最近、画像の異常検知研究が活発になってきました。
そこで、本稿では、画像の異常検知研究に関する最新情報をお伝えします。
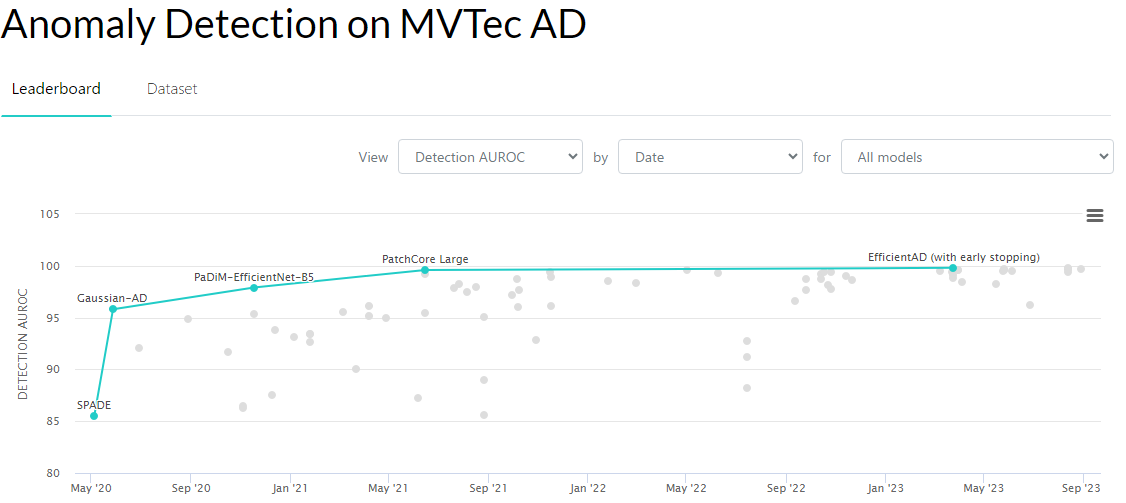
画像はpaper with codeより転載
先に結論
- 最近の研究は精度を維持しつつ、メモリの圧迫を抑える。さらに、推論時間も短縮させている。
- 最近のデータセットは多様性が増し、より難易度が上がっている
予備知識
本題に入る前に、従来の手法・データセットが抱える問題点をおさらいしておきます。2021年くらいまでの情報ですので、ご存知の方は読み飛ばしてください。
従来の手法
PaDimとマハラノビスAD
今でも根強い人気があるのがPaDim[1]です。中身が簡単なことに加え、異常検知性能も高いことが理由だと思います。また、PaDimの基となったのがマハラノビスAD(gaussian AD)[2]です。
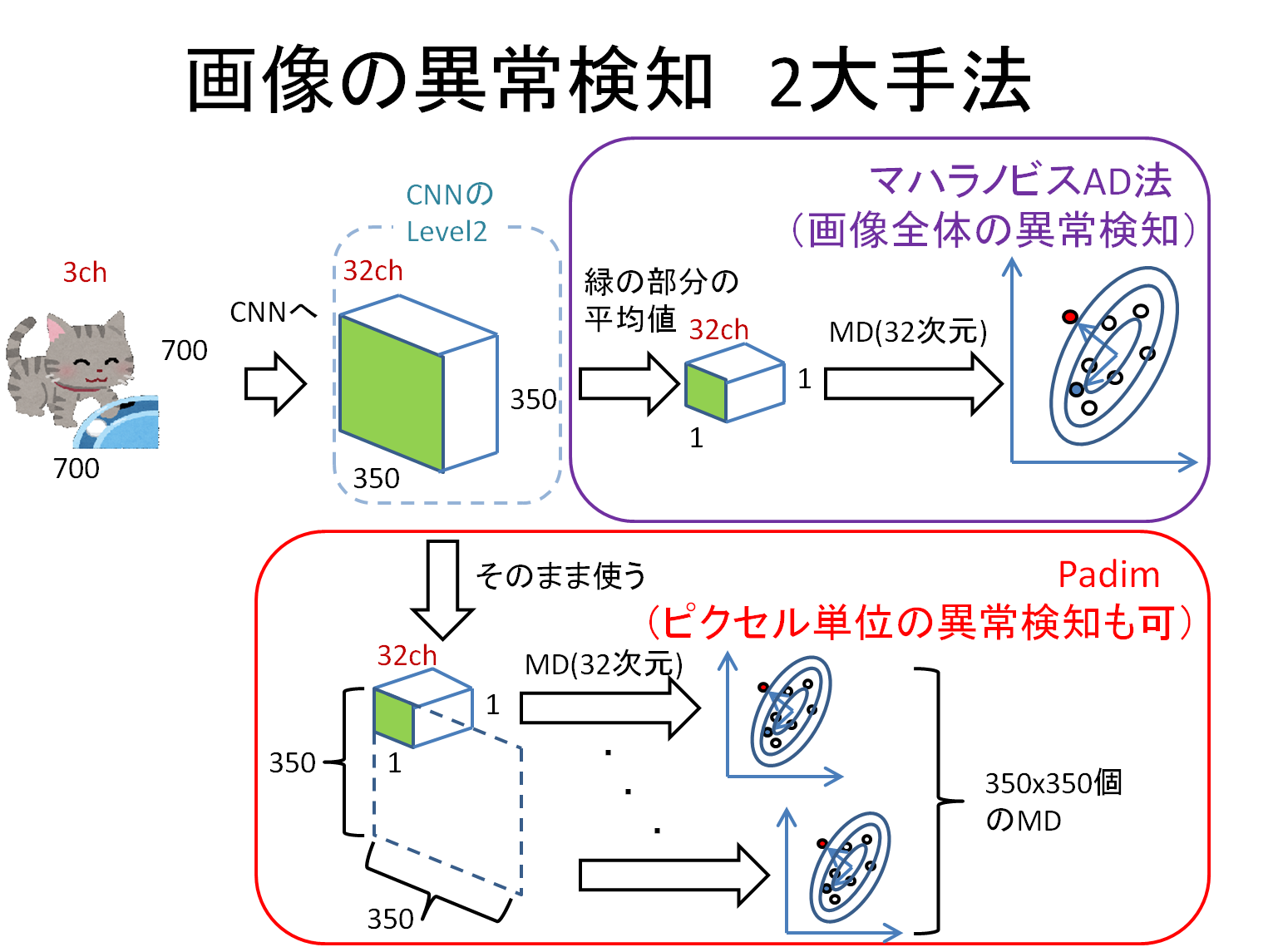
上記のスライドは二つの手法を説明したものです。両手法とも、ImageNetで学習済のCNNについて、中間層の出力を取得して特徴量としています。そして、マハラノビス距離(MD)を算出し、これが大きいものは異常品として検出されます。
マハラノビスADは
- ×ピクセル単位の異常検知はできない
- 〇その代わり、メモリを圧迫しない。画像の解像度を上げてもメモリの記憶サイズは同じ。
- ×性能的にはやや劣るとされる
PaDimは
- 〇ピクセル単位の異常検知ができる
- ×上記のスライドのように1ピクセルずつ正常空間を作るので、位置ズレに弱い
- ×さらに、構造上メモリを圧迫する。画像の解像度を上げるとメモリの圧迫が顕著に。
- 〇性能的には良い
PatchCore
上記2つの手法は、異常度の算出にマハラノビス距離を採用していました。PatchCore[3]ではK近傍法を用いて異常度を算出します。
PatchCoreは
- 〇ピクセル単位の異常検知ができる
- 〇1ピクセルずつ正常空間を作るわけではなく、embeddingをごちゃ混ぜにするので、位置ズレに強い
- 〇性能的にはSOTAに近い
- △メモリの圧迫を避けるために、CoreSet sampling(下図)を使い、保持するembeddingを効率的に絞る
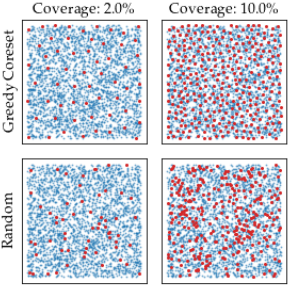
画像は文献[3]より引用(Greedy CoresetがCoreSet samplingに相当)
従来のデータセット
- MVTech AD[4]
- 工業製品を主眼とした画像のデータセット
- 画像の異常検知において、長い間ベンチマークの対象とされた
- 最近では100%近い精度が出ているため、次なるデータセットが求められている
- 個人的には同じ製品内で多様性が少なすぎるのでは?と思う
最近の研究
ここからが本題です。
従来の研究・データセットは以下の課題がありました。
- 手法の精度は高いものの、メモリを圧迫しがち
- さらに、推論時間もある程度必要
- データセットもMVTech ADだけでは限界
最近の手法は、これらの課題を克服する動きがあります。
精度向上・推論時間短縮を狙ったもの
-
SimpleNet[5]
- 正常品についてCNNの中間層を取り出し、それにノイズを付与し異常なembedding(Anomalous Features)を生成。正常/異常の二値分類に持ち込む(下図)
- 〇PatchCore相当の性能
- 〇メモリを圧迫しない。推論時間はbackboneに依存する。
- ×testデータにoverfitしている疑惑がある(後述)
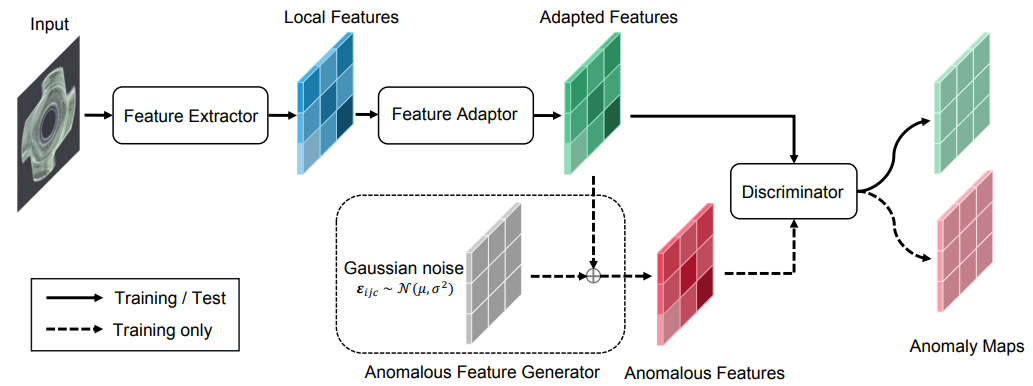
画像は文献[5]より引用
- EfficientAD[6]
- ImageNet-pretrained-modelを軽量なモデルに蒸留させる
- 〇さらに、オートエンコーダも用意して論理的異常にも対応させる
- 推論時は、ImageNet-pretrained-modelと軽量モデル・オートエンコーダの差分を取って異常値とする
- 〇メモリを圧迫しない。推論時間はbackboneに依存する。
- 〇PatchCoreを超える性能。異常検知モジュールanomalibではトップスコア(image-level)。
- 多分、MVTech LOCO(後述)でもSOTA(未確認)。
基盤モデルを使ったもの
- SAA[7]
従来の手法では、検出したい異常の大きさや中身をコントロールすることはできませんでした。しかし、この手法はそれらが制御できるため、より設計者の意図を反映させた異常検知ができます。個人的に、これは実用上もの凄く大事な事で、新時代の異常検知手法だと感じています。
最近のデータセット
- ViSa[8]
- MVTech ADと同じく工業製品を主眼としている
-
MVTech LOCO[9]
- MVTech ADは傷や変形などの異常であったが、LOCOでは個数が少ないなど論理的な異常も含む
このほかにも、ドメインシフトがあるもの[10]やスーパーマーケットの商品を対象としたもの[11]も発表されています。
ドメインシフトがある外観検査用の異常検知データセットが公開。著者による解法も紹介されている。https://t.co/p2mmte5gAq pic.twitter.com/PEwYkYCg1o
— shinmura0 (@shinmura0) May 18, 2023
スーパーマーケット商品の外観検査用の異常検知データセットが公開。異常は「ラベルが破れている」「袋が開封されている」など。
— shinmura0 (@shinmura0) July 13, 2023
論文では、最新のSimpleNetまで掲載されていて凄いが、やはりPatchCoreが優れているらしい。(手法の改善の余地はあると思う)https://t.co/UYAuZxOB6E pic.twitter.com/U3vHAozyzo
私見
以上が最近の動向でした。以下は私見です。
論文の信憑性は?
文献[6]の4. Experimentsに興味深いことが書かれています。直接の表現は避けていますが、ある論文ではちょっとしたズルがされています。つまり、各論文に記載されているスコアを鵜呑みにするのは危険ということです。
例えば、PatchCoreではCenterCropの前処理が入っており、Cropされない外側を強制的に正常と認識させています。(Kaggle的には、データの特性を捉えた素晴らしい前処理ですが、アカデミックの業界では意見が割れそうです。)
また、文献[6]には書かれていませんが、SimpleNetでも、PatchCore同様にCenterCropの前処理が入っています。SimpleNetでは、さらにearly stoppingが入れられ、test data(異常データを含む)を見ながら最適なモデルを保存しています。個人的に、これはレッドカードの行為です。
ここまで読んできて、失望した方も多いのではないでしょうか。論文のスコアが信用できないとなると、最新の論文は信用できるのでしょうか?我々、実務者は何を信じて手法を選べばよいのでしょうか?
結局、最強の手法はどれだ?
一旦、従来手法の話しに戻ります。最近の論文に、PatchCoreなど従来の手法・backboneを数個用意して、精度の変化を調べた論文があります[12]。驚くべきことに、従来手法を使ってもbackboneなどを調整すれば、MVTech ADにおいて完全制覇に近いスコア(AUROCが99.9%)が出ます。
つまり、EfficientADなど最新手法を使わなくても、良いスコアが出るということです。では、最新手法を学ぶ必要がないかというと、そうではないと感じています。
なぜなら、異常検知には最強の手法はなく、データに適した手法を選ぶ必要があると思っているからです。
Kaggleでは最強のbackboneは存在しません。データによってVitが強いときもあれば、CNNが強いときもあります。結局、有力なbackboneを泥臭く探すしかありません。
異常検知でも同じことが言え、文献[12]のように手法やbackboneを泥臭く探索する必要があります。性能的には劣るとされるマハラノビスADも、データセットの相性によっては一番性能が良いときもあります。(ちょっとしたテクニックが必要ですが)
実務では、精度に加え、推論時間の制約やメモリの制限もあります。これらを複合的に考えた上で手法を決める必要があり、その際に、この記事が皆さんの一助になると幸いです。
まとめ
- 最近の研究は精度を維持しつつ、メモリの圧迫を抑える。さらに、推論時間も短縮させている。
- 基盤モデルを使った方法は、検出したい異常をコントロールできる画期的なもの
- 最近のデータセットは多様性が増し、より難易度が上がっている
- (私見)最強の手法は存在せず、do everythinの精神で色々試す必要がある
参考文献
- [1] Thomas Defard, Aleksandr Setkov, Angelique Loesch and Romaric Audigier. PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization.
- [2] Oliver Rippel, Patrick Mertens and Dorit Merhof. Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection.
- [3] Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox and Peter Gehler. Towards Total Recall in Industrial Anomaly Detection.
- [4] Bergmann, Batzner, Fauser, Sattlegger, and Steger. The MVTec Anomaly Detection Dataset.
- [5] Zhikang Liu, Yiming Zhou, Yuansheng Xu and Zilei Wang. SimpleNet: A Simple Network for Image Anomaly Detection and Localization.
- [6] Kilian Batzner, Lars Heckler and Rebecca König. EfficientAD: Accurate Visual Anomaly Detection at Millisecond-Level Latencies.
- [7] Yunkang Cao, Xiaohao Xu, Chen Sun, Yuqi Cheng, Zongwei Du, Liang Gao and Weiming Shen. Segment Any Anomaly without Training via Hybrid Prompt Regularization.
- [8] Yang Zou, Jongheon Jeong, Latha Pemula, Dongqing Zhang and Onkar Dabeer. SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation.
- [9] Paul Bergmann, Kilian Batzner, Michael Fauser, David Sattlegger and Carsten Steger. Beyond Dents and Scratches: Logical Constraints in Unsupervised Anomaly Detection and Localization.
- [10] Zilong Zhang, Zhibin Zhao, Xingwu Zhang, Chuang Sun and Xuefeng Chen. Industrial Anomaly Detection with Domain Shift: A Real-world Dataset and Masked Multi-scale Reconstruction.
- [11] Jian Zhang, Runwei Ding, Miaoju Ban and Ge Yang. PKU-GoodsAD: A Supermarket Goods Dataset for Unsupervised Anomaly Detection and Segmentation.
- [12] Lars Heckler, Rebecca Konig and Paul Bergmann. Exploring the Importance of Pretrained Feature Extractors for Unsupervised Anomaly Detection and Localization.