YOLO
YOLOの原論文は以下になります。
yolo論文
目的
英語の勉強とyoloを実装するためです。そのため、自分はyoloモデルのアーキテクチャや各要素の細部に興味があります。なので、大雑把に何ができるとか何がすごいってことを書いているAbstractとIntroductionは省略します。また、論文内の直訳を書き写すだけならgoogle翻訳使えばいいじゃんってなるので、論文内の表現をそのまま使わず、自分なりにかみ砕いて訳している部分があります。ご容赦ください。
Unified Detection
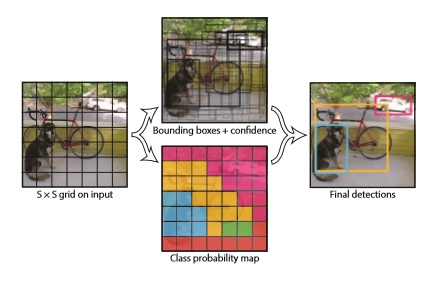
我々は物体検出の要素を一つのNN(Neural Network)にまとめた。我々のネットワークはバウンディングボックスを予測するために画像全体から得た特徴を使用する。同時にすべてのバウンディングボックスでクラスを予測する。
我々のシステムでは入力画像をSxSのグリッドに分割する。もし検出物体の中心がグリッドセルの内に存在したら、そのグリッドセルがその物体の検出の責任を負う。 形式的に、我々はこのconfidenceを
confidence = P_r(Object) * IoU^{truth}_{pred}
として定義する。セル内に物体が存在しない場合、confidence scoreはゼロになるべきだ。その一方で、confidence scoreは、予測したボックスとground truthのIoUと等しくなってほしい。
各グリッドセルはB個のバウンディングボックスとconfidence scoreを予測する。confidence scoreはモデルがどれだけボックスが物体を含んでいることに自信があるか、その予測がそれだけ正確かを反映している。
各バウンディングボックスは5つの値を予測する:x,y,w,h,confidenceである。(x,y)はグリッドセルの境界に対応した中心座標である。幅と高さは全体画像に相対的に予測される。最後に、confidenceは予測したボックスとground truth boxのIoUを示す。
各グリッドセルは同様に条件付きクラス確率Cを予測する。それらの確立はグリッドセルに物体が存在することによって条件づけられる。
C = P_r(class_i|Object)
ボックスの数に関係なく、各グリッドセルごとにワンセットのクラス確率を予測する(必ずすべてのクラスの確立を求めるということでしょうか)。
テスト時には、条件付きクラス確率と個々のボックスのconfidenceの予測値をかけ合わせる。
P_r(class_i|Object) * P_r(Object) * IoU^{truth}_{pred} = P_r(class_i) * IoU^{truth}_{pred}
こうすることで、各ボックスに対する特定のクラスのconfidence scoreを得られる。そのスコアはボックス内部のクラスの確率とどれだけよくボックスが物体に合っているかを表す。
Network Design
我々はこのネットワークをConvolutional Networkとして実装し、PASCAL VOCデータセットで評価する。ネットワークの初めの畳み込み層は特徴を抽出し、FC層は確率と座標を出力する。
我々のモデルはGoogLeNetをインスパイヤーしている。ネットワークは24層の畳み込み層と、その後ろに2層のFC層を持つ。GoogLeNetで使われているInception moduleの代わりに我々は3x3の畳み込み層の後に1x1のreduction layerを使用する。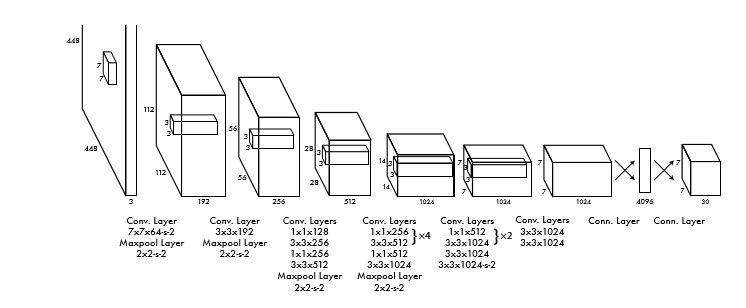 ネットワークの全体像を以下に示す。
ネットワークの全体像を以下に示す。
我々は速さの限界を引き上げるために設計されたfast version of YOLOも訓練した。fast versionは24層の畳み込み層の代わりに9層の畳み込み層を利用し、各層のフィルター数も減らしている。それ以外のパラメータはオリジナルのYOLOと変わらない。ネットワークの最終層の出力は7x7x30のテンソルである。
Training
我々は畳み込み層をImageNet 1000-class competition datasetで事前学習した。事前学習には20層の畳み込み層を使用した。我々はこのネットワークをおおよそ1週間訓練し、ImageNet 2012のvalidation setにおいて、single cropで88%の精度を獲得し、GoogLeNetと同程度の精度を獲得した。
我々は、その後モデルを検出を行うためのものに変換した。Ren氏は事前学習したネットワークに畳み込み層とFC層を追加することでネットワークのパフォーマンスを向上させることができることを示した。この例に従って、乱数で初期化した重みをもつ4層の畳み込み層と2層のFC層を追加した。検出にはきめ細かな視覚的情報が必要とされるため、ネットワークの入力解像度を224x224から448x448に増加した。
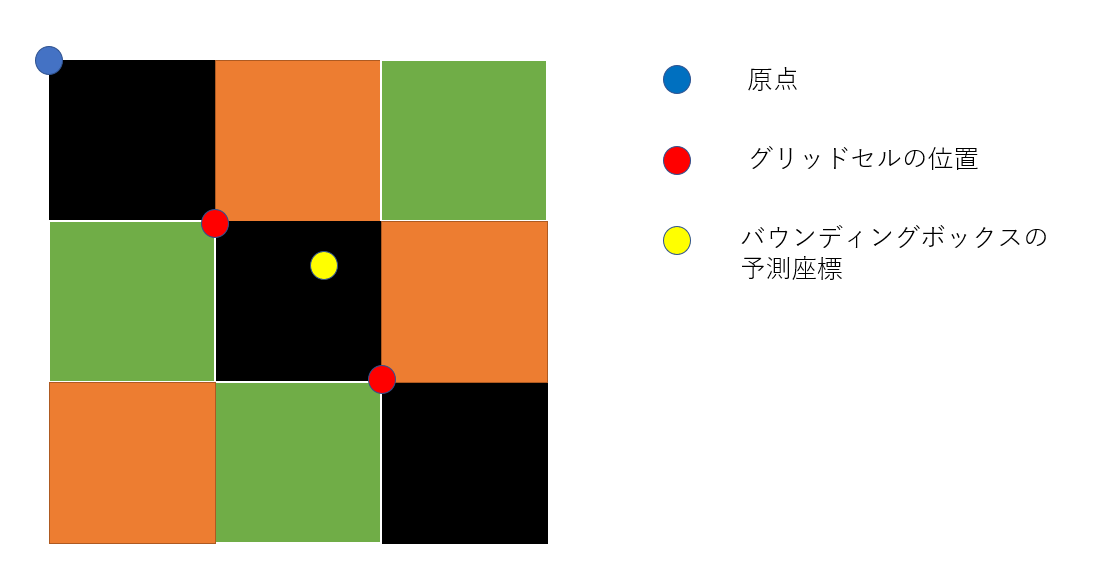
最終層はクラス確率とバウンディングボックスの座標の両方を予測します。我々はバウンディングボックスの幅と高さを入力画像の幅と高さで正規化し、0~1に落とし込む。バウンディングボックスのx座標とy座標の予測値を0~1に落とし込むために特定のグリッドセルの位置のオフセットになるようにパラメター化する。(オフセットになるようにパラメータ化ってよくわからないのですが、バウンディングボックスの予測中心座標(x,y)をグリッドセルの原点から遠い方の角の座標(xmax,ymax)と原点に近い方の座標(xmin,ymin)でmin-max Normalizaionしたなら0~1になるから、そういうことなんですかね)
我々は最終層に対し、線形活性化関数を使用し、他のすべての層には以下のLeaky Rectified Linear activation(Leaky ReLu)を使用する。
Φ_x= \left\{
\begin{array}{ll}
x & (x \gt 0) \\
0.1x & (x \le 0)
\end{array}
\right.
モデルの出力の二乗和誤差を最適化する。二乗総和誤差を使用するのは最適化が簡単だからである。しかし、それは、Average Precision(AP)を最大化するという我々の目的を達成するには少し問題がある。それは、理想的でないかもしれない分類誤差と位置の誤差を同様に重みづけしてしますことである。画像中の多くのグリッドセルは物体を含んでいない。このことはconfidence scoreを0に追いやってしまう。それは、物体を含んでいるセルの勾配を圧倒してしまうためである。これはモデルの不安定性を引き起こす可能性があり、誤差の早い段階での発散の原因となる。
これの対処法として、バウンディングボックスの座標の予測値による誤差を増加させ、物体を含んでいないボックスのconfidenceの予測値による誤差を減少させる。我々はλcoord=5とλnoobj=0.5を使用する。
二乗総和誤差は同様に大きいボックスと小さいボックスの誤差を同様に重みづける。我々の誤差関数は、小さな偏差があったとして、大きいボックス内の偏差は小さいボックス内の偏差よりも小さく扱うようにするべきである。部分的にこれに対処するために、ボックスの幅と高さを誤差関数内で直接使うのではなく、ルートをとった値を誤差関数内で使用する。YOLOは各グリッドセルごとに多くのバウンディングボックスを予測する。訓練時は各物体を担当する(責任を負った)1つのバウンディングボックスを予測する予測器が欲しい。我々は1つの予測器がある物体の予測を「担当している(責任を負っている)」状態を、その時点でもっとも高いIoUとなる予測を行うものに割り当てる。これは、各バウンディングボックス予測器を、ある物体に特化した予測器とすることができる。各予測器は全体のrecallを向上させることで、特定のサイズ、アスペクト比、物体のクラスを予測することにおいてよくなる。訓練中は、以下の複数のパートに分かれた誤差関数を最適化する。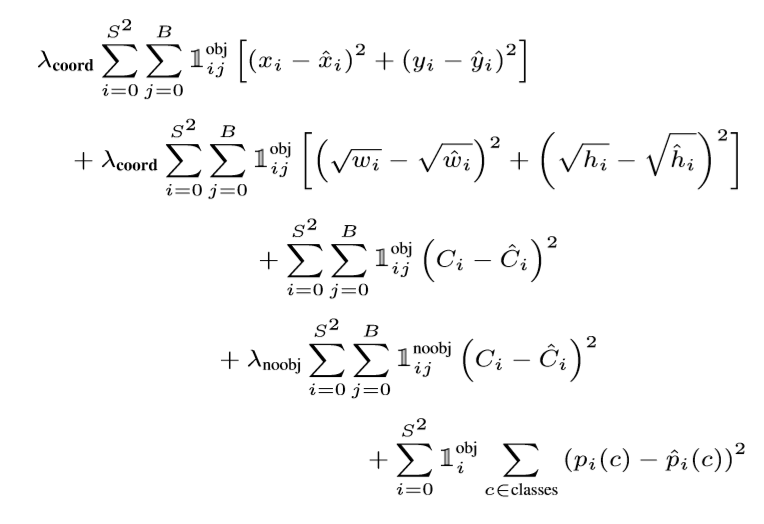 (書くのが面倒だったのでスクショとりました)
(書くのが面倒だったのでスクショとりました)
1objiはi番目のセル内に物体が存在すること、そして、1obji,jはi番目のセルで予測されるj番目のバウンディングボックスは予測を「担当している(責任を負っている)」ことを示す。
誤差関数は、グリッドセル内に物体が存在するとき分類誤差に罰則を与える(誤差が大きくなる)ことに気づく(上記の条件付きクラス確率より)。同様に、バウンディングボックスの座標誤差は予測器がground truthを担当しているとき罰則を与える(予測器がグリッドセル内で最大のIoUを持っている場合)。
モデルはPASCAL VOCデータセットの2007と2012の訓練セットと確認用セットを用いて135epoch訓練した。取れイニング中はバッチサイズを64、慣性項を0.9(momentum)、減衰(decay)を0.0005とした。
学習率は後述のように管理した。最初は10^-3から10^-2までゆっくり増加させた。学習率を最初から大きく設定すると誤差関数の勾配が安定しないためモデルが発散してしまう。その後、10^-2で75epoch、10^-3で30epoch、最後に10^-4で30epoch訓練した。
過学習を避けるために、dropoutと拡張的なデータ水増しを行った。最初の結合層の後にdropoutを0.5のパラメータとともに設置することでレイヤ間の共適応を防ぐ(共適応ってなんですかね。突然変異?なのかな)。データの水増しに関しては、ランダムなスケーリングと平行移動を元画像の20%行い、露光や彩度をHSV色空間における1.5の要素を最大としてランダムに調整する。
Inference
訓練と同じように、テスト画像に対する予測はたった一つのネットワークの評価で済む。PASCAL VOCでは各画像ごとに98のバウンディングボックスと各ボックスに対するクラス確率を予測した。分類ベースの手法とは違い、YOLOは1つのネットワークの評価を行うだけでいいのでテスト時には極端に速い。グリッドはバウンディングボックス予測における空間的な多様性を強要する(バウンディングボックスの各要素をベクトル化したときに、それが存在する超空間はむしろ制限される気がするのですが)。たいていどのグリッドセルに物体が存在するかはは明確で、ネットワークは各物体に対して、1つのバウンディングボックスを予測する。一方で、大きい物体や複数のセルの境界付近に存在する物体は複数のセルによって位置決めされる。Non-maximum suppressionはそれらの複数のセルによる予測を調整する。R-CNNやDPNのようにパフォーマンスにとって重要ではないが、Non-maximum suppressionは2-3%の精度向上をもたらした。
Limitations of YOLO
YOLOはバウンディングボックスの予測において強い空間的な拘束を受ける。それは、各グリッドセルはたった2つのバウンディングボックスと1つのクラスしか予測できないためである。この空間的な拘束は我々のモデルが予測できる物体の付近に存在する物体の予測を制限する。我々のモデルは、鳥の群れのような、小さな物体がグループとなっているものの検出は苦手だ。
我々のモデルはデータからバウンディングボックスを予測することを学ぶため、新しいかったり、普段通りでないアスペクト比や輪郭の一般化に苦労する。我々のアーキテクチャは多くのダウンサンプリング層を持っているため、バウンディングボックスを予測するときには比較的粗い特徴を使用することになる。
最後に、誤差関数を訓練している間に、我々の誤差関数は小さなバウンディングボックス内と大きなバウンディングボックス内の誤差を同じように扱っていた。大きいボックス内の小さな誤差はいいものの、小さなボックス内の誤差はIoUに大きな影響を与えていた。主な誤差の要因は不正確な位置決めにあった。
まとめ
これ以降は他のモデルと比べてどうだとかの話だったので省略します。わかった気になっていますが実装をしてみると理解しきれていない部分が浮き彫りになると思います。その時に、この記事を更新しようかなと思っています。