Deep Learning論文紹介 Advent Calendar 2019の9日目の記事です。
半教師あり学習は、ラベル付きデータを少なくすることができる、非常に実用的な
技術です。本稿で紹介する論文は、驚異的なラベル数の少なさで高い精度を叩き出した
論文です。(SoTA更新)
※本稿の図は、基本的に論文(REMIXMATCH: SEMI-SUPERVISED LEARNING WITH DISTRIBUTION ALIGNMENT AND AUGMENTATION ANCHORING)から転載しています。
論文の概要
- 半教師あり学習の先行研究であるMixMatchをベースに、新たな技術を4つ盛り込んだ論文。
- CIFAR-10で40個だけのラベルを用意し、85%の精度(中央値)を達成した!
- CIFAR-10で250個のラベルを用意し、93.7%の精度を達成した(約5ポイント更新)。
※論文では、画像の水増しについて、回転・拡大・平行移動などを「弱い水増し」、Auto Augmentなどを「強い水増し」と呼んでいます。
半教師あり学習とは
- 「ラベル付きデータ」と「ラベルなしデータ」が与えられる。
- 「ラベル付きデータ」を基に「ラベルなしデータ」にラベルを付け、学習させるのが主流。
- ラベルを付ける方法は、「ラベル付きデータ」で学習させたモデルに、「ラベルなしデータ」を入力しその出力値を疑似ラベルとするのが流行っている。
MixMatch
本論文はMixMatchをベースにしています。
まずは、MixMatchを簡単に説明します。
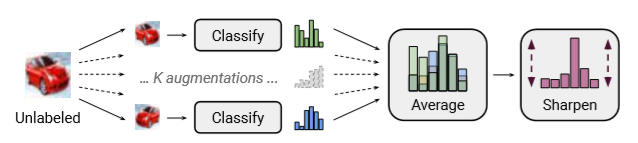
(図はMixMatchの論文より転載)
MixMatchは以下の手順で行われます。
- ラベルなしの画像1枚を使って、K個の「弱い水増し」した画像を用意する。
- そして、ラベル付きで学習させたモデルを使って、それらK個の画像を入れ出力を得る。
- それら出力の平均値を取得し、その画像のラベルとする。
- ただし、そのラベルは温度パラメータTによって鋭くしておく。
- 最後にMixUpを使って、学習を行う。
- ただし、損失関数はラベル付きではクロスエントロピーを、ラベル無しはMSEを使い、最後に重み係数をかけている。
基本的に、ラベル無しの画像では、画像を回転しようが拡大しようが、中に写っている
ものは変わりません。従って、それらの「弱い水増し」の画像を、学習させたモデルに入れ、
出力の平均値をとると、もっともらしいラベルを取得することができ、それをラベル無しの
ラベルとして使うというのが、MixMatchの根幹にあるようです。
また、MixMatchではMixUpを使っている点もかなり効いたようです。
先行研究に対し、大きく精度を向上させました。詳しくは、以下を参考にしてください。
https://github.com/arXivTimes/arXivTimes/issues/1237
ReMixMatch
MixMatchの時点で多くの技法が使われており、ReMixMatchではさらなる
改良として以下を追加しています。
- Distribution alignment
- Augmentation anchoring
- CTAugment
- Rotation loss
Rotation loss以外は本論文で考案されたものです。
一つずつ説明していきます。
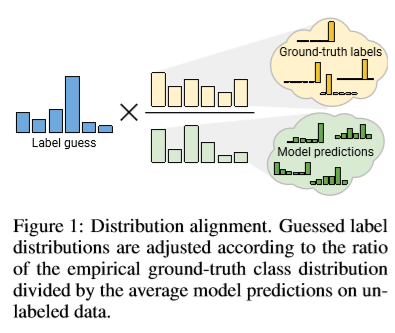
Distribution alignment
例えば、CIFAR10を学習する場合、訓練バッチ内で出てくる各クラスの頻度は
同じくらいになるはずです。「犬」が出てくる回数も「猫」が出てくる回数も
ほぼ等しくなるはずです。
そして、ラベル無し画像でも、バッチ内では等しい出現回数(確率)になるはず
です。そこで、ラベル無しデータにおいて、バッチ内の出現確率が等しくなる
ように制約をかけようというのがDistribution alignmentです。(実際は、
等しい確率にならなくても適用できます。)
式にすると、以下になります。
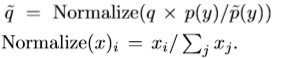
ただし、$q$は「ラベル付き」で学習させたモデルに、「ラベル無し」画像を入力し得られた出力値、
$p(y)$は周辺クラス分布(ラベル付きデータから各クラスが出力する頻度をあらかじめ計算し、
分布を得ておきます。)、$\tilde{p}(y)$は前のバッチで現れたクラスの分布の移動平均を指します。
そして、Normalizeは総和が1になるように標準化しているに過ぎません。
(具体例)
上の式だけだと、良く分からないのでCIFAR10を題材に具体例を示します。
CIFAR10は「犬」や「猫」などが含まれる10クラスに分けられた画像データセットです。
従って、各クラスの周辺確率は$p_{class}(y)=\frac{1}{10}$になります。
今、バッチ数を10として、前のバッチで「犬」が2回、「猫」が1回登場したとします。
この場合、$\tilde{p_{dog}}(y)=\frac{2}{10}$、$\tilde{p_{cat}}(y)=\frac{1}{10}$となります。
上の式に代入します(説明の便宜上、Nomalizeを省略します)。
\tilde{q_{dog}} =q_{dog}\frac{\frac{1}{10}}{\frac{2}{10}} = q_{dog}\frac{1}{2} \\
\tilde{q_{cat}} =q_{cat}\frac{\frac{1}{10}}{\frac{1}{10}} = q_{cat}
この結果、登場頻度が高い犬には、次のバッチで登場頻度が低くくなるような制約が
加えられ、猫には制約は加えられません。なお、制約が加えられた結果、総和が1になる
(確率的に扱う)前提が崩れてしまうので、最後にNomalizeで正規化しています。
実際には、分布を計算しているので、以下の図のように登場回数ではなく、確率スコアの分布に
制約を加えています。
ただし、MixMatchと同じように疑似ラベルを鋭くする処理も併用されています。
個人的には、この技術は非常に汎用性がある技術だと思います。
教師あり学習ではもちろんのこと、自己教師あり学習などでも導入すると、
精度アップさせる可能性を秘めています。
Augmentation anchoring
最初、著者たちはMixMatchの「弱い水増し」を「強い水増し」に変えれば、つまり
画像の回転などではなく、Auto Augmentを使えば精度が上がるのでは?
と考えたようです。通常の教師あり学習では、Auto Augmentを使うことで
大幅な精度向上が認められたからです。
しかし、結果は学習が収束せずに失敗したようです。
失敗した理由として以下二点が挙げられています。
①強い水増し画像を学習済モデルに入力し、その出力値を平均化したため
②Validationデータが少ないため
①について、MixMatchでは弱い水増した画像を用意し、それらの出力の平均値を
疑似ラベルとして使用しました。一方、強い水増しの画像の平均値はお互い弱め
あって、意味がないラベルになってしまうことがあったようです。
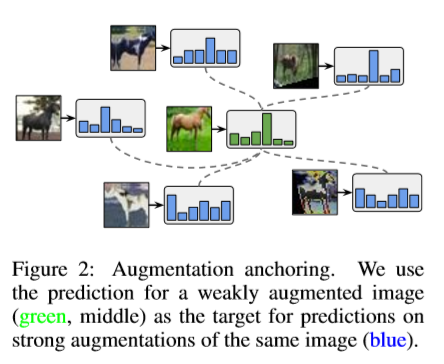
そこで、ReMixMatchでは平均化を止める手法を採用しています。
具体的には、1枚のラベル無し画像を用意し、弱い水増しを実行します。そして
弱い水増しで得られた画像を学習済モデルに入力し、その出力値を疑似ラベルとして
取得します。その後、元になったラベル無し画像を使って、今度は強い水増しを
行います。ここで水増しされた画像には、前述した疑似ラベルを割り当て、その後の
学習で使用します。これによって、平均化で弱められることはなくなり、意味ある
ラベルとして作用します。これをAugmentation anchoringと呼んでいます。
CTAugment
Auto Augmentで失敗した理由②について、通常のAuto AugmentではValidationデータの
精度を見ながら画像を水増ししていきます。しかし、半教師あり学習ではValidationデータ
が少ないため、学習が非常に不安定になるようです。
そこで、本論文ではCTAugmentを提案しています。CTAugmentでは、RandAugmentのように
ランダムに画像変換を選び、教師ありプロキシタスクで最適化される必要がありません。
そのため、ハイパーパラメータの影響を受けず、半教師あり学習でも使えるように
なったようです。(正直、強化学習に疎く、良く分かりませんでした。)
直感的には、水増し画像が分類器で正しく分類できるように、CTAugmentでは尤度を学習
していきます。FastAutoAugmentの密度マッチングとも関係があるようです。
Rotation loss
Rotation lossは半教師あり学習と自己教師あり学習用に考案された手法です。
画像のラベルだけではなく、画像の回転角を予測することで、精度アップが望めるようです。
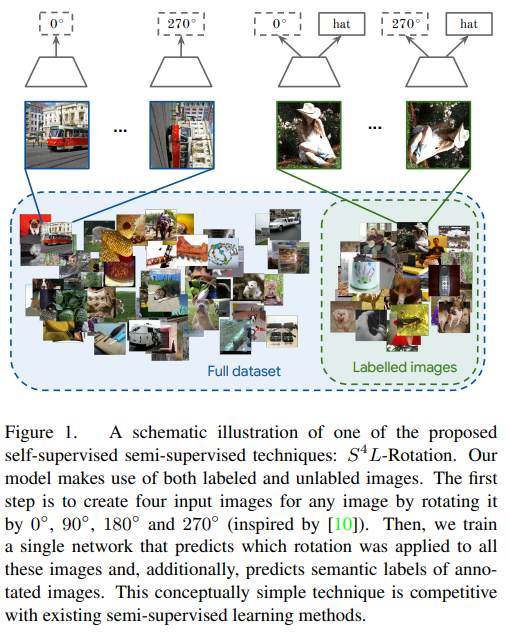
(図は$S^4$L: Self-Supervised Semi-Supervised Learninより転載)
損失関数
以上の技術を導入して損失関数を構築すると、以下の式になります。
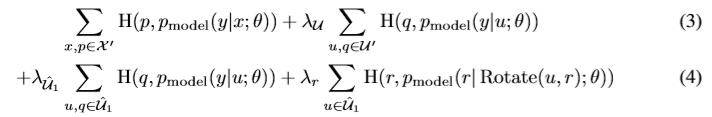
1項目はラベル付きの画像をMixUpしたときのエントロピー、2項目はラベルなし画像を
MixUpしたときのエントロピー、3項目はラベルなし画像をMixUPなしで分類させたときの
エントロピー、4項目はラベルなし画像に関するRotation lossの損失関数です。
ただし、$\lambda_u,\lambda_u,\lambda_{\hat{u_1}},\lambda_r$はパラメータです。
MixMatchとの違いはラベル無しデータに関する項を消して、上記の式の
2~4項目を加えたことです。
実験結果
CIFAR-10とSVHN
CIFAR-10とSVHNは、10クラスからなるデータセットです。
Wide ResNet-28-2を使った結果は以下のとおりです。
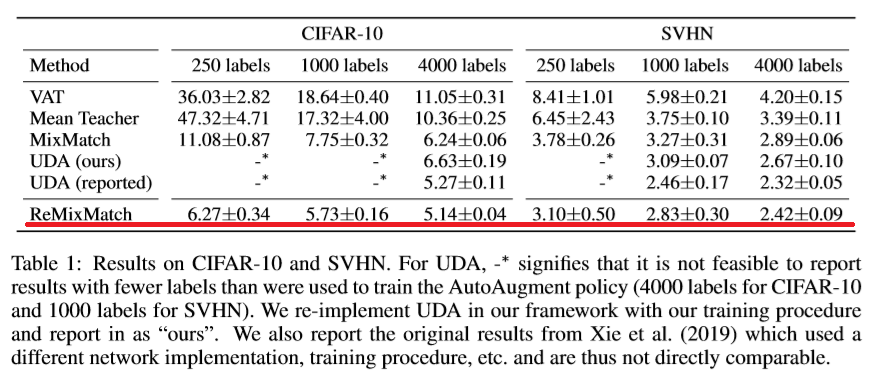
ご覧のとおり、ReMixMatchでは誤差が7%以下に抑えられ、SoTAを更新しています。
250枚の画像にラベルを付ける作業は、2時間もあればできると思うので、結構
現実的な枚数だと思います。
STL-10
STL-10は5,000枚のラベル付き画像と、100,000枚のラベル無し画像から構成されて
います。まさしく、半教師あり学習のためのデータといったところです。
WRN-37-2を使って学習させた結果は以下のとおりです。
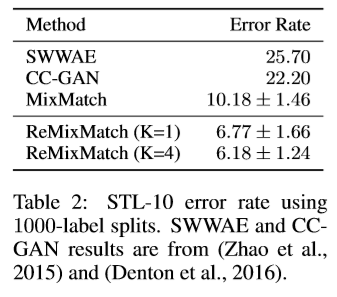
ご覧のとおり、ReMixMatchが誤差6%強でSoTAを更新しています。
40個のラベル付き画像
個人的に驚きだったのが、この実験。
CIFAR-10とSVHNを使って、ラベル40個だけを付与し実験した結果は以下のとおり。
(データセットを5つ作ったため、結果が5つ掲載されています。)
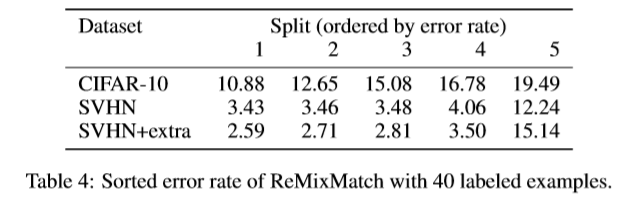
CIFAR-10では、精度80%超えを達成。中央値でも85%ほどの精度が出ています。
ラベル40個と言っても、1クラス当たり4個のラベル付き画像しか与えていません。
本技術はFew Shot Learningといえるような潜在能力を持っています。
個人的には転移学習と併用すると、どれくらいの精度が出るのか気になります。
除去実験
各技術の影響度を調べるために行った実験。
ここでは、ReMixMatchフル装備から各技術を除去した場合の誤差を調べています(下の表の右側)。
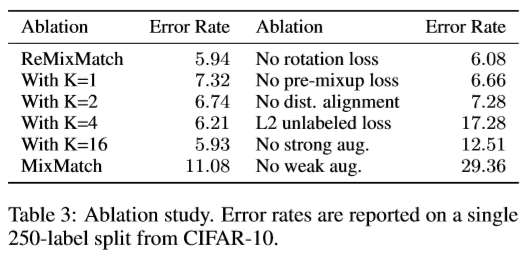
L2や「強い水増し」、「弱い水増し」の影響度が強く、本論文で開発した
CTAugment(strong aug)の効果が出ている模様。
実装
以下のリンクで公開されるようですが、~~今のところ準備中のようです。~~公開されました!
https://github.com/google-research/remixmatch
個人的な感想
- CIFAR-10で、たった40個のラベル付きデータを用意して、精度80%超えは驚異的(転移学習は使っていない)。
- →**教師無しのクラスタリングが不要になる?**と思わせるほどのインパクト!(実際、クラスタリングが不要になることはないと思う)
- →実務的に、40個のラベルを用意する時間は10分もかからないので、省力化にかなり貢献しそうな論文。
- 1個1個の技術を高めてSoTAを更新した論文。地道に努力することの大切さを教えてくれる論文。