スクレイピング・ハッキング・ラボ 躓きポイントメモ
この記事では、私が2021年頃に買ったスクレイピング・ハッキング・ラボ を、今更やっている私が、情報が古くなっているがゆえに上手くいかなかったことに対するメモです
もしかしたら私と同じように躓いている人がいるんじゃないかなと思って、軽くメモを残しておく
本を持っている人向けなので、ここを読むだけでは全く何を言っているのか分からないと思うけど、その分本を持っている人だとちゃんと分かるように意識して書いているつもり
2022年4月に内容を改定しているらしいけど、私が持っているのは初版のバージョンなので、最新のものだとこの辺りはクリアされている可能性はあり
タイトルに書いてる数字(7.2 など)は、私の本のチャプター番号(=詰まった箇所のチャプターの番号)と一致しているので、検索などに利用してください
私の動作環境
OS: windows 10 Pro(英語版インストール)
OS cersion: 22H2
processor: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz 2.59 GHz
System type: x64 based processor
居住地: ドイツ
IDE: PyCharm 2023.3.5 (Community Edition)
プログラミング歴: 2014年~
好きな言語: Java
はじめに気を付けるポイント
この本は、基本的にJupyterLab を使用しているので、function定義などを行っていない
もし、JupyterLab以外のIDEを使うのなら、def 定義とmain定義を行うことを忘れないようにした方がいい
repositoryを公開しているので、参考にしたいだったり、全コード見てみたいなどありましたら見て下さい。ただし、あんまり親切設計にはしていないから、ファイル探したりなんかはやりにくいかもね
https://github.com/shino51/ScrapingHackingLab
第6章
6.1 reppyのインストール
クローリングの為にreppyをインストールしようとしたら、"Microsoft Visual C++ 14.0 or greater is required" とメッセージが出たので、面倒だけどインストールしておいた。(ダウンロードのurlはエラーメッセージが出てくる時に出てくるからそこからインストールした)
正直、この本のハンズオンするためだけにこれをインストールしなきゃいけないのはかなりストレス…
面倒だけどC++のコンパイラーをインストールして、reppyのインストールにまた挑戦したけど、出来ない…。どうやら、reppyはPython 3.10だとインストール出来ないらしい。
なので、Pythonのバージョンをダウングレードする必要があった!
本では、当時の最新である3.8を使っていたので、3.8にしてみたらやっとインストール出来た…!
ちなみに、.venvを使っている場合、C++をインストールした時に.venvを一度deactivateしたうえでもう一回activateしないといけなかったし、.venvのpythonのバージョンを変える為には、一回.venvを消す必要があった(多分どっかに設定があったんだろうけど、面倒臭いので削除で対応した。笑)
第7章
7.2 Chrome Driverのインストール
Windows を使っているので、ChromeDriverのインストールをしなければいけないということで、早速 ChromeDriverのダウンロードサイト へ。早速本に載っているURLと違っているので注意。
私の使っているChromeのバージョンは123.0.6312.59
ダウンロードサイトには、バージョン115よりも新しいバージョンを使っている人は the Chrome for Testing availability dashboard に行けと書いてある。
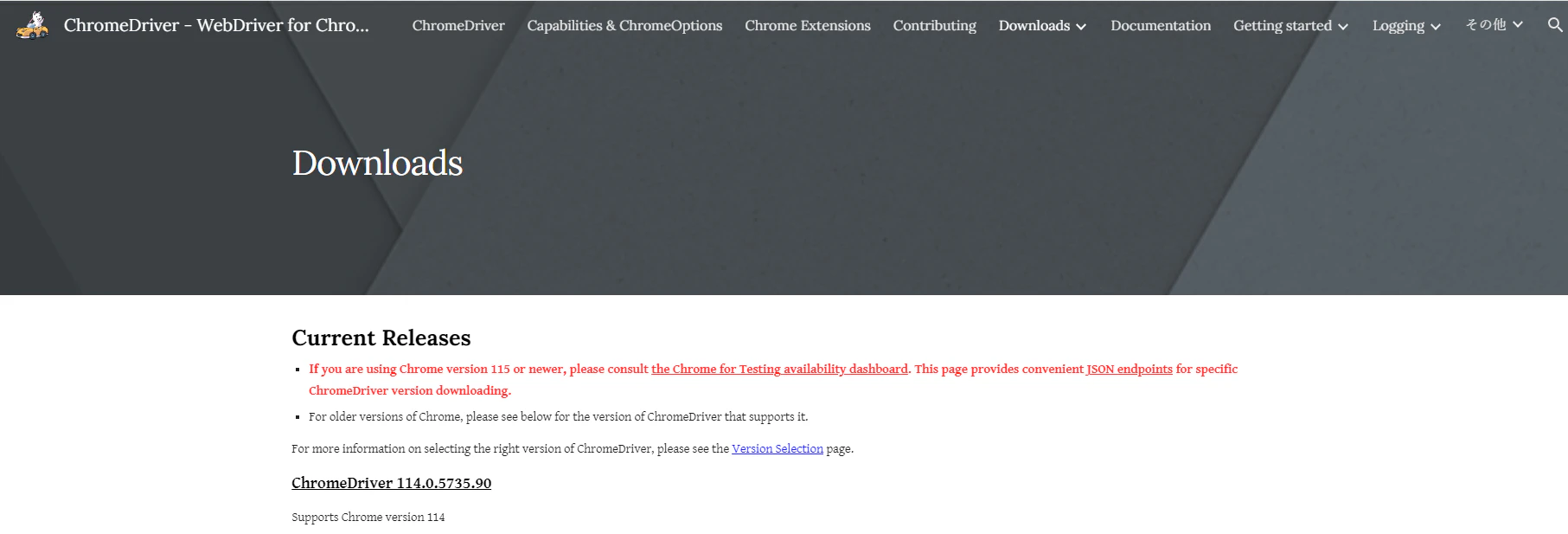
ので、そっちのページも見てみたけど、若干バージョンがズレている・・・
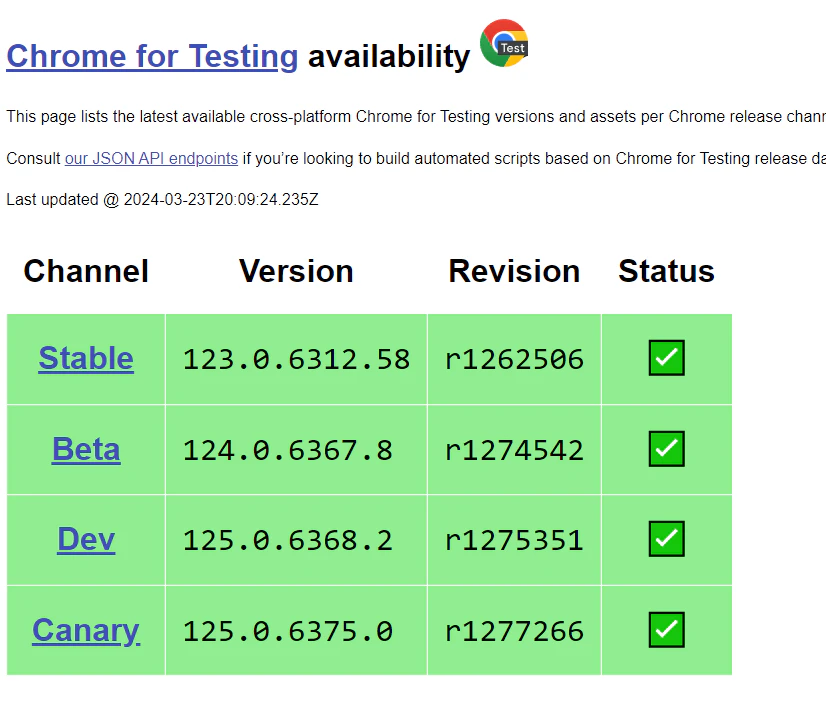
え・・・私のバージョン、新しすぎ!!???
というわけで、後々に出てくるChromeのドライバーを勝手に選んでインストールしてくれる奴を使った
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
7.4 driver.find_element_by_name Unresolved attribute reference 'find_element_by_name' for class 'WebDriver'
webdriver のクラスから、どうやらfind_element_by_nameのfunctionが取り除かれたらしい。えぇ~~、、そこはせめてbackwards-compatibleにしないのかよぉ…
なので、新しいfunctionのfind_elementを使用しないといけない
代わりのコードはdriver.find_element("name", "p")になる
7.4 クッキーの承認
selenium でコードを実行しようとすると出てくるこのクッキーの承認のポップアップのせいで、search = driver.find_element("name", "q")が上手く作動しない。このポップアップを閉じてから検索を行う必要がある
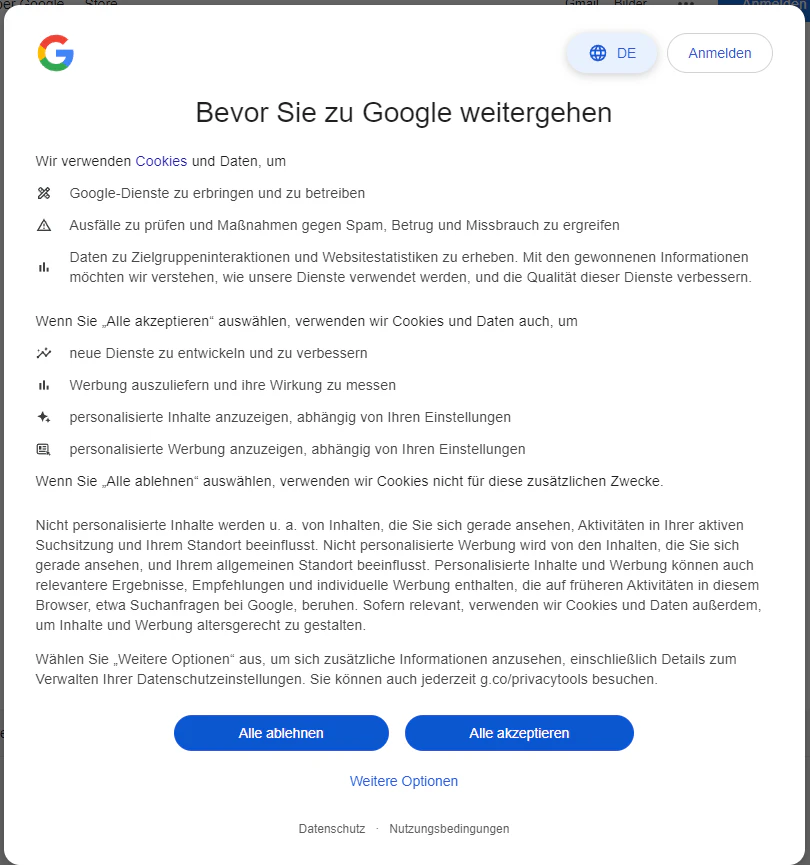
7.4 google 検索へのスクレイピング規制
デバッカーを止めて承認してから続きを走らせてみたけど、ついでにsoup.find_all("h3", attrs={"class": "LC201b"})がempty arrayを返してくる
どうやら、そもそもdriber.page_sourceに内容が何も入っていないっぽいので、ないものは抜き出せないっていう状態みたいね
調べてみたら、こんな記事を見つけた
https://co.nobilista.com/ja/column/seo/scraping/#toc_3
確かに、Google広告ポリシーヘルプにこう書いてある
Google 検索結果ページやその他の Google のプロパティをスクレイピングすることはできません
Google Custom Search APIを使えば出来そうな気はするけど、別に練習だし、そこまでする熱意はないから、代わりにyahooを使うことにした
Yahoo Search DE のrobots.txtを見た感じ、/searchのクローリングは禁止しているらしいけど、私の数回のスクレイピング練習くらいなら、サービスを邪魔しない程度だし、恐らく大丈夫だと思われる。
最終的にこういうコードになった
なお、イラチなのでtime.sleep(3)の部分を全部除けてやったけど、多分本来は入れなきゃいけないよdef scrape_from_google_search():
url = "https://www.yahoo.com"
keyword = "Scraping"
options = Options()
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.get(url)
driver.maximize_window()
# Cookieの承認をする
driver.find_element("name", "agree").click()
search = driver.find_element("name", "p")
search.send_keys(keyword)
search.submit()
soup = BeautifulSoup(driver.page_source, "html.parser")
results = soup.find_all("h3", attrs={"class": "title"})
index = 1
for result in results:
# aria-label が貼られているものだけがタイトルなので、それが含まれているものだけ抽出する
if result.select("a[aria-label]"):
print("%d: %s " % (index, result.find("a")["aria-label"]))
index += 1
time.sleep(5)
driver.quit()
概ね思っていた通りの結果が出た!(広告(Anzeige)は全部無視したデータになっているのもありがたいね…!)
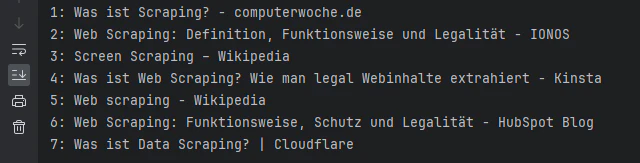
- 結果が全部ドイツ語なのは、私がドイツに住んでいるからであって、バグではない
8.3 parse メソッドのoverride
AnondSpiderSpider.parse のmethod signatureが違っているので、warningが出てくる
Signature of method 'AnondSpiderSpider.parse()' does not match signature of the base method in class 'Spider'

親クラスを見てみたら、確かに **kwargs: Anyが足りていない
def parse(self, response: Response, **kwargs: Any) -> Any:
raise NotImplementedError(
f"{self.__class__.__name__}.parse callback is not defined"
)
**kwargs をargumentに足したらとりあえずは良さそう
def parse(self, response, **kwargs):
...
第9章
9.1 MeCab が文字化けする
MeCabのWindowsの64bit版をダウンロードして、コマンドを走らせてみたら、見事に文字化けしている
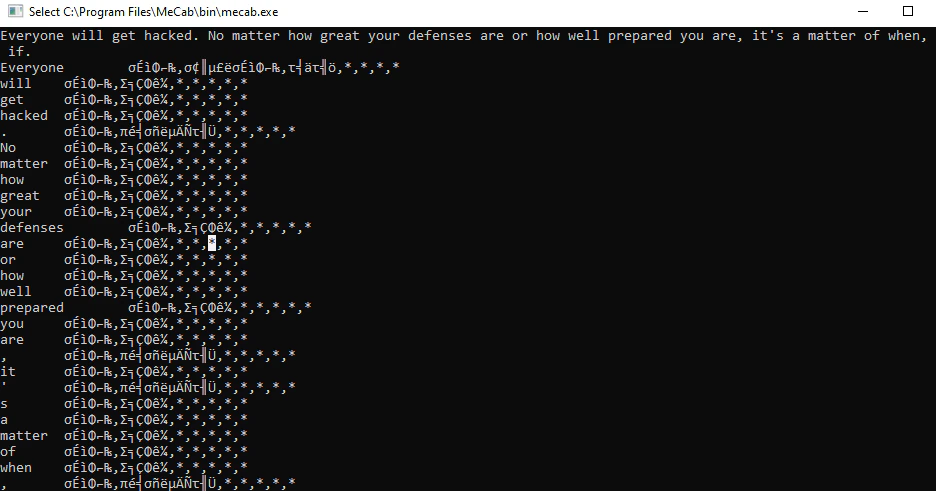
(日本語だけなのかな?と思ったから英語でやってみたけど、英語でも超文字化けしとる)
本には32bit版をutf-8指定でダウンロードしたら直るって書かれてるけど、それはちょっと面倒臭いし、どうせPythonでやるので、ここは無視して進めて行こう
ちなみに、Pythonコード上は特に問題なく表示出来たので、スキップしてOKということにしておく
9.1 pip install mecab-python-windows ←出来ない
そもそもこれはインストールできなかったので、pip install mecab-python3の方をインストールしないとだった。本では「windowsでは~」って書かれてあったけど、まぁそういうこともあるんだろう
9.2 UnicodeEncodeError
多分これも、私のPCが英語環境だから起こったんだと思う
UnicodeEncodeError: 'charmap' codec can't encode character '\u68ee' in position 0: character maps to <undefined>
日本語の文字をファイルに出力しなきゃいけないんだから、encodingを指定する必要がありそう
with open("data.txt", "w", encoding="utf-8") as file:
これで問題なく出力出来た!

同じ理由で、次のセクションのファイルを開く時にも、指定してあげないとエラーが出るから気を付けよう
file = open("data.txt", encoding="utf=8")
9.2 word2vec.Word2Vec(corpus, size=200... <- Unexpected argument
こういうのさぁ~~、何でdeprecatedにしてしばらく残しておいてくれないの~~そういう所は不親切だよねぇ、君。Pythonにbackward compatibility という概念はなかったりするのかい…?
word2vec.Word2Vecを呼ぼうと思ったら、sizeというパラメーターはダメだと言われた。多分除けてしまってもいいんだろうけど、何となく気になるので代わりの値を探す
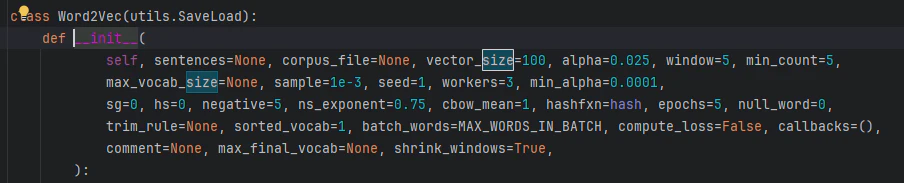
sizeという言葉が何かに置き換わったんだと考えると、恐らくこのvector_sizeかmax_vocab_sizeなんじゃないかと思う。
本を見てみたけど、この値に関する記述はなかったので、もうちょい探っていると、このStackOverFlowの記事にたどり着いた
From the Gensim documentation, size is the dimensionality of the vector.
これを読む感じ、恐らくsizeはvectorのサイズとして使われているっぽいので、vector_sizeを使うことにした。まぁ、間違ってても何とかなるでしょ
9.2 model.word2vec でモデルを呼び出す
多分これはtypoだと思う。実験してみたら、このコードでいけた。最新版では直ってるんじゃないかな?
model = word2vec.Word2Vec.load("data.model")
10章
pip install fbprophet が、ModuleNotFoundErrorが永遠に出てきてウザい
pip install fbprophetをしていると、マジでModuleNotFoundError -> 次のdependencyのインストール が終わらない。
ModuleNotFoundError: No module named 'convertdate'
ModuleNotFoundError: No module named 'lunarcalendar'
ModuleNotFoundError: No module named 'holidays'
…
もうええって!!!!
これ、必要なモジュールを一気にインストールしてくれるやつないの?
というわけで、ここに載ってた pip-compile でrequirements.txtをgenerateしてくれるツールを使ってみた!
まずはrequirements.in にfbprophetと入れる
次にpip-toolsをインストール&使ってみる
pip install --upgrade pip # pip-tools needs pip==6.1 or higher (!)
pip install pip-tools
pip-compile requirements.in
これをやると、requirements.txtが作られるので、pip install -r requirements.txtのコマンドを叩くか、PyCharm様にボタン一つでインストールして貰う
しかし、そこでまたもやエラー
Failed to build fbprophet
ERROR: Could not build wheels for fbprophet, which is required to install pyproject.toml-based projects
調べたらC++のコンパイラーをインストールしろって書かれてあるんだけど、もうとっくにやってるのになぜ…?
同じ事で詰まっている人達を見かけた。超最近じゃん…
しかし、何故か同じようなissueをprophetという名前の超似ているモジュールで話している人がいる
これってもしやprophetでもいけるんじゃ…?と思って調べてみたら、どうやらfbprophetはprophetに名前が変わったらしい!マジか~~!prophetはFBが開発しているものなんだけど、確かにFacebookはMetaになったんだから、fbと冠するものの名前が変わっててもおかしくないよね~
Facebookのgithubの、prophetに関するページに
As of v1.0, the package name on PyPI is “prophet”; prior to v1.0 it was “fbprophet”.
って書かれてあった!!
ちなみに、prophetは何の問題もなくインストール出来た
(上の困ってる人を見かけたサイトにも、一応書き込みしておいたZE)
10.3 Yahoo ファイナンスの上場企業ランキングのURL
細かいけど、まぁウェブサイトは生き物だからちょくちょく変わっちゃうよねー
Yahoo Finance から「上場企業平均年収ランキング」を自力で探すしかない
しかし、私は海外から接続しているので、HTTP Error 403: Forbiddenが返ってきてしまう…
仕方がないので、別のサイトの平均年収ランキングを参照しました。
... と思ったら、これhtmlのtableタグを使ってないと取得できないやんけ!
Yahoo ファイナンスのサイトはtableを使っているけど、上記のサイトは使っていないので、仕方ないからこの項目は読むだけにしておきました
次の章で気象庁のサイトを読むやつをやるからそっちでカバーします
余談だけど、BeautifulSoup とBeautifulTableを使えば、良い感じに出来るらしい。今回はやらないけど、もし無理やりしなければいけなくなったらこの方法を使おう
10.6 グラフが可視化されなくて、数字だけ返ってくる
df.plot("年", "月")を実行しても、本が示しているような線グラフが出力されない。
print で実行すると、中に数字は沢山入っているから、間違ってはいないみたいだけど…
ということで調べてみたら、どうやらIDEとしてJupyterLabを使っていたら df.plotの時点でグラフが出力されるけど、他のIDEで動かす場合は import matplotlib.pyplot as pltをプログラムの先頭付近に追加して、plt.show()を末尾に追加 するといいらしい
(引用: https://teratail.com/questions/354326)
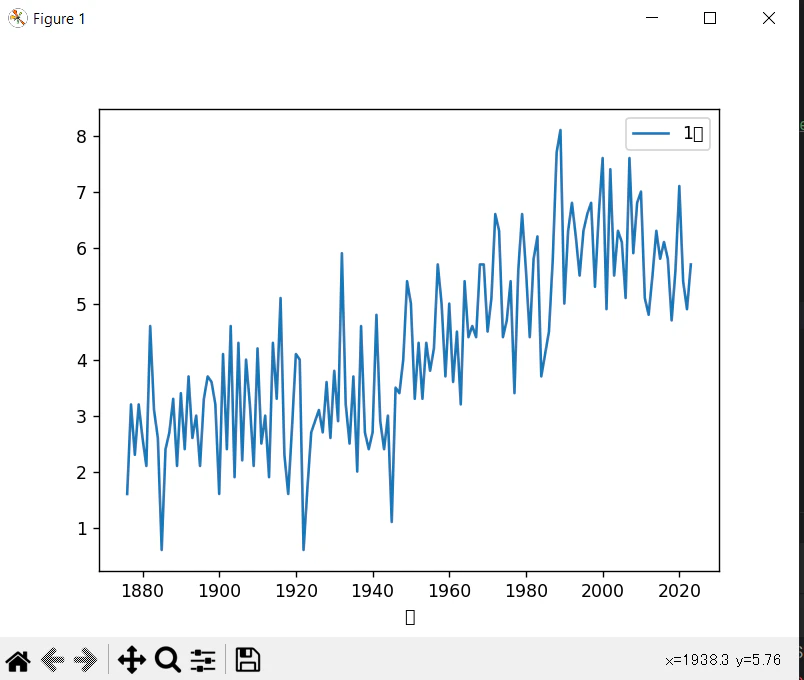
ちょーーっと文字化けしてるけど、本の通りの図が出てきた…!嬉しい!
次のページで散布図を出力するコードが出てくるけど、そこでもplt.show()を末尾に入れたらグラフが出てきた。
10.6 plotlyのimportが出来ない
未来予想をするコードを書く時、下のようなエラーが出てきて、実行できなかった
Importing plotly failed. Interactive plots will not work.
plt自体のライブラリーが古くなっているらしい
上の図の時は、図が出てきた事を喜んでいたから気づかなかったけど、上のコードの時にもひそかにこのエラーメッセージが出ていた
これは、pip install --upgrade plotlyでplotlyのライブラリーをアップデートすることで回避できた
第11章
11.1 アプリパスワードがない
本通りにやってみても、googleヘルプに載っている方法を試してみても、何故か見つからないアプリパスワードのページ。
最終的に、ここのURLを直で踏むと出てきた
https://myaccount.google.com/apppasswords
11.1 プロパティファイルの設定をしたい
ここ、アプリパスワードとかを直で入力しないといけないんだけど、事故が起こりそうで怖いなぁと思うから、プロパティファイルを導入したいなぁと思ったので、ちょっと調べてみた。
(アプリパスワードとメールアドレスの組み合わせを見られたら多分死ぬ)(これだけ言っておいたのに、一回うっかりコミットしてしまって死にかけた)
configparserを使ってConfigFile.propertiesを作っておいた
11.4 QRコードが出てこない
JupiterNoteじゃないので、notify.register() を打ってもQAコードは出てこないので、print(notify.register()) でQAコードを出す
* 12章は、私がラズパイを持っていない事からやっていません
おわりに
スクレイピングハッキングラボはめちゃめちゃ楽しい本だけど、今やるには少し大変な部分もあったので、もし近々この本をやろうと思っている人に、少しでもお役に立てたら幸いです
私はPythonに詳しくないので、もし「ここはこういうやり方もあるよ」とか「こっちの方がいいよ」とかあったらコメントに書いておいてもらえたら、この記事を参考にしてくれている人の為にもなるのでお願いします。