初めまして,自然言語処理の研究をしてる大学院生です.slackに流れてきたので参加してみました.(Advent Calendar初めてです.)ダラダラと書いてしまった気がするので,ここは特に重要と思しきところに*をつけました.(例:一言で言うと*)また,丁寧語を使っているところが自分の所感で,そうでないところが論文の主張です.
一言で言うと*
QAタスクにおいて質問に答えるだけでなく質問を生成するモデルを学習することで複雑な推論(reasoning)を可能にし,QAタスク自体の精度も上がった話
レビュワーのスコアは7,6,8で上から110番目(1,449中)
おそらくacceptされるのではと思っています.
URL: https://openreview.net/forum?id=Bkx0RjA9tX
AnonReviewer2にベタ褒めされてる
1. 導入
1.1. そもそもQAタスクって?*
機械学習分野でのQA(Question Answering)タスクとはコンピュータに自然言語の質問を投げかけてそれに答えさせるタスクのことです.
QAタスクにはいくつか種類があって
- 文章についての質問に答えるDocument QA
- 画像についての質問に答えるVisual QA (VQA)
- 知識ベースを使って質問に答えるknowledge base QA
の3つに大別することができます.(これらの呼び方が一般的かどうか分からないですが便宜上ここではこう呼ぶことにします.)
さらに答えを
- 3,4つの選択肢の中から選ぶ
- 単語やフレーズで答える
- 文章で答える
のいずれかで答えさせるタスクに分類できる.(と認識しています)
この論文で取り組むのはこの中でも
- Document QA + 単語やフレーズを抜き出して答える (SQuAD)
- Visual QA + 単語やフレーズで答える (CLEVR)
の2つのタスク(データセット).
1.2. 問題意識*
例えばVisual QAタスク1で,下の画像が与えられた時,

What colour is this grass?
という質問は,grassは緑色であるという知識を学習できていれば画像を参照しなくても答えることができてしまう.
QAタスクではコンピュータに文章を読ませたり画像を見せたりして読解力や推論力を身につけさせてそれを評価したいのに,この例ではとても表層的な=浅い理解だけで正解できてしまう.
著者たちはこの問題はdiscriminative lossに起因していると主張している.つまりただ"区別"すること(=候補の中から答えを選ぶこと)を学習させるだけでは,コンピュータは(芝生の色 -> 緑)のような質問と答えの簡単な相関関係を学習するだけに留まってしまうという主張.
そこでこれを解決するために,generative lossを使ってコンピュータを学習させた.つまり質問生成タスクを解かせた.
上の例でいうと,芝生の画像と緑という答えを使ってWhat colour is this glassという質問を作らせる.この質問を作るためには,greenという答えだけではglassという単語は出てこないので,画像を参照せざるを得ない.すなわち,質問に答えるよりも質問を生成する方がより推論を要することが想像できる.
さらに質問を生成するときは1単語ずつ予測していくので,many-hop reasoning=多段階の推論を要する.例えば"greenはcolourの一種である","画像にあるgrassのcolourはgreenである","grassにつける指示語はthisが適切",などなど考えなければいけないことがたくさんある.
(論文で挙げられていた画像・文章を参照しなくても答えられる例:

)
2. モデル
2.1. 全体像*
datasetはquestion $q=q_0, ..., q_T$, answer $a$, context $c$ (document or image)からなる.
目的関数は一般的なQAではanswerの負の対数尤度$- \log p(a|q, c)$だが,この研究では1.2.で述べた仮説に基づいてcが与えられたもとでの(a, q)ペアの負の対数尤度
$L=-\log p(q, a|c)=-\log p(a|c) - \sum_t \log p(q_t|a, c, q_0, ..., q_{t-1})$
を用いる.
流れとしては
- まずcをencode(文章にはRNN,画像にはCNNを用いる)
- 次に$p(a|c)$を全てのaの候補をスコアリングすることで計算
- $p(q|a, c)$は条件付き言語モデルでモデリング
- 答えは$p(a, q|c)$が最大になるものを選ぶ.
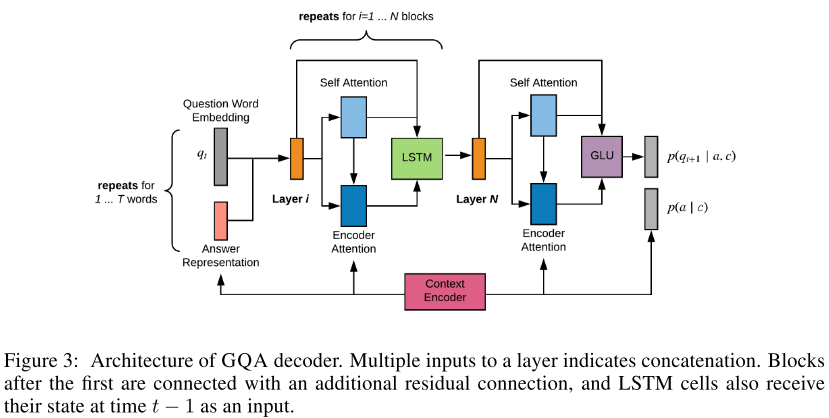
2.2. モデル詳細
Neural Architechtureの詳細はここで説明したところでしょうがない・学びが薄い感があるので軽く触れる程度にします.
-
Document Encoder
-
Answer-independent Context Representation
- LSTM(ELMoを参考にした感じ)
-
Answer Encoder
- 答えは文章中にあるので,上のrepresentationのうち該当するものの重み付き和を学習
-
Answer-dependent Context Representation
- 答えの位置情報を加味してLSTM
-
Image Encoder
- pretrained ResNet-101を使う
-
Answer Prior: $p(a|c)$
- document QAではanswer-independent context representationからanswer候補の初めと終わりの位置のrepresentationを抜き出して実数値のスコアにprojection, さらにanswer候補の長さを加味したスコアを足してsoftmax:
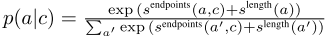
- visual QAではanswer候補の総数次元の空間にprojectしてsoftmax
- document QAではanswer-independent context representationからanswer候補の初めと終わりの位置のrepresentationを抜き出して実数値のスコアにprojection, さらにanswer候補の長さを加味したスコアを足してsoftmax:
-
Question Decoder: $p(q|a, c)$
2.3. Fine Tuning
teacher forcingのみで訓練したモデルはnegative sampleに遭遇したことがないのでテスト時にパフォーマンスが落ちる可能性が高い
そのためquestion answerペアの尤度p(q, a|c)をanswer候補100個の中で比べたて正解のanswerが与えられた時に最大化するように以下の値を最小化してfine-tuningする
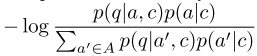
2.4. Inference
テスト時はanswer候補全てのp(a|c)を計算したのちにp(q, a|c)を最大にするaを返す.
$a^* = argmax_a ~ p(q|a, c)p(a|c)$
しかし全てのanswer候補について計算すると時間がかかってしまうので,beam searchを行う.
answer spanの長さが30以下のものに絞りp(a|c)が高い方から250を選んでp(q, a|c)を計算する.SQuAD Validation setではbeamに正しい答えが入っているものが98.5%以上.
3. 実験
3.1. Document QA*
Document QAのデータセットにはSQuADを用いる.
discriminative modelに匹敵する精度
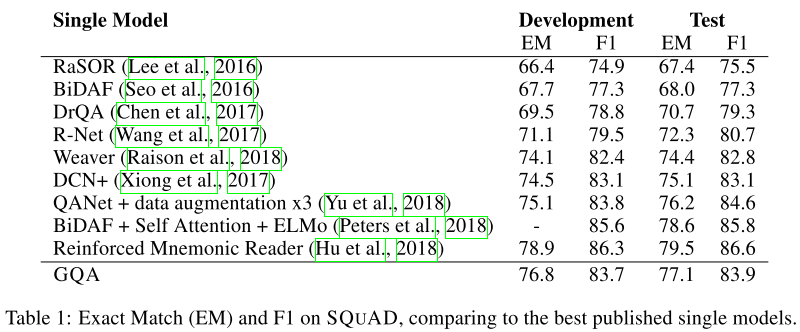
↑ensembleやdata augmentation, reinforcement learningと提案手法は互いに競合していないので適用すればさらに精度は上がるかも
ablation↓
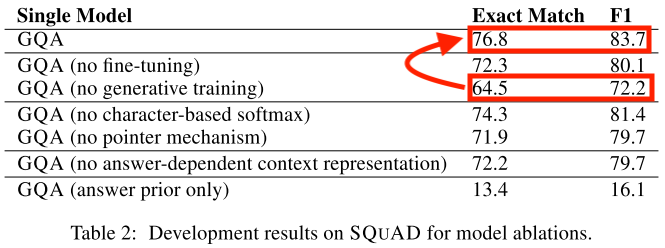
↑character-based softmaxやpointer mechanismによってrare word対応しないと精度が落ちる
↑fine-tuningなども大事だが,何よりgenerative trainingをしたことによる精度向上が大きい.(64.5 -> 76.8)
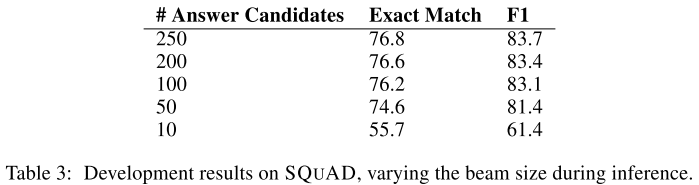
↑当然だがanswerのbeam searchはbeam sizeが増えれば計算コストが高くなる
3.2. Multihop Reasoning
multihop reasoningができているかをCLEVRデータセットで検証した.
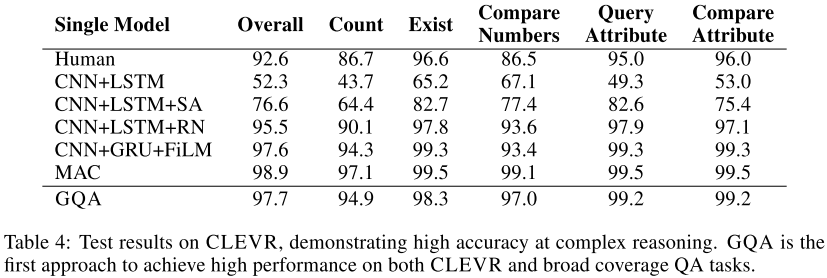
CNN+LSTM+SAがVisual QAのstandard modelらしいのだが,それに比べて精度が良い
MAC cellやFiLM layerにもGQAは応用可能だが試してはいない.
(CLEVRで精度が良い=>multihop reasoningができたと言って良いのか?という疑問は残ります.)

question wordを予測するときの画像へのattentionの様子の違い
(右から2つ目の例をみると,leftの概念がわかっているのかも・・?という気がします)
3.3 Learning From Biased Data*
document QAで,whenから始まる質問が聞かれているけど文章中にdateが1つしかないから大した読解をしなくても事実上whenとdateを見るだけで答えられる,というような問題がある.
そこでnamed entity typeごと(numbers, dates, people)にSQuADからsubsetを作った
それぞれのnamed entity typeが1度しか文章に含まれないものを集めてきて,これでモデルを訓練する.一方で評価にはそれぞれのnamed entity typeが複数回文章に含まれるものを使う.
つまり,単にwho->people, when->dateのマッチングをするだけでは解けない問題をつかって評価するのでmultihop reasoningできないと解けない.
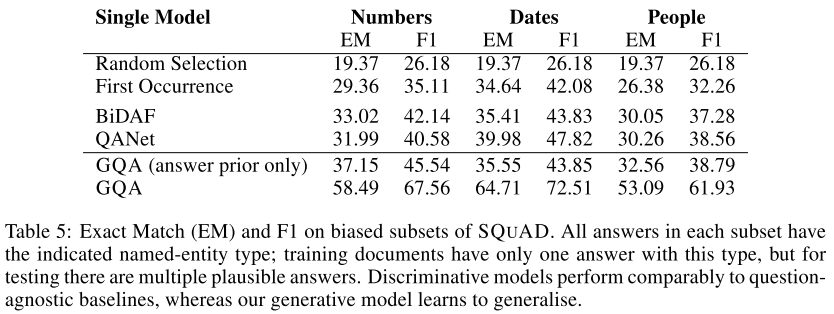
このTable 5の結果がすごくて,従来精度が良いとされていたQANetやBiDAFを提案手法のGQAが大きく上回っています.QANetなどが浅い理解しかできていないのに対してGQAはもっと複雑なreasoningができると言えそうです.
3.4. Adversarial Evaluation
Adversarial attackに対してGQAがもっともrobust
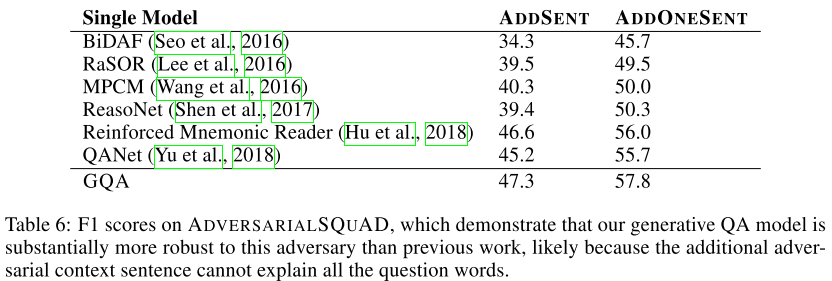
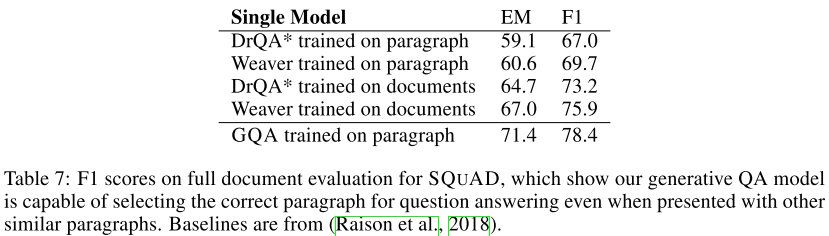
3.5. Long Context Question Answering
multi-paragraph settingでも実験
感想
自分の研究と似ていたから選んだのですが,ひやひやしながら読みました.自分の研究と着眼点は違うものの素直に面白くて悔しいです.
$a^* = argmax_a ~ p(q|a, c)p(a|c)$
のようにgenerative lossを組み込んだところが斬新で面白いと思いました.
著者たちがときたい問題の最も簡単な例がはじめにあって分かり易かったし.
微妙なのはやはりp(a|c)の精度がbeam sizeに依存していて,(aの候補の数だけqの尤度を計算する必要があるから)計算コストがかかるところかなあ.
SQuADでBERTが人間を超えたとして注目されていますが実は3.3で述べたような浅い理解しかできていない可能性はあるのでリーダーボードでの精度という一面的な評価だけでモデルの良し悪しを測らないよう注意したいところです.その点でgenerative learningによってmultihop reasoningのようなものができている(Figure 4やTable 5)というのは本質的に良い方向に向かっている気がします.
これだけシナリオがしっかりしてて実験もやることやってればこれくらいのスコアがつくのかーという気持ちになりました.精進して行きたいです.
(初めはVAEのposterior collapseに興味があってLagging Inference Networks and Posterior Collapse in Variational Autoencodersも読んでいたので機会があれば紹介します...)
おかしいところがあれば遠慮なく指摘してくださると幸いです.
-
Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C. Lawrence Zitnick, Devi Parikh, and Dhruv Batra. Vqa: Visual question answering. Int. J. Comput. Vision, 123(1):4–31, May 2017. ISSN 0920-5691. ↩
-
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. In Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, pp. 2692–2700, 2015. ↩
-
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, 4-9 December 2017, Long Beach, CA, USA, pp. 6000–6010, 2017. ↩