自分用メモ
Beautiful Soup 4とrequestsのインストール
pip install beautifulsoup4
pip install requests
Beautiful Soup 4とrequestsのインポート
from bs4 import BeautifulSoup
import requests
URLからrequestsのresponseを取得
変数「url」にリクエスト対象のURLを指定
※この段階ではインデントされていないHTML
url = "https://qiita.com"
response = requests.get(url)
print(response.text)
BeautifulSoupでHTMLをインデントして取得
prettify()がHTMLをインデントして取得する関数
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
Beautiful Soup 4+requestsでインデントされたHTMLを取得するまとめ
ついでにファイル出力
from bs4 import BeautifulSoup
import requests
# URLからrequestsのresponseを取得
url = "https://qiita.com"
response = requests.get(url)
print(response.text)
# BeautifulSoupの初期化
soup = BeautifulSoup(response.text, 'html.parser')
# HTMLをインデントして取得
html = soup.prettify()
# インデントされたHTMLをファイル出力
f = open('prettify.html', 'w', encoding='UTF-8')
f.write(html)
f.close()
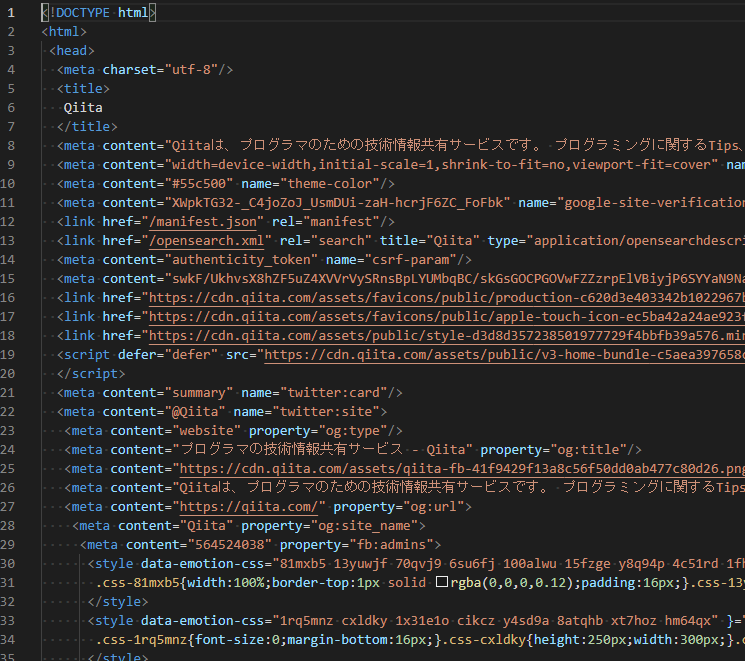
出力したHTMLがこんな感じ
参考(Beautiful Soup 4.2.0 Doc. 日本語訳)
403 Forbiddenが出てHTML情報が取得出来なかった場合は以下参照
403 Forbidden(You don't have permission to access)が出た場合の対処法
以上