます。ログ解析をすることでワークロードの挙動を捉えることができますし、外部メトリクスを使えばエンドユーザー視点でユーザーエクスペリエンスを理解することができ、もちろん必要であれば修正することができるでしょう。