はじめに
OpenShiftではインストール時のデフォルトとしてクラスターモニタリングスタックが利用可能です。AzureのマネージドOpenShiftであるARO(Azure Red Hat OpenShift)でもそれは同様で、AROインストール時点でクラスターモニタリング用のPrometheus(/Alertmanager)/Grafanaがデプロイされています。
クラスター内の各種メトリクスを取得・蓄積するPrometheusにおいて、セルフマネージドのOpenShift(OpenShift Container Platform)ではメトリクスデータを貯めるストレージの永続化が設定可能です。
一方、AROではこの設定はOperatorにより制御されており、設定を投入しても反映されないようになっています。
AROのメトリクス・ロギングの取得については、基本的にAzure Arc対応のKubernetes用Container Insightsを使用することが推奨されています。しかしデータの永続化の目的だけでContainer Insightを使うのも費用対効果が薄いといったケースもなくはないと思います。
今回は、Victoria Metricsを使ってAROのクラスターモニタリングのメトリクスデータを永続ストレージに格納する方法をまとめます。PrometheusとVictoria Metricsの連携についてはこちらのスライドが大変参考になりますので、是非ご一読ください。
注意
今回の手順ではクラスターモニタリングの設定変更を行いますが、AROのサポートポリシーではPrometheus および Alertmanagerサービスの変更はNGとなっています。今回の設定によってMicrosoft/Red Hatのサポートが適切に提供されなくなる恐れがあること、ご理解の上対応ください。
前提条件
- AROクラスター:v4.10.20
- Cluster-admin権限を持つユーザー
手順
まずはProjectを作成します。
oc new-project victoria-metrics
このプロジェクト上にVictoriaMetrics OperatorとGrafana Operatorをデプロイします。
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: victoria-metrics-og
namespace: victoria-metrics
spec:
targetNamespaces:
- victoria-metrics
---
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: grafana-operator
namespace: victoria-metrics
spec:
channel: v4
installPlanApproval: Automatic
name: grafana-operator
source: community-operators
sourceNamespace: openshift-marketplace
startingCSV: grafana-operator.v4.6.0
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: victoriametrics-operator
namespace: openshift-operators
spec:
channel: beta
installPlanApproval: Automatic
name: victoriametrics-operator
source: community-operators
sourceNamespace: openshift-marketplace
startingCSV: victoriametrics-operator.v0.26.2
oc apply -f grafana-operator.yaml -f victoria-metrics-operator.yaml
Operatorがインストールできたら、実際にCRDを使ってVictoriaMetrics/Grafanaをデプロイします。
まずVictoria MetricsのCRDです。こちらはVictoria Metricsのクラスターをデプロイするためのyamlファイルです。
retentionPeriodや各リソースに必要なスペック・ディスク容量などは各自チューニングください。
いきなりドンズバのリソース設定は難しいかと思いますので、まずは仮値で設定後、開発環境などでアジャストすることをお勧めします。
ちなみにretentionPeriod: 4は4ヶ月間データを保持するといった意味になります。1y(1年間)や2w(2週間)といった設定も可能です。詳しくはこちらを参照ください。
kind: VMCluster
apiVersion: operator.victoriametrics.com/v1beta1
metadata:
name: example-vmcluster-persistent
namespace: victoria-metrics
spec:
replicationFactor: 2
retentionPeriod: '4'
vminsert:
replicaCount: 2
resources:
limits:
cpu: '1'
memory: 1000Mi
requests:
cpu: '0.5'
memory: 500Mi
vmselect:
cacheMountPath: /select-cache
replicaCount: 2
resources:
limits:
cpu: '1'
memory: 1000Mi
requests:
cpu: '0.5'
memory: 500Mi
storage:
volumeClaimTemplate:
spec:
resources:
requests:
storage: 2Gi
vmstorage:
replicaCount: 2
resources:
limits:
cpu: '1'
memory: 1500Mi
storage:
volumeClaimTemplate:
spec:
resources:
requests:
storage: 10Gi
storageDataPath: /vm-data
oc apply -f victoria-metrics-cluster.yaml
次にGrafanaをデプロイします。
本来ならばGrafanaもチューニングが必要ですが、今回はまずダッシュボードで閲覧できればよしとするので、以下のようにシンプルな設定にします。
後ほどデプロイするGrafanaDashboardリソースを識別するために、dashboardLabelSelectorを設定しておきます。
apiVersion: integreatly.org/v1alpha1
kind: Grafana
metadata:
name: custom-grafana
namespace: victoria-metrics
spec:
config: {}
dashboardLabelSelector:
- matchExpressions:
- key: app
operator: In
values:
- grafana
oc apply -f grafana.yaml
これでGrafanaとVictoria Metricsのコンポーネントがデプロイされました。
しっかりPVが作成されていることがわかります。
oc get pod,pvc,pv -n victoria-metrics
NAME READY STATUS RESTARTS AGE
pod/grafana-deployment-745fcc845f-dmhks 1/1 Running 0 27m
pod/grafana-operator-controller-manager-55b64cc88f-zgfxp 2/2 Running 0 36m
pod/vminsert-example-vmcluster-persistent-7c4cb4f764-brh94 1/1 Running 0 4h13m
pod/vminsert-example-vmcluster-persistent-7c4cb4f764-pzvff 1/1 Running 0 4h13m
pod/vmselect-example-vmcluster-persistent-0 1/1 Running 0 4h13m
pod/vmselect-example-vmcluster-persistent-1 1/1 Running 0 4h13m
pod/vmstorage-example-vmcluster-persistent-0 1/1 Running 0 4h13m
pod/vmstorage-example-vmcluster-persistent-1 1/1 Running 0 4h13m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/vmselect-cachedir-vmselect-example-vmcluster-persistent-0 Bound pvc-2ed20254-752b-4332-8bea-3fdff1ed73f8 2Gi RWO managed-premium 4h13m
persistentvolumeclaim/vmselect-cachedir-vmselect-example-vmcluster-persistent-1 Bound pvc-f7a2ac3b-7c79-4cbe-a65d-d53c8399efd3 2Gi RWO managed-premium 4h13m
persistentvolumeclaim/vmstorage-db-vmstorage-example-vmcluster-persistent-0 Bound pvc-272af200-54d4-49ff-afde-6ca2aec458e5 10Gi RWO managed-premium 4h13m
persistentvolumeclaim/vmstorage-db-vmstorage-example-vmcluster-persistent-1 Bound pvc-18a80105-dd5d-4968-8588-0f4a3ed1bf1d 10Gi RWO managed-premium 4h13m
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-18a80105-dd5d-4968-8588-0f4a3ed1bf1d 10Gi RWO Delete Bound victoria-metrics/vmstorage-db-vmstorage-example-vmcluster-persistent-1 managed-premium 4h13m
persistentvolume/pvc-272af200-54d4-49ff-afde-6ca2aec458e5 10Gi RWO Delete Bound victoria-metrics/vmstorage-db-vmstorage-example-vmcluster-persistent-0 managed-premium 4h13m
persistentvolume/pvc-2ed20254-752b-4332-8bea-3fdff1ed73f8 2Gi RWO Delete Bound victoria-metrics/vmselect-cachedir-vmselect-example-vmcluster-persistent-0 managed-premium 4h13m
persistentvolume/pvc-f7a2ac3b-7c79-4cbe-a65d-d53c8399efd3 2Gi RWO Delete Bound victoria-metrics/vmselect-cachedir-vmselect-example-vmcluster-persistent-1 managed-premium 4h9m
ではそれぞれのコンポーネントの連携設定を行います。
まずはクラスターモニタリング用のPrometheusからRemote Writeを使ってVictoria Metricsへデータを転送します。
AROのPrometheusはPrometheus Operatorで管理されていますが、さらにその上位のOperatorとしてCluster Monitoring Operator
が存在します。Prometheusへの設定は基本的にこのOperatorへ設定を渡して実現します。
Cluster Monitoring Operatorやその他のコンポーネントはopenshift-monitoringプロジェクト上に存在します。
oc get pods -n openshift-monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 6/6 Running 0 22h
alertmanager-main-1 6/6 Running 0 22h
cluster-monitoring-operator-5bbfd998c6-9lt58 2/2 Running 0 12h
grafana-5487f6d9cf-72xwk 3/3 Running 0 22h
kube-state-metrics-6d685b8687-6w9jb 3/3 Running 0 20h
node-exporter-9kvwc 2/2 Running 2 22h
node-exporter-dbsnk 2/2 Running 0 22h
node-exporter-fcdtp 2/2 Running 2 22h
node-exporter-fxrnt 2/2 Running 0 22h
node-exporter-gdwfr 2/2 Running 2 22h
node-exporter-qngtz 2/2 Running 0 22h
openshift-state-metrics-65f58d4c67-85l4k 3/3 Running 0 22h
prometheus-adapter-98b79f97-bqdc5 1/1 Running 0 3h33m
prometheus-adapter-98b79f97-g9wd6 1/1 Running 0 3h33m
prometheus-k8s-0 6/6 Running 0 12h
prometheus-k8s-1 6/6 Running 0 12h
prometheus-operator-76f79c8d85-s4qsg 2/2 Running 0 20h
thanos-querier-996bbbbfc-k67zk 6/6 Running 0 22h
thanos-querier-996bbbbfc-rn48x 6/6 Running 0 22h
Cluster Monitoring Operatorへの設定はcluster-monitoring-configConfigMapで管理されています。
oc get cm -n openshift-monitoring cluster-monitoring-config -o yaml
apiVersion: v1
data:
config.yaml: |
alertmanagerMain: {}
prometheusK8s: {}
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
dataを見ると、特に設定が入っていないことがわかります。こちらにRemote Writeの設定を投入します。
以下のようなyamlファイルを作成します。
urlにはvminsertのserviceのURLを設定します。またサブパスは/insert/0/prometheus/api/v1/writeを指定します。(こちらを参照)
apiVersion: v1
data:
config.yaml: |
alertmanagerMain: {}
prometheusK8s:
remoteWrite:
- url: "http://vminsert-example-vmcluster-persistent.victoria-metrics.svc.cluster.local:8480/insert/0/prometheus/api/v1/write"
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
oc apply -f cluster-monitoring-config.yaml
設定を反映させるために、prometheusを再起動します。
oc rollout restart statefulsets/prometheus-k8s -n openshift-monitoring
これでPrometheusとVictoria Metricsの連携が設定できました。
次にVictoria Metrics側に保管されたメトリクス情報をGrafanaから閲覧できるようDataSourceの設定を行います。
以下のyamlファイルを作成します。
Grafanaからへのアクセス先はvmselectのServiceのURLを指定します。サブパスは/select/0/prometheus/を指定します。
apiVersion: integreatly.org/v1alpha1
kind: GrafanaDataSource
metadata:
name: victoria-metrics-datasource
namespace: victoria-metrics
spec:
datasources:
- name: VictoriaMetrics
type: prometheus
url: >-
http://vmselect-example-vmcluster-persistent.victoria-metrics.svc.cluster.local:8481/select/0/prometheus/
access: Server
name: VictoriaMetrics
oc apply -f victoria-metrics-datasource.yaml
Grafanaの設定は自動で反映されるため、Podの再起動は不要です。
最後にGrafanaDashboardをデプロイしていきます。今回はクラスターモニタリングのデフォルトのダッシュボードと同じものを作るので、ConfigMapの情報を取得します。
まずはopenshift-monitoringプロジェクトにあるダッシュボードのConfigMapを、victoria-metricsプロジェクトへデプロイします。
patchコマンドでNamespaceを書き換えたyamlをapplyします。
oc patch cm grafana-dashboard-k8s-resources-namespace -n openshift-monitoring -p '{"metadata":{ "namespace":"victoria-metrics"}}' --dry-run=client -o yaml | oc apply -f -
次にこのConfigMapを参照するGrafanaDashboardを作成します。
apiVersion: integreatly.org/v1alpha1
kind: GrafanaDashboard
metadata:
name: grafana-dashboard-k8s-resources-namespace
namespace: victoria-metrics
labels:
app: grafana
spec:
configMapRef:
key: k8s-resources-namespace.json
name: grafana-dashboard-k8s-resources-namespace
oc apply -f grafana-dashboard-1.yaml
他のダッシュボードも上記を繰り返すことで設定できます。
ではGrafanaにアクセスしてみましょう。
以下のコマンドでRouteを作成します。
oc expose svc grafana-service -n victoria-metrics
Grafanaのadminのパスワードを取得しておきます。
oc get secret grafana-admin-credentials -n victoria-metrics --template={{.data.GF_SECURITY_ADMIN_PASSWORD}} | base64 -d
URLを取得してブラウザでアクセスします。
oc get route grafana-service -n victoria-metrics --template='{{ .spec.host }}'
ブラウザではadminとパスワードでログインします。
ログインして、ダッシュボードのManageを選択します。
先ほどデプロイしたGrafanaDashboardで設定されたダッシュボードが表示されていますので、選択します。
namespaceをvictoria-metricsなどに変更すると、Podのメトリクス情報が確認できることがわかります。
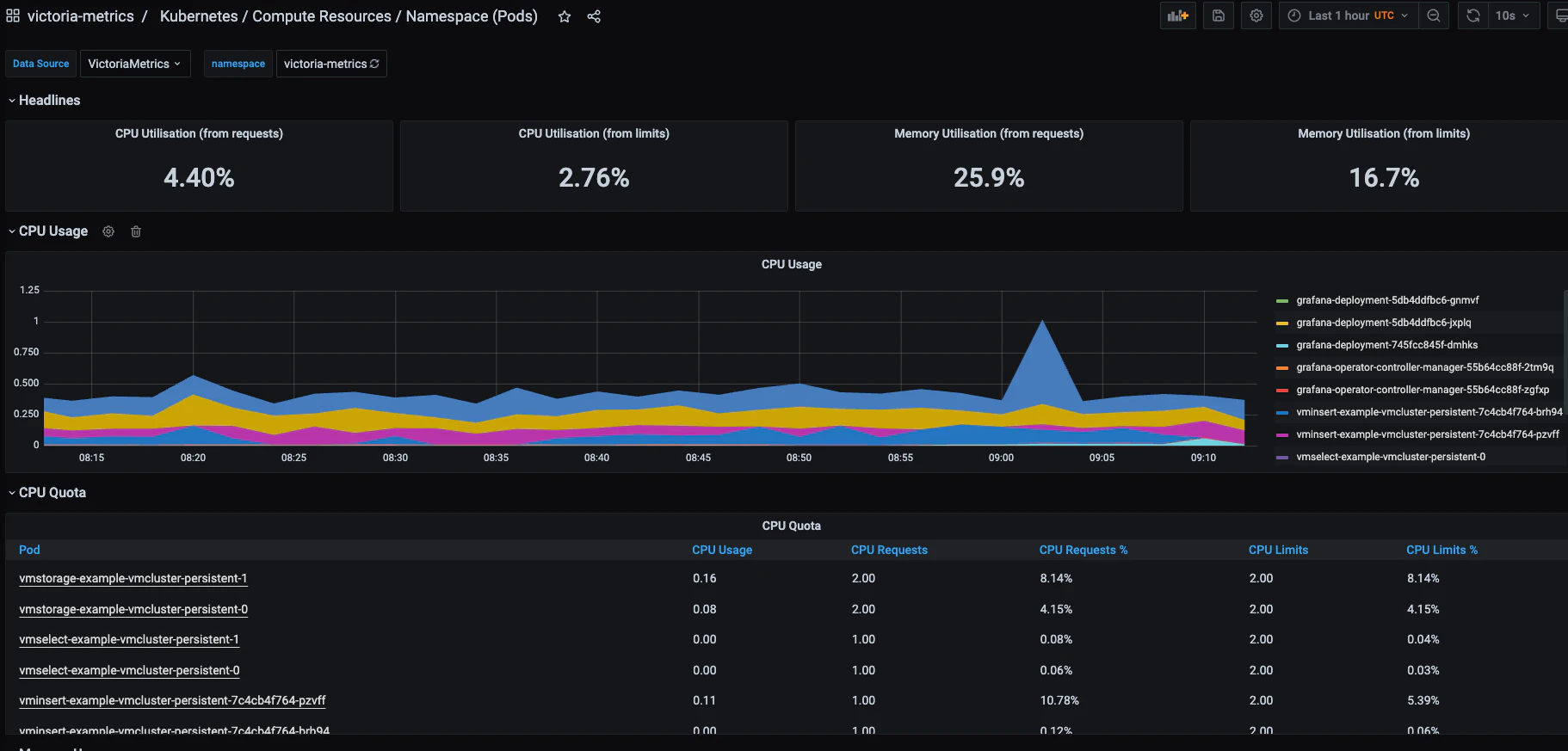
以上より、Victoria Metricsで永続化されたストレージ上にデータを保管し、かつGrafanaで閲覧できる環境が整いました。
短期的なデータなら既存のモニタリング環境を確認し、長期データを確認する場合はこちらのダッシュボードで確認するなど、使い分けをすると良いかと思います。