はじめに
みなさん、OpenShiftのアップグレードしていますか?
OpenShiftの運用のタスクの中で、多くの人が頭を抱えながら対応するものの筆頭がOpenShiftクラスターのアップグレードです。
ここでは、OpenShiftのクラスターアップグレードについて紐解き、Red Hatの中の人が推奨するアップグレードのベストプラクティスをお伝えします。
1.なぜOpenShiftアップグレードが必要なのか?
2.OpenShiftのライフサイクル
3.アップグレードの仕組み
4.アップグレードへの心構え
5.アップグレード戦略
6.おわりに
1. なぜOpenShiftアップグレードが必要なのか?
そもそもなぜOpenShiftのアップグレードが必要なのでしょうか?
理由としては大きく4つあります。
-
理由1. 新機能の追加
OpenShiftは日々開発が行われ、開発・運用の効率化を促進するための新機能が追加されていきます。OpenShift導入の目的を継続的に達成するためには、新機能をうまく活用していくことが必要ですので、OpenShiftをアップグレードし新機能をいち早く利用できる状態を作り上げるべきです。
-
理由2. バグのFIX
Kuberntes/OpenShiftはソフトウェアのため、バグが混入している可能性は0ではありません。そしてバグの対応は、基本的にパッチリリースを適用(アップグレード)する形になります。そのため、今利用しているOpenShiftに何らかの問題があり、それを迅速に対処するにはOpenShiftのアップグレードを素早く実施できる環境をととのえておく必要があります。なお、性能向上や安定化もパッチリリースに含まれます。
-
理由3. セキュリティ対策
OpenShiftではKubernetesのリリースサイクルに従いながらセキュリティパッチを提供します。利用者は定期的にセキュリティパッチを適用することで、脆弱性を突いた攻撃を防御することができます。逆にクラスターが塩漬けの状態であれば、どんどんセキュリティ的に脆弱になっているということになります。
-
理由4. サポート
おそらく多くのOpenShiftユーザーがアップグレードの対応理由としているのが、サポート期間の遵守だと思います。OpenShiftはKubernetesのリリースサイクルに準拠した形で新バージョンがリリースされます。
Kubernetesのサポート期間が1年間のため、OpenShiftもある程度その期間に縛られた形でサポート期間が設定されています。2023年12月時点では最長で24ヶ月のサポート期間を提供しているため、どれだけ長くても2年ごとにはOpenShiftをアップグレードしなければならないことになります。
2. OpenShiftのライフサイクル
OpenShiftのライフサイクルを語る前に、OpenShiftのバージョンの採番方針をお伝えします。
例えば、以下のようなOpenShiftのバージョンがあったとします。
OpenShift 4.14.5
-
メジャーバージョン
例で言うと"4"がOpenShiftのメジャーバージョンになります。このバージョンが違えば基本的に別の製品だと認識いただいてOKです。(5がどうなるのかは不明ですが・・・)
別製品レベルで異なる前提のため、アップグレードよりマイグレーションでの対応を推奨します。要は新しいクラスターを作ってアプリを引っ越す対応になります。
大規模な新機能の追加や既存機能の削除が発生するため、慎重なテストが必要です。
-
マイナーバージョン
例で言うと"14"がOpenShiftのマイナーバージョンになります。ひとつバージョンが変わるごとに新規パッケージの追加や機能拡張を含みます。およそ3〜4ヶ月に1回出荷し、kubernetesの特定のマイナーバージョンと連動します。例えば、OpenShift 4.14はKubernetes 1.27をベースとしています。一般的によくOpenShiftのアップグレードとして認知されているのがこのマイナーバージョンの更新になります。
-
パッチバージョン
重要なセキュリティ問題やバグの修正になります。機能拡張は行わず、およそ1〜2週間に1回出荷されます。
バグの修正も含まれるため、何かしらOpenShift利用中に不具合が発生しサポートに問い合わせると、特定のパッチバージョンに上げてくれ、という回答をもらうことも少なくありません。毎回一生懸命上げる必要はありませんが、突発的にこのパッチバージョンだけ上げるという作業が発生する可能性があります。
以上を踏まえ、OpenShiftのライフサイクルを確認してみましょう。
なお、OpenShiftにはRed HatからSubscriptionを購入し、ユーザー自身で構築・管理を行うOpenShift Container Platform(OCP)と、AWSやAzureで提供されているManagedなOpenShift(ROSA/ARO)の大きく2種類があります。それぞれの製品においてライフサイクルが異なるため、分けて説明します。
OpenShift Container Platform (Self-Managed OpenShift / OCP) のライフサイクル
OpenShift Container Platformのライフサイクルについては、こちらのページに詳細がまとまっています。
ここではかいつまんで説明していきます。
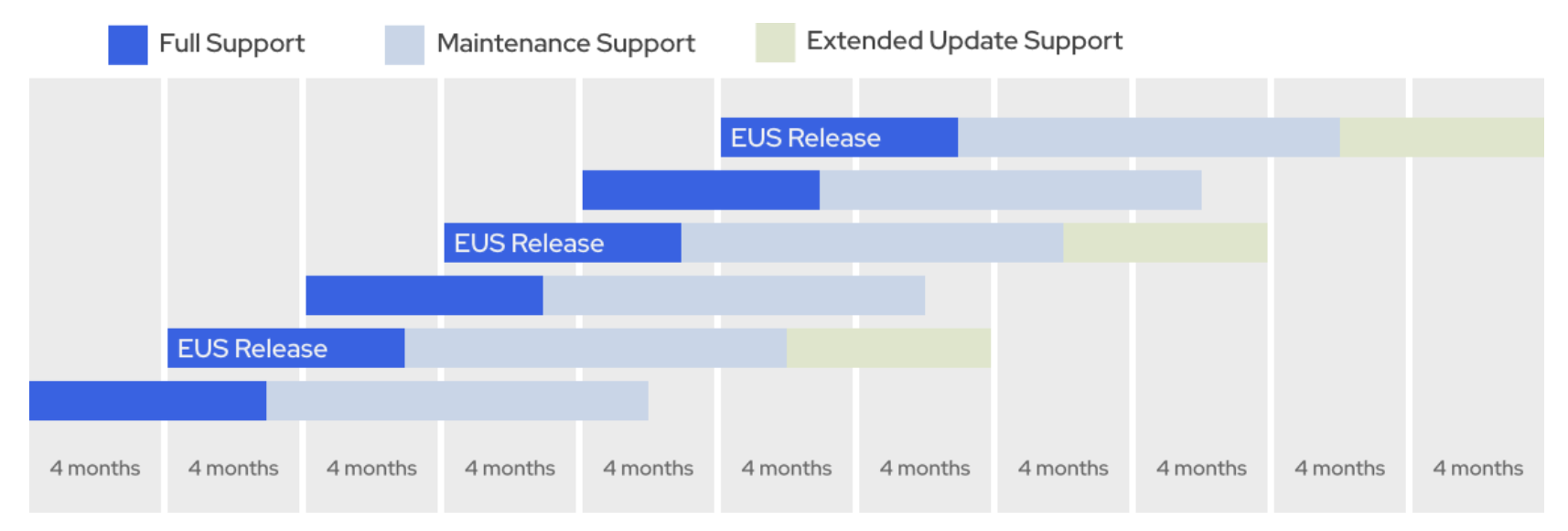
OpenShiftはおよそ4〜6ヶ月程度で新しいマイナーバージョンをリリースします。このマイナーバージョンでは2つ、もしくは3つのライフサイクルフェーズが定義されており、そのフェーズを理解した上でアップグレードのスケジュールを検討する必要があります。
-
奇数のマイナーバージョン
4.11 , 4.13など、奇数となるマイナーバージョンにおいては、18ヶ月のサポート期間が設定されています。
フェーズはFull SupportとMaintenance Supportの2種類から構成されます。
-
偶数のマイナーバージョン
4.12 , 4.14など、偶数となるマイナーバージョンにおいては、24ヶ月のサポート期間が設定されています。
フェーズはFull SupportとMaintenance Support、そしてExtended Update Supportの3種類から構成されます。
- フェーズごとのサポート内容
OpenShiftのフェーズごとのサポート情報は以下の通りです。
| フェーズ | 期間 | サポート内容 |
|---|---|---|
| Full Support | マイナーバージョンの一般提供 (GA)に開始。 以下のいずれかの遅い方まで ・GAから6カ月後 ・後続のマイナーリリースのGAから90日後 |
セキュリティアドバイザリー(RHSA):重大・重要 バグ修正アドバイザリー(RHBA):緊急・一部の高 機能強化アドバイザリー(RHEA):定期的な製品アップデートを通じてリリース |
| Maintenance Support | Full Supportフェーズ後に開始 最大で12カ月間 ※フルサポートが6ヶ月以上の場合はフル+マイナーが合計18ヶ月になるよう調整 |
セキュリティアドバイザリー(RHSA):重大・重要 バグ修正アドバイザリー(RHBA):緊急・一部の高 機能強化アドバイザリー(RHEA) :Red Hat判断でリリースされるが、リリースされないものもある |
| Extended Update Support (EUS) | Maintenance Supportフェーズ後に開始 偶数番号のマイナーリリース (4.12、4.14 など)に適用される ・6カ月間 |
Maintenance Supportと同様 |
見ていただくとわかる通り、機能強化の面で多少の差があるものの、セキュリティ対応やバグFIXについては、どのサポートも同様のレベルにて実施されるので、あまりFull SupportとMaintenance Supportの違いに敏感にならなくても大丈夫です。
ROSA (Red Hat OpenShift Service on AWS) のライフサイクル
ROSAはAWSとRed Hatの共同で管理される関係上、独自のライフサイクルを持っています。
- メジャーバージョン (X.y.z)
後続のメジャーバージョンの提供開始から1年間サポートを提供
- マイナーバージョン (x.Y.z)
基本は提供開始から16ヶ月間サポートを提供
- パッチバージョン (x.y.Z)
基本はマイナーバージョンの期間に準拠
重要なバグ/脆弱性の修正は2営業日以内に適用の必要あり (2営業日以降は自動適用の可能性あり)
メジャー・マイナー・パッチのバージョンの位置付け自体はSelf-ManagaedなOpenShiftと同様です。
マイナーバージョンのライフサイクルが16ヶ月と、Self-Managaedの奇数バージョンよりも短いため注意が必要です。
また、パッチバージョンにおいては重要なバグやセキュリティ脆弱性が発生した場合、ユーザーの意思を待たずして強制的にアップグレードが走る可能性があります。
ARO (Azure Red Hat OpenShift) のライフサイクル
AROもROSAと同様、独自のライフサイクルを持ちます。
- メジャーバージョン (X.y.z)
2023/12時点ではサポートポリシー未定義
- マイナーバージョン (x.Y.z)
〜4.11
2つのマイナーバージョンをサポート (最新と1つ前)
4.12〜
基本は提供開始から14ヶ月間サポートを提供
- パッチバージョン (x.y.Z)
基本はマイナーバージョンの期間に準拠
重要なバグ/脆弱性の修正は自動適用の可能性あり
AROの場合は14ヶ月とROSAよりもさらに短いライフサイクルになります。
その他はほぼROSAと同様のポリシーです。
3. アップグレードの仕組み
さて、ようやくOpenShiftアップグレードの中身についてお伝えします。
まず、皆さんご存知の通りOpenShiftは"Over The Air(OTA)アップグレード"という独自の機能を具備しています。この機能を使うと、Kubernetesのレイヤだけでなく、OpenShiftが持つ様々な管理コンポーネントやノードのOSも含めて一括でアップグレードを実行することができます。OpenShiftでアップグレードというと、基本的にはこのOTAアップグレードを指します。
ただし、このアップグレードではユーザーがOpenShiftデプロイ後にインストールしたOperatorや、Deployment、ServiceなどのKubernetesマニフェストはアップグレードの対象外になります。これらはクラスターのアップグレード後に適宜バージョンアップの対応が必要になるのでご注意ください。
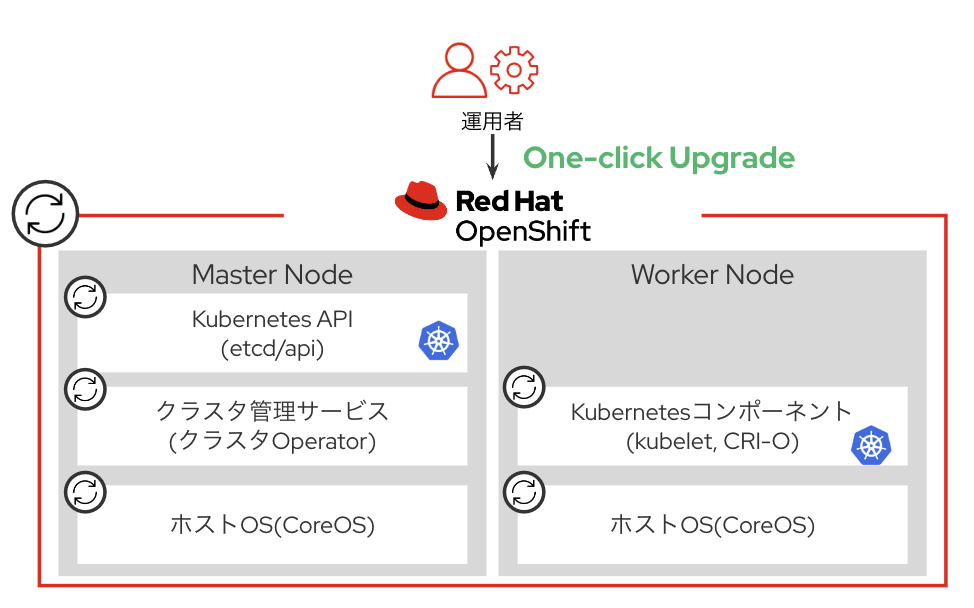
アップグレードの流れ
OpenShiftはクラスター内のCluster Version Operatorがアップグレードの実行・管理を行います。アップグレードは Cluster Operator → Control Plane → Worker Node の順に実行されます。
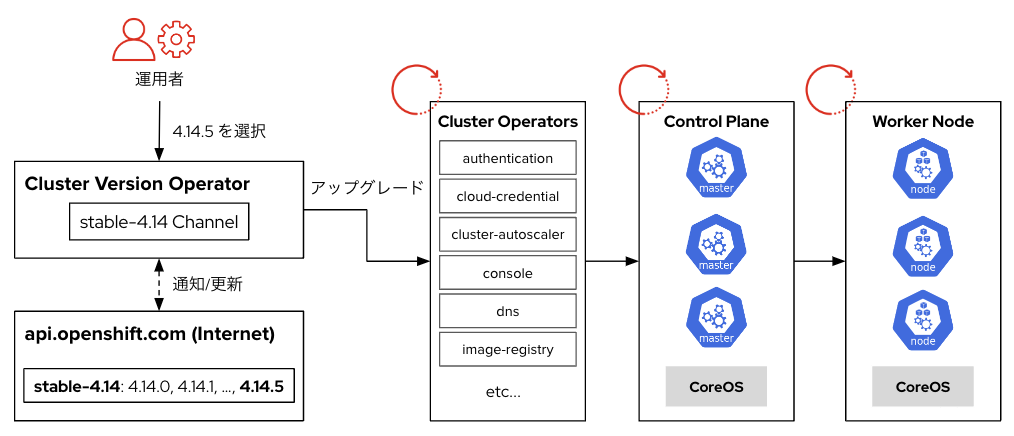
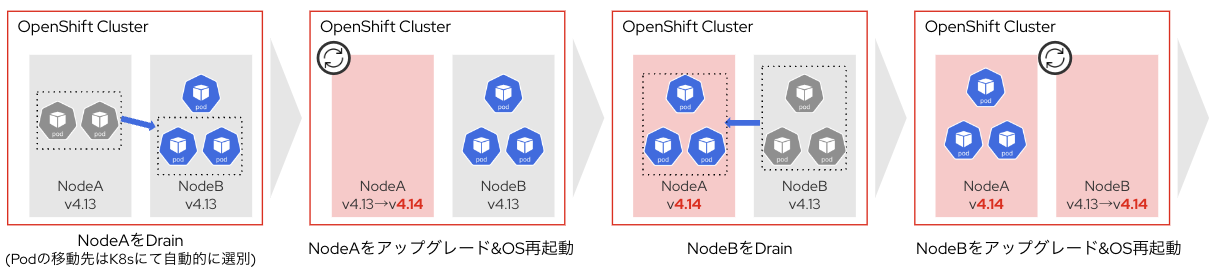
Control PlanおよびWorker Node のアップグレードは1台ずつ実行されます。
アップグレードの際はノードのOS再起動が発生するため、事前に対象のノードのPodに対して退避処理(Drain)が行われます。
4. アップグレードへの心構え
OTAアップグレードの簡単な仕組みが分かったところで、いよいよ本題のアップグレードの戦略について掘り下げていきます。
が、その前にOpenShiftのアップグレードへの心構えをお伝えします。
OpenShift アップグレードにはアプリの変更業務が伴う
OpenShiftはInfrastructureではなくPlatfromであるため、従来のInfrastructureのアップグレード(例:vSphere/vCenterのアップグレード)とは異なり、アプリケーションレイヤへの影響がないことを担保するものではありません。
OpenShiftで開発・運用しているアプリ担当者は、OpenShiftのアップグレードがアプリに影響を与えることを理解した上で利用する必要があります。
-
アプリ開発者が動作を担保する範囲
OpenShiftアップグレードはアプリ側の変更が不要なことを担保しません。バージョンアップによってアプリの動作に影響があった場合はアプリ開発者でも状況を確認し、必要に応じて変更作業を行いましょう。
-
Platform管理者が動作を担保する範囲
OpenShiftのコアコンポーネントや管理系のOperator、およびPlatform管理者が管理するツール群のアップグレードはPlatfrom管理者が対応します。なお、OpenShiftアップグレードによって運用業務の変更が発生する可能性があることを理解しておきましょう。
5. アップグレード戦略
OpenShiftにおいては、Kubernetesと同様、大きく3つの戦略から選択することになります。
-
In-placeアップグレード
単一クラスターでアップグレードを実行するシンプルな方法です。もし本番環境でこのアップグレードを採用する場合は、搭載しているワークロードの可用性を維持しながらアップグレードを完了する必要があります。
アプリへの影響が発生しやすいため、アプリケーションの構成やマニフェストの設定における考慮が必要です。
-
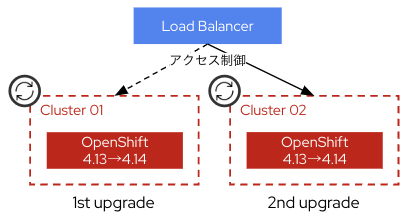
Blue/Greenアップグレード
クラスターを複数準備し順番にIn-placeアップグレードを行う手法です。クラスターの上段にあるネットワーク装置(DNS/LBなど)でアップグレード前に対象のクラスターをサービスアウトし、アプリの可用性に影響の出ない状態でクラスターをアップグレードしていきます。
-
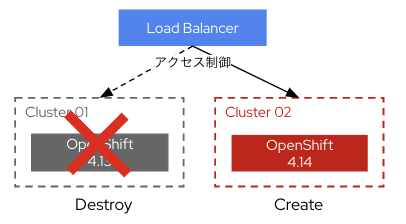
Recreateアップグレード
Blue/Gleenに似ていますが、In-placeではなく新バージョンのクラスターを新規作成した上でアプリケーションを移行していきます。ネットワークの切り替えで本番適用後、しばらくした上で旧バージョンのクラスターを削除します。
In-placeアップグレード
In-place方式では、搭載しているワークロードの可用性を維持しながらアップグレードを完了する必要があります。Blue/Green方式に比べてアプリへの影響が発生しやすいため、アプリケーションの構成やマニフェストの設定における考慮が必要です。ここではいくつかの方針を取り上げてみます。
Podの分散配置
アップグレード時のOS再起動に伴い、PodのDrain処理が行われるため、アプリケーションを構成するPodがひとつのノードに偏っていると、Drain時にサービス断が発生します。K8sマニフェストの設定でPodを複数ノードに分散配置させるなどの対応が必要です。
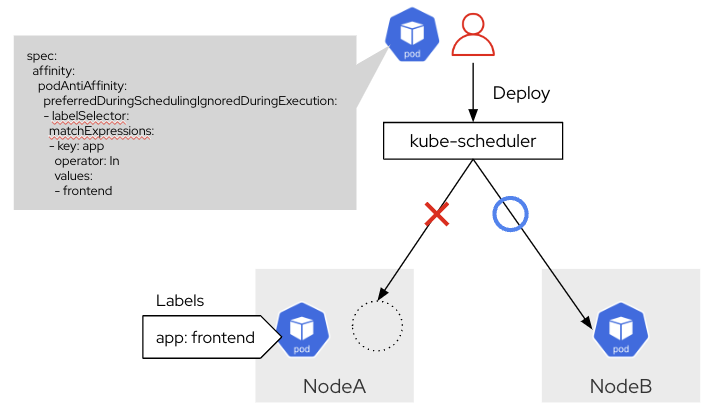
Inter-Pod Anti-Affinity
「特定の条件のPodが存在しない」ノードにPodをデプロイするための設定です。Deploymentに自身のPodのラベル条件を指定することで、配置するPodを分散できます。アップグレード時は後述のPodDisruptionBudgetでサービス断に対応可能ですが、ノード障害には対応できないため本設定と組み合わせを推奨します。
Drain時のPod数を制御
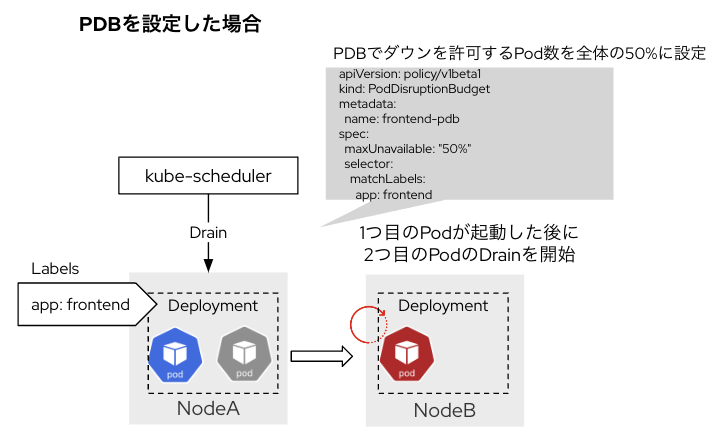
万が一Podがひとつのノードに偏っていても、PodDisruptionBudgetを設定しておくことで安全にDrain処理を実行できます。DrainするPodの数をコントールして、該当のPodが全てダウンすることを防ぎます。
PodDisruptionBudget(PDB)
Drain処理の際に停止可能なPodの数を指定できます。
-
PDBを設定していない場合
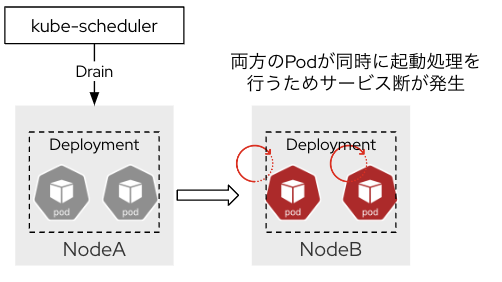
-
PDBを設定した場合
ステートレス化
Pod内にステートフルデータを持っていると、Drain処理の際にデータが消失するため、外部に切り出す必要があります。ただし外部の切り出し方によってはPVを使ってもデータを引き継げない可能性があるため、注意が必要です。
例えばAWSでEBSをPVとして利用した場合、そのPVは同じAZ上のノードにいるPodのみマウントすることができます。もし各AZに1台ずつしかノードがない状態でアップグレードすると、Podは別のAZにあるノードにDrainされ、再起動を試みます。しかしPVがマウントできず、PodがPendingとなっていまいます。
この事象を回避するためには、各AZに2台以上のノードが存在する状態でアップグレードを実施する必要があります。
Podの正常終了処理
PodのDrainではPodの終了→作成の処理が発生するため、Podの終了処理を適切に設定しておく必要があります。本設定によって、Drainによるアプリケーションの不具合を回避したり、Drain処理の時間を短縮することができます。
以下にPodの終了プロセスとGracefulShutdownのサンプルを載せています。
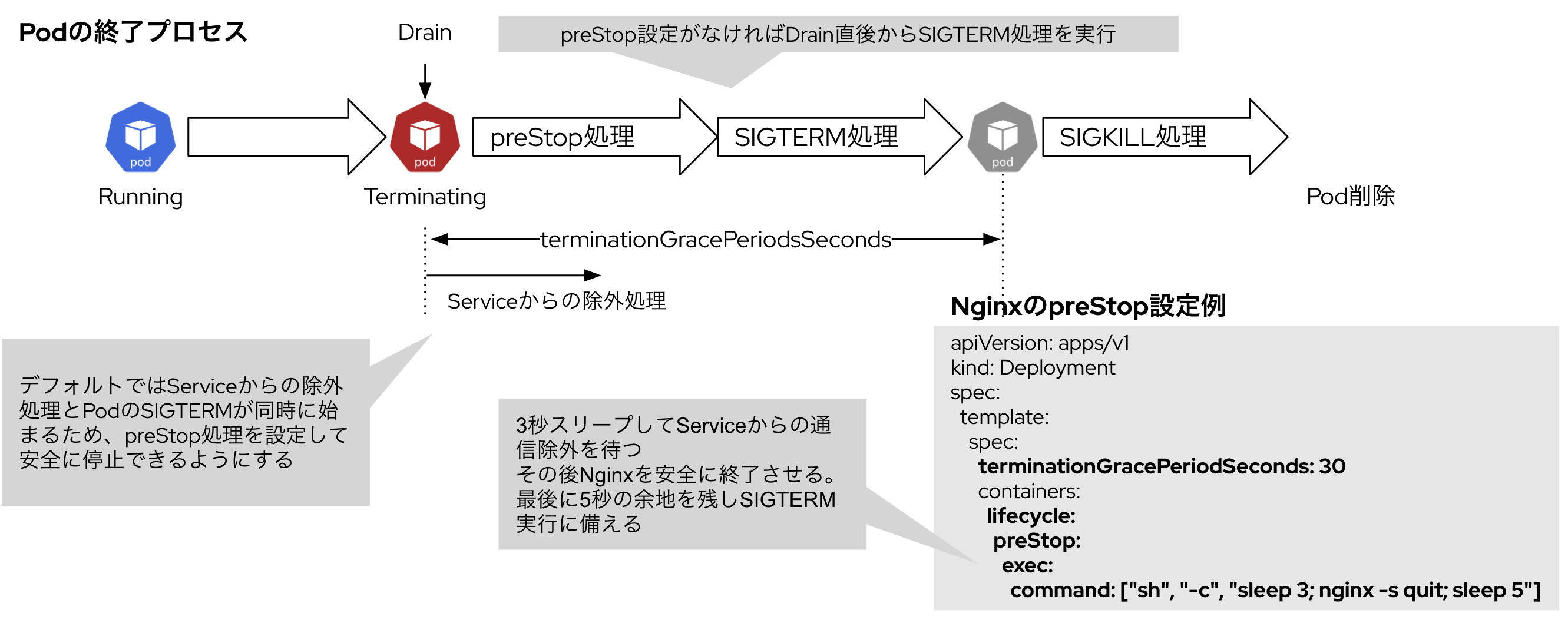
Blue/Greenアップグレード
マルチクラスター構成を取りBlue/Greenアップグレードを実施することで、ノード停止を意識せずに安全にアップグレードを実現できます。各クラスターのアップグレードはOpenShiftのOTAアップグレードにて対応します。
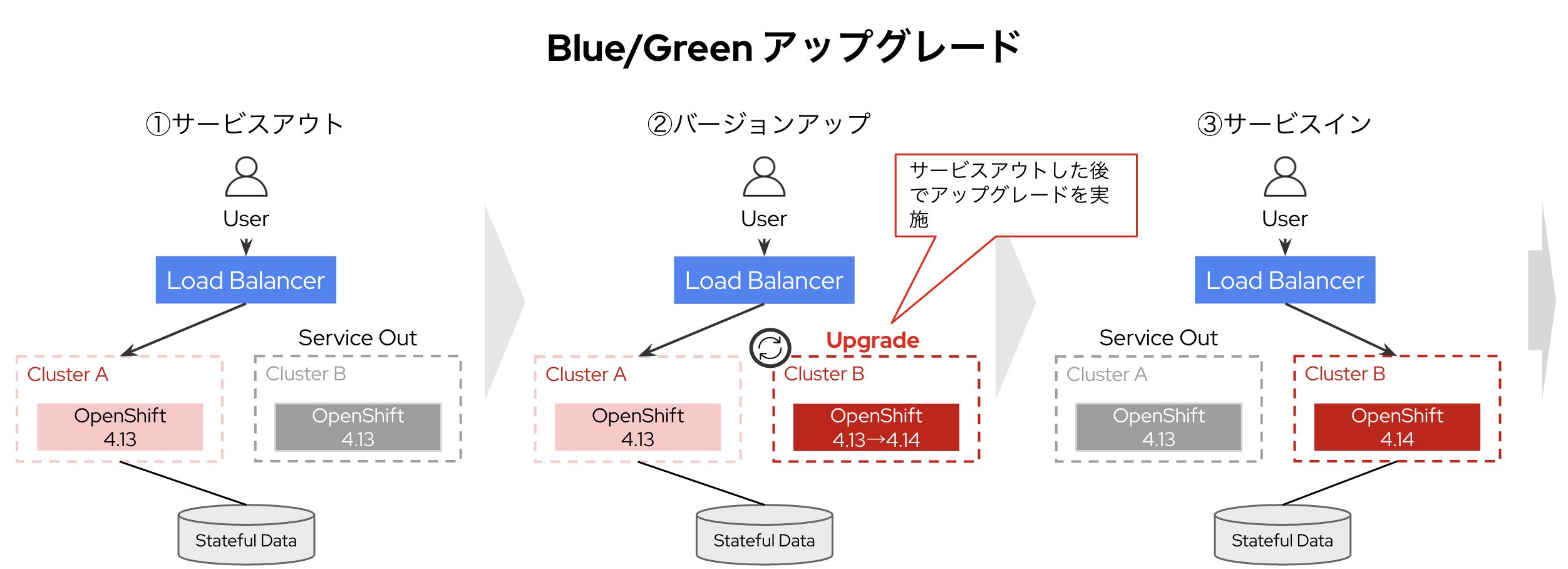
クラスターの切り替え方式
BlueとGreenのクラスターの切り替え方法として、よく使われるのがDNSによる切り替えとLoadBalancerによる切り替えです。
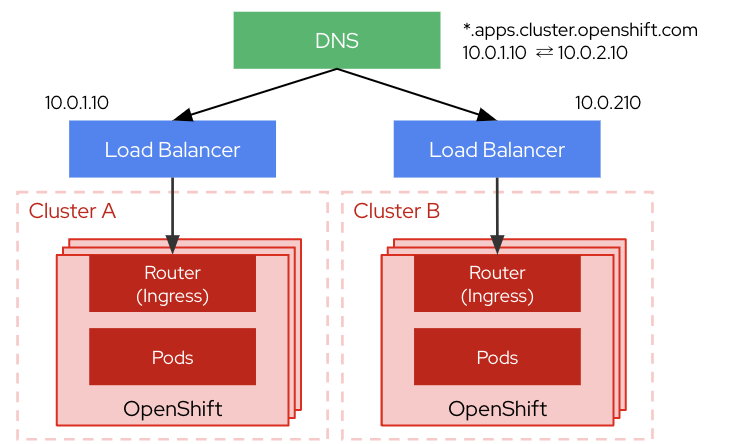
DNSによる切り替え
クラスターのDNSのAレコードを書き換えてルーティングを制御します。
構成や切り替えの設定方法がシンプルですが、TTLを意識した運用が必要になります。
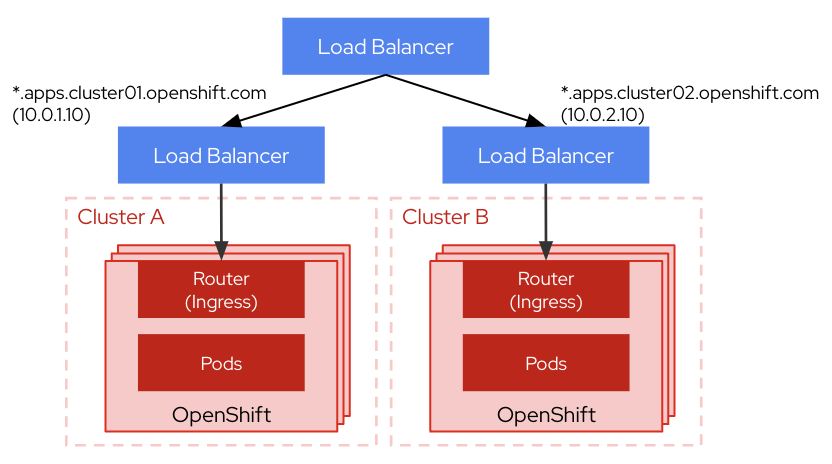
LBによる切り替え
クラスターの前段にLoad Balancerを設置してルーティングを制御します。
細かいルーティング制御や切り替えの即時反映が可能ですが、SPOFの増加や設定の管理の煩雑化の恐れがあります。
それぞれ一長一短のため、アプリケーションの可用性やその他の特性を鑑みて切り替え方式を決定します。
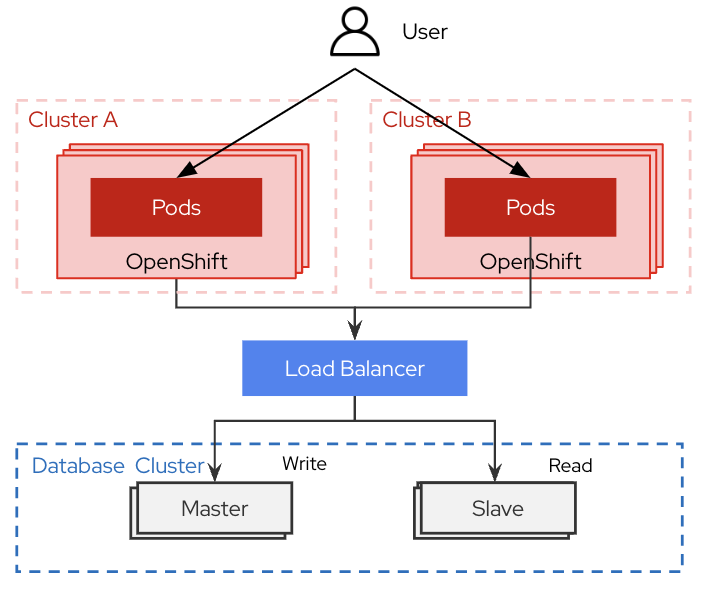
データの外部管理
Blue/Greenでは基本的にステートフルなデータはクラスターの外部に切り出しておく必要があります。そのため、PVの利用も基本は避けるべきです。ネットワーク経由でDBやNFSにアクセスする方式とし、クラスターは最大限ステートを持たない状態を維持します。
Recreateアップグレード
クラスターをアップグレードするのではなく、新しいバージョンで新規作成し、切り替え後に旧クラスターを削除します。
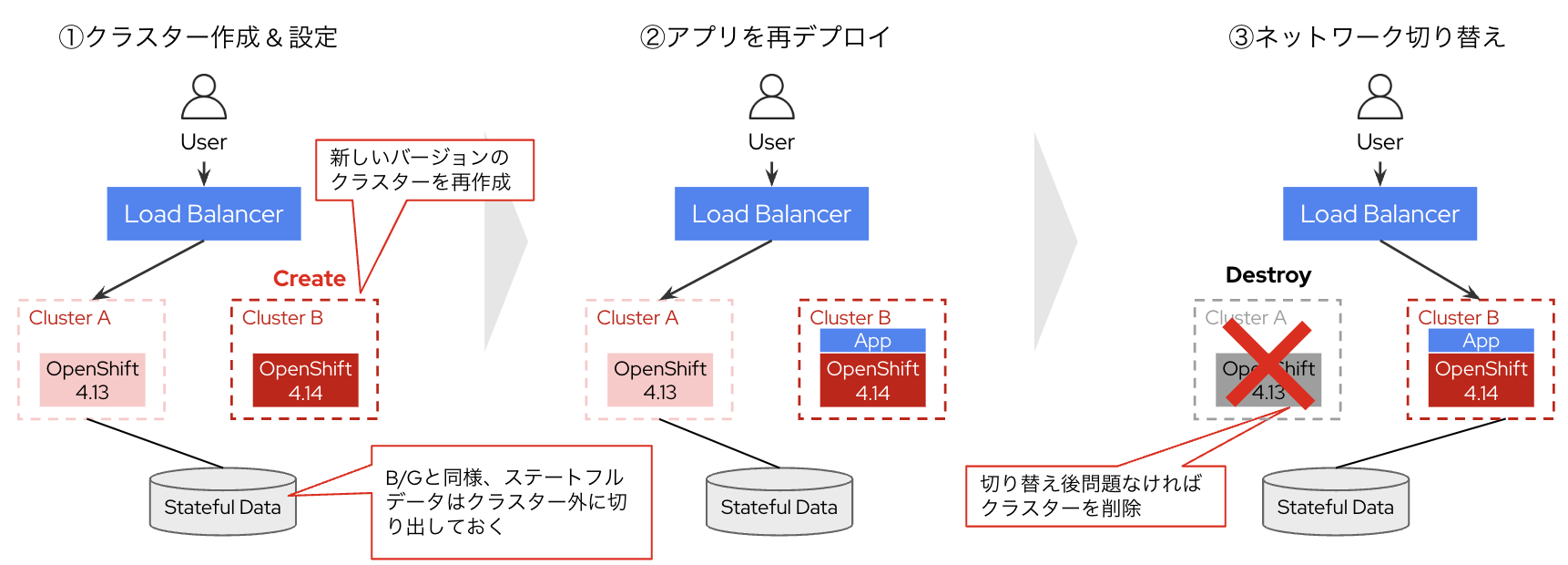
このRecreateはIn-placeやBlue/Greenと比べて、さまざまなメリットを持っています。
メリット1: Before / After のバージョン互換性を気にしなくていい
OpenShiftを一度でもアップグレードしたことがある人ならわかるかと思いますが、OpenShiftは通常のKubernetesと比べてアップグレードパスをより意識しながらアップグレードを検討する必要があります。
OpenShiftはこちらでアップグレード可能なBeforeとAfterを確認できるのですが、みていただくといろいろな理由でアップグレードのパスが制限されていることがわかります。
またOpenShiftのリリースの方針上、新しいマイナーバージョンのGAは、旧バージョンからのアップグレードパスの保証とは無関係に行われます。 そのため、In-placeの場合は新しいバージョンがリリースされてもすぐにアップグレードすることができず、アップグレードパスが繋がるまで待機する必要があります。
その点においてRecreateでは、Beforeのバージョンに捉われることなく、新バージョンの導入が可能です。
新規作成のため、アップグレードパスは気にしなくていいですし、GAは新規構築ができる状態が保証されるため、すぐに新バージョンを試すことができます。
このBeforeを気にしなくていいというのは、OpenShiftだけでなく、その上にインストールするOperatorにも影響します。
Operatorのアップグレード
OpenShiftをアップグレードする際に欠かせない検討項目のひとつが、Operatorのアップグレードです。ここでいうOperatorとは、クラスター構築時にデフォルトでインストールされているものではなく、クラスター構築後にユーザーが追加でインストールするOperatorを指します。
Red Hatが提供するOperatorは3種類のライフサイクルに分類されます。ユーザーはそれぞれのOperatorがどの種類のライフサイクルを持ち、どのようにアップグレードをしていくかを検討する必要があります。詳細はこちらにまとまっています。

...が、ただでさえOpenShiftのBefore/Afterの考慮だけでもしんどいのに、このOperatorのBefore/Afterも意識しないといけないのは非常に面倒です。そのため、ここでもRecreateのメリットが活きます。
Reecreateであれば、新バージョンのOpenShiftに紐づくOperatorをインストールし直すだけでOKです。「このOperatorは上げる必要あるか?」みたいな検討をする必要がなくなります。
メリット2. OpenShift(Kubernetes)の特性との親和性が高い
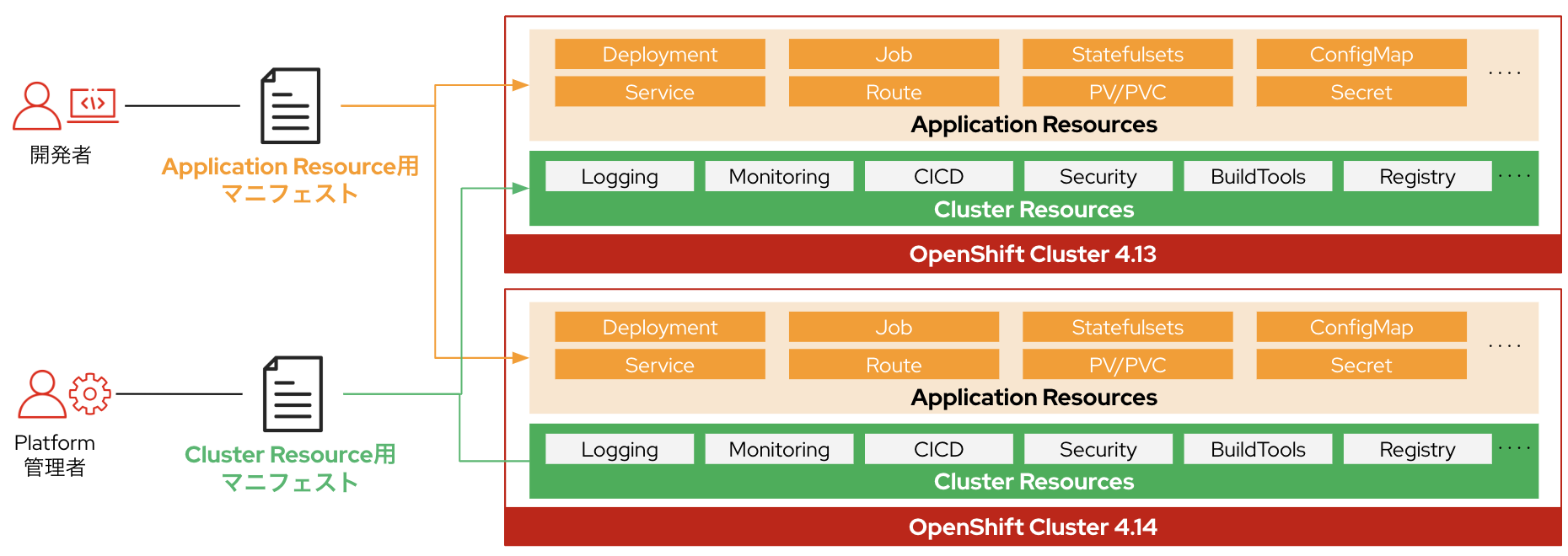
OpenShift(Kubernetes)は宣言的な構成管理を行うため、クラスターのあるべき姿をコード化することで複数クラスターに対して同様の設定を投入しやすくなります。これにより、クラスター再作成のプロセスを大きく効率化できます。これはOpenShiftというよりはKubernetesの特性ですね。
メリット3. ステートのリフレッシュで本番環境のエラーを削減
これは直接的なメリットではなく、どちらかというと副次的なメリットになります。
新バージョンを新規構築するということは、旧バージョンに設定された情報を捨てることになります。そう聞くとリスクのように聞こえますが、それは逆で、むしろ同一環境を長期運用することで環境にステートが蓄積し、意図しない環境差異が生まれるリスクが増加します。ステートの蓄積は想定外を引き起こし、想定外に対処するためのコストが必要になります。Recreate アップグレードで”クラスターの短命化”を実現し、ステートの蓄積による想定外の事象発生を軽減することができます。
クラスターの作り替えを日常にしよう
Recreateアップグレードのメリットを語りましたが、デメリットはなんといっても「クラスターの作り替えがしんどい」に尽きます。具体的なしんどさを感じる点は以下になるかと思います。
- クラスターの作成がしんどい
- クラスターの設定がしんどい
- クラスターが正常に構築・設定されているかの確認がしんどい
- アプリケーションの動作に問題ないかの確認がしんどい
- アプリケーションのデプロイがしんどい
ただ、このしんどさは解決可能であり、是非とも解決を目指して行っていただければと思います。それほどまでにRecreateはOpenShiftのライフサイクルに追従する上で最適なアプローチです。
ではこれらのしんどさを乗り越えるにはどうすればいいか?その答えは自動化になります。順番に見ていきましょう。
クラスターの作成がしんどい
OpenShiftクラスター自体の構築を自動化しましょう。専用のインストーラーによって、特定のクラウドプロバイダー上に仮想マシンを含めたプロビジョニングを実行できます。ベアメタル環境やカスタマイズ環境などユーザーが事前に構築したインフラ上にデプロイする場合は、別途プロビジョニング(IaC)ツールと併用して自動化します。
Managedサービスを利用の場合はもっと簡単で、コマンドをいくつか実行するだけで環境構築が可能です。
Try & Errorを繰り返して、まずクラスターの作成作業を自動化してみましょう。
クラスターの設定がしんどい
OpenShiftクラスターの設定を自動化します。基本的にOpenShiftの設定はK8sマニフェスト(yamlファイル)の適用によって行われます。IaCツールやGitOpsツール、およびスクリプトを活用して、OpenShiftクラスターに対する設定(=K8sマニフェスト適用)を自動化しましょう。
クラスターが正常に構築・設定されているかの確認がしんどい
OpenShiftクラスターの構築および設定が正常に完了しているかを確認するために、プラットフォームテストを行います。スクリプトやIaCツールを活用して、このプラットフォームテストを自動化します。IaCツールを使えば、テストのどのステップでエラーが出力されているかがわかりやすく、効率的な確認と調査が可能です。

アプリケーションの動作に問題ないかの確認がしんどい
アプリケーションに対する各種テスト(単体テスト、結合テストなど)をコード化し、開発を行いながら継続的なソフトウェアの品質確認を実現します。この取り組みにより、”アプリケーションとして出荷可能な状態”をすぐに確認できる状態を作り出せます。
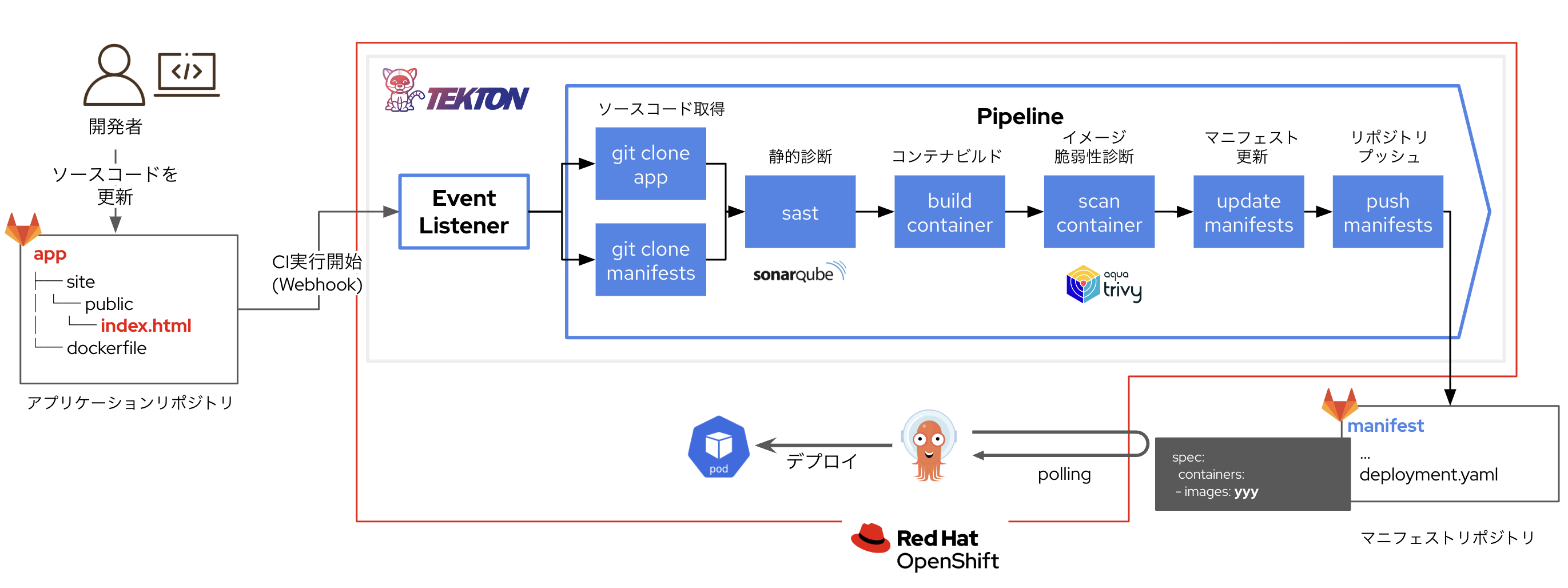
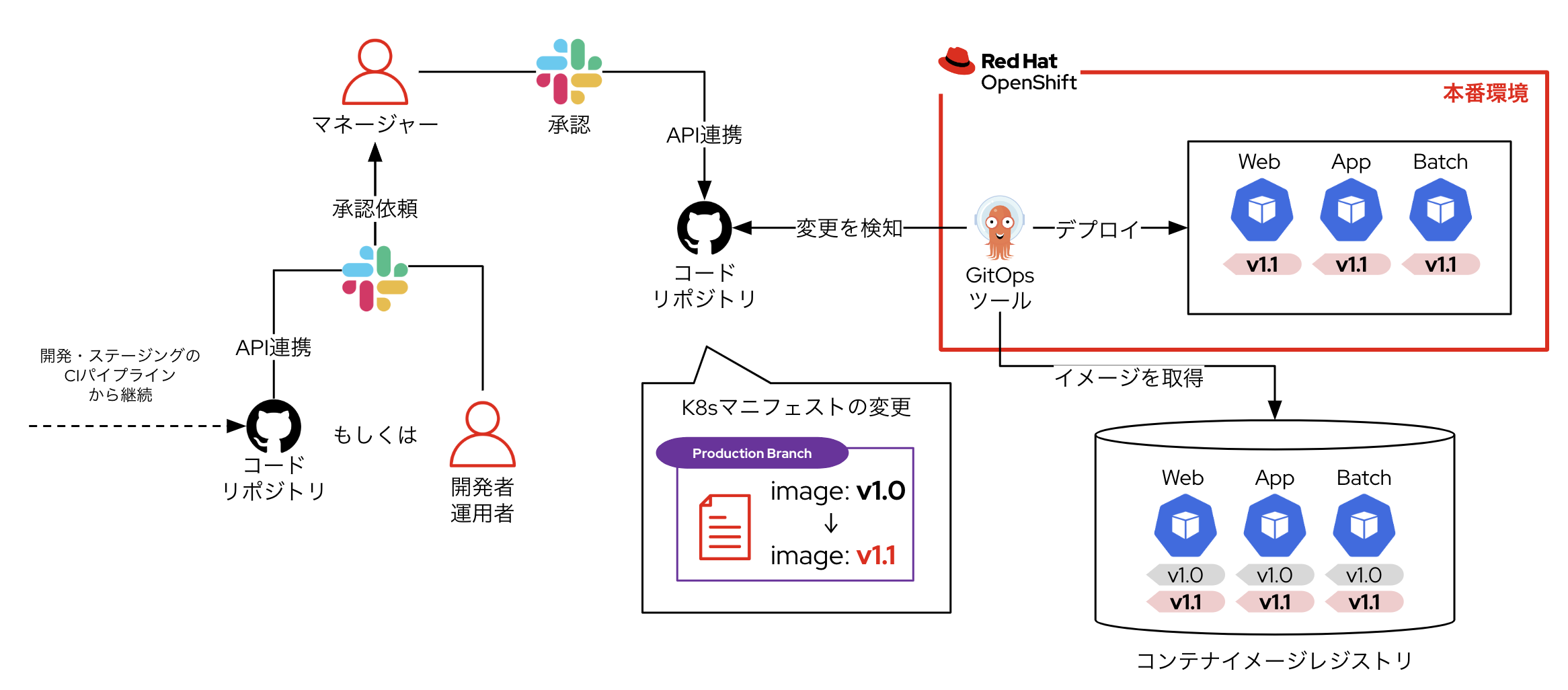
アプリケーションのデプロイがしんどい
本番環境へのリリース作業を自動化しましょう。GitOpsツールを使用して、本番環境のOpenShift上にアプリケーションコンテナをデプロイします。マネージャーによる本番デプロイの承認作業のみを手動で行い、その他の作業をGitOpsツールで代替することで、作業ミスの防止や稼働削減を実現できます。
全部実現できると・・・
上記の取り組みを全て実現できると以下のような世界が実現できます。
- OpenShiftの新しいバージョンが出たタイミングでクラスターを自動構築する
- 旧バージョンに投入していた設定をk8sマニフェストとしてapplyして一気に設定する
- プラットフォームのテストを実行して、これまでの設定が問題なく生きているかを確認する
- アプリケーションをデプロイしてみる。これもGitOpsでこれまでデプロイしていたマニフェストを流用する
- アプリケーションの出荷前テストを自動実行してみる
これらのフローをまずは実行してみて、なにか問題が発生すれば都度調査し、修正し、再度実行してみる、といったように、アップグレード業務全体をTry & Errorですばやく確認していく体制を整えることが重要になります。
OpenShiftはさまざまな機能を包含しているため、リリースノートを眺めて一生懸命差分をチェックして、満を持してアップグレードを実行しても、アプリに影響が出る可能性は防げません。それよりも、さくっと新しいバージョンのOpenShiftをたてて、そこでアプリも運用も試しながら問題がないかを確認した方がよほど近道になります。
もう一度言いますが、OpenShiftのアップグレードをアプリに影響なく実行しようという考えは捨てましょう。 アプリに影響が出ることを前提として、その影響が本番のSLAに波及しないことだけに注力し、開発環境などではむしろ問題を引きながら開発者とPF管理者が連携して解決していくことを推奨します。
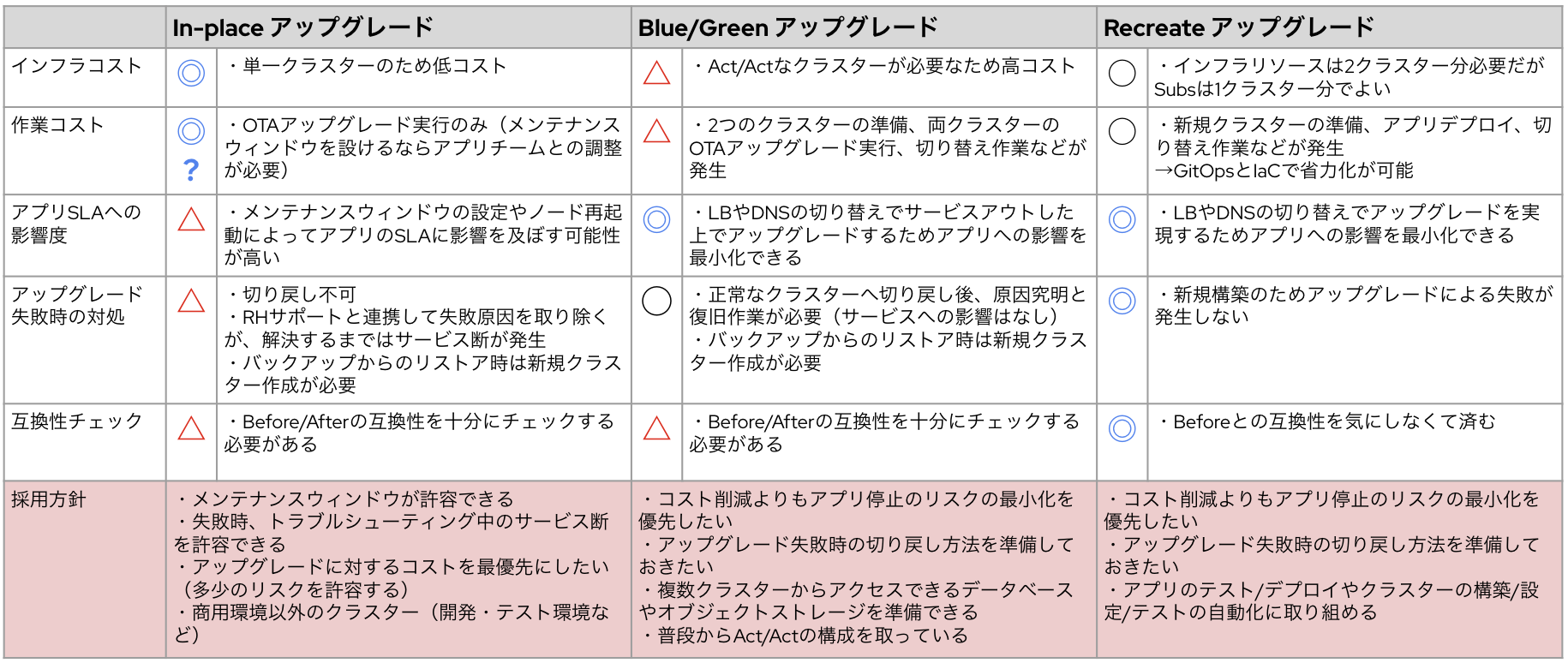
それぞれのアップグレード戦略の比較
各戦略の特徴は以下の通りです。アプリケーションの特性や環境の利用用途に応じて、適切なアップグレード戦略を策定ください。
6. おわりに
最後に改めてOpenShiftアップグレードに対する心構えをまとめます。
for 開発者
-
OpenShift アップグレードがアプリに影響を与えうることを理解しよう
OpenShiftはInfraではなくPlatformです。
-
アップグレードの戦略に合わせてアプリケーションのアーキテクチャを検討しよう
アップグレードがアプリケーションに与える影響を正しく理解し、アップグレードにおいても本番のアプリのSLAに影響が出ないようなアーキテクチャーを考えましょう。
for Platform管理者
-
商用環境とその他の環境の取り扱いを明確に分けよう
従来のIaaSのように、利用者の環境の用途にかかわらず一律のサービスレベルを定義するのは止めましょう。開発環境や検証環境、ステージング環境など、それぞれの用途に応じて適切なサービスレベルを設定し、それを開発者にきちんと周知しましょう。
-
開発者に対してクラスターアップグレードにおける影響を正しく伝えよう
とはいえ開発者がOpenShiftのアップグレードを理解するには、プラットフォーム管理者からの説明が不可欠です。ここにまとまっているアップグレードの概要を正しく開発者に伝えましょう。
-
開発者がOpenShiftアップグレード後の環境に適用できるようサポートしよう
無論、プラットフォーム管理者はOpenShiftのスペシャリストとして、アップグレード後のアプリが正しく動作するまでサポートを行いましょう。インターネットに上がっている情報やRed Hatの公式ドキュメント、あるいはサポートケースを駆使して問題解決に努めましょう。
for ALL
-
柔軟かつ迅速な対応ができるよう、コミュニケーションをしっかり取ろう
説明不要!両者の連携なくしてイノベーションの加速は起きません!
OpenShiftのアップグレードを正しく理解し、ぜひイノベーションの加速と信頼性の両立を実現してください。