はじめに
Cartesian Genetic Programmingを実装してみたので,それについて.
今回実装するのは,回帰問題(単目的)用です.全体のソースコードはここにあげてます.
修正点・ミス・バグあったら教えてください.
Cartesian Genetic Programming(CGP)の実装
一般的にCGPは,多層のフィードフォワード型の合成関数で表現されます.
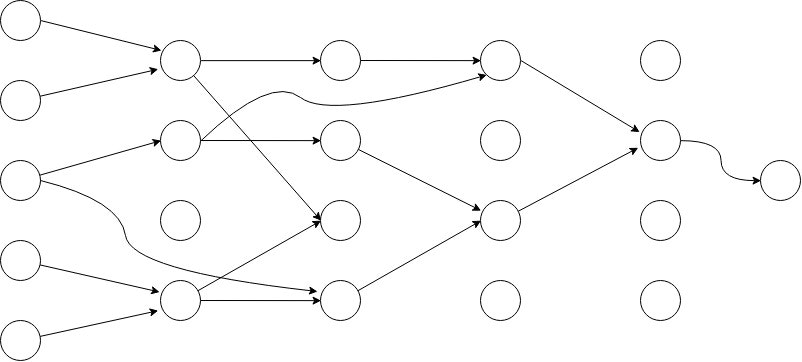
しかし,今回は実装が簡単なので,一層当たり1ノードのフィードフォワードネットワークにします.CGPは自分より前の層ならどこからでも接続できるので,ノード総数が同じならば,一層当たり1ノードのフィードフォワードネットワークでもそんなに問題ないはずです.
個体表現
個体は,固定長の配列で表現します.要素数がノードの総数です.このとき,すべてのノードが使われることはないので,表現型は可変長ネットワークになります.
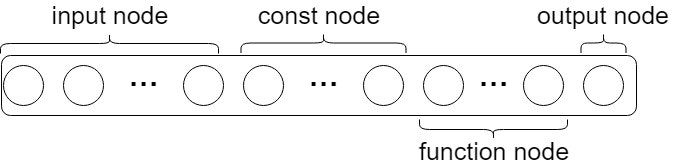
また,各ノードは
- functionノードの種類
- 子ノードの接続関係
- 定数(constノードのみ使用)
をパラメータとして持つ構造体です.さらに,Ephemeral Constant(ERC)と呼ばれるconstantノードを一定数持つことにします.ERCとは,個体の生成時と同時にランダムに決まる定数です.
class Gene:
def __init__(self, func_name, inputs_arg, arity, const):
self.func_name = func_name
self.inputs_arg = inputs_arg
self.arity = arity
self.const = const
class Individual(list):
def __init__(self, content=[]):
list.__init__(self, content)
self.fitness = None
def create(self, gene_num, output_num, nodeSet, leafSet, ERC_func=lambda:random.random()*2-1):
self.output_num = output_num
variable_leaf = [(name,leaf_info) for name,leaf_info in leafSet.items() if leaf_info["const"]!=None]
variable_leaf.sort(key=lambda obj:obj[1]["const"])
const_leaf = [(name,leaf_info) for name,leaf_info in leafSet.items() if leaf_info["const"]==None]
const_leaf.sort(key=lambda obj:obj[0])
for n, item in enumerate(variable_leaf):
name, leaf_info = item
self.append(Gene(name, [], 0, leaf_info["const"]))
for n, item in enumerate(const_leaf):
name, leaf_info = item
self.append(Gene(name, [], 0, ERC_func()))
function_node = [(name,node_info) for name,node_info in nodeSet.items() if name!="out"]
max_arg_num = max([node_info["arity"] for node_info in nodeSet.values()])
for n in range(gene_num):
name,node_info = random.choice(function_node)
inputs_arg = [random.randrange(len(self)) for x in range(max_arg_num)]
self.append(Gene(name, inputs_arg, node_info["arity"], None))
function_num = len(self)
self.function_num = function_num
for n in range(output_num):
inputs_arg = [random.randrange(function_num) for x in range(max_arg_num)]
self.append(Gene("out", inputs_arg, 1, None))
あとで,交叉しやすいように,子ノードの数は揃えてます.ただし,子ノードは先頭から使われていき,そのノードの関数の規定まで使われます.また,関数のノードセット(nodeSet)と入力ノードのノードセット(leafSet)は,各要素に関数名,入力数,定数が定義された辞書in辞書となります.
個体関数の実行
実行ですが,本実装の場合は,配列の先頭から実行しすれば大丈夫です.
しかし,実行しなくてもよいノードも存在するため,実行するノードだけを先に計算します.これは配列の最後の要素であるoutputノードから子ノードを辿ることで計算できます.
def calc_path(self):
path = [False for n in range(len(self))]
for n in range(len(self))[::-1]:
gene = self[n]
if gene.func_name == "out":
path[gene.inputs_arg[0]] = True
path[n] = True
else:
if path[n]:
for i in range(gene.arity):
path[gene.inputs_arg[i]] = True
return path
そして,実行するノードだけを,合成関数として計算します.
def run(self, X, nodeSet, leafSet):
path = self.calc_path()
calc_rets = [None for _ in range(len(self))]
for n, use in enumerate(path):
if use:
gene = self[n]
name = gene.func_name
if gene.arity == 0:
if "x" in name:
ret = leafSet[name]["function"](X, gene.const)
else:
ret = leafSet[name]["function"](gene.const, len(X))
else:
ret = nodeSet[name]["function"](calc_rets, gene.inputs_arg)
calc_rets[n] = ret
for n in range(1,self.output_num+1):
ret = calc_rets[-1*n]
mask = np.isfinite(ret)
m = np.mean(ret[mask])
ret[mask==False] = m
calc_rets[-1*n] = ret
return calc_rets[-1*self.output_num:]
一応,対応できるように書いてあります.単出力の場合は,返り値の最初の要素が出力列となります.
進化アルゴリズム
実装した進化アルゴリズムはGenetic Algorithm(GA)とEvolutionary Strategy(ES)の二つです.
また,この二つのアルゴリズムのパラメータは後述するsklearn_objectが持つパラメータを使います.
Genetic Algorithm
GAの場合は交叉・突然変異・選択の3つの操作を行います.トーナメント選択のみしか実装していないです.
交叉は,1点交叉と一様交叉の2つが選べます.突然変異は,使用ノードのみを変異させる方法と,すべてのノードを変異させる方法がとれます.
以後,増やしていきたいです.
また,各手法はエリート戦略として,エリートを一個体保存するようにしました.
def GA_evolution(sklearn_object):
ind_num = sklearn_object.ind_num
nodeSet = sklearn_object.nodeSet
leafSet = sklearn_object.leafSet
gene_num = sklearn_object.gene_num
output_num = sklearn_object.output_num
generation_num = sklearn_object.generation_num
tour_size = sklearn_object.tour_size
CXPB = sklearn_object.CXPB
MUTPB = sklearn_object.MUTPB
CXMode = sklearn_object.CXMode
MUTMode = sklearn_object.MUTMode
X = sklearn_object.train_X
y = sklearn_object.train_y
evaluator_args = (X,y,nodeSet,leafSet)
pop = op.makeInitialPopulation(ind_num, nodeSet, leafSet, gene_num, output_num)
elite = None
for g in range(generation_num):
pop = op.evaluation(pop, evaluator, evaluator_args)
new_elite = min([ind for ind in pop if ind.fitness!=None], key=lambda ind:ind.fitness)
if elite == None or elite.fitness == None or new_elite.fitness < elite.fitness:
elite = deepcopy(new_elite)
pop = op.tournament_selection(pop, tour_size, elite)
#print(g,*getGenerationInfo(pop))
if CXMode == "OnePoint":
pop = op.one_point_crossover(pop, CXPB)
if CXMode == "Uniform":
pop = op.uniform_crossover(pop, CXPB)
if MUTMode == "Point":
pop = op.point_mutate(pop, MUTPB, nodeSet, leafSet)
if MUTMode == "UsePoint":
pop = op.use_point_mutate(pop, MUTPB, nodeSet, leafSet)
pop = op.evaluation(pop, evaluator, evaluator_args)
new_elite = min([ind for ind in pop if ind.fitness!=None], key=lambda ind:ind.fitness)
if new_elite.fitness < elite.fitness:
elite = deepcopy(new_elite)
return elite
Evolutionary Strategy
ESの場合は,(1+λ)ESのみ実装しました.論文見てると(1+λ)ESが強いようなので.
ESの場合は,交叉ができないようにしました.突然変異はGAと同じく,2つの方法が選べます.
def ES_evolution(sklearn_object):
ind_num = sklearn_object.ind_num
nodeSet = sklearn_object.nodeSet
leafSet = sklearn_object.leafSet
gene_num = sklearn_object.gene_num
output_num = sklearn_object.output_num
generation_num = sklearn_object.generation_num
MUTPB = sklearn_object.MUTPB
MUTMode = sklearn_object.MUTMode
stop_eval = sklearn_object.stop_eval
X = sklearn_object.train_X
y = sklearn_object.train_y
evaluator_args = (X,y,nodeSet,leafSet)
pop = op.makeInitialPopulation(ind_num, nodeSet, leafSet, gene_num, output_num)
elite = None
eval_num = 0
for g in range(generation_num):
pop = op.evaluation(pop, evaluator, evaluator_args)
eval_num += len(pop)
if eval_num > stop_eval:
break
new_elite = min([ind for ind in pop if ind.fitness!=None], key=lambda ind:ind.fitness)
if elite == None or elite.fitness == None or new_elite.fitness < elite.fitness:
elite = deepcopy(new_elite)
pop = [deepcopy(elite) for _ in range(ind_num)]
if MUTMode == "Point":
pop = op.point_mutate(pop, MUTPB, nodeSet, leafSet)
if MUTMode == "UsePoint":
pop = op.use_point_mutate(pop, MUTPB, nodeSet, leafSet)
#print(g,*getGenerationInfo(pop))
new_elite = min([ind for ind in pop if ind.fitness!=None], key=lambda ind:ind.fitness)
if elite == None or elite.fitness == None or new_elite.fitness < elite.fitness:
elite = deepcopy(new_elite)
return elite
scikit-learnからの呼び出し
sklearnのcross validationやgrid searchから呼び出せるように,sklearnのbaseの要件を満たします.
baseオブジェクトを継承をしない場合は,
- fit関数
- predict関数
- get_params関数
- set_params関数
- score関数
を定義すればいいはずです(2019/07/12現在).もしかしたらpredict関数はいらないかもしれません.
また,grid searchなどでscore関数を参照する場合には,戻り値のスコアを最大化します.今回は回帰問題を対象とするため,スコアに-1を掛けて返します.
class CGPRegressor:
def __init__(self,ind_num=4, nodeSet=None,
const_num=0, gene_num=100, generation_num=100, tour_size=7,
CXPB=0.7, CXMode="OnePoint", MUTPB=0.05, MUTMode="UsePoint",
ea_type="ES",stop_eval=100000):
self.ind_num = ind_num
if nodeSet == None:
self.nodeSet = cgp_base.CreateNodeSet({"add","sub","mul","div"})
else:
self.nodeSet = nodeSet
self.const_num = const_num
self.gene_num = gene_num
self.generation_num = generation_num
self.tour_size = tour_size
self.CXPB = CXPB
if ea_type == "GA":
self.MUTPB = 1.0 - CXPB
else:
self.MUTPB = MUTPB
self.CXMode = CXMode
self.MUTMode = MUTMode
self.ea_type = ea_type
self.output_num = 1
self.stop_eval = stop_eval
def fit(self, X, y):
self.train_X = X
self.train_y = y
variable_num= X.shape[1]
output_num = 1
self.leafSet = cgp_base.CreateLeafSet(variable_num, self.const_num)
if self.ea_type == "ES":
self.best_ind = ea.ES_evolution(self)
if self.ea_type == "GA":
self.best_ind = ea.GA_evolution(self)
return self
def predict(self, X):
_y = self.best_ind.run(X, self.nodeSet, self.leafSet)[0]
return _y
def get_params(self, deep=True):
return {
"nodeSet":self.nodeSet,
"ind_num":self.ind_num,
"const_num":self.const_num,
"gene_num":self.gene_num,
"generation_num":self.generation_num,
"tour_size":self.tour_size,
"CXPB":self.CXPB,
"MUTPB":self.MUTPB,
"CXMode":self.CXMode,
"MUTMode":self.MUTMode,
"ea_type":self.ea_type
}
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self,parameter, value)
return self
def score(self,X,y,sample_weight=None):
_y = self.predict(X)
s = np.sum((y-_y)**2)/len(y)
return -1*s
実行結果
実行してみます.対象の回帰問題ですが,データセットを用意するのが面倒なので,乱数列とします.
そのうちちゃんとした問題に適用してみます.
if __name__ == "__main__":# test code
seed = 6
inputs_num = 3
const_num = 1
instances_num = 5
random.seed(seed)
np.random.seed(seed)
X = np.random.random((instances_num, inputs_num))
y = np.random.random(instances_num)
model = CGPRegressor(ind_num=4, nodeSet=None,
const_num=const_num, gene_num=10, generation_num=100,
MUTPB=0.05, MUTMode="UsePoint",
ea_type="ES")
model.fit(X,y)
s = model.score(X,y)
print(s)
実行結果
-0.08112019089484938
とりあえず,動いているようです.
おわりに
今回は,CGPを実装してみました.ソースコードはこちら
次は,CGPにはGAがよいのか,それともESがよいのかを検証しようと思っています.
そのときは,実際の回帰問題で試してみることにします.