はじめに
個人的にData-efficient Neuroevolution with Kernel-based Surrogate models1を読んで,「Surrogateって便利かもしれないな」って思ったのでまとめます.
About Surrogate Model
Surrogateは「代理」や「代わりのもの」という意味です.
一般にSurrogate Modelと言った場合には,代理モデルとして,多様な意味合いがあります.
しかし,本記事中でのSurrogate-ModelはSurrogate-Assistedなどと呼ばれる,探索を補助する手法のことを指します.
これは簡単に言えば,評価値を予測する手法になります.
通常,解を探索する場合には解を評価関数(目的関数)に入力することで,評価値を得ます.
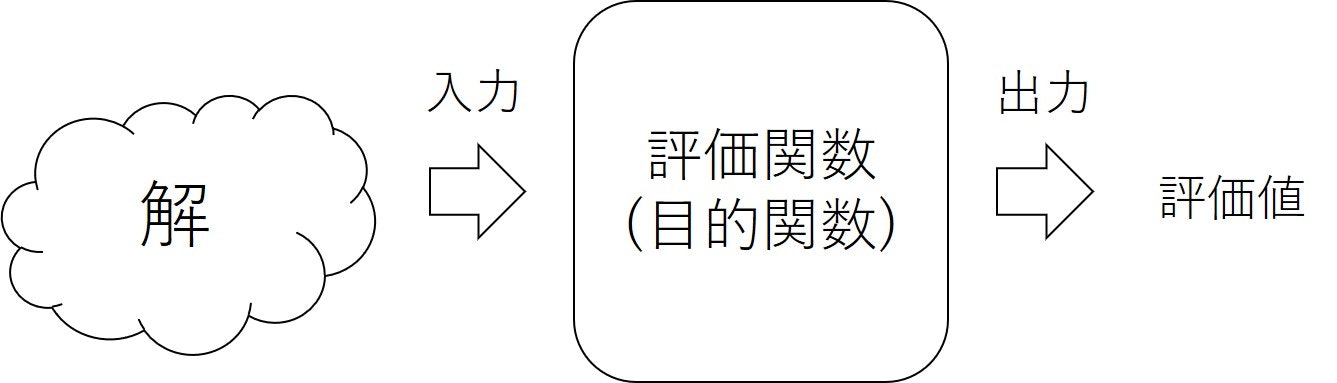
しかし,評価関数が高速ではない場合はあります.
たとえば物理シミュレータや,ゲームエミュレータなどによってシミュレータティングしたときの結果を評価値としたときです.
このときの評価関数は,実際にシミュレータを動作する必要がありますが,シミュレータは高速に動作することができない場合が多いです(特に,学習や最適化用のシミュレータではない場合には,高速動作をサポートしていない場合があります).
このときに,何万回・何百万回と探索を進めたい場合には,評価関数自体の速度が遅いために実時間では,最適化することが困難です.
そこで,登場するのがSurrogate-Modelです.評価関数をほかの手法で近似するのです.
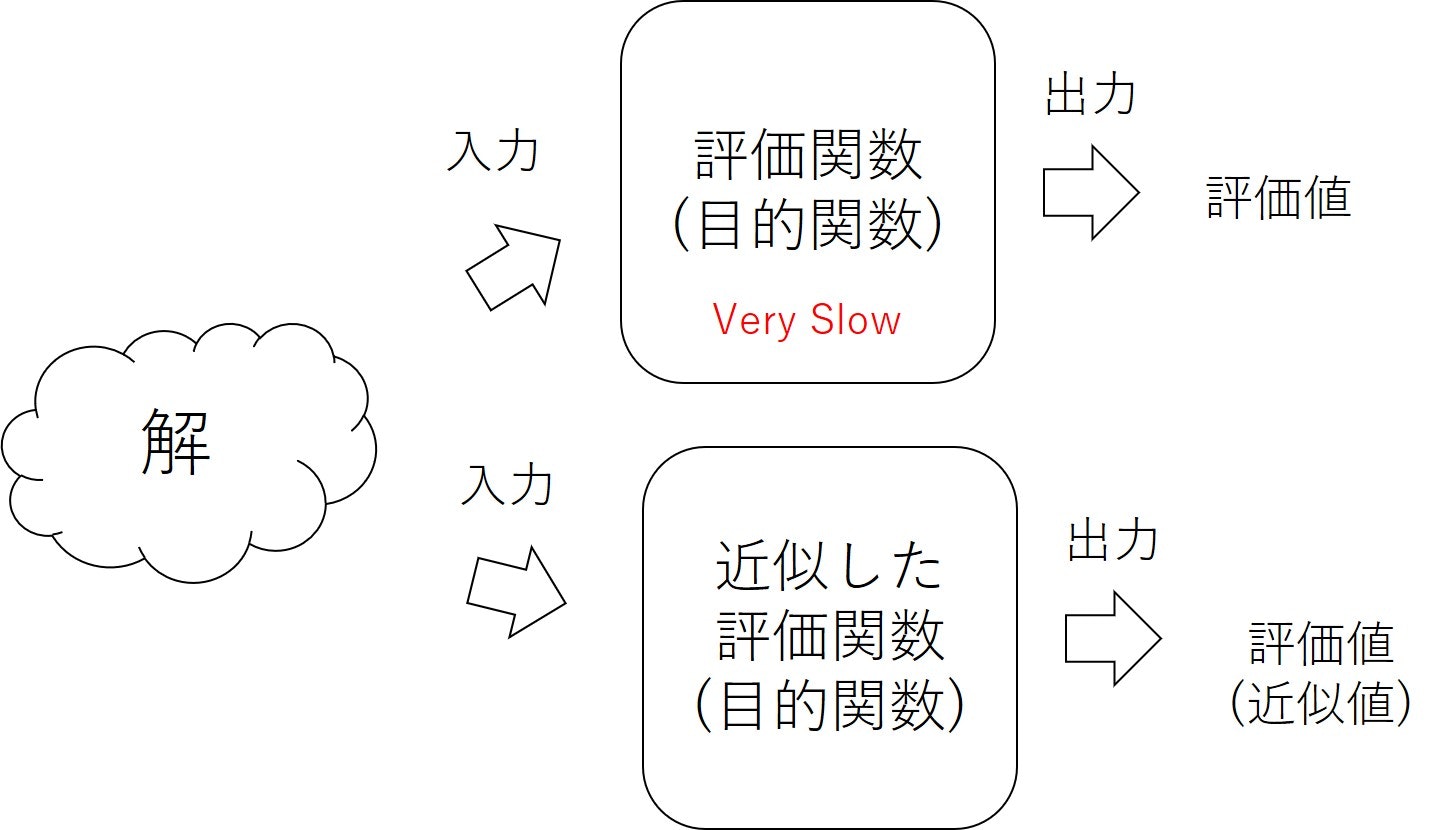
実際,文献1ではBayesian Optimizationによって評価関数を近似することで,評価関数を通さずに評価値を得ることに成功しています.
この手法では,探索と同時に評価関数を近似することで,探索効率が上がることを示しています.
注意点
Surrogate-Modelはたしかに面白い手法ですが,適用しようと思った場合には注意点があります.
一つ目は,「評価関数を近似するためには,その評価関数を探索しなければいけない」ということです.
このときの学習データは,解そのものになることに注意しなければいけません.
解が大きすぎる場合には,情報過多によって評価関数の近似ができない場合があります.
当然,評価関数の近似ができない場合には,Surrogateできないので,注意しましょう
二つ目は,評価関数を近似する学習にも時間がかかるということです.
文献1の場合は解探索と同時に評価関数の近似学習も行っていますが,当然,近似学習の時間が発生しています.評価関数の速度自体が遅くない場合には,通常の学習を行ったほうがよいでしょう.
Neuroevolution with Kernel-based Surrogate models
文献1ではNeuroevolution(この場合はNEAT)でSurrogate-Modelを行っています.
多くの探索点をもつ進化計算は非常にSurrogate-Modelと相性がいいのでしょう.
特に,最近Hotな進化計算+多目的最適化の分野では光るのかもしれません.
その場合には,下のようなモデルになります.
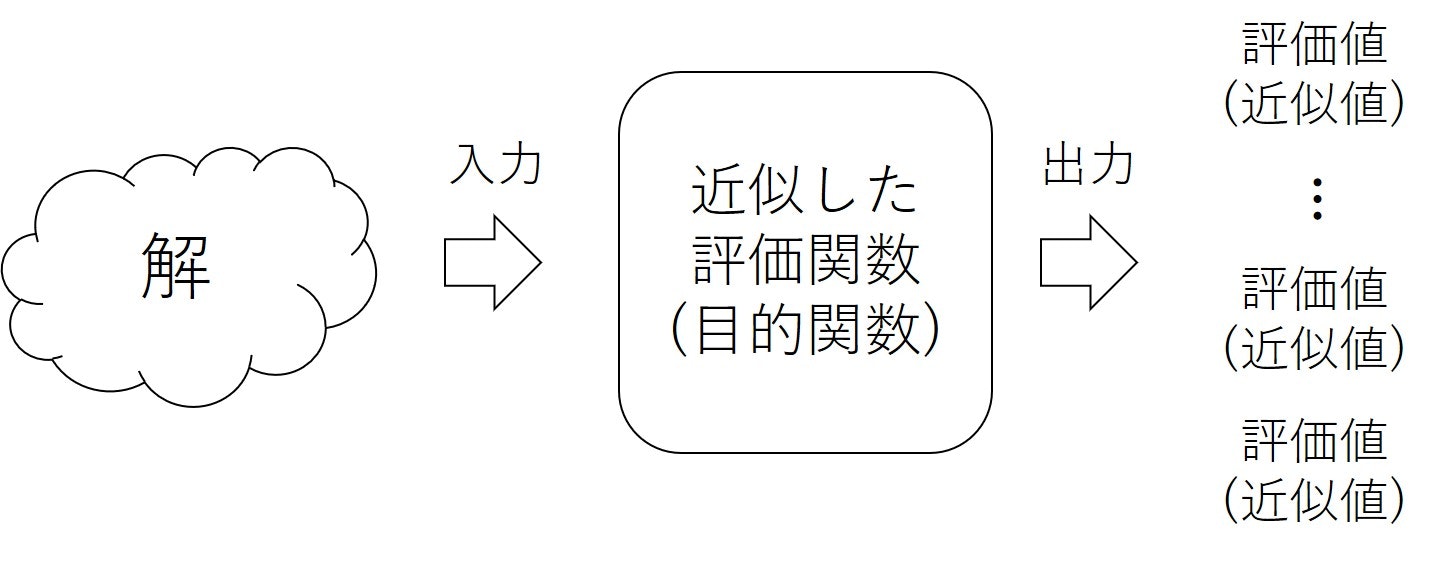
高度なシミュレータを通す場合には非常に高速に探索できるようになると思います.
今後光ってくる手法でしょう.
また,遺伝子型とよばれる固定長のデータで表現される点も,Surrogate-Modelと相性がいいのでしょう.やはり,不定形のものを学習することは非常に困難です.さらに,文献1ではBayesian OptimizationをSurrogate-Modelとして使っていましたが,他の機械学習モデルをしようしてもいいと思います.
ただ,最適化と同時に関数近似をするという点ではBayesian Optimizationの少数サンプルの利点が効いてくるのかもしれません.
おわりに
半自分用にSurrogate-Modelについてまとめました.
そのうち実際に使ってみた例を挙げたいと思います.